







视频matting
时序监督

摘要
我们介绍了一种稳健、实时、高分辨率的人类视频抠图方法,该方法取得了新的最先进性能。我们的方法比以前的方法轻得多,可以在Nvidia GTX 1080Ti GPU上以76 FPS处理4K,以104 FPS处理HD。与大多数现有的逐帧作为独立图像进行视频抠图的方法不同,我们的方法使用循环架构来利用视频中的时间信息,并在时间一致性和抠图质量方面取得了显著改进。此外,我们提出了一种新的训练策略,强制我们的网络同时满足抠图和分割目标。这显著提高了我们模型的稳健性。我们的方法不需要任何辅助输入,如trimap或预捕获的背景图像,因此可以广泛应用于现有的人类抠图应用程序
1. 简介
尽管大多数现有的方法[18, 22, 34]是为视频应用设计的,但它们将单个帧作为独立的图像进行处理。这些方法忽略了视频中最广泛可用的特征:时间信息。时间信息可以出于许多原因改善视频抠图性能。首先,它允许预测更一致的结果,因为模型可以看到多个帧和它自己的预测。这显著减少了闪烁并提高了感知质量。其次,时间信息可以提高抠图的稳健性。在个别帧可能模糊不清的情况下,例如前景颜色变得与背景中经过的物体相似,模型可以通过参考前面的帧更好地猜测边界。第三,时间信息允许模型随着时间了解更多关于背景的信息。当摄像机移动时,由于透视变化,主体后面的背景被揭示出来。即使摄像机固定不动,被遮挡的背景仍然经常由于主体的运动而显露出来。更好地了解背景简化了抠图任务。因此,我们提出了一种循环架构来利用时间信息。我们的方法显著提高了抠图质量和时间一致性。它可以应用于所有视频,而不需要任何辅助输入,如手动注释的trimap或预捕获的背景图像
大多数现有的方法都是在合成抠图数据集上进行训练的。样本通常看起来很假,阻止网络推广到真实图像。以前的工作[18, 22]曾试图用分割任务上训练的权重初始化模型,但模型在抠图训练期间仍然过度拟合到合成分布。其他人曾尝试在未标记的真实图像上进行对抗性训练[34]或半监督学习[18]作为额外的适应步骤。我们认为人类抠图任务与人类分割任务密切相关。同时进行分割目标的训练可以有效地调节我们的模型,而无需额外的适应步骤。
2. 网络结构
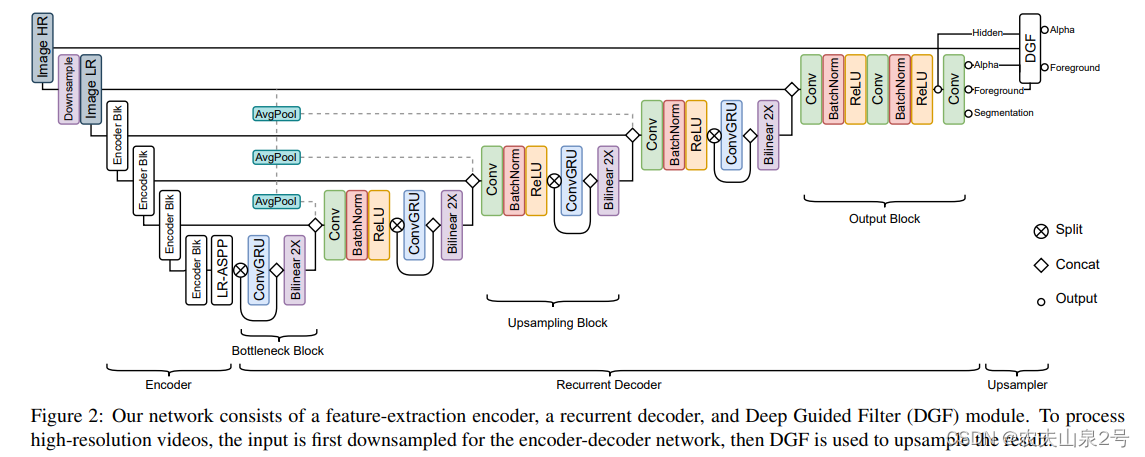
encoder
采用MobileNetV3-Large [15]作为我们高效的骨干网络,后面跟着MobileNetV3为语义分割任务提出的LR-ASPP模块。值得注意的是,MobileNetV3的最后一个块使用了扩张卷积而没有下采样步幅。编码器模块在单个帧上运行,并在1/2、1/4、1/8和1/16的尺度上提取特征,供循环解码器使用。
循环解码器
使用循环架构而不是注意力或简单地将多帧作为额外的输入通道进行前馈,原因有几个。循环机制可以在连续的视频流中自行学习保留和忘记哪些信息,而其他两种方法必须依靠固定的规则在每个间隔中删除旧信息并插入新信息到有限的内存池中。能够自适应地保留长期和短期时间信息的能力使循环机制更适合我们的任务。
我们的解码器在多个尺度上采用ConvGRU来聚合时间信息。我们选择ConvGRU是因为它比ConvLSTM更节省参数,因为它有更少的门。形式上,ConvGRU定义如下:
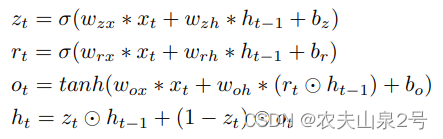
发现通过拆分和连接将ConvGRU应用于一半的通道是有效且高效的。这种设计有助于ConvGRU专注于聚合时间信息,而另一个拆分分支则将当前帧的空间特征向前传递。所有卷积都使用3×3内核,除了最后一个投影使用1×1内核。
DGF模块
我们采用[44]中提出的深度引导滤波器(DGF)进行高分辨率预测。当处理高分辨率视频时,我们会先将输入帧下采样,然后再通过编码器-解码器网络。然后,低分辨率的alpha、前景、最终隐藏特征以及高分辨率的输入帧被提供给DGF模块,以产生高分辨率的alpha和前景。整个网络进行端到端训练。
3. 训练
我们提出同时使用抠图和语义分割目标来训练我们的网络
数据集
视频包括各种运动,如汽车经过、树叶摇晃和摄像机移动。我们选择3118个不包含人类的剪辑,并从每个剪辑中提取前100帧。我们还按照[22]的方法爬取了8000张图像背景。这些图像有更多的室内场景,如办公室和客厅。我们在前景和背景上都应用运动和时间增强来增加数据多样性。运动增强包括仿射平移、缩放、旋转、剪切、亮度、饱和度、对比度、色调、噪声和模糊,这些变化会随着时间连续变化。运动采用不同的缓冲函数应用,使变化不总是线性的。增强还向图像数据集添加人工运动。此外,我们还在视频上应用时间增强,包括剪辑反转、速度变化、随机暂停和帧跳过。其他离散增强,如水平翻转、灰度和锐化,则始终应用于所有帧。
训练
我们的抠图训练分为四个阶段。它们旨在让我们的网络逐渐看到更长的序列和更高的分辨率,以节省训练时间。我们使用Adam优化器进行训练。所有阶段都使用批量大小B = 4,分布在4个Nvidia V100 32G GPU上。
stage1:
在VM上以低分辨率训练15个epoch,不使用DGF模块。我们设置一个短序列长度T = 15帧,以便网络能够更快地更新。MobileNetV3骨架使用预训练的ImageNet [32]权重初始化,并使用1e-4的学习率,而网络的其余部分使用2e-4。我们独立地在256和512像素之间采样输入分辨率的高度和宽度h,w。这使我们的网络对不同的分辨率和纵横比具有鲁棒性。
stage2:
将T = 50
stage3:
我们附加DGF模块并在VM上使用高分辨率样本训练1个epoch。由于高分辨率会消耗更多的GPU内存,序列长度必须设置得非常短。为了避免我们的循环网络过拟合到非常短的序列,我们在低分辨率长序列和高分辨率短序列上同时训练我们的网络。具体来说,低分辨率通道不使用DGF,T = 40,h,w∼(256,512)。高分辨率通道包含低分辨率通道,并使用下采样因子s = 0.25的DGF,Tˆ = 6和hˆ,wˆ∼(1024,2048)。我们将DGF的学习速率设置为2e-4,网络的其余部分设置为1e-5。
分割部分:
我们的分割训练在每次抠图训练迭代之间交错进行。我们在每个奇数迭代后对图像分割数据进行网络训练,在每个偶数迭代后对视频分割数据进行网络训练。分割训练应用于所有阶段。对于视频分割数据,我们使用与每个抠图阶段相同的B,T,h,w设置。对于图像分割数据,我们将它们视为仅包含1帧的视频序列,因此T0 = 1。这为我们提供了空间来应用更大的批量大小B0 = B×T。
4. 实验结果
与其他方法的比较
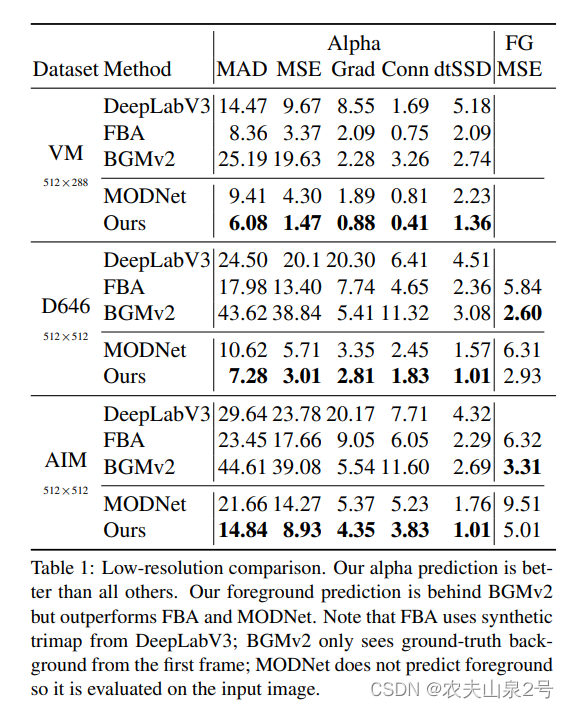
在真实场景
在图3a中,我们比较了所有方法的alpha预测,并发现我们的方法能更准确地预测细微的细节,如头发丝。在图3b中,我们对随机的YouTube视频进行实验。由于这些视频没有预先捕获的背景,我们从比较中删除了BGMv2。我们发现我们的方法对语义错误更具鲁棒性。在图3c和3d中,我们进一步比较了MODNet在手机和网络摄像头视频上的实时抠图。我们的方法能比MODNet更好地处理快速移动的身体部位。

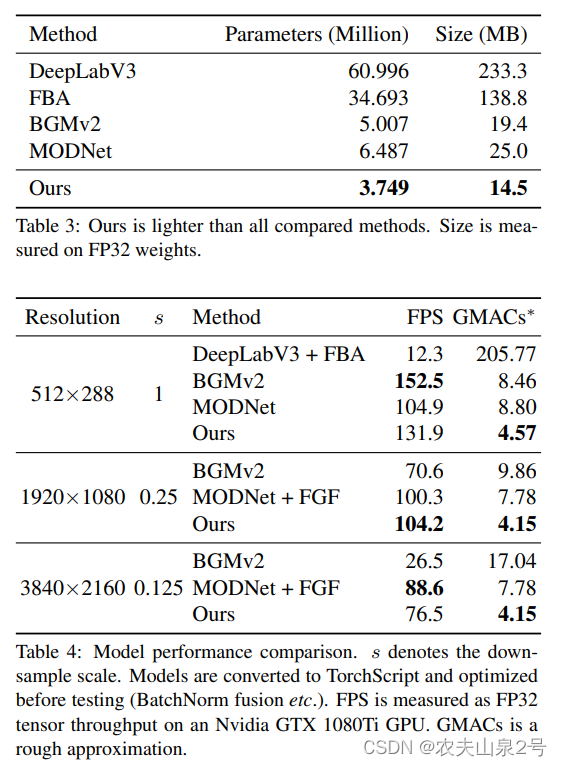
参数和速度
CONVGRU的作用
所有VM测试剪辑的平均alpha MAD指标随时间的变化。我们的模型在前15帧中的误差显著下降,然后指标保持稳定。即使使用邻帧平滑技巧,MODNet的指标也有很大波动。
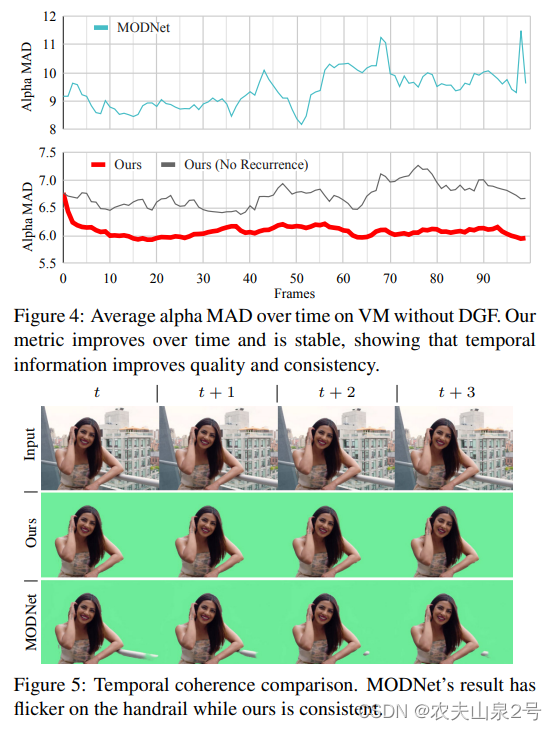
语义分割的作用
表5显示,当在仅包含人类和仅在人类类别上的COCO验证图像子集上进行评估时,我们的方法与语义分割方法一样鲁棒。我们的方法达到了61.50 mIOU,这在MobileNetV3和DeepLabV3在COCO上训练的性能之间是合理的,考虑到模型大小的差异。我们还尝试通过将α>0.5阈值化为二进制掩码来评估我们的alpha输出的鲁棒性,而我们的方法仍然达到了60.88 mIOU,表明alpha预测也是鲁棒的。















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









