







论文: Robust High-Resolution Video Matting with Temporal Guidance
1. 概要
大多数现有方法将视频数据视为一帧帧相互独立的图像加以处理。与此不同,本文利用一个循环架构来发掘视频中帧与帧间的时间信息,显著提高了时间一致性和抠图质量。同时,提出一种新的训练策略,同时用匹配和语义分割目标来训练网络,使模型的鲁棒性得到显著提高。此外,我们的方法不需要任何辅助输入,因此它可以在现有的人像抠图领域中得到广泛应用。
2. 简介
Matting(抠图)是一个从输入图像中预测前景和 alpha 图的过程。通常而言,一张图片
I
I
I 可视作前景
F
F
F 和背景
B
B
B 的线性组合:
I
=
α
F
+
(
1
−
α
)
B
I = \alpha F + (1-\alpha)B
I=αF+(1−α)B
其中,
α
\alpha
α 为透明度系数。若已确定
F
F
F 和
α
\alpha
α,则可实现任意背景替换的功能。背景替换有着许多实际的应用场景,如视频会议和娱乐视频的创建。目前用于实现背景替换的神经网络存在着健壮性不足和替换的视觉效果欠佳(看起来假)的问题。因此,论文聚焦于提升模型的抠图质量及其健壮性。
大多数现有方法尽管是为视频应用而设计的,但仍将视频划分为单帧,独立地对每帧图像进行处理。这些方法忽略了视频帧序列间时间信息,而有效利用视频的时序信息可有效提高视频匹抠图的最终效果:
- 让预测结果更加一致。模型可以看到多个帧和它自己的预测,这能够减少抖动和提高感知质量;
- 时序信息可提高抠图的鲁棒性。在单帧模糊(前景与背景过于相似)的情况下,模型可通过参考前面的帧来更好地猜测边界;
- 时序信息使模型随着时间的推移了解更多背景信息,而更好地了解背景可以简化抠图任务。当相机移动时,由于视角的变化,人像的背景将被揭示。即使相机是固定的,由于人像的移动,背景信息依然能够被捕获。
基于以上原因,论文提出一种循环架构来利用时序信息。该方法显著提高了抠图的质量和时间的关联性。该方法可以应用于所有视频,而不需要任何辅助输入(如人工注释的 trimap 图或预先捕获的背景图)。
此外,论文使用了一种新的模型训练策略:同时再humanmatting datasets和segmentation datasets上训练网络。多数现有方法需要自行合成数据集进行训练(一般数据集只提供前景图和 alpha 图),而这些合成的图片往往看起来比较假。考虑到抠图任务与分割任务的密切相关性,也使用segmentation datasets对网络进行训练。
所提方法是目前的 SOTA 模型,更为轻量,速度更快。模型只使用了 58% 的参数,可在 Nvidia GTX1080Ti GPU上处理 4K(76 FPS)和 HD(104 FPS)的实时高分辨率视频。
3. 模型结构
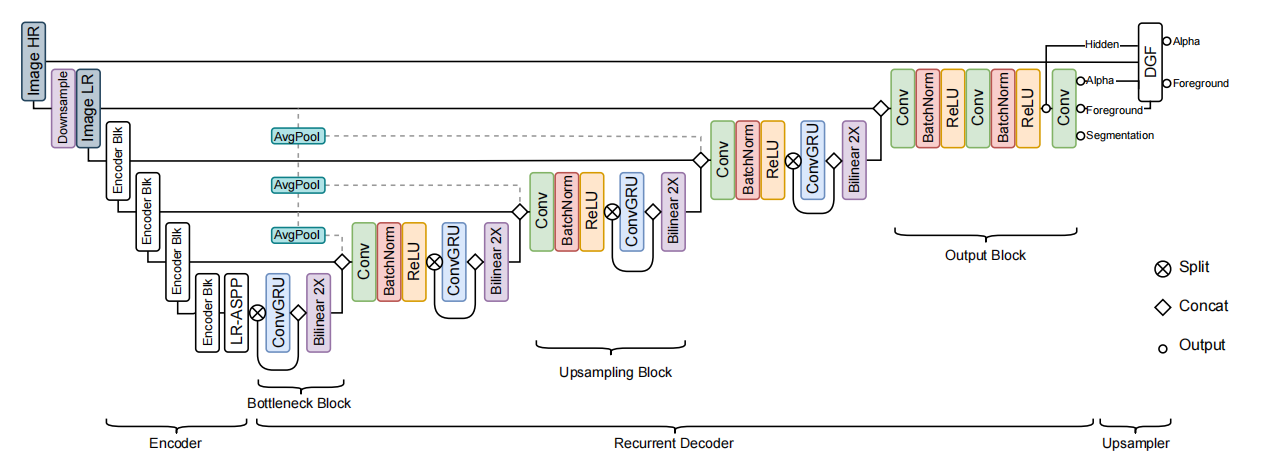
网络模型结构如下图所示,主要由三部分组成:编码器(提取每帧图像的信息)、循环解码器(聚合时序信息)和深度引导滤波器模块(实现高分辨率的上采样)。
-
编码器
编码器主要用来提取特征。采用MobileNetV3-Large作为backbone,后接LR-ASPP模块。编码器对单个帧进行操作,并以 1/2、1/4、1/8 和 1/16 的尺度分别提取特征。 -
循环解码器
循环机制可自主决定视频流中相关信息的记忆和遗忘,自适应地保持长期和短期时间信息。如上图所示,在解码器中使用了多个尺度的ConvGRU来聚合时间信息。整个解码器部分由一个 Bottleneck block、Upsampling block 和一个 Output block 组成。
- Bottleneck block
该模块位于LR-ASPP模块后,对 1/16 的特征图进行处理。该模块中的ConvGRU层通过分割只在一半的通道上进行操作,输出的结果再与另一半的通道进行拼接。该模块可减少参数量和计算量。- Upsampling block
对 1/8 、1/4、1/2 的特征图分别进行上采样。首先,拼接双线性插值后的输出和对应编码器的输出成为模块输入,再使用 2 × 2 2 \times 2 2×2 平均池化。其次,使用卷积、BN 和 ReLU 以实现特征的合并与信道的缩减。最后,执行与 Bottleneck block 模块相同的ConvGRU操作。- Output block
不使用ConvGRU,只使用普通卷积来生成结果。首先,拼接双线性插值后的输出和对应编码器的输出成为模块输入(注意不进行池化操作)。然后,使用 2 个重复的卷积、BN 和 ReLU 堆栈来生成最终的隐藏特征。最后,将这些特征映射(即最后一个卷积层)成为输出,包括 alpha 预测(1 通道)、前景预测(3 通道)和 分割预测。
- 深度引导滤波器模块(DGF)
DGF 用来生成高分辨率的预测结果。其输入为高分辨率的输入帧(高清原图)、最终的隐藏特征以及 Output block 生成的 alpha 预测图和前景预测图(粗糙)。其输出为高分辨率的 alpha 预测图和前景预测图。此外,关于 DGF 模块还需注意以下两点:
- 如网络结构图所示,如网络接收的是高分辨率原图,需先经过下次样处理成为低分辨率图片;
- DGF 模块是可选的,如对输出分辨率要求不高,可不使用该模块。
4. 网络训练
同时在 Matting Datasets 和 Segmentation Datasets 上对网络进行训练,其主要原因如下
- Human matting 任务与 human segmentation 任务关联紧密。Trimap-based 和 background-based 的抠图算法会在输入中给出一些附加信息,RVM 算法则没有。RVM 算法要求网络能够从语义上理解场景,在定位人像时具有鲁棒性。(需要语义分割数据集)
- 现有的抠图数据集一般只提供前景图和 alpha 图,背景图则需自行合成。由于光线等诸多原因,合成图片可能看起来比较假。此外,语义分割数据集包含多样的真实场景,在该数据集上进行训练可在一定程度上防止过拟合。
- 语义分割任务中可用的数据集更多。
4.1 数据集
- Matting Datasets
视频 — VM
共包含 484 个 4K/HD 视频,将之划分为训练集/验证集/测试集(475/4/5)。
图像 — D646 和 AIM
筛选合并两个数据集中包含人像的图像,而后将之将之划分为训练集/验证集(420/15)。21 = 11(D646) + 10(AIM)张测试图片。
- 背景
- 视频背景:3118 个视频,视频中包含大量动作(如汽车驶过、树叶飘落和相机移动等),取每个视频的前 100 帧;
- 图片背景:8000 张图片,多为室内背景(如办公室和客厅等)。
- 数据增强(运动和时间)
- 运动增强包括仿射平移、缩放、旋转、透明、亮度、饱和度、对比度、色调、噪声和模糊,这些都会随着时间的推移而不断变化。该运动采用了不同的缓动函数,这样的变化并不总是线性的。此外还为图像数据集添加了人工运动。
- 对视频数据应用时间增强,包括剪辑反转、速度变化、随机暂停和帧跳跃。相同的离散增强操作(水平翻转、灰度和锐化)应用于所有帧。
- Segmentation Datasets
- YouTubeVIS:选择 2985 张包含人像的图片,进行数据增强(不使用运动增强);
- COCO:选择 64111 张包含人像的图片,进行数据增强(不使用运动增强);
- SPD:选择 5711 张包含人像的图片,进行数据增强(不使用运动增强)。
4.2 训练过程
训练过程可分为四个阶段,采用 Adam 优化器,通过训练让网络逐步看到更长的序列和更高的分辨率,节省训练时间。
- Stage 1:在低分辨率的 VM 数据集上训练 15 个 epoch,不使用 DGF 模块
- 序列长度 T T T:15;
- Backbone:MobileNetV3,使用预训练的 ImageNet 权值;
- 学习率:backbone 部分取 1 e − 4 1e^{-4} 1e−4,网络其它部分取为 2 e − 4 2e^{-4} 2e−4;
- 输入尺寸:(250,512)。
- Stage 2:在低分辨率的 VM 数据集上训练 2 个 epoch,不使用 DGF 模块。该阶段训练目的是使网络看到更长的序列,学习长期依赖关系
- 置序列长度 T = 50 ~T = 50 T=50;
- 学习率减半;
- 其它参数同 Stage 1。
- Stage 3:在高分辨率的 VM 数据集上训练 1 个 epoch,使用 DGF 模块。同时在短的高分辨率序列和长的低分辨率上训练网络
- 低分辨率:
(1) T = 50 ~T = 50 T=50;
(2) h , w ∼ ( 236 , 512 ) ~h, w \sim (236, 512) h,w∼(236,512);
(3) 不使用 DGF 模块- 高分辨率:
(1) T ^ = 6 ~\hat{T} = 6 T^=6;
(2) h ^ , w ^ ∼ ( 1024 , 2048 ) ~\hat{h}, \hat{w} \sim (1024, 2048) h^,w^∼(1024,2048);
(3) 使用下采样因子 s = 0.25 s=0.25 s=0.25 的 DGF 模块;
(4) DGF 模块学习率取 2 e − 4 2e^{-4} 2e−4,其它部分取 1 e − 5 1e^{-5} 1e−5。
-
Stage 4:在 D646 和 AIM 组成的数据集上训练 5 个 epoch。将解码器的学习率提高到 5 e − 5 5e^{−5} 5e−5,以使网络适应并保持 Stage 3 的其他设置。
-
Segmentation:Segmentation training 在 matting training 的回合间交错进行。在 matting training 的第奇数个回合后使用 imgae segmentation training,第偶数个回合后使用 video segmentation training。
5. 实验
官方网页:含论文、源码和Demo。
6. 其它
- VM 数据集只提供了视频的前景图和 alpha 图,需要与视频背景图(DVM)进行合成;
- 选择 D646 和 AIM 中包含人的图像合成一个新的数据集 IM(ImageMatte);















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









