







散列
一般想法
散列函数
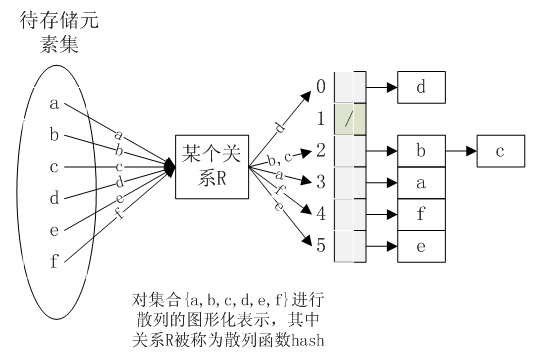
其中关系R为散列函数
分离链接法
hash函数的运行时间为O(1),所以插入和删除都为常量时间O(1)。(注意,插入和删除都是以元素x而非关键字k作为输入,所以不用查找。)
接下来分析查找特定元素的性能。对于一个存放了n个元素,具有m个槽的散列表T,定义它的装载因子(load factor)a为n/m,即每个槽里链表的平均长度。a可以小于、等于或大于1。
在最坏情况下,所有的元素都被散列到同一个槽里,这样查找的运行时间为Ө(n)。
为了分析平均情况,我们假设所有元素被散列到m个槽中的每一个的可能性是相同的,这个假设为简单一致散列(simple uniform hashing)。
在查找不成功的情况下,(即关键字k不在散列表中,)我们会遍历某个槽的链表的所有元素,而该链表的元素数量的平均值为a,所以这种情况下运行时间为Ө(1+a)。
开放定址散列法
开放定址散列法不使用链表存储,使用数组存储,寻找储存表中的空余的位置进行存储。
-
线性探测法:依次查找没有冲突的位置 f(i)=1
-
平方探测法:依平方次查找没有冲突的位置,第一次为距离冲突点1,第二次为距离冲突点4。f(i)=i^2
-
双散列,在该位置上再次散列。F(i)=i*hash(i)
再散列
对一次散列的结果进行再一次散列(更改表大小后),存储到另外一张表中。散列规则和散列方法有很多,散列规则常见的有
-
表存储到一半
-
插入失败时散列
-
途中散列,散列达到某个装填因子时再散列。
最坏情况下的散列表
前面讨论散列方法的平均运行时间均为0(1),但是考虑最坏情况均为0(n),以下有几种散列方法可以缩短最坏情况的运行时间。
-
布谷鸟散列
在布谷鸟散列中,假设有N个项,我们维护两个分别超过一半空的表,而且有两个独立的散列函数,可以把每一项分配到每一个表中的位置,布谷鸟是散列中总是会被存储在这两个位置之一
于是焦点问题就在于,存在阻碍插入成功的循环概率有多大,以及成功插入需要替换次数的期望是多少,装填因子小于0.5的时候替换次数的期望是一个常数。
因此在若干次替换被检测到后,我们就可以简单的用新的散列函数重新建表,更N次插入以重新建表,即便如此 也意味着这种花费很,然而表的装填因子达到0.5或者更高,循环的概率就更高,这种方法就不太好用了
-
跳房子散列
跳房子散列的思路是 用事先确定的 对计算机底层体系结构而言是最优秀的一个常数 给探测序列的最大长度加一个上届。这样做可以给常数的最坏查询时间,并且与布谷鸟散列一样,查询并优化,以同时检查可用位置的有限集
如果某次插入要把一个新的项放到距离它的散列位置太远的地方,我们会很有效的掉头想散列位置走,替换掉潜在项,如果足够谨慎,那么替换可以很快完成,并且保证那些被替换的想都不会放到距离它们的散列位置很远的地方
通用散列法
尽管散列表很有效,并且子啊装填因子适当的情况下,假设每个操作都有固定的平均花销,但是其表现和分析却取决于散列函数具有以下两种性质
1. 散列函数必须可在常数时间内计算
2. 散列函数必须将各项均匀分布在数组单元中
以你散列函数不好,一切都是徒劳。每个操作的花销都可能是线性的
优先队列(堆)
优先队列(堆)
查询最小元:o(1)
最坏插入o(logn)
删除最小元:o(logn)
合并:o(NlogN)
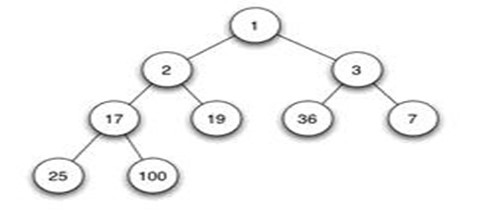
如上图所示,堆是一颗完全二叉树,且根为最小元,所以查询最小元的操作时间复杂度为0(1)
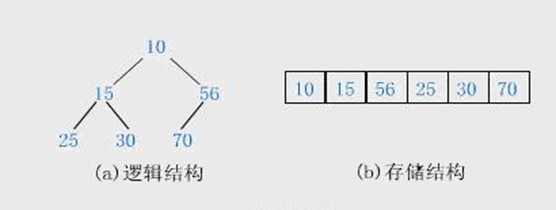
由于堆的完全二叉树性质,可以十分方便的存储在数组中,如上图所示。
当堆添加一个元素时,添加到树叶最右端,由于会破坏堆结构,所以需要和父节点对比,移动到对应的位置,具体操作如下图:
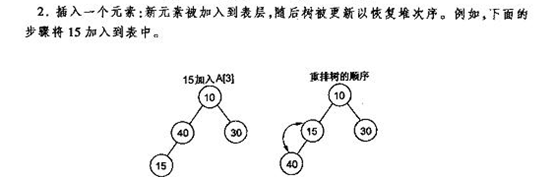
这种操作叫上滤。
如果移除一个跟节点,则堆结构也需要调整,需要将最后一个元素移到根节点,然后再和子节点对比,将较小的子节点放入根中,然后再排序。
具体如下:
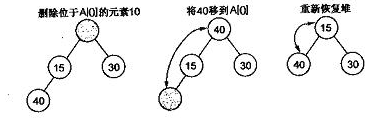
这种操作叫下滤。
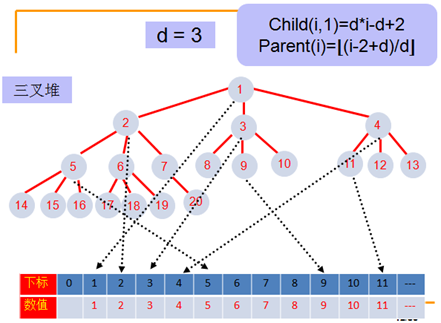
D-堆
查询最小元:o(1)
最坏插入o(logmn)
删除最小元:o(dlogdn)
合并:o(NlogdN)
D-堆是二叉堆的拓展,d-堆的高度要比二叉堆要小的多,所以insert操作更加快。
左式堆
合并:o(logN)
左式堆是为了更加方便对两个堆进行合并的数据结构,左式堆是不平衡的二叉树,结构如下:

斜堆
合并:o(logN)
斜堆(Skew Heap)基于左倾堆的概念,也是一个用于快速合并的堆结构,但它可自我调整(self-adjusting),每一个merge操作的平摊成本仍为O(logN)。
二项队列
左堆的合并,优化的左式堆。
Java 优先队列
System.out.println("test begin");
Queue<String> queue = new PriorityQueue<String>();
queue.add("this is quern");
queue.add("this is d quern");
queue.add("this is d qern");
System.out.println(queue.poll());















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









