






![谷歌开发的强化学习方法 [CT,左上] 与其他各种方法和人类竞争,以最好地将大块电路放置在芯片上。 Chung-Kuan Cheng 等人](https://i-blog.csdnimg.cn/direct/f0286cc9c9ef4a6aaa1160a4a5b3b1c4.png)
芯片设计会议 上的讨论很少会变得激烈。但在一年前的国际物理设计研讨会(ISPD) 上,事情变得一发不可收拾。观察人士将其描述为“一场灾难”和“一次伏击”。冲突的关键在于谷歌针对芯片设计最棘手的问题之一的人工智能解决方案是否真的比人类或最先进的算法更好。它让资深的男性电子设计自动化 (EDA) 专家与两位年轻的女性谷歌计算机科学家展开对决,而潜在的争论已经导致一名谷歌研究员被解雇。
今年在同一次会议上,该领域的领军人物、IEEE 院士 Andrew Kahng希望一劳永逸地结束这种争执。他和加州大学圣地亚哥分校的同事对谷歌的强化学习方法进行了所谓的“公开透明的评估”。他们使用谷歌的开源版本 Circuit Training,并对 Kahng 团队不太清楚的部分进行逆向工程,将强化学习与人类设计师、商业软件和最先进的学术算法进行了对比。Kahng 拒绝就本文 接受IEEE Spectrum 的采访,但他上周在以线上方式举行的 ISPD 会议上与工程师们进行了交谈。
在大多数情况下,Circuit Training 都不是赢家,但它具有竞争力。这一点尤其值得注意,因为实验不允许 Circuit Training 使用其标志性功能——通过学习其他芯片设计来提高其性能。
他告诉工程师们:“我们的目标是让大家理解得更清楚,这样社区才能继续前进。”只有时间才能告诉我们这个方法是否奏效。
如何以及何时
这个问题叫做布局。基本上,它是确定逻辑块或内存块应该放在芯片上什么位置的过程,以便最大限度地提高芯片的工作频率,同时最大限度地降低芯片的功耗和占用面积。找到这个难题的最佳解决方案是最困难的问题之一,其可能的排列组合比围棋游戏还要多。
但围棋最终败给了一种名为深度强化学习的人工智能,而这正是前谷歌大脑研究人员 Azalia Mirhoseini 和 Anna Goldie 应用于布局问题的技术。该方案当时被称为Morpheus ,它将大型电路(称为宏)的布局视为一场游戏,学习寻找最佳解决方案。(宏的位置对芯片特性有巨大影响。在 Circuit Training 和 Morpheus 中,单独的算法用较小的部件(称为标准单元)填补空白。其他方法对宏和标准单元都使用相同的过程。)
简而言之,它的工作原理 如下:芯片的设计文件以所谓的网络表开始 - 根据哪些约束将哪些宏和单元连接到其他宏和单元。然后将标准单元收集到集群中以帮助加快训练过程。然后,Circuit Training 开始将宏逐个放置在芯片“画布”上。当最后一个宏完成后,单独的算法会用标准单元填补空白,系统会对尝试进行快速评估,包括布线长度(越长越糟糕)、布线密度(越密集越糟糕)以及布线拥挤程度(你猜对了,越糟糕)。这被称为代理成本,其作用类似于强化学习系统中的分数,该系统正在弄清楚如何玩视频游戏。分数被用作反馈来调整神经网络,然后再次尝试。清洗、漂洗、重复。当系统最终了解了它的任务时,商业软件会对完整的布局进行全面评估,生成芯片设计人员关心的指标,例如面积、功耗和频率限制。
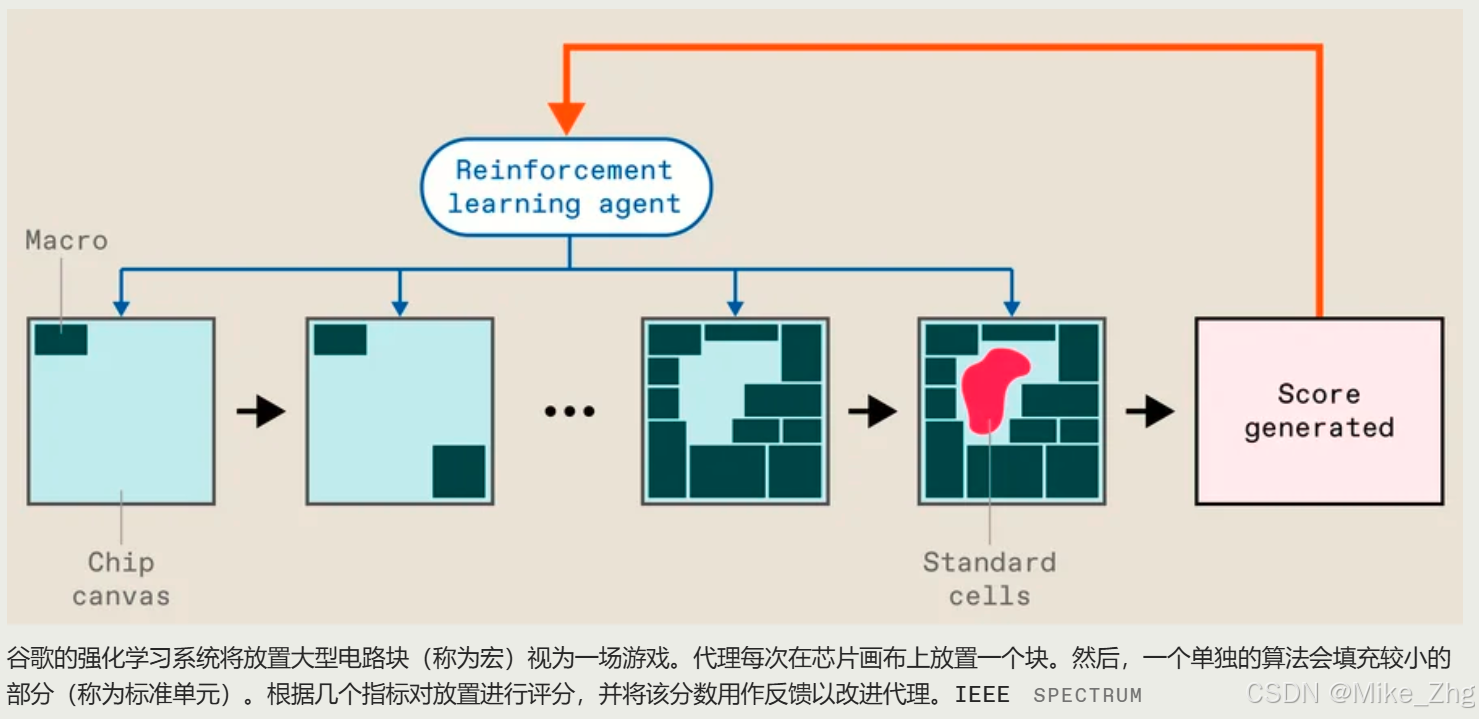
经过 7 个月的审查过程, Mirhoseini 和 Goldie于 2021 年 6 月在Nature 上发表了 Morpheus 的结果和方法。( Kahng 是 3 号审稿人。)而该技术被用于设计谷歌不止一代的TPU AI 加速器芯片。(所以是的,你今天使用的数据可能是由运行在部分由 AI 设计的芯片上的 AI 处理的。但随着 Cadence 和Synopsys等 EDA 供应商全力投入AI 辅助芯片设计,这种情况越来越多。)2022 年 1 月,他们在 GitHub 上发布了一个开源版本Circuit Training。但 Kahng 和其他人声称,即使是这个版本也不够完整,无法重现这项研究。
为了回应《自然》杂志的报道,另一组工程师(主要来自谷歌)开始研究他们认为更好的方法来比较强化学习和现有算法。但这并不是友好的竞争。据新闻报道,其领导人 Satrajit Chatterjee 多次破坏 Mirhoseini 和 Goldie 的个人形象,并因此于 2022 年被解雇。
Chatterjee 还在谷歌任职时,他的团队发表了一篇题为《更强的基线》的论文,批评了《自然》杂志发表的研究。他试图在一次会议上发表这篇论文,但经过独立解决委员会的审查后,谷歌拒绝了。在他被解雇后,这篇论文的早期版本在 2022 年 ISPD 会议前夕 通过一个匿名推特账户泄露,引发了公众的对抗。
基准、基线和可重复性
当IEEE Spectrum在 ISPD 2022 之后与 EDA 专家进行交谈时,批评者有三个相互关联的担忧——基准、基线和可重复性。
基准是研究人员用来测试新算法的公开电路块。谷歌开始这项工作时使用的基准已经有大约 20 年的历史了,它们与现代芯片的相关性还存在争议。卡尔加里大学教授 Laleh Behjat 将其比作规划现代城市与规划 17 世纪城市。她说,两者所需的基础设施不同。然而,其他人指出,如果每个人都在同一组基准上进行测试,研究界就无法取得进展,而既定的基准仍然受到专家的广泛支持。
《自然》杂志的论文 没有使用当时可用的基准,而是专注于为谷歌的TPU进行布局,这是一款复杂而尖端的芯片,谷歌以外的研究人员无法获得其设计。泄露的“Stronger Baselines”工作放置了 TPU 块,但也使用了旧的基准。虽然 Kahng 的新工作也为旧的基准进行了布局,但主要关注的是三种更现代的设计,其中两种是新推出的,包括多核RISC-V处理器。
基准是您的新系统与之竞争的最先进的算法。《自然》杂志将使用商业工具的人类专家与强化学习和当时领先的学术算法 RePlAce 进行了比较。“更强的基准”认为《自然》杂志的工作没有正确执行 RePlAce,并且还需要与另一种算法模拟退火进行比较。(公平地说,模拟退火结果出现在《自然》杂志论文的附录中。)
但 Kahng 真正关注的是可重复性。他声称,发布到GitHub上的 Circuit Training不足以让独立团队完全重现该过程。因此,他们决定自行对他们认为缺失的元素和参数进行逆向工程。
重要的是,Kahng 的团队公开记录了进展、代码、数据集和程序,以此作为此类工作如何提高可重复性的一个例子。他们甚至首次成功说服 EDA 软件公司 Cadence 和 Synopsys 允许发布实验中使用的高级脚本。“这对我们这个领域来说绝对是一个分水岭,”Kahng 说。
加州大学圣地亚哥分校的 成果被简称为MacroPlacement,并非旨在一一重现《自然》杂志的论文或泄露的 Stronger Baselines 成果。除了使用 2020 年和 2021 年无法获得的现代公共基准之外,MacroPlacement 还将 Circuit Training(虽然不是最新版本)与商业工具Cadence 的 Innovus 并发宏布局器 (CMP)进行比较,并与 Nvidia 开发的一种名为AutoDMP的方法进行比较,后者非常新颖,以至于在 Kahng 发言前几分钟才在 ISPD 2023 上公开介绍。
强化学习与其他方案
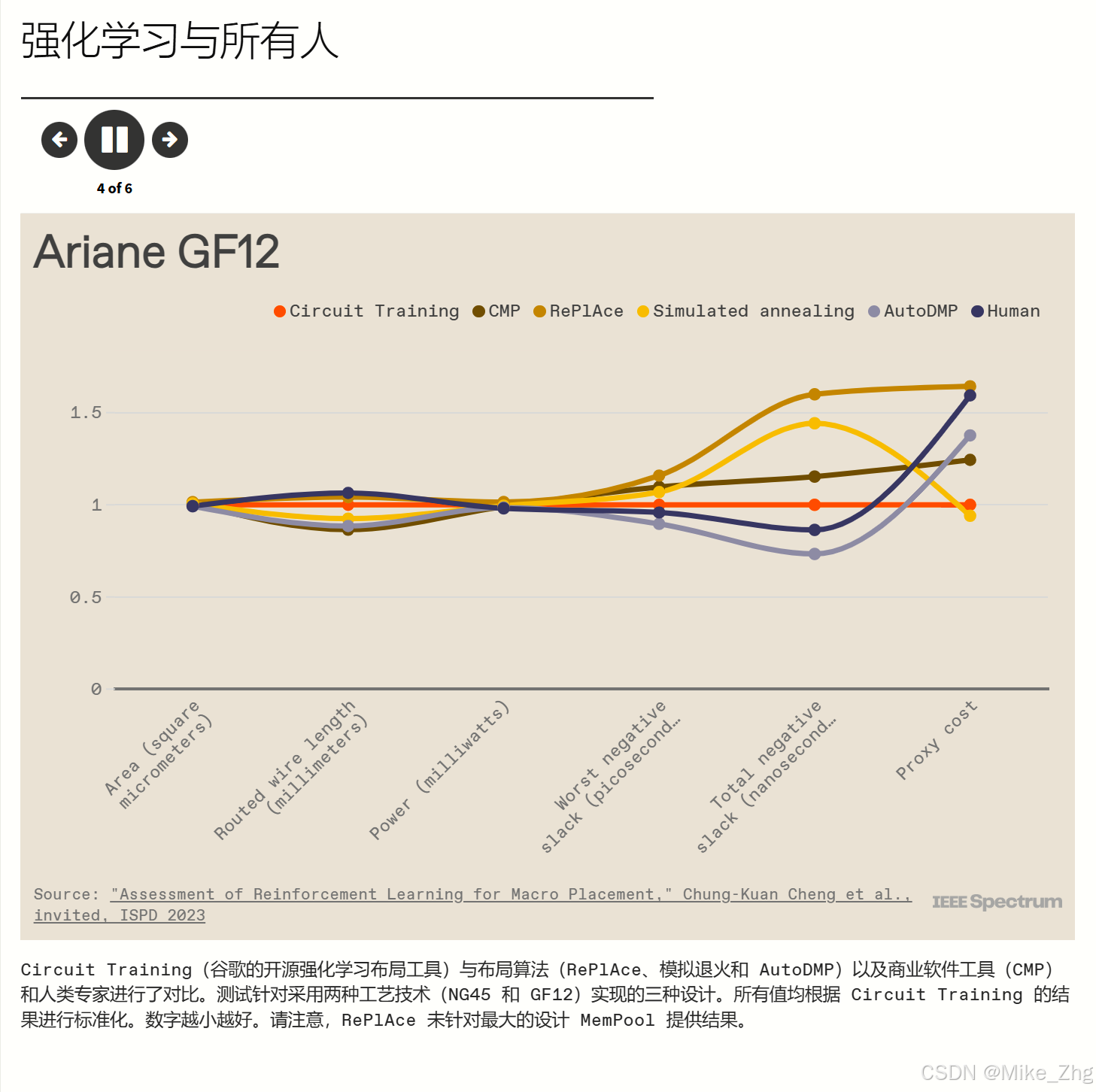
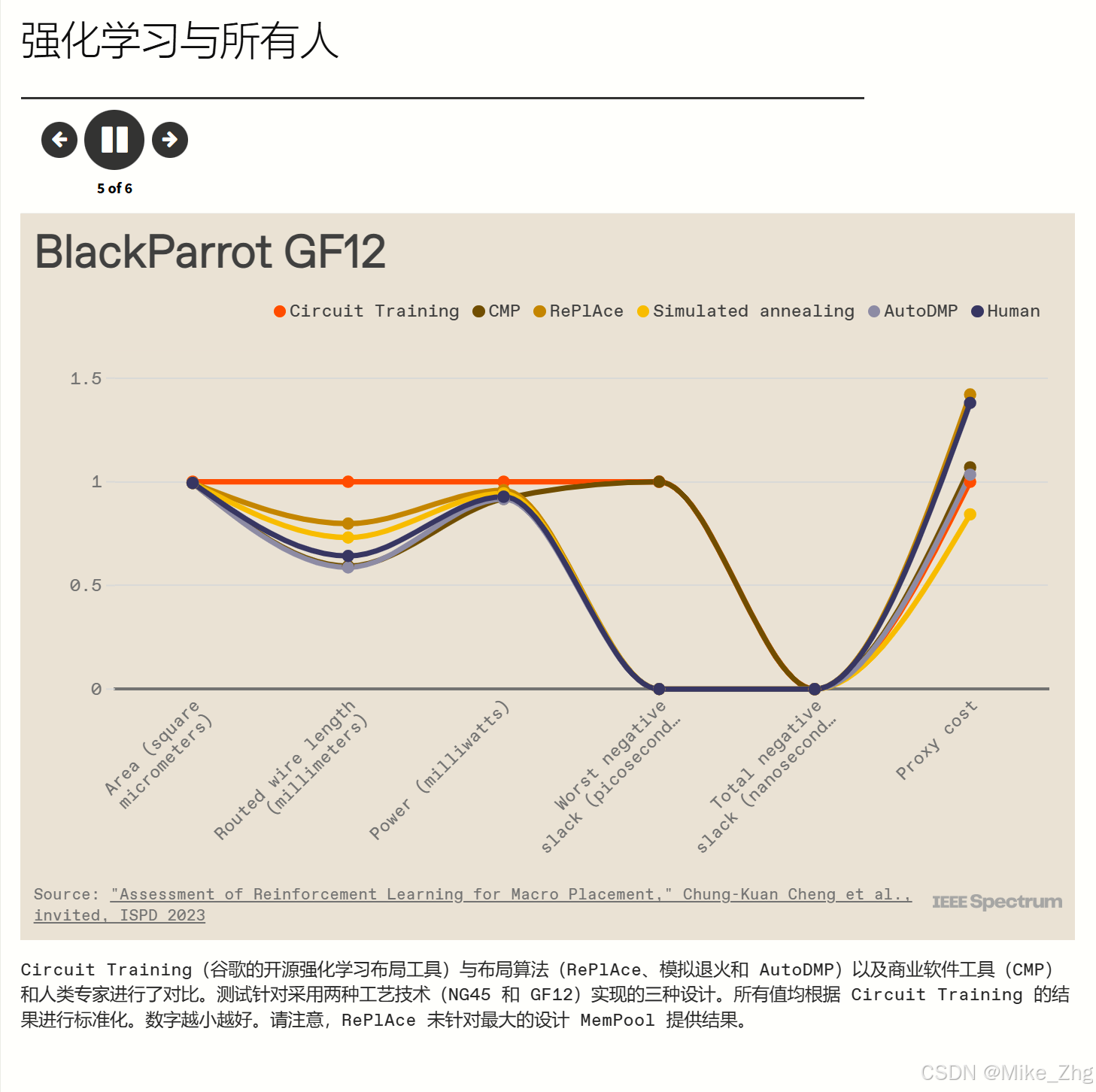
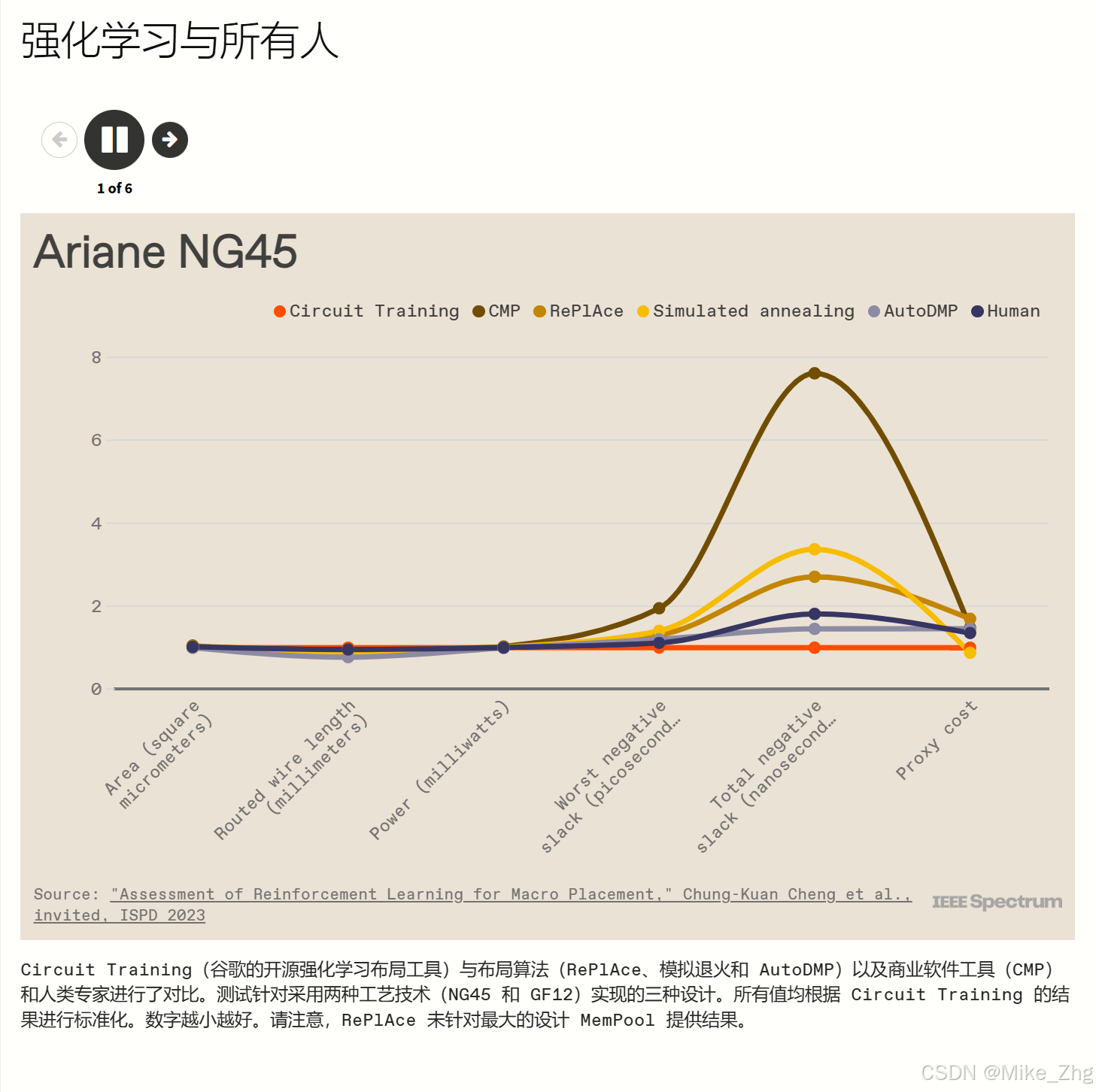
Kahng 的论文报告了使用两种技术实现的三种现代基准设计的结果——开源的 NanGate45和商用 GlobalFoundries FinFET 工艺的 GF12 。( 《自然》杂志报道的 TPU 结果使用了更先进的工艺技术。)Kahng 的团队测量了 Mirhoseini 和 Goldie 在《自然》杂志论文中测量的六个指标:面积、布线长度、功率、两个时序指标以及前面提到的代理成本。(代理成本不是生产中使用的实际指标,但它被包括在内以反映《自然》杂志论文。)结果好坏参半。
正如《自然》杂志 的原始论文中所述,强化学习在大多数进行过直接比较的指标上都击败了 RePlAce。(RePlAce 没有对三种设计中最大的一个给出答案。)与人类专家相比,Circuit Training 经常失败。与模拟退火相比,竞争更加均衡。
对于这些实验,最大的赢家是最新进入的 CMP 和 AutoDMP,它们在更多情况下比任何其他方法都提供了最佳指标。
在旨在匹配 Stronger Baselines 的测试中,使用较旧的基准,RePlAce 和模拟退火几乎总是击败强化学习。但 Mirhoseini 和 Goldie 认为,这些结果只报告了一个生产指标,即线路长度,因此它们并没有提供完整的情况。
缺乏学习
可以理解的是,Mirhoseini 和 Goldie 对 MacroPlacement 的工作有自己的批评,但也许最重要的是它没有使用在其他芯片设计上预先训练过的神经网络,这剥夺了他们的方法的主要优势。他们在一封电子邮件中写道,“与提出的任何其他方法不同,Circuit Training 可以从经验中学习,在遇到每个问题时更快地产生更好的布局”。
但在 MacroPlacement 实验中,每个 Circuit Training 结果都来自一个从未见过这种设计的神经网络。“这类似于在每场比赛前重置 AlphaGo……然后每次面对新对手时,都强迫它从头学习如何下围棋!”
《自然》杂志 的论文结果证实了这一点,表明系统学习的 TPU 电路块越多,它对尚未见过的电路块的宏布局就越好。论文还表明,经过预训练的强化学习系统可以在 6 小时内完成布局,其质量与未经训练的系统在 40 小时后完成的布局相同。
新的争议?
Kahng 在 ISPD 演讲中强调了《自然》中描述的方法与开源版本 Circuit Training 之间的特殊差异。回想一下,作为预处理步骤,强化学习方法将标准单元聚集到簇中。在 Circuit Training 中,该步骤由商业 EDA 软件实现,该软件输出网络表(哪些单元和宏相互连接)以及组件的初始位置。
据 Kahng 称,即使作为论文审稿人,他也不知道《Nature 》论文中存在初始布局。据 Goldie 称,生成初始布局(称为物理综合)是行业标准做法,因为它指导了网表的创建,即宏布局器的输入。《Nature》和《MacroPlacement》中的所有布局方法都具有相同的输入网表。
初始布局是否在某种程度上为强化学习带来了优势?Kahng 表示,是的。他的团队进行了实验,将三种不同的不可能初始布局输入 Circuit Training,并将它们与真实布局进行比较。不可能版本的布线长度差了 7% 到 10%。
Mirhoseini 和 Goldie 反驳说,初始位置信息仅用于聚类标准细胞,而强化学习不会进行聚类。他们说,宏观放置强化学习部分对初始位置一无所知。更重要的是,提供不可能的初始位置可能就像用大锤砸向标准细胞聚类步骤,从而给强化学习系统一个错误的奖励信号。“Kahng 引入了一个劣势,而不是消除了一个优势,”他们写道。
Kahng 表示,即将进行更精心设计的实验。[更新 2023 年 4 月 25 日:Kahng 团队的一名成员报告说,这些实验已经完成。他们对 Ariane 基准的初始位置进行了小幅调整,并测量了关键指标的变化。他们写道,这一程序“使除路由线长之外的所有 CT 结果都恶化”。在此处查看结果。]
继续前进
这场纠纷当然带来了后果,其中大部分都是负面的。Chatterjee 与谷歌陷入了一场不当解雇诉讼。Kahng 和他的团队花费了大量的时间和精力来重建多年前完成的工作(也许已经完成了好几次)。在花费数年时间抵御未发表和未经审查的研究的批评之后,Goldie 和 Mirhoseini 离开了这个历来难以吸引女性人才的工程领域,而他们的目标是帮助改进芯片设计。自 2022 年 8 月以来,他们一直在Anthropic从事大型语言模型的强化学习工作。
如果说有什么好的一面,那就是 Kahng 的努力为开放和可重复的研究提供了一种模式,并增加了公开可用的工具库,以推动芯片设计的这一部分向前发展。话虽如此,Mirhoseini 和 Goldie 在谷歌的团队已经制作了他们研究的开源版本,这在行业研究中并不常见,而且需要一些不平凡的工程工作。
尽管存在诸多争议,但机器学习(尤其是强化学习)在芯片设计中的应用仍在不断扩大。甚至在 Morpheus 开源之前,就有多个团队能够基于它进行开发。机器学习正在帮助Synopsys和Cadence等商业 EDA 工具不断增长的领域。
但即使没有这些不愉快的事情,一切美好的事情也可能会发生。
这篇帖子于 4 月 4 日进行了更正。CMP 最初被错误地描述为一种新工具。4 月 5 日,添加了有关 CT 与人类和模拟退火相比如何的背景和更正。有关围绕初始放置问题的实验清晰度的声明被删除。
进一步探究:
MacroPlacement项目在 GitHub上有详尽的文档。常见问题解答页面面向更广泛的受众,并解答了批评。
Google 在 GitHub 上的 Circuit Training 条目在这里。
Andrew Kahng在此记录了他参与《自然》论文的过程。《自然》杂志于 2022 年发表了同行评审文件。
您可以在此处找到 Mirhoseini 和 Goldie 对 MacroPlacement 的回应。
本文刊登在 2023 年 6 月的印刷版上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









