






1.工具Memcached Daemon,如果当生成很多无需每次请求都更改的动态内容,可以将php等代码生成的html缓存起来,而不用像通常那样用户每次访问foo.php,都需要重新解释代码然后重新生成html。比如维基百科,看的人肯定比写的人多,因此只需要等有人编辑后才需要用php之类的程序重新生成html。
2.以下书籍将何为可规模性及如何实现可规模性

3.构建RAID,有不同的RAID级,比如RAID0,硬盘分割,可以让数据一半放在硬盘A上,另一半放在硬盘B上,这能增加运行效率。
4.垂直规模化就是指提升cpu速度,存储容量等等,但这会受现实世界的限制,cpu在这个时期内总有最快速度上限。
而水平规模化,就是购买很多廉价服务器,然后通过软件设计,将负载分到这些服务器上。比如google,当你使用google搜索时,你的请求任务不是发送给一台服务器,而是被分成多个小块,然后把各个小块的工作分到多个服务器上去处理。开源软件Hadoop,它能让你实现所谓的mapreduce,这是一种计算机科学编程技术,它能将问题分解成小块分出
5.一些软件可以用于缓存解释php文件完成后生成的html,来直接提供给用户,避免每次用户访问都需要服务器重新解释一次。

6.当我们在代码中加入这些东西后,接下来要做的就是将代码分到多台服务器中去。我们现在有一个CDN服务器供视频使用,还有一个CDN服务器待命随时可以分担流量。
SSH到cloud.cs75.net时也有多个登陆服务器,在登录时有时会到login0,有时会到login1,如果我们开启了的话甚至可能到login2 ,login3,login4等等,这些都是配置相同的不同虚拟机,都可以登陆到你的帐户上(你的文件夹等等),但实际上他们是不同的虚拟机,并且一般都在不同的物理机器上。
此时就有出现问题了,当你SSH到cloud.cs75.net时,我们会将你的通信发送到其中一个机器,这就要使用所谓的负载均衡器,很多大流量网站都用这个。
使用这个技术的原因一,比如哈佛大学某个课程有两个班总共700多个学生,在项目提交当晚,多VM机制能帮助我们提高性能,这样大家的响应时间会更快。
原因二,如果出了什么漏子,可能有人跑了死循环让其中某台服务器挂掉,我们仍然需要整体能够顺利运行,所以说负载均衡还能有效实现冗余。
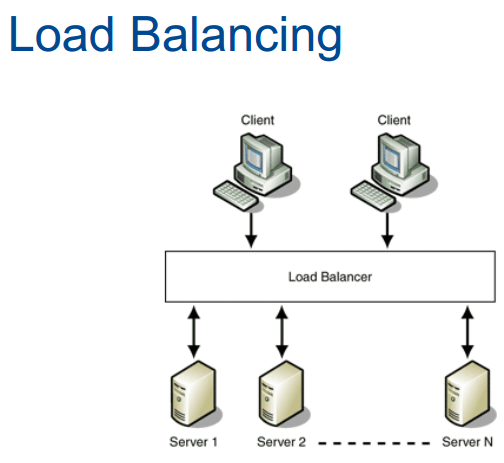
当某用户通过因特网连接到这里,然后回到下图黑箱中,即负载均衡器,在负载均衡器之后的就是N台web服务器。然后这个负载均衡器是使用的轮询调度,也就是说第一个请求分配到srv1 第二个请求分配到sev2这样。当然还有更好的分配方法,而这里用的是轮询调度这个分配方法。
但如何实现黑箱中的负载均衡呢,肯定不会仅仅是维持计数功能这么简单,他是如何接受请求,检查计数,然后发送到别的服务器。DNS是一种选择,第一讲谈到过了A记录和CNAME记录,域名映射到特定IP地址。
还可以使用虚拟IP地址,这也是哈佛用的方法,当SSH到cloud.cs75.net,通过TCP/IP协议会到达一个称为代理的虚拟机,这是一台运行linux的虚拟机,上面有款免费软件叫HAProxy (high-availability proxy),配置起来很贱,只用配置一个文本文件,这个软件会一直运行,在不同端口监听TCP连接,哈佛就开了三个端口,其中端口22是SSH,80是web, 443是SSL。因此看cloud.cs75.net的IP地址它不是映射到login1或login0,而是到所谓的代理装置,也即是一台运行HAProxy的Linux机器,它实现了轮询调度的功能,该软件让你能够用TCP连接到他,并且他会了解到用户需要端口22,而我们有两台提供端口22服务的VM也即login0和login1,因而会通过轮询调度向login0或者login1建立TCP连接,基本上,你又了某种隧道,这不是VPN,因为没有加密,只是创建一个TCP隧道,让用户的通信能通过黑箱,到达后端的某个设备上,然后用户就能得到相应的响应,可以是登陆提示或者属于该用户的主目录,也可以是web情况下的http响应。
这又什么好处呢,如果我们需要让其中一台vm停止运转,比如现在login1没了,我们让他停止为了升级其所在物理机器的内存,此时编辑负载均衡器的配置文件,在这之后所有人都不会被发往login1的ip地址,当晚上不再有学生连接进来的时候,就关掉电源,插入内存,还原配置文件等等,这样第二天新的通信又可以到这个vm上了。
这和nat很类似,但进行代理的并不是nat,有其他设备实现nat,下图黑箱之后应该还有个路由器来实现nat,图上没有画出来,黑箱不需要知道nat的存在。而且我们还有个应急方案,就是当vm负载过大时,会转发到我们在亚马逊ec2的账户,那里有vm,因此可以在用户毫不知情的情况下将用户的入站连接发给亚马逊ec2云服务器.
无需在单独的VM上运行SSL,有种专门为SSL计算优化的硬件,让所有人都能通过它连接到不同的设备上,也就是在这个硬件之后连接到其他后端服务器都无需经过加密,毕竟我们这里的可信度较高,不像因特网上的情况那么复杂。
关于轮询调度还有个问题,就是当人们的请求依次被发送不同服务器如此往复,这对SSH还行,因为大家的连接会保持固定,没人会关心具体连到哪个机器,但在本课中讲过session这是通过存放在/temp中的文件来实现的,这是本地硬盘上的一个目录或者说一个文件夹,它只对应特定机器,这意味着当我已经在购物网站登陆完成后,此时重新连接,那么有概率会被轮询调度到别的服务器上,而别的服务器上并没有我的session,因此就会很麻烦,比如我刚才在这购物网站中点了一堆要买的物品进购物车了,那么此时就全都没有了。
负载均衡器分配通信还有另一个问题,虽然理论上每个机器能够处理一半负载,同时如果一个挂掉,另外的也能补上,只是挂掉的那台服务器上的用户可能遭殃需要重连接或者丢失未保存的信息,但至少整个网站系统能够正常运行,这个问题就是轮询调度完全没有顾及服务器内的情况,在linux系统中可以通过命令查看使用最多内存和cpu的进程,而负载均衡器却对这些都一无所知,比如有个人被随机分配到一台服务器上而这人进行了大量的运算,此时还有用户连接进来依然同概率被分配过来,按理说应该提高分配到其他服务器上的概率,才能是更好的均衡。同理比如一堆老手成天泡在服务器上跑程序,而他们恰好都被分配到同一个服务器上,而另一堆菜鸟不会常泡在服务器上却被分配到另一个服务器上,那么此时老鸟们所在服务器的负载就很大。所以说轮询调度虽然不错,很简单,普通情况它也能应对,但极端情况就无法处理了,甚至某些消耗cpu的通常情况它都很吃力。当然还有些其他负载均衡技术能和后端服务器之间形成双向联系,负载均衡器每隔几秒就会询问后端服务器负载多少,用户数多少等等,然后根据回答来确定如何分配用户。
但冗余依然是个问题,我们有冗余www0, www1或login0, login1,但这里负载器没有冗余,一直在宣扬冗余的好处如果某台机器挂掉了依然可以高枕无忧,但如果运行负载均衡软件的vm挂掉了,那所有人都完了,后端服务器都在等待连接,但没人连的上,因为nat的关系,所以因特网的用户无法通过ip地址访问它们,因为这些ip地址是私有的。
那么怎么解决这个问题呢?我们先拿掉负载均衡器,也就是不要它,可以怎么做呢,刚有同学说用DNS,这确实可以。如果后端SSH和web服务器有多个,我们或许可以不用nat而使用共有ip地址,此时我们使用这个同学讲的DNS作为“负载均衡器”,DNS能为特定域名设置多个ip地址,而dns服务器自身能进行轮询调度类似的功能,比如上图的情况用dns服务器作为黑箱,此时域名cloud.cs75.net就不仅只有1个ip地址了,而有多个ip,每个ip指向不同的vm,而且dns服务器有多台的,何况还有根服务器,所以在冗余方面还是不错的。但是改用dns服务器作为负载均衡器的缺点就是它和后端服务器之间没有双向沟通,因而无法考虑实际上各个服务器的负载情况。
讲例子。有个网站www.don.com,没有用第三层或第四层的网络层 负载均衡,而是用第五层或第七层的负载均衡,也即是应用导向的负载均衡,那么当你访问站www.don.com时,网站会有php这之类的语言发送http重定向location:header信息,然后将你送到服务器站www1.don.com或站www2.don.com等等,这样的负载均衡有点可怜,只用了不到3行代码。这样的问题就是,当有用户在www3.don.com时收藏了这个地址,而后来网站关闭了www3.do.con,那么这个用户如果是非专业的话,直接使用收藏地址就无法访问了,他们会认为这个网站关闭了,然后也许还存在前面讲的session存储在另一台www1的服务器上,而用户重新连接后却访问的是www2。
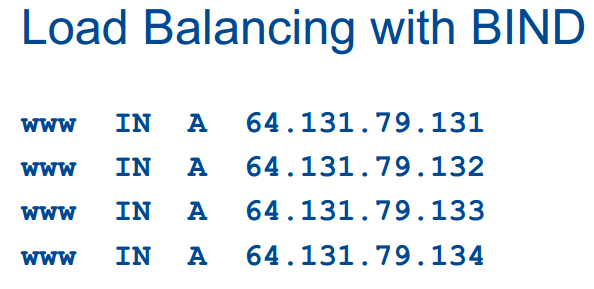
回到DNS的问题上,很多dns服务器都是用免费软件BIND,下图中的4个IP是www.cs75.net拥有的,这是使用标准 dns服务器完成轮询调度。
现在的问题在于如果通过均衡负载,让用户到不同服务器,下次再通过http连接时,他可能被分配到其他服务器上去,这样就得不到原来的session了。
一,可以使用共享数据库,至少php支持mysql等数据库作为后端以此替代/temp,只要所有web服务器能连接到此数据库,那么session数据就能存在这一个中心数据库中了。但解决一个问题往往意味着一个新问题的诞生,这种方案很麻烦,使用单一数据库是最简单的易于实现易于维护,但单个就损失了web服务器冗余的优势,此时web服务器或ssh还有冗余的,但数据库同/temp目录比起来则是没有冗余的。
数据库当然可以有冗余,但我们还有别的办法,一个同学提出可以用cookie,cookie本身是个很大的随机数,可以把随机数头为数字0-5之间的分配到这个服务器,另一个范围的分配到另一个服务器,这实现起来不困难,因为负载均衡器会查看入站请求,很多商业负载均衡器都是这么做的,即网入站和出站http请求中插入他们自己的cookie,这不是由服务器设置也不是由客户发送的,而是作为中间人插入进来跟踪走向。
还有什么办法能让用户始终被分配到相同服务器?cookie太容易被黑了,我们其实可以使用源IP,然后哈希任何人的IP,然后用这哈希表来将它们接入到login0,login1,login2或,login3等等其中之一 ,这样至少能让相同用户到相同设备,cs75这门课就是用的这种方法,对这门课参与的学生来说问题不大,因为只是http,但另一门课要让学生在命令行运行编译器,调试器,这也需要连接到相同的服务器,因此如果某学生在这里开了个ssh窗口在服务器A上,又在服务器B上开了另一个程序,然后试图用A来调试B的那个进程,这是不行的,因为进程id并非存在于两个服务器上的。
那么还有什么办法呢,我们不一定要引入数据库,还是可以用/temp的,我们只需要在本地硬盘让/temp成为共享存储,即所有系统均可见的硬盘空间,而在哈佛云服务器上就是用了这个方法,不管用户是登入的login0还是login1,都可以看到自己的主目录,这得益于NFS技术(在unix和linux系统中存在很久了,甚至mac都支持),全称为network file system(网络文件系统),它和windows以及苹果的文件共享很像,可以像本地内容一样浏览外部硬盘内容。但NFS也有缺点,所以如今最常用的还是iSCSI协议,它能在以太网中实现存储共享,讲到SAN, storage area network(存储区域网络),通常就要用到一个或多个这种协议,设置的做法就是,把所有web服务器数据库服务器等弄好之后,若还需要更快更大的硬盘空间在不同服务器之间共享,可以弄一个单独设备它具有多网卡插入,这个共享存储设备有多个大容量的硬盘,然后把这个设备加入网络交换机,然后通过网络共享。
实现负载均衡方法很多,难易程度各不相同,哈佛现在用的免费软件HAProxy,我们有两台ssh登陆服务器登陆大家的主目录,web服务器则完全分离。所以cloud.cs75.net虽然是一开始你的ssh连接到的地方,是你在80端口或443端口上的web 请求最开始到的地方,但HAProxy会根据目的端口将其分发到不同的机器上或者将mysql数据库通信弄到不同vm,即LAMP1 Linux Apache MySQL-1,这样做主要为了防止学生在折腾时不仅弄挂掉的登陆服务器还弄挂掉数据库或者web服务器。另外它还能让我们运行其他版本的os软件和工具,我们可以根据代码选择不同版本的操作系统。并且还有个好处,当想要第2或第3或第4台web服务器,还是一样只需要在HAProxy中再设置一些即可,它会为我们实现负载均衡。

LVS,Linux虚拟服务器是一个热门的选择,可以在网络层实现负载均衡。但建议大家选择HAProxy开始入门。
7.接下来从软件层面考虑如何提升性能,实现规模化。回到以前讲在mysql会议讨论的事情时讲到的缓存的事,那么有哪些可以缓存呢

首先,课程中PHP用的很多,显然我们能对它们解释后的结果进行缓存输出,而不用计算机每次重复编译解释相同的页面。
其次,mysql中,如果你不断选择相同的数据 ,也是可以让其记住最近输入和输出的,让其遇到相同问题时,如果表格或行没有变化,就不要再到数据库折腾了,直接给出答案。
上图中.html,直接使用静态页面好处就是有效率,但坏处也很多。
再来看看mysql查询缓存,要想开启这个功能直接在my.cnf文件中插入这一行:query_cache_type = 1即可。一般这个文件在/etc里面。但缺点之一就是对于一般的网站没有大量用户访问的,没有爆炸性新闻会使得短时间内有大量用户请求的,那么可能存在的问题就是当缓存满了。删掉一些,之后又收到请求,那请求刚好请求的是删掉的那些。所以有无法控制的缺点。
接着在看看memcached,如果你刚使用php生成了一些html,你可以将所有html捕获到一个变量内,也可以将其存到缓存内,又或者你查询数据库请求比如用户id,资金等等很多数据,但是又不想反复询问数据库同样的问题,类似的,不仅可以放入html字符串,还可以存放php对象到这种数据库中,只要对象能够序列化,只要它能表示为字符串能转化为某标准格式,这样做的php代码大致就是如下这样:
$memcache = memcache_connect(HOST, PORT); //memcache_connect此函数明确主机和端口
$user = memcache_get($memcache, $id); // memcache_get函数在缓存中通过键值查询值,这里取得的是id为$id的用户
if (is_null($user)) //如果得到null表示缓存中没有此用户
{
mysql_connect(HOST, USER, PASS); //查询mysql数据库
mysql_select_db(DB);
$result = mysql_query("SELECT * FROM users WHERE id=$id");
$user = mysql_fetch_object($result, User); //然后有用户对象
memcache_set($memcache, $user->id, $user); //将此用户对象缓存起来,理想情况存到内存中
} 或者下面这样
$memcache = memcache_connect(HOST, PORT);
$user = memcache_get($memcache, $id);
if (is_null($user))
{
$dbh = new PDO(DSN, USER, PASS);
$result = $dbh->query("SELECT * FROM users WHERE id=$id");
$user = $result->fetch(PDO:FETCH_ASSOC);
memcache_set($memcache, $user['id'], $user);
}
所以memcached是很棒的一个工具。
8.最后讲讲mysql本身,之前讲过表格设计,用过主键和外键,不过这里还有一些需要做决策的,当存储量达到10万推文这么大时,显然需要考虑使用哪种数据库引擎,如何定义键,如何搜索等等。因此在mysql中,大家应该了解所谓的MyISAM,它是mysql默认存储引擎,存储引擎相当于数据库中的文件系统,比如说操作系统有NTFS,HFS+,EXT3这些文件系统,而MyISAM则是数据库存储数据的格式,另一个很常用的叫InnoDB,它支持事务(transactions),这能让你锁定数据而且是在行层面,无需像MyISAM中那样锁定整个表格,只在单行处防止同时读写显然更高效,当表格很大,很多用户同时要用时,这显然更好,除这两之外还有其他引擎,这里列了两个
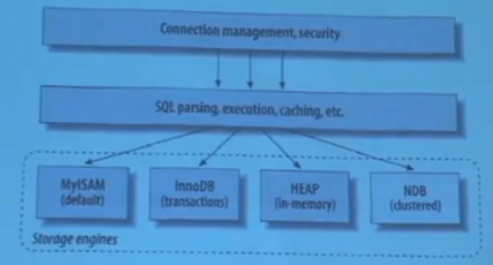
HEAP存储引擎,即内存存储引擎,它为只存储在内存中的表格所设计,对于临时性的内容,这显然很棒,如果你只想临时性存储,快速搜索,只要不关机,都不用担心数据丢失,那你就可以创建这种HEAP表,一切都一样,行列,键等等,只是要告诉数据库服务器存到内存。
然后还有NDB,用于集群,这门课不会讲这个,反正mysql支持某些复杂的集群环境,比我们今天讲的要复杂。
同一数据库内,每个表可以有不同数据引擎,所以在设计表格时,可以考虑各个表格用什么引擎,有时用InnoDB它支持事务,有时用MyISAM它性能更好对特定操作更高效。
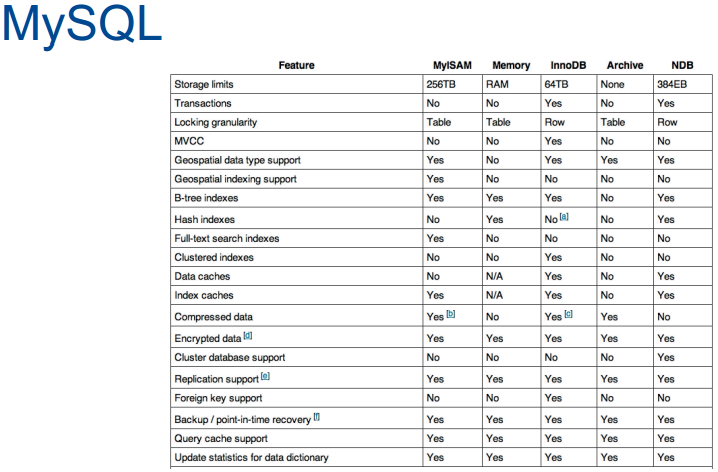
下面这图摘自mysql文档关于各个引擎的不同。关于外键就是某张表中有键,但它是其他表格中的主键,而不是这张表的主键,InnoDB的好处就是有外键的概念,我们可以创建很多有趣规则,这些就是DBA(数据库管理员)所做的,可以标记某表中的字段,依赖于其他表中的字段,于是不用写任何php代码,就能让数据库具备自动关联式,比如我删除用户,数据库就会自动将该用户所有表中的相关行都删除,这样一来最后想让表格保持一致,连代码都不用写,
那么如何将这些数据库服务器连起来呢,之前提出的问题是我们只用了一台数据库服务器,和负载均衡器一样,这是单故障点,这当然能解决,我们只是图方便。其实,往结构中引入从服务器也并不难。下图是数据库层实现冗余的一般结构除了主服务器1外还有多个从服务器与之相连,任何时候数据写入主服务器1的时候,会同时复写到2-4号从服务器,但反方向则不行,所以主从关系是指从服务器是读出还是写入,写入进主服务器,要读的时候从从服务器中选其中一个来读。这样能处理越来越大的读请求,在mysql中这样做,一般需要进行一些网络及防火墙设置,告诉主服务器写入从服务器,从服务器接收,不过这里还是有单故障点。
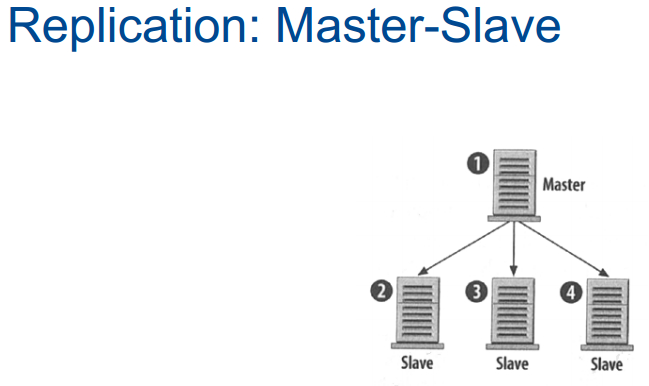
我们用一种明显方式来解决它吧,若主服务器是单故障点,那就弄两台,如下图,两个主服务器相互连接,只要有数据写入左服务器,右侧服务器也会写入。课程中只介绍了最简单的php对于mysql的api,叫做所有的函数叫做mysql_connect,使用这些函数就能维持多数据库连接,所以代码中可以分开写成一个写连接和一个读连接,这就能在代码层面简单实现控制,如果要做的更好一点,可以让所有选择发到这里,而让所有插入更新删除发到那里,

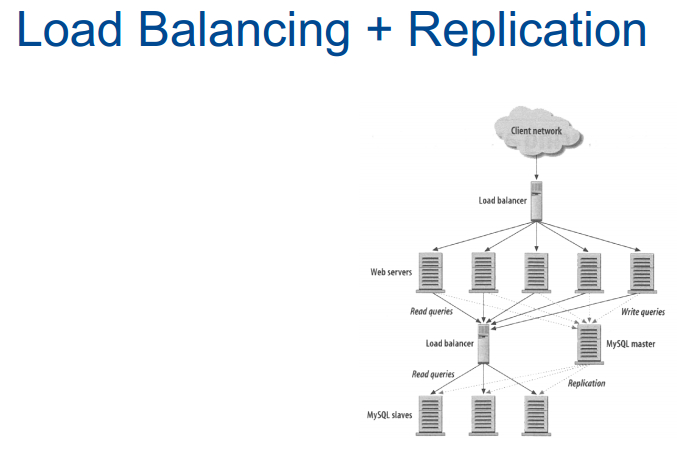
如果需要在主服务器1和2之间做选择,因而可以同正确的对应于该主服务器的从服务器通信,可以硬编码到代码中,不过通常最好提出来,我们没有让名字开头字母是什么的ssh到这个服务器,而其他字母的到另一台服务器,对用户及代码隐藏这些最好,理论上可以用之前讲的一些包含负载均衡器的结构,如下图:用户发送来请求会由负载均衡器随机分配到后面的web服务器上,然后若用户是读请求则连接到从服务器的负载均衡器上,若是写请求则连接到主服务器上。
这里还有要当心的特别是我们需要避免竞态条件,有几种办法,一种是分割,fb一开始就是这种办法,那时候其URL形如harvard.facebook.com,mit.facebook.com, bu.facebook.com,扎克伯格最开始的情况是所有代码和数据库服务器都在一个学校,之后他们要去别的学校,最简单的办法就是创建另一个子域名,然后用cp -r递归复制所有代码并拷贝数据库,然后以这种方式分割不同学校,一开始facebook限制用户在自己的学校,这样区分对性能有好处,也有可能所有这些还是在一台服务器上,只是用不同数据库和代码文件夹,这样的好处就是可以将mit.facebook.com这些移到不同服务器,从而实现水平规模化,这只需要增加一些有空余周期的不同服务器,而不用修改代码,然后用一些域名技巧,就让用户映射到了别处,不管按学校,名字还是别的什么来分开用户,通常称作分割(Partitioning),这在数据库中很常用,能将用户分开以避免一些问题,比如竞态条件之类的,而且仍然能够横向增长并处理多个用户,不过像下图这样所有a-m的到左边,所有n-z的到右边有缺点,facebook的例子是来自harvard的域名到这里,来自mit的域名到那里这样,当然也可以根据用户登录的邮箱的结尾来分,但当没有这种明显的方式分割用户,那么就需要更多的工作了

下图中有负载均衡器连接两台主服务器,两台主服务器相互复制,负载均衡器不仅是盲目的将用户用户轮换送到A和B,它可能不知道每台服务器的负载,但它显然需要不断ping两台服务器A和B,来看它们是否还在运行,当某服务器停止响应时,它就应该停止向这服务器发送用户,HAProxy就是这样做的,所以得益于不断ping,因此有了高可用性
















 5190
5190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









