






第1章 扩散模型简介
1.生成模型
扩散模型(diffusion models)属于无监督生成模型,而关于生成模型的研究浩如烟海,例如耳熟能详的生成对抗网络(GAN)、变分自编码器(VAE)、流模型(Flow)、玻尔兹曼机(Boltzman Machine)、自回归模型等。
生成模型的基本任务是生成样本,例如生成逼真的人脸图片、生成高质量的语音等;当然也可以通过改进生成模型从而实现样本之间的映射转换,例如图像风格迁移、语音增强等。
2、扩散模型
扩散模型成功的秘诀在于扩散过程的迭代本质。最先生成的只是一组随机噪声,但是经过若干步的逐渐改善之后,最终会出现有意义的图像。在每一步中,模型都会估计如何从当前的输入生成完全去噪的结果。因为我们在每一步都只做了一个小小的变动,所以在早期阶段(预测最终输出实际上非常困难),这个估计中的任何 error 都可以在以后的更新中得到纠正。与其他类型的生成模型相比,训练扩散模型相对较为容易。我们只需要重复以下步骤即可:
-从训练数据中加载一些图像
-添加不同级别的噪声。请记住,我们希望模型在面对添加了极端噪声和几乎没有添加噪声的带噪图像时,都能够很好地估计如何 “修复”(去噪)。
-将带噪输入送入模型中
-评估模型对这些输入进行去噪的效果
-使用此信息更新模型权重
为了用训练好的模型生成新的图像,我们从完全随机的输入开始,反复将其输入模型,每次根据模型预测进行少量更新。有许多采样方法试图简化这个过程,以便我们可以用尽可能少的步骤生成好的图像。
3、 扩散模型的应用
计算机视觉:图像分割与目标检测、图像超分辨率(串联多个扩散模型)、图像修复、图像翻译和图像编辑。
时序数据预测:TimeGrad模型,使用RNN处理历史数据并保存到隐空间,对数据添加噪声实现扩散过程,处理数千维度德多元数据完成预测。
自然语言:使用Diffusion-LM可以应用在语句生成、语言翻译、问答对话、搜索补全、情感分析、文章续写等任务中。
基于文本的多模态:文本生成图像(DALLE-2、Imagen、Stable Diffusion)、文本生成视频(Make-A-Video、ControlNet Video)、文本生成3D(DiffRF)
AI基础科学:SMCDiff(支架蛋白质生成)、CDVAE(扩散晶体变分自编码器模型)
第2章 Hugging Face简介
无
第3章 从零开始搭建扩散模型****
1、环境准备
2、数据
我们使用一个非常小的经典数据集mnist来进行测试。该数据集中的每张图都是一个数字的28x28像素的灰度图,像素值的范围事从0到1。
3、损坏过程
我们可能想要一个简单的方法来控制损坏的程度。那么,如果我们要引入一个参数来控制输入的“噪声量”,那么我们会这么做:
noise = torch.rand_like(x)
noisy_x = (1-amount)x + amountnoise
如果 amount = 0,则返回输入而不做任何更改。如果 amount = 1,我们将得到一个纯粹的噪声。通过这种方式将输入与噪声混合,我们将输出保持在相同的范围(0 to 1)。
我们可以很容易地实现这一点(但是要注意tensor的shape,以防被广播(broadcasting)机制不正确的影响到)
4、模型
我们想要一个模型,它可以接收28px的噪声图像,并输出相同形状的预测。一个比较流行的选择是一个叫做UNet的架构。最初被发明用于医学图像中的分割任务,UNet由一个“压缩路径”和一个“扩展路径”组成。“压缩路径”会使通过该路径的数据被压缩,而通过“扩展路径”会将数据扩展回原始维度(类似于自动编码器)。模型中的残差连接也允许信息和梯度在不同层级之间流动。
一些UNet的设计在每个阶段都有复杂的blocks,但对于这个玩具demo,我们只会构建一个最简单的示例,它接收一个单通道图像,并通过下行路径上的三个卷积层(图和代码中的down_layers)和上行路径上的3个卷积层,在下行和上行层之间具有残差连接。我们将使用max pooling进行下采样和nn.Upsample用于上采样。某些比较复杂的UNets的设计会使用带有可学习参数的上采样和下采样layer。下面的结构图大致展示了每个layer的输出通道数:
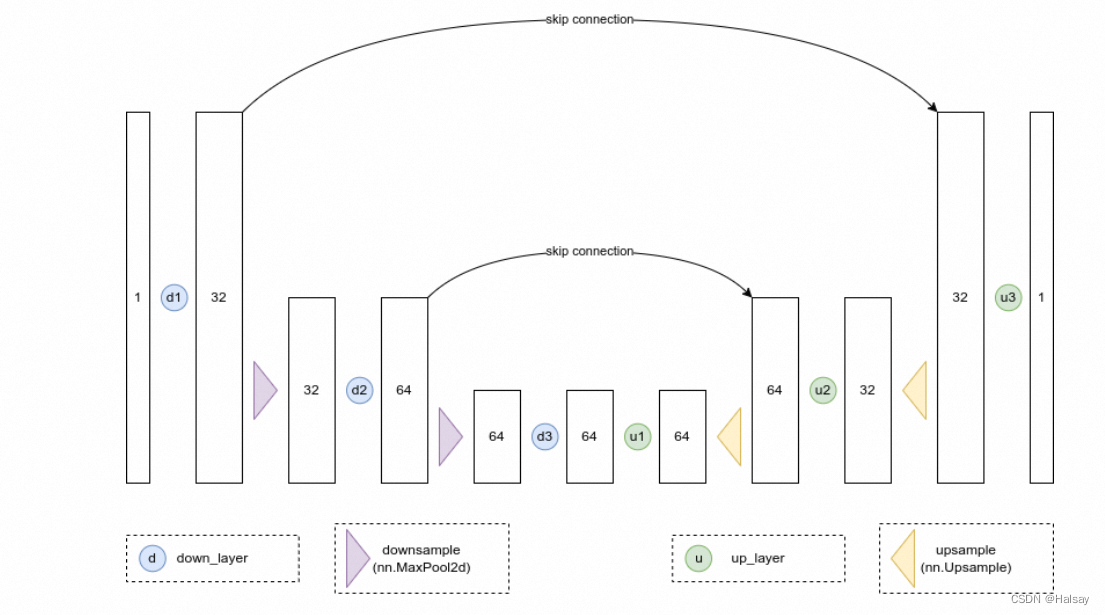
5、训练模型
那么,模型到底应该做什么呢?同样,对这个问题有各种不同的看法,但对于这个演示,让我们选择一个简单的框架:给定一个损坏的输入noisy_x,模型应该输出它对原本x的最佳猜测。我们将通过均方误差将预测与真实值进行比较。
我们现在可以尝试训练网络了。
获取一批数据
添加随机噪声
将数据输入模型
将模型预测与干净图像进行比较,以计算loss
更新模型的参数。
你可以自由进行修改来尝试获得更好的结果!
6、取样(采样)
如果我们在高噪声水平下的预测不是很好,我们如何才能生成图像呢?
如果我们从完全随机的噪声开始,检查一下模型预测的结果,然后只朝着预测方向移动一小部分,比如说20%。现在我们有一个噪声很多的图像,其中可能隐藏了一些关于输入数据的结构的提示,我们可以将其输入到模型中以获得新的预测。希望这个新的预测比第一个稍微好一点(因为我们这一次的输入稍微减少了一点噪声),所以我们可以用这个新的更好的预测再往前迈出一小步。
如果一切顺利的话,以上过程重复几次以后我们就会得到一个新的图像!以下图例是迭代了五次以后的结果,左侧是每个阶段的模型输入的可视化,右侧则是预测的去噪图像。Note that even though the model predicts the denoised image even at step 1, we only move x part of the way there. 重复几次以后,图像的结构开始逐渐出现并得到改善,直到获得我们的最终结果为止。














 2553
2553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









