







论文
来自:meta ai

摘要
我们介绍了“分割任何东西”(SA)项目:一项新的图像分割任务、模型和数据集。利用我们高效的模型在数据收集循环中,我们建立了迄今为止最大的分割数据集,拥有超过11百万张经过许可且尊重隐私的图像上的10亿个掩码。该模型经过设计和训练,可以进行提示,因此它可以零点转移到新的图像分布和任务。我们评估了它在众多任务上的能力,并发现它的零点性能令人印象深刻——通常与甚至优于以前的完全监督结果相竞争。我们正在发布“分割任何东西”模型(SAM)和相应的数据集(SA-1B),其中包含1B个掩码和11M张图像,以促进计算机视觉基础模型研究。
任务,模型,数据
1. 简介
大型语言模型如何通过在网络规模的数据集上进行预训练来革新自然语言处理(NLP),具有强大的零点和少点泛化能力。这些“基础模型”能够推广到训练期间未见过的任务和数据分布。这种能力通常是通过提示工程来实现的,其中手工制作的文本用于提示语言模型为手头的任务生成有效的文本响应。当通过网络上丰富的文本语料库进行扩展和训练时,这些模型的零点和少点性能与(甚至在某些情况下匹配)微调模型相当。
基础模型也在计算机视觉领域得到了探索,但程度较小。也许最突出的例子是将来自网络的成对文本和图像对齐。例如,CLIP [82] 和 ALIGN [55] 使用对比学习来训练文本和图像编码器,使两种模态对齐。一旦训练完成,经过设计的文本提示就能够实现对新颖视觉概念和数据分布的零点泛化。这些编码器还可以与其他模块有效地组合,以实现下游任务,如图像生成(例如 DALL·E [83])。尽管在视觉和语言编码器方面取得了很大进展,但计算机视觉包括超出此范围的广泛问题,而且对于其中许多问题,不存在丰富的训练数据。
我们对SAM进行了广泛的评估。首先,使用一个多样的新的23个分割数据集套件,我们发现SAM从单个前景点产生高质量的掩码,通常仅略低于人工标注的真实值。其次,我们在使用提示工程的零点转移协议下的各种下游任务上发现了一致强大的定量和定性结果,包括边缘检测、对象建议生成、实例分割和文本到掩码预测的初步探索。这些结果表明,SAM可以通过提示工程直接使用,解决涉及对象和图像分布超出SAM训练数据范围的各种任务。然而,仍有改进空间。
2. 分割一切的任务
我们从自然语言处理(NLP)中汲取灵感,其中下一个令牌预测任务用于基础模型预训练和通过提示工程解决多样的下游任务。为了建立一个分割的基础模型,我们的目标是定义一个具有类似能力的任务。
提示性分割任务:
如何将自然语言处理(NLP)中的提示概念转换为分割,其中提示可以是一组前景/背景点、一个粗略的框或掩码、自由形式文本,或者通常指示图像中要分割什么的任何信息。因此,可提示的分割任务是在给定任何提示的情况下返回一个有效的分割掩码。对“有效”掩码的要求仅仅意味着即使提示是模糊的并且可能指多个对象(例如,回忆衬衫与人的例子,并参见图3),输出应该是至少其中一个对象的合理掩码。这个要求类似于期望语言模型对模糊提示输出一个连贯的响应。我们选择这个任务是因为它导致了一个自然的预训练算法和一个通过提示进行下游分割任务零点转移的通用方法。
分割部分的预训练:该算法模拟每个训练样本的一系列提示(例如,点、框、掩码),并将模型的掩码预测与真实值进行比较。我们从交互式分割[109, 70]中改编了这种方法,尽管与交互式分割不同的是,其目的是在足够的用户输入后最终预测一个有效的掩码,而我们的目标是始终为任何提示预测一个有效的掩码,即使提示是模糊的。这确保了预训练模型在涉及歧义的使用情况下有效。
zero-shot 迁移:
我们的预训练任务直观地赋予了模型在推理时对任何提示做出适当响应的能力,因此下游任务可以通过设计适当的提示来解决。例如,如果有一个用于猫的边界框检测器,猫实例分割可以通过将检测器的边界框输出作为提示提供给我们的模型来解决。
提示和组合的基础AI
提示和组合是强大的工具,它们能够使单个模型以可扩展的方式使用,可能完成在模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如,CLIP [82] 是 DALL·E [83] 图像生成系统的文本-图像对齐组件。我们预计,由诸如提示工程等技术支持的可组合系统设计将比专门为固定任务集训练的系统能够实现更广泛的应用
网络结构
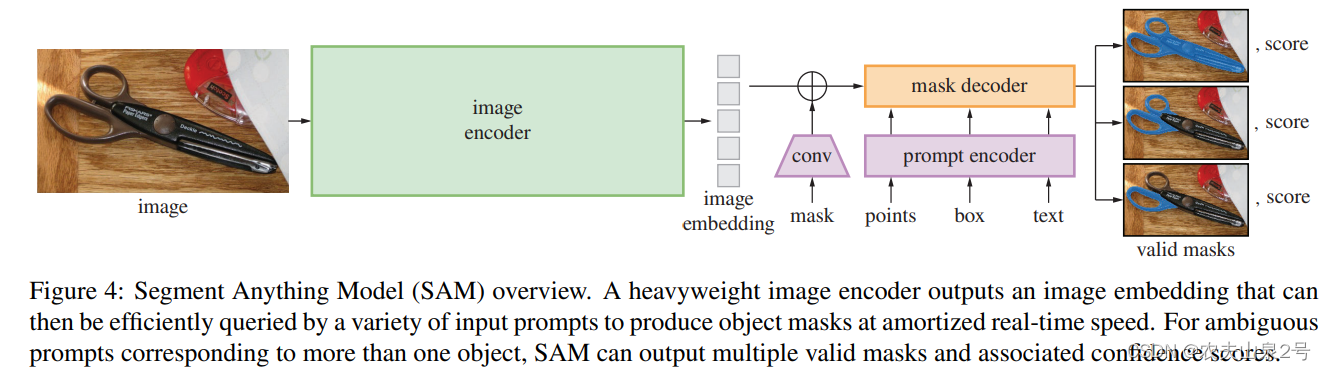
- 图像编码部分:MAE
- prompt encoder: 稀疏(点,框,文字),密集的(分割的mask)用位置编码,文字用CLIP, mask用卷积。
- 解码:主要是采用了mask2former的思想(下一篇安排)
- 模糊提示:如果给定一个模糊的提示,模型将平均多个有效掩码。为了解决这个问题,我们修改了模型,使其能够为单个提示预测多个输出掩码(见图3)。我们发现3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多三层深:整体、部分和子部分)。在训练期间,我们只对最小的损失进行反向传播。
数据引擎
11M的图像,1.1B个mask

zero-shot 迁移
-
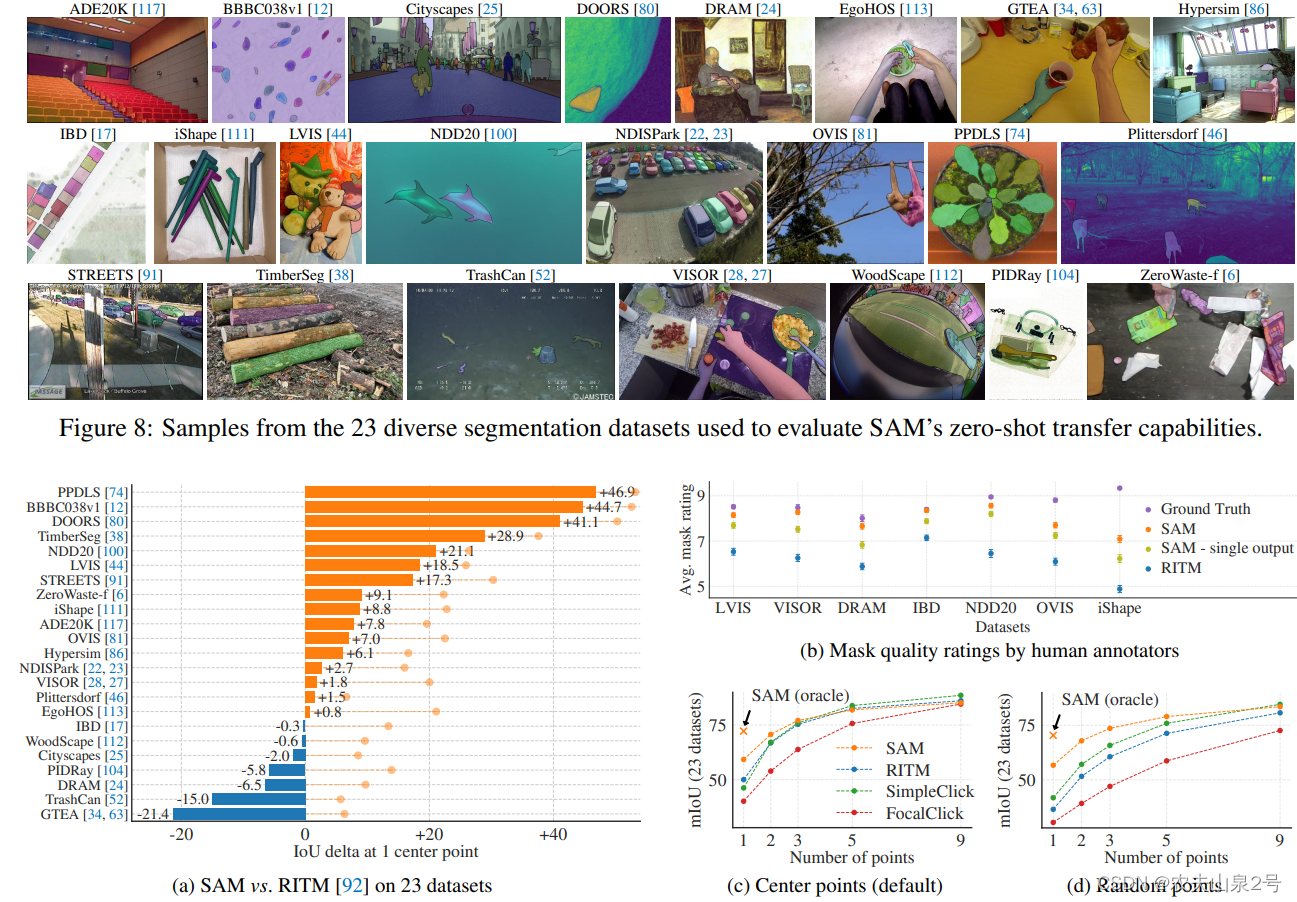
交互式分割
比RITM更优秀
-
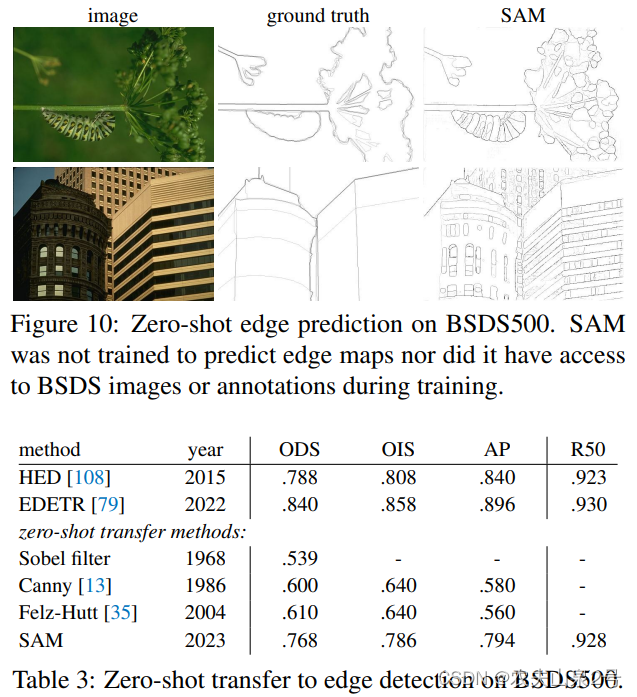
边缘检测
-
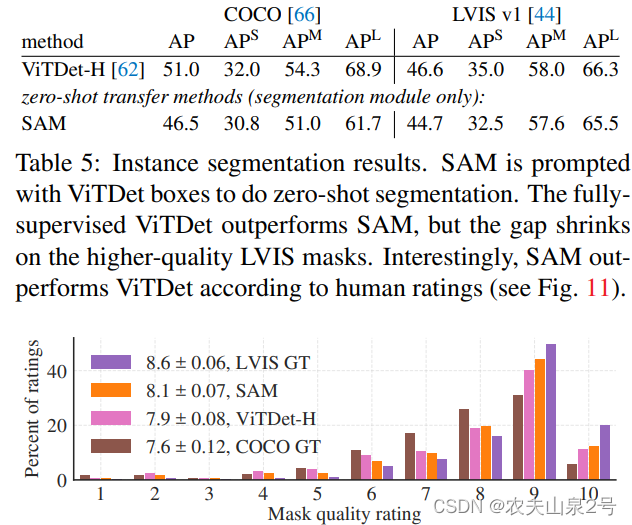
实例分割
训练数据和模型大小
1百万+308M的VIT-L模型是一个选择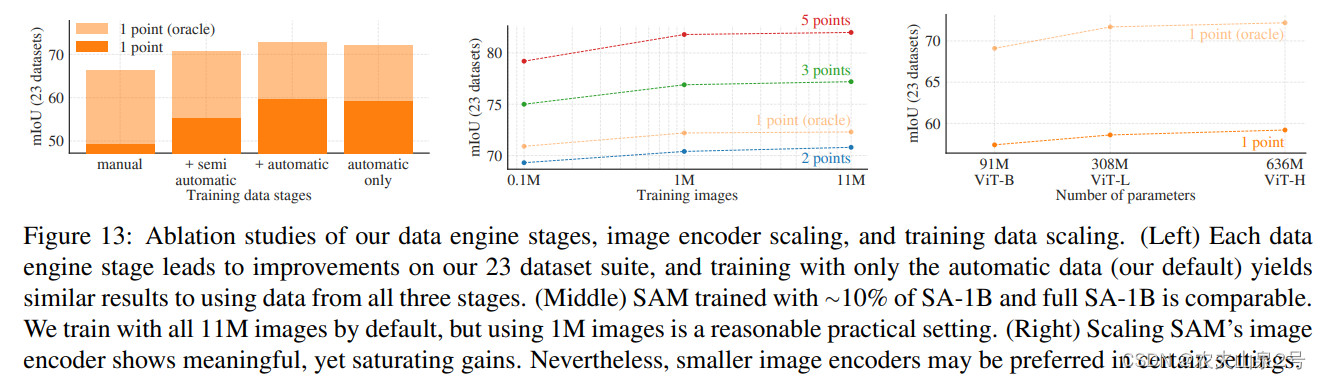
















 1869
1869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









