










 本文通过sklearn库演示了感知机在二分类任务中的应用过程。从生成样本数据开始,经过训练获得感知机模型,并最终评估其分类性能。
本文通过sklearn库演示了感知机在二分类任务中的应用过程。从生成样本数据开始,经过训练获得感知机模型,并最终评估其分类性能。
一、感知机(perceptron)
- 感知机简介:
感知机(perceptron)是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别。感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面。感知机是一种线性分类模型。
感知机实际上表示为输入空间到输出空间的映射函数,如下所示:

其中, 和
和 称为感知机的模型参数,
称为感知机的模型参数, 叫做权值(weight)或权值向量(weight vector),
叫做权值(weight)或权值向量(weight vector), 叫做偏置(bias),
叫做偏置(bias), 是和
是和 的内积,
的内积, 是符号函数,其定义形式如下:
是符号函数,其定义形式如下:

虽然有了感知机的定义形式,也知道了它的作用,但这样看起来仍然不直观,现在我用sklearn库来做一个二维空间的感知机来演示一下感知机的实际效果。
首先,使用sklearn中的make_classification来生成一些用来分类的样本。p er
from sklearn.datasets import make_classification
x,y = make_classification(n_samples=1000, n_features=2,n_redundant=0,n_informative=1,n_clusters_per_class=1)
#n_samples:生成样本的数量
#n_features=2:生成样本的特征数,特征数=n_informative() + n_redundant + n_repeated
#n_informative:多信息特征的个数
#n_redundant:冗余信息,informative特征的随机线性组合
#n_clusters_per_class :某一个类别是由几个cluster构成的 make_classification默认生成二分类的样本,上面代码中,x代表了生成的样本空间(特征空间),y代表了生成样本的类别,使用1和0分别表示正例和反例:
y=[0 0 0 1 0 1 1 1... 1 0 0 1 1 0]
然后将生成的样本分为训练数据和测试数据,并将其中的正例和反例也分开:
#训练数据和测试数据
x_data_train = x[:800,:]
x_data_test = x[800:,:]
y_data_train = y[:800]
y_data_test = y[800:]
#正例和反例
positive_x1 = [x[i,0] for i in range(1000) if y[i] == 1]
positive_x2 = [x[i,1] for i in range(1000) if y[i] == 1]
negetive_x1 = [x[i,0] for i in range(1000) if y[i] == 0]
negetive_x2 = [x[i,1] for i in range(1000) if y[i] == 0]
接下来,就开始真正的分类工作,首先定义一个感知机(percetpron):
from sklearn.linear_model import Perceptron
#定义感知机
clf = Perceptron(fit_intercept=False,n_iter=30,shuffle=False)
#使用训练数据进行训练
clf.fit(x_data_train,y_data_train)
#得到训练结果,权重矩阵
print(clf.coef_)
#输出为:[[-0.38478876,4.41537463]]
#超平面的截距,此处输出为:[0.]
print(clf.intercept_)
此时,我们已经得到了训练出的感知机模型参数,那么这个感知机的分类能力怎么样呢?我们利用测试数据对其进行验证。
#利用测试数据进行验证
acc = clf.score(x_data_test,y_data_test)
print(acc)
#得到的输出结果为0.995,这个结果还不错吧。
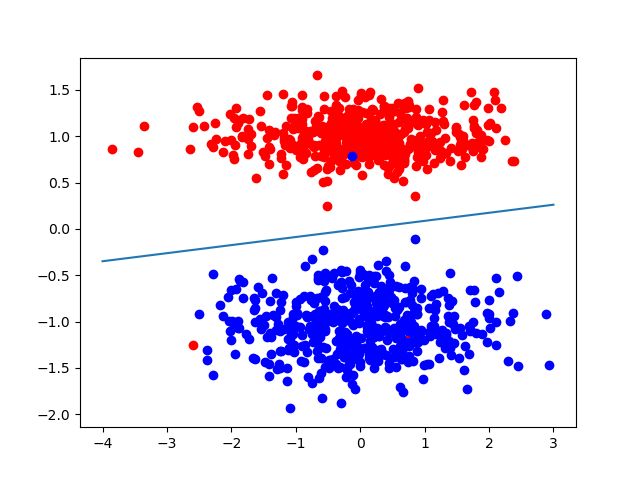
最后,我们将结果用图形显示出来,直观地看一下感知机的结果:
from matplotlib import pyplot as plt
#画出正例和反例的散点图
plt.scatter(positive_x1,positive_x2,c='red')
plt.scatter(negetive_x1,negetive_2,c='blue')
#画出超平面(在本例中即是一条直线)
line_x = np.arange(-4,4)
line_y = line_x * (-clf.coef_[0][0] / clf.coef_[0][1]) - clf.intercept_
plt.plot(line_x,line_y)
plt.show()
得到的图如下所示:

















 5220
5220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









