









散列表为什么诞生,它用于做什么?
先说说数组:数组的优点是查找比较快,但是添加和删除效率比较低。
再说说链表:链表的优点是添加和删除效率比较快(相对于数组),但是遍历需要一个指针从头节点往后找。
两者都各有优点和缺点,那么有没有一种方法,既可以添加和删除比较快,查找元素也比较快呢?
于是,便引出了我们今天的主角----散列表(hash表)。
其实散列表在java里还是比较常见的,HashMap就实现了散列表。

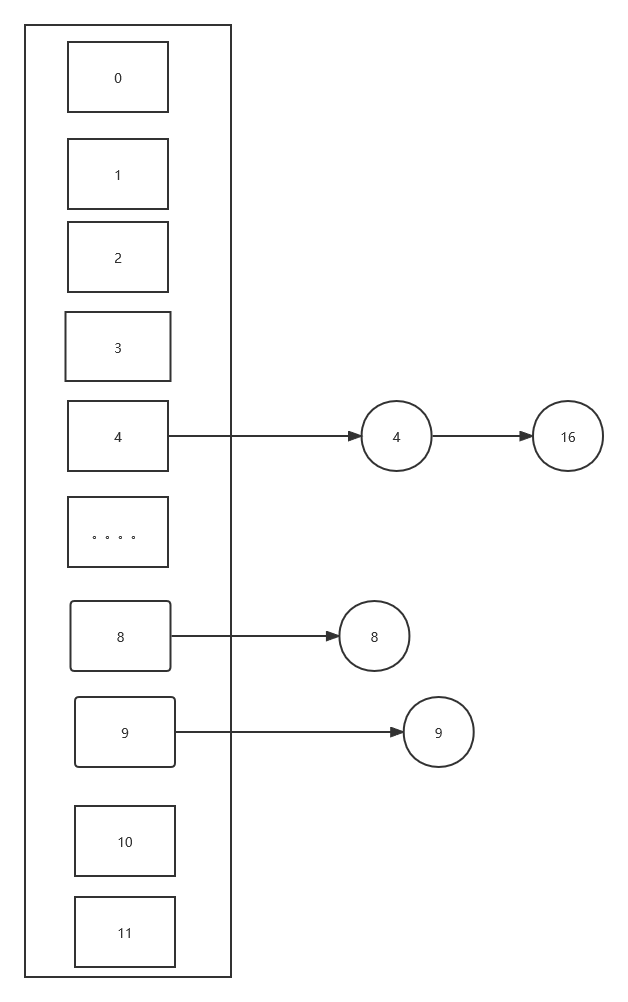
如上图我们依次将这些数对 12取余,将这些数添加到对应的关键字里。(当然除了取余还有很多种方法求出关键数,这里我们就用取余法)
散列冲突及解决
但是当我们添加16时,我们发现,16和4在散列表的位置冲突了,我们必须给16安排到别的位置去。
有以下方法解决:
1.开放定址法(再散列法):
基本思想:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。 这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。
1.线性探测再散列:
dii=1,2,3,…,m-1 冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
2.二次探测再散列:
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 ) 冲突发生时,在表的左右进行跳跃式探测,比较灵活。
3.伪随机探测再散列:
di=伪随机数序列。 具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点。上面的方法不过过多赘述了,接下来我们来说一个经常使用的方法,也是hashmap(1.7)的散列表的创建形式:
数组+链表法创建散列表
上面我们容易发生hash冲突的原因就是一个关键字只能储存一个元素。那么我们结合数组和链表,每个数组元素储存一个链表不就解决了这个问题嘛。
发生碰撞,只需要把元素放到链表的下一位即可。
另外,散列表还可以作为缓存缓存我们的数据,我们实现对员工信息查询的功能,不需要每次都向数据库查询,我们可以把常用数据储存在散列表里,下次查询就可以直接查询散列表。















 1234
1234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









