










目录
1. 背景与问题
2. PuLID网络结构和原理
3. 效果对比与应用场景
4. ComfyUI_Pulid_Flux的应用实践
5. 源码分析
6. 资料
一. 背景与问题
在文生图(Text-to-Image,T2I)领域,保证人物ID的一致性,是一个关键技术,可以通过lora进行微调训练,但要针对每个人物进行训练成本还是比较高,ipadapter和InstantID在人物一致性方面取得了很好的进展,但是插入ID身份信息时往往会干扰原始模型的行为,导致生成的图像在风格,布局等方面和原始模型生成的图片有较大的差异.
字节团队提出了一种PuLID(Pure and Lightning ID Customization via Contrastive Alignment)的方案,通过对比对齐实现纯粹且快速的ID一致性,主要的亮点:
-
增加了对比对齐loss和ID loss,最大限度减少对原始模型的破坏并保证ID的一致性
-
提示词可以很好的引导生成过程

二. PuLID网络结构和原理
2.1.PuLID网络结构
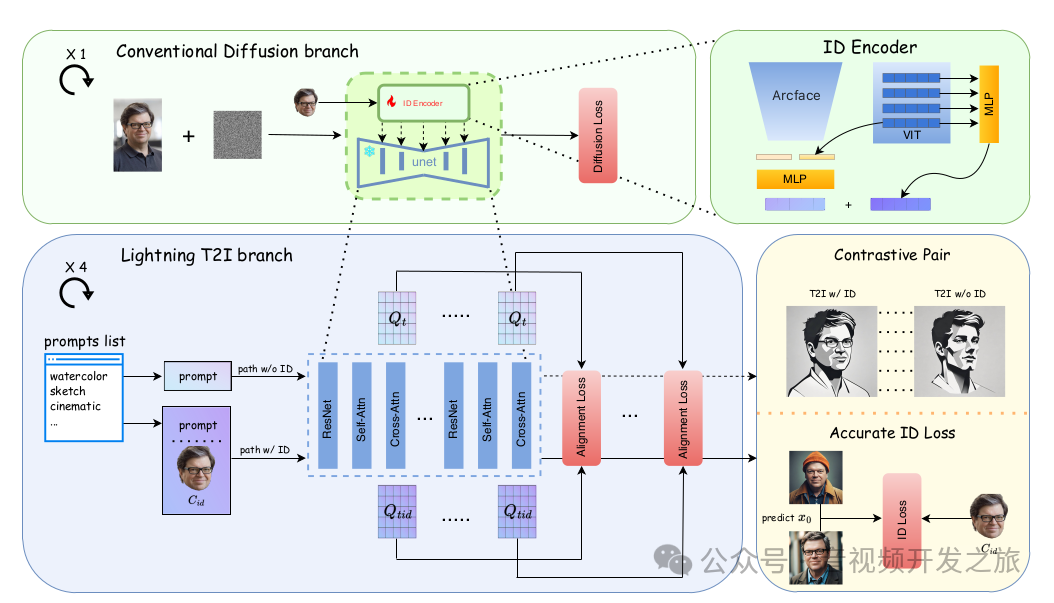
双分支训练框架:PuLID采用了一个结合了常规的扩散模型分支(Conventional Diffusion branch)和快速文生图分支(Lightning T2I branch)的训练框架,通过对齐损失和精确的ID损失,减少对原始模型图像生成过程的干扰,同时实现精准的身份ID定制
ID Encoder:使用Arcface(对人脸进行识别特征提取) 和Clip-VIT(对图像特征提取)对采集的1.5M人像数据进行特征提取和MLP影射拼接,作为condition信息,指导模型生成和condition人脸相似的图像.
对比对齐(Contrastive alignment): 构建两条生成路径(具有相同的prompt和latent初始条件,差异点在于一条保护ID嵌入,一条不包含),使用对齐损失(alignment Loss)来语义和布局上对齐两条路径的UNet特征,指导模型在不干扰原始模型行为(保持风格,布局的一致性)的情况下嵌入ID信息.
精确ID损失(Accurate ID Loss):在ID插入后,PuLID从生成的图像(predict x0)提取提取人脸特征,和真实的人脸特征(C_id)计算ID损失,确保生成的图像在身份特征上的高保真度.
模型总的学习目标: 扩散模型Loss + 对齐Loss(语义对齐和布局对齐)+ID Loss,训练出生成ID一致性的高质量图像的模型.
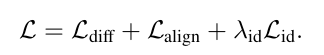
下面我们详细介绍下每个Loss
2.2 扩散模型的Loss
扩散过程使用噪声调度器对噪声ε进行采样添加到原始数据x_0上,在时间步t生成一个x_t噪声样本;去噪过程使用由残差网络,自注意力机制和交叉注意力机制组成的UNet去噪模型ε_θ,将x_t,t和可选的附加条件C作为输入来预测噪声,对应公式如下:
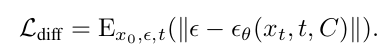
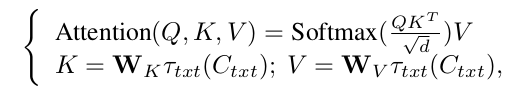
2.3 对齐loss
对齐损失由语义对齐损失(Lalign-sem)和布局对齐损失(Lalign-layout)构成
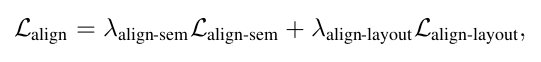
2.3.1 语义对齐loss
Qt:不带ID embeding的UNet features
Qtid:带ID embeding的Unet features
是一个Attention(K,Q,Q),两个路径的插值越小,ID嵌入对原始模型的Unet的影响越小
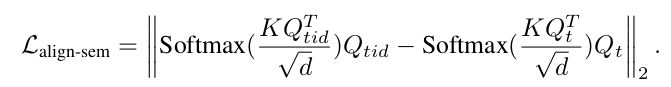
2.3.2 布局对齐loss
Lalign-sem语义损失显著的减轻了ID信息破坏原始模型行为的问题,但是它不能保证布局的一致性,为此添加一个布局对其损失Lalgin_layout. 通过计算Qt和Qtid的loss,使得图像布局上保持原始模型的特征
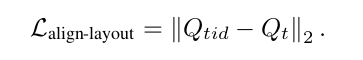

2.4 ID loss
通过余弦相似性计算生成图像和真实图像Cid之间的ID特征的差异,使其最小化从而保证ID的一致性
Cid: id Condition 身份条件
Ctxt: text Condition 文本条件
ϕ(Cid):真实图像的ID特征
ϕ(L−T2I(Xt,Cid,Ctxt)):生成图像的ID特征
Xt:时间步为t的扩散过程产物
T2I:结合身份条件,文本条件来生成图像
L:表示扩散过程,它接受噪声图像和时间步t作为输入,并预测在该时间步长的噪声
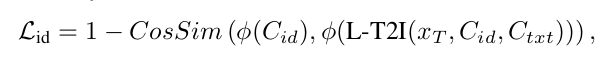
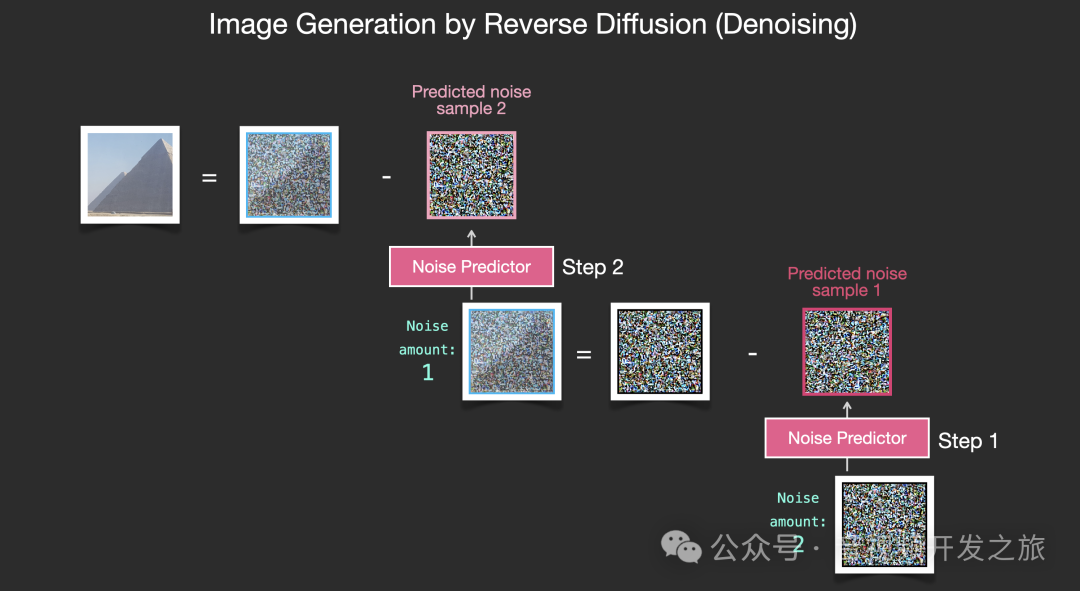
三. 效果对比与应用场景
3.1 不同方案的对比
PuLID实现了更高的ID保真度,同时减少对原始模型中文本提示的干扰. PuLID在光影,风格,布局方面和提示词描述更加吻合

3.2 不同权重下的结果
可以看到当ID权重设置相对较小值时,ID嵌入对原始模型的影响很小,随着权重的增加,可以看出PuLID只影响和ID相关的部分,不会显著的扰乱原始模型的行为.

3.3 更多应用场景
论文中也给出了PuLID的更多应用场景:
风格变化,IP融合,配饰修改,场景修改,人物属性修改,ID混合等


四. ComfyUI_Pulid_Flux的应用实践
上面我们介绍原理的PuLID是基于SDXL的,网络结构还是UNet, Flux相比SDXL有更大参数,UNet也改为了DiT,随着Flux的发布以及相应生态建立和完善,基于Flux的ComfyUI插件也是很快跟上. 这一小节,我们对ComfyUI_Pulid_Flux进行实践.
4.1 模型下载与依赖
下载Flux.1-dev放在ComfyUI/models/checkpoints下
下载PuLID_flux预训练权重,放在ComfyUI/models/pulid下
下载EVA-Clip放在ComfyUI/models/clip下. 这里需要注意,由于代码中eva-clip自动下载到cache路径,这里需要修改源码中的权重加载路径:ComfyUI/custom_nodes/ComfyUI-PuLID-Flux/pulidflux.py
eva_clip_model_path='ComfyUI/models/clip/EVA02_CLIP_L_336_psz14_s6B.pt'model, _, _ = create_model_and_transforms('EVA02-CLIP-L-14-336', eva_clip_model_path, force_custom_clip=True)
安装facexlib,下载相关的权重
detection_Resnet50_Final.pthparsing_parsenet.pthparsing_bisenet.pth
下载insightFace需要的AtelopeV2放在ComfyUI/models/insightface/models/antelopev2
公众号"音视频开发之旅",关注并回复"PuLID"获取相关权重
4.2 ComfyUI_Pulid_Flux
使用https://github.com/balazik/ComfyUI-PuLID-Flux/tree/master/examples/pulid_flux_16bit_simple.json 工作流
基于FLUX.1-dev-fp8模型
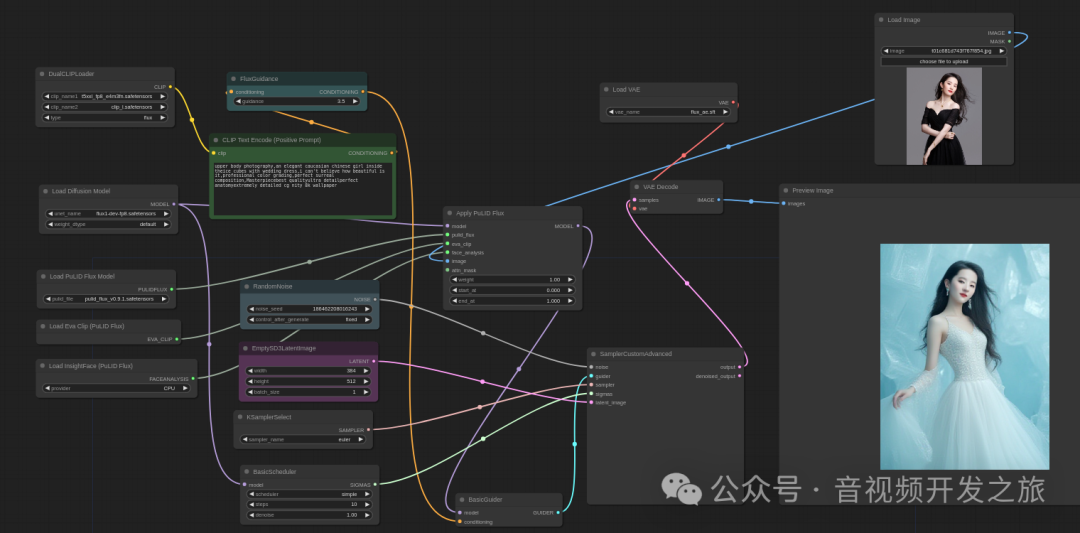
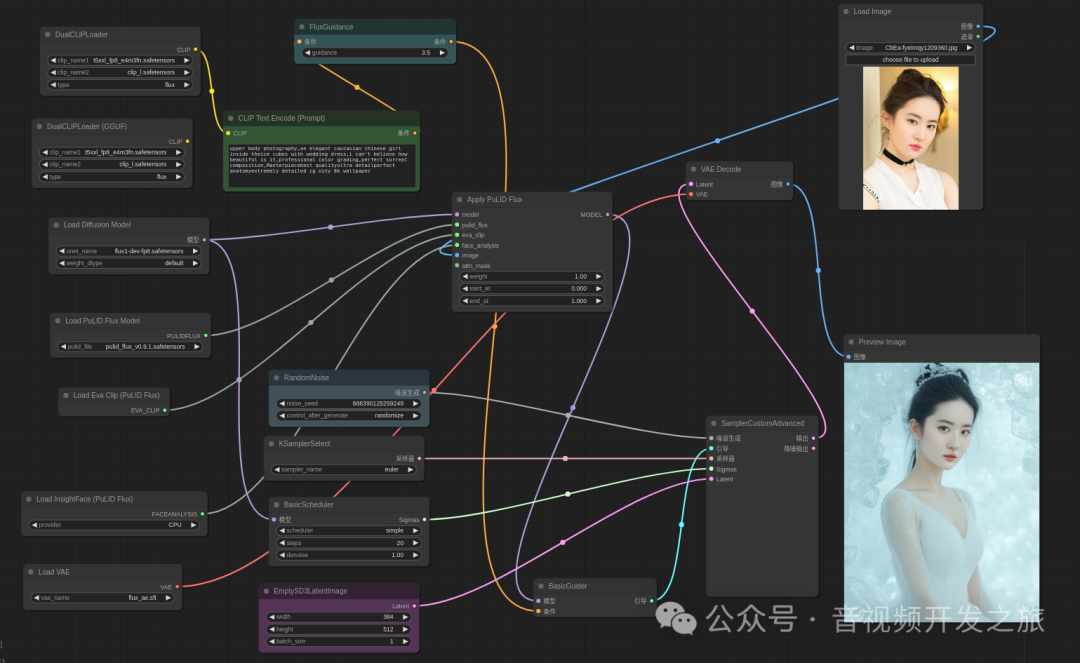
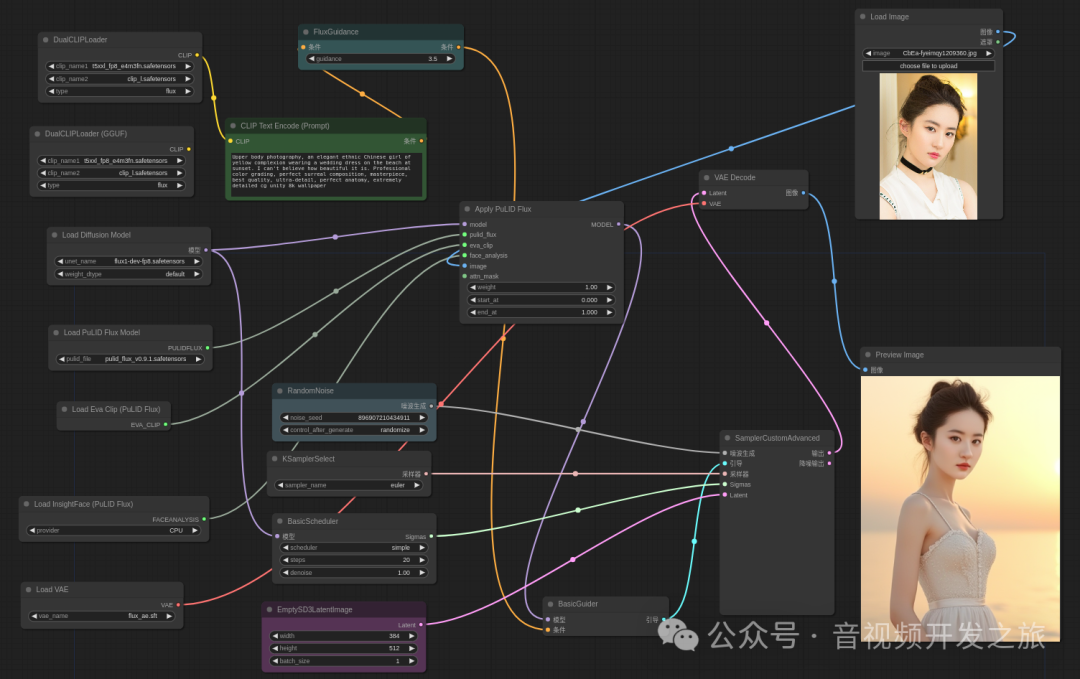
小技巧: 使用过程中,如果显存不足,报OOM,可以把图片的wh等比例缩小, 生成后在使用超分放大模型进行处理
五. 源码分析
https://github.com/balazik/ComfyUI-PuLID-Flux/pulidflux.py
ComfyUI-PuLID-Flux支持的节点类型如下,其中前三个分别是模型加载器, ApplyPulidFlux是把Flux低模和PulidFluxMode,人脸检测模型PulidFluxInsight以及EVA编码模型NODE_CLASS_MAPPINGS = {"PulidFluxModelLoader": PulidFluxModelLoader,"PulidFluxInsightFaceLoader": PulidFluxInsightFaceLoader,"PulidFluxEvaClipLoader": PulidFluxEvaClipLoader,"ApplyPulidFlux": ApplyPulidFlux,}我们重点看ApplyPulidFlux节点,它结合了人脸检测,特征提取,条件嵌入和模型应用等多个步骤.以实现在图像中嵌入身份信息,同时保证图像的其他属性不变. 代码注释如下:class ApplyPulidFlux:"""apply_pulid_flux方法接受多个参数,包括低模、PuLID_Flux模型、Eva Clip模型、人脸分析器、输入图像、PuLID_Flux权重、起始和结束时间步长、注意力掩码和唯一标识符。"""def apply_pulid_flux(self, model, pulid_flux, eva_clip, face_analysis, image, weight, start_at, end_at, attn_mask=None, unique_id=None):device = comfy.model_management.get_torch_device()dtype = model.model.diffusion_model.dtype#将eva_clip和pulid_flux模型转换到指定的设备和数据类型。eva_clip.to(device, dtype=dtype)pulid_flux.to(device, dtype=dtype)#将输入图像转换为张量。image = tensor_to_image(image)#人脸检测和特征提取face_helper = FaceRestoreHelper(upscale_factor=1,face_size=512,crop_ratio=(1, 1),det_model='retinaface_resnet50',save_ext='png',device=device,)face_helper.face_parse = Noneface_helper.face_parse = init_parsing_model(model_name='bisenet', device=device)bg_label = [0, 16, 18, 7, 8, 9, 14, 15]cond = []# Analyse multiple images at multiple sizes and combine largest area embeddingsfor i in range(image.shape[0]):# get insightface embeddingsiface_embeds = None#从图像中提取人脸特征for size in [(size, size) for size in range(640, 256, -64)]:face_analysis.det_model.input_size = sizeface_info = face_analysis.get(image[i])if face_info:face_info = sorted(face_info, key=lambda x: (x.bbox[2] - x.bbox[0]) * (x.bbox[3] - x.bbox[1]))[-1]iface_embeds = torch.from_numpy(face_info.embedding).unsqueeze(0).to(device, dtype=dtype)breakelse:# No face detected, skip this imagelogging.warning(f'Warning: No face detected in image {str(i)}')continue# get eva_clip embeddingsface_helper.clean_all()face_helper.read_image(image[i])face_helper.get_face_landmarks_5(only_center_face=True)face_helper.align_warp_face()if len(face_helper.cropped_faces) == 0:# No face detected, skip this imagecontinue# Get aligned face imagealign_face = face_helper.cropped_faces[0]# Convert bgr face image to tensoralign_face = image_to_tensor(align_face).unsqueeze(0).permute(0, 3, 1, 2).to(device)parsing_out = face_helper.face_parse(functional.normalize(align_face, [0.485, 0.456, 0.406], [0.229, 0.224, 0.225]))[0]parsing_out = parsing_out.argmax(dim=1, keepdim=True)bg = sum(parsing_out == i for i in bg_label).bool()white_image = torch.ones_like(align_face)# Only keep the face featuresface_features_image = torch.where(bg, white_image, to_gray(align_face))# Transform img before sending to eva_clip# Apparently MPS only supports NEAREST interpolation?face_features_image = functional.resize(face_features_image, eva_clip.image_size, transforms.InterpolationMode.BICUBIC if 'cuda' in device.type else transforms.InterpolationMode.NEAREST).to(device, dtype=dtype)face_features_image = functional.normalize(face_features_image, eva_clip.image_mean, eva_clip.image_std)# eva_clipid_cond_vit, id_vit_hidden = eva_clip(face_features_image, return_all_features=False, return_hidden=True, shuffle=False)id_cond_vit = id_cond_vit.to(device, dtype=dtype)for idx in range(len(id_vit_hidden)):id_vit_hidden[idx] = id_vit_hidden[idx].to(device, dtype=dtype)id_cond_vit = torch.div(id_cond_vit, torch.norm(id_cond_vit, 2, 1, True))# 将人脸特征和clip-vit条件 嵌入到扩散模型中id_cond = torch.cat([iface_embeds, id_cond_vit], dim=-1)# Pulid_encodercond.append(pulid_flux.get_embeds(id_cond, id_vit_hidden))# average embeddingscond = torch.cat(cond).to(device, dtype=dtype)if cond.shape[0] > 1:cond = torch.mean(cond, dim=0, keepdim=True)sigma_start = model.get_model_object("model_sampling").percent_to_sigma(start_at)sigma_end = model.get_model_object("model_sampling").percent_to_sigma(end_at)flux_model = model.model.diffusion_model# 将条件嵌入到Flux模型中,并存储在pulid_data 字典中。flux_model.pulid_data[unique_id] = {'weight': weight,'embedding': cond,'sigma_start': sigma_start,'sigma_end': sigma_end,}self.pulid_data_dict = {'data': flux_model.pulid_data, 'unique_id': unique_id}return (model,)
小结
PuLID将常规的扩散分支和Lightning T2I分支想结合,引入对比对齐损失和准确的ID损失,最大限度的减少对原始模型的破坏,生成具有较高ID一致性高质量图像.
但也存在一些局限性:引入T2I分支,需要更多的显存;T2I分支引入IdLoss显著提升ID一致性的同时也一定程度上影响了生成图像的质量,例如导致面部模糊等问题
六. 资料
1.PULID论文:https://arxiv.org/abs/2404.16022
2.源码: https://github.com/ToTheBeginning/PuLID
3.ComfyUI_Pulid_flux节点: https://github.com/balazik/ComfyUI-PuLID-Flux
4.PULID:对比对齐的ID定制化技术:https://blog.csdn.net/qq_44091004/article/details/139455437
5.PuLID-字节跳动开源的个性化文本到图像生成框架:https://ai-bot.cn/pulid/
6.Review_PuLID: https://cp0000.github.io/posts/review_pulid/
7.【论文笔记】| 定制化生成PuLID:https://blog.csdn.net/m0_62249876/article/details/139013586
8.Flux_pulid工作流: https://openart.ai/workflows/bulldog_fruitful_46/flux_pulid/dq1yBzUQim9ArrJQslVG
9.Face Swapping: EcomID vs. Flux PuLID vs. InstantID工作流:https://openart.ai/workflows/myaiforce/2ATyK62dutoPVCevX8o5
10.字节发布文生图模型PuLID:高效身份ID特征定制,单张图像克隆AI虚拟分身:https://blog.csdn.net/nulifancuoAI/article/details/138636073
感谢你的阅读
接下来我们继续学习输出AI相关内容,欢迎关注公众号“音视频开发之旅”,一起学习成长。
欢迎交流


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









