










微服务架构下的运维知识体系
基础设施与应用的标准化
微服务技术体系下的应用指的是以什么呢?
软件架构服务化的过程,就是我们根据业务模型进行细化的过程,在这个过程中切分出一个个具备不同职责的业务逻辑模块,然后每个微服务模块都会提供相对应业务逻辑的服务化接口。

应用模型及关系模型的建立
应用作为微服务架构的核心,在实际的运维部署中,为满足对外提供完整业务功能还需要与周边的应用,相对独立的中间件,基础设施打交道,如服务器,存储,缓存,消息对象,注册中心,配置中心等。那么以应用为中心的运维信息体系是什么样的呢?如下图所示:
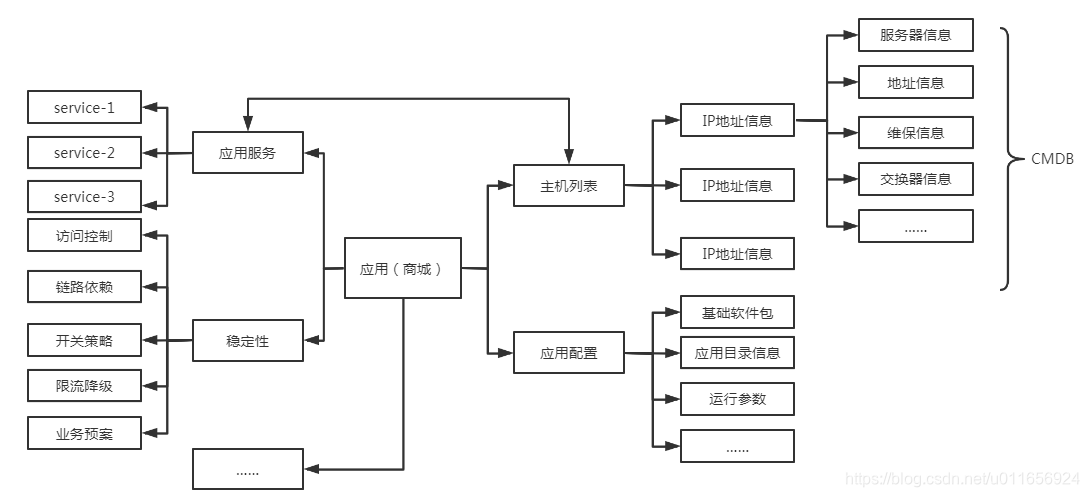
梳理运维信息模型,那么如何建立起这样一套完备的信息标准呢?
运维信息标准化建立,遵循如下的一些标准化动作
- 识别对象
- 识别对象属性
- 识别对象关系
- 识别对象使用场景
遵照上面的步骤,接下来分别对基础设施层与中间件层进行标准化识别动作。
基础设施层标准化
- 第一步:识别实体对象,主要有服务器、网络、IDC、机柜、存储、配件等。
- 第二步:识别对象的属性,比如服务器就会有 SN 序列号、IP 地址、厂商、硬件配置(如 CPU、内存、硬盘、网卡、PCIE、BIOS)、维保信息等;网络设备如交换机也会有厂商、型号、带宽等信息。
- 第三步:识别对象之间的关联关系,比如服务器所在的机柜,虚拟机所在的宿主机、机柜所在 IDC 等简单关系;复杂一点就会有核心交换机、汇聚交换机、接入交换机以及机柜和服务器之间的级联关系等,这些相对复杂一些,也就是我们常说的网络拓扑关系。
- 第四步:识别对象使用场景,静态的对象与对象关系建立起来之后,真正对运维有价值的是这些对象主体在使用场景中的动态信息,比如服务器的采购,入库,上架,下架,运行过程中的故障,告警等等。
应用层面的标准化
-
第一步:识别实体对象,应用实体对象是由应用架构师识别,在微服务架构中,通常包括微服务,API等等。
-
第二步:识别对象的属性,包括业务属性与运维属性,其中运维属性包括:
应用元数据:也就是简单直接地描述一个应用的信息,如应用名、应用 Owner、所属业务、是否核心链路应用以及应用功能说明等,这里的关键是应用名。
应用代码属性:主要是编程语言及版本(决定了后续的构建方式),git地址;
应用部署模式:涉及到基础软件包,如语言包 Java、C++、Go 等;容器如 Tomcat、JBoss 等;
应用运行脚本:如启停脚本、健康监测脚本;
应用运行时的参数配置:如运行端口、Java 的 JVM 参数 GC 方式、新生代、老生代、永生代的堆内存大小配置等; -
第三步:识别对象之间的关联关系,比如服务器所在的机柜,虚拟机所在的宿主机、机柜所在 IDC 等简单关系;复杂一点就会有核心交换机、汇聚交换机、接入交换机以及机柜和服务器之间的级联关系等,这些相对复杂一些,也就是我们常说的网络拓扑关系。
也就是应用与外部的关系,概括起来有三大类:如下图所示
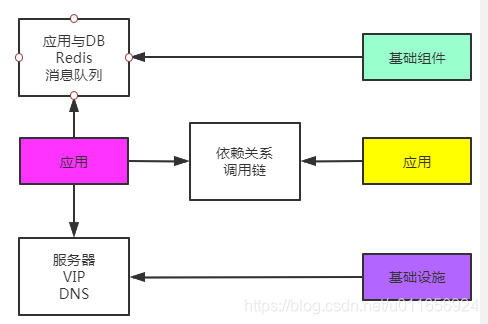
-
第四步:识别对象使用场景,这个就会比较多了,比如应用创建、持续集成、持续发布、扩容、缩容、监控等;再复杂点
的比如容量评估、压测、限流降级等。
基础架构标准化
分布式架构基组件对象分析
- 分布式服务化框架:业界开源产品比如 Dubbo、Spring Cloud 这样的框架;
- 分布式缓存及框架:业界如 Redis、Memcached,框架如 Codis 和 Redis Cluster;
- 数据库及分布式数据库框架,这两者是密不可分的,数据库如 MySQL、MariaDB 等,中间件如淘宝 TDDL(现在叫 DRDS)、Sharding-JDBC 等。当前非常火热的 TiDB,就直接实现了分布式数据库的功能,不再额外选择中间件框架;
- 分布式的消息中间件:业界如 Kafka、RabbitMQ、ActiveMQ 以及 RocketMQ 等;
- 前端接入层部分:如四层负载 LVS,七层负载 Nginx 或 Apache,再比如硬件负载 F5等;
没有统一技术标准约束会有什么问题
-
开发层面:每个开发团队使用的技术栈不统一,每个团队都需要将大量的精力应用到具体的技术上,由于技术不统一,每个团队在技术所采的坑没法在团队之间共享,存在大量技术重复性投入。
-
运维层面:开发技术标准统一,导致基础组件五花八门,运维的工作难度非常大。
所有综合上面两个因素,我们需要在对分布式架构组件进行统一的技术选择与版本选择,也技术基础架构标准化的动作。
第二作为运维还需要将这些选定的标准化基础组件,以方便,服务化的形式提供出来。
比如以Redis为例
创建和容量申请;
容量的扩容和缩容,新增分片的服务发现及访问路由配置;
运行指标监控,如 QPS、TPS、存储数据数量等等;
主备切换能力等等;
这些日常的操作都需要Redis提供的基本运维命令来提供,但这些基础的操作命令对运维非常不友好,需要将这些基础的Redis操作进行封装,服务化,以提供运维的效率。
运维架构建设方法
运维架构的规划从应用生命周期入手,划分阶段,提炼属性,理清关系,固化基础信息,实现运维场景。
微服务架构下,一切要以应用核心。因此,我们就找到了整个运维体系,或者说软件运行阶段的核心对象,那就是应用。
应用的生命周期可以分为如下几个阶段:

- 应用的创建阶段
确认应用的基础信息,以及应用与基础服务之间的关系。应用基础信息就是上面讲到的应用信息标准化相关内容。同时在这应用创建这个过程中,会开启其他的基础服务的生命周期,包括应用用到的缓存,DB,消息队列等,还包括DNS服务,VIP服务等。
- 应用研发阶段
应用的研发阶段主要是业务逻辑实现和验证的阶段。针对业务逻辑层面的场景就是开发代码和质量保证,但是这个过程中就会涉及到代码的提交合并、编译打包以及在不同环境下的发布部署过程。同时,开发和测试在不同的环境下进行各种类型的测试,比如单元测试、集成测试以及系统测试等等,这整个过程就是我们常说的持续集成。
- 应用上线阶段
这是个过渡阶段,从应用创建过渡到线上运行。创建阶段,应用的基础信息和基础服务都已经到位,接下来就是申请到应用运行的服务器资源,然后将应用软件包发布上线运行。
- 应用运行阶段
这个阶段,应用最重要的属性就是应用本身以及相关联的基础服务的各项运行指标。我们就需要制定每个运维对象的 SLI、SLO 和 SLA,同时要建设能够对这些指标进行监控和报警的监控体系。
- 应用销毁阶段
如果应用的业务职责不存在了,应用就可以下线销毁了。但是这里不仅仅是应用自身要销毁,我们说应用是整个运维体系的核心,所以围绕着某个应用所产生出来的基础设施、基础服务以及关联关系都要一并清理,否则将会给系统中造成许多无源(源头)的资源浪费。
CMDB与应用配置管理
CMDB 是面向资源的管理,应用配置是面向应用的管理
CMDB 是面向资源的管理,是运维的基石
那么基础资源如服务网,网络设备这样肉眼可见的资源如何规划与管理呢?这个分析的过程与前面讲运维模型设计的思路是一样,首先确定实体对象,确定对象属性,确定对象关系,分析对象使用场景。
- 第 1 步,把服务器、网络、IDC、机柜、存储、配件等这几大维度先定下来;
- 第 2 步,把这些硬件的属性确定下来,比如服务器就会有 SN 序列号、IP 地址、厂商、硬件配置(如 CPU、内存、硬盘、网卡、PCIE、BIOS)、维保信息等等;网络设备如交换机也会有厂商、型号、带宽等等;
- 第 3 步,梳理以上信息之间的关联关系,或者叫拓扑关系。比如服务器所在机柜,虚拟机所在的宿主机、机柜所在 IDC 等简单关系;复杂一点就会有核心交换机、汇聚交换机、接入交换机以及机柜和服务器之间的级联关系;
- 第 3.5 步,在上面信息的梳理过程中肯定就会遇到一些规划问题,比如,IP 地址段的规划,哪个网段用于 DB,哪个网段用于大数据、哪个网段用于业务应用等等,再比如同步要做的还有哪些机柜用于做虚拟化宿主机、哪些机柜只放 DB 机器等。
应用集群分组管理
- 多环境问题
我们常见的环境会有开发联调环境、集成测试环境、预发环境、线上环境等等。后面我们讨
论持续交付时会讲到,实际场景下所需要的环境会更多。 - 多 IDC 问题
对于大型互联网业务,会做业务单元化,或者有海外业务拓展需求的场景,我们会在多个IDC 机房部署应用,应用代码是相同的,但是配置可能会不同。 - 多服务分组问题
由此我们总结运维的技术体系
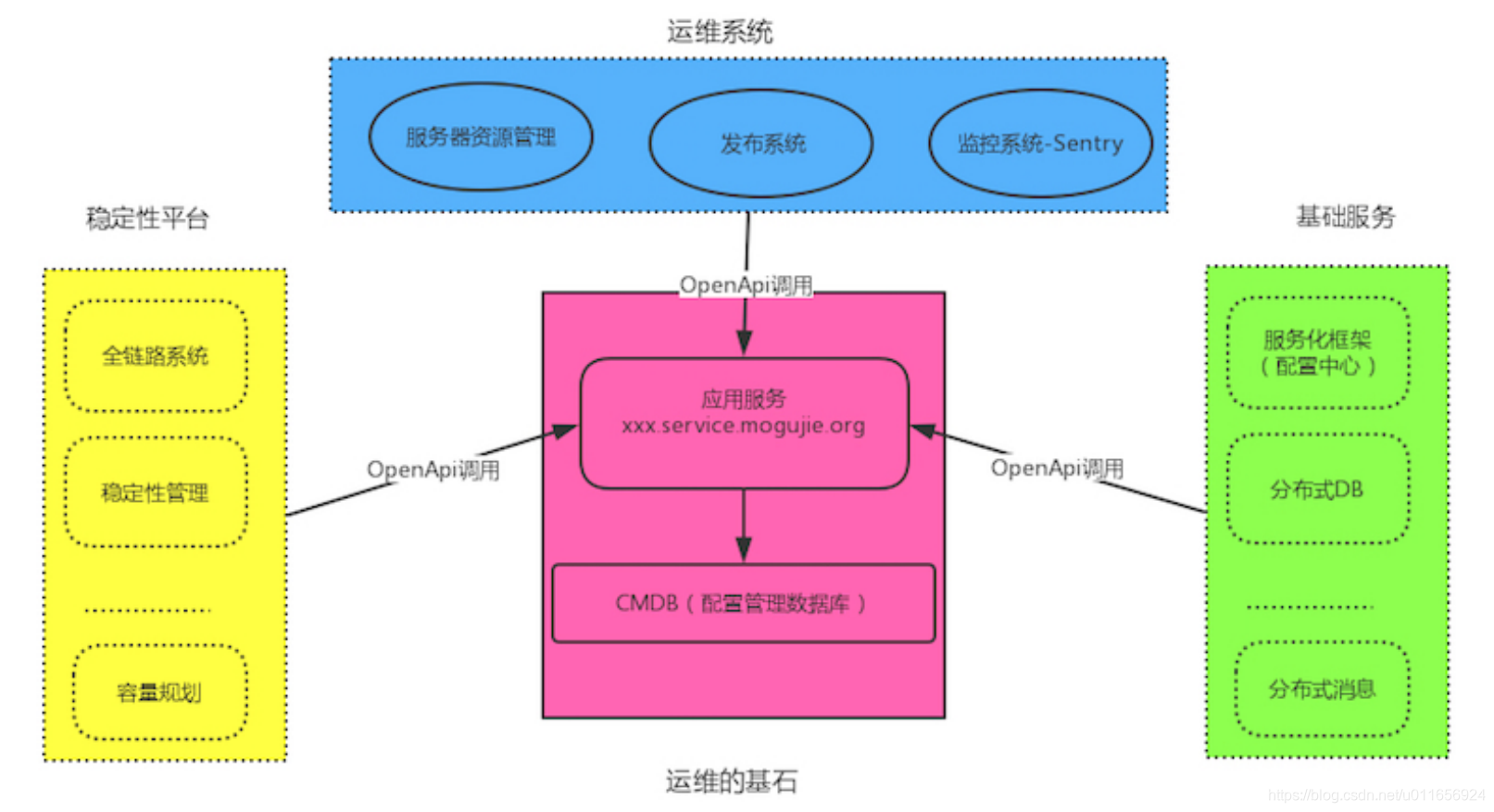
运维组织架构
在上面的章节我们介绍了运维知识体系,以及运维架构落地的一些方法论。大致来说这些就是运维工作的基本对象了,那么面临这样的工作职责,需要配套怎样的运维团队呢?
Netflix 给我们的启示
Netflix的做法就是在在提供基础服务能力的同时,提供对应的自助化运维能力。也就是说,开发人员可以在这样一个平台上完成自己想要做的任何运维操作,而不再依赖运维的人。我们可以将技术能力与运维能力统一纳入到技术中台这样的一个范围。使得运维和整个技术架构体系的融合,一定不要割裂两者。同时,还要注意不仅仅是促进组织架构层面的融合,最重要的是要促进职能协作上的融合。
这样一个技术中台组织的目标就是:为业务开发提供高效,稳定,低成本的开发与运维支撑。
结合这个目标,技术中台团队应该负责落实的事项如下:
- 运维基础平台体系建设
这块主要包括我们前面提到的标准化体系以及 CMDB、应用配置管理、DNS 域名管理、资源管理等偏向运维自身体系的建设。这一部分是运维的基础和核心,我们前面讲到的标准化以及应用体系建设都属于这个范畴。 - 分布式中间件的服务化建设
在整个技术架构体系中,分布式中间件基础服务这一块起到了支撑作用。这一部分的标准化和服务化非常关键,特别是基于开源产品的二次开发或自研的中间件产品,更需要有对应的标准化和服务化建设。这也是我们无意识地割裂运维与技术架构行为的最典型部分,这里容易出现的问题。 - 持续交付体系建设
持续交付体系是拉通运维和业务开发的关键纽带,是提升整个研发团队效率的关键部分。这个部分是整个软件或应用的生命周期的管理体系,包括从应用创建、研发阶段的持续集成,上线阶段的持续部署发布,再到线上运行阶段的各类资源服务扩容缩容等。开发和运维的矛盾往往比较容易在这个过程中爆发出来,但是这个体系建设依赖上面两部分的基础,所以要整体去看。 - 稳定性体系建设
软件系统线上的稳定性保障,包括如何快速发现线上问题、如何快速定位问题、如何快速从故障中恢复业务、如何有效评估系统容量等等。这里面还会有一些运作机制的建设,比如如何对故障应急响应、如何对故障进行有效管理、如何对故障复盘、如何加强日常演练等等。同样,这个环节的事情也要依赖前两个基础体系的建设。 - 技术运营体系建设
技术运营体系也是偏运作机制方面的建设,最主要的事情就是确保我们制定的标准、指标、规则和流程能够有效落地。这里面有些可以通过技术平台来实现,有些就需要管理流程,有些还需要执行人的沟通协作这些软技能。
运维岗位细分
- **基础运维:**包括 IDC 运维、硬件运维、系统运维以及网络运维;
- **应用运维:**主要是业务和基础服务层面的稳定性保障和容量规划等工作;
- **数据运维:**包括数据库、缓存以及大数据的运维;
- **运维开发:**主要是提供效率和稳定性层面的工具开发
谷歌的 SRE(Site Reliability Engineer)
在谷歌SRE的定位是:通过软件工程的方式开发自动化系统来替代重复和手工操作。
SRE,直译过来是网站稳定性工程师。表面看是做稳定的,但是我觉得更好的一种理解方式是,以稳定性为目标,围绕着稳定这个核心,负责可用性、时延、性能、效率、变更管理、监控、应急响应和容量管理等相关的工作。
分解一下,这里主要有“管理”和“技术”两方面的事情要做:
管理体系上,涉及服务质量指标(SLI、SLA、SLO)、发布规则、变更规则、应急响应机制、On-Call、事后复盘机制等一系列配套的管理规范和标准制定等。
技术体系上,以支持和实现上述标准和规范为目标,涉及自动化、发布、监控、问题定位、容量定位,最终以电子流程串联各个环节,做到事件的闭环。


















 29
29

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











