







文章目录

标准梯度下降法GD


随机梯度下降法(SGD)和批随机梯度下降法(BGD)

所以,由此可知,batch的目的只是为了优化梯度下降法。

为什么不用牛顿法?

动量法
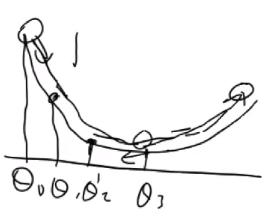
 动量法用于解决局部梯度的反方向不一定是函数整体下降的方向,如隧道型曲面的震荡。
动量法用于解决局部梯度的反方向不一定是函数整体下降的方向,如隧道型曲面的震荡。


吸收一部分上次更新的余势,就类似于加上了铁球的惯性,铁球有惯性,就一直在下滑方向保持一定的速度。上一步的余势加上当前点处的梯度。
NAG 动量法改进算法(带刹车)

针对于学习率有关的下面两个问题:

自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。
目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
AdaGrad
AdaGrad = Adaptive + Gradient
思想:AdaGrad算法,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根。具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降。



 我的理解:不同类别样本数量差异大的时候,不能通用相同的学习率。所以AdaGrad就是解决这个学习率的问题。
我的理解:不同类别样本数量差异大的时候,不能通用相同的学习率。所以AdaGrad就是解决这个学习率的问题。
RMSProp算法
AdaGrad的学习率衰减太快,特别是样本越多,衰减越多,学习率相对来说很快就趋于0,为了解决这个问题,提出了AdaDelta。

移动平均的效果其实就是指数平均。

这里的AdaDelta其实是常说的RMSProp算法。

AdaDelta算法
为了解决RMSProp的两个问题:
1.更新公式中量纲统一;
2.彻底消灭学习率这个超参数;
提出了AdaDelta的另一个改进算法,就被称为AdaDelta算法。


Adam算法


无偏估计就是通过下面的式子实现的。当t比较小的时候,m的估计值和计算值差别很大,随着t越来越大,m的估计值就几乎等于计算值了。

选择标准

以上都是采用更新参数法则来实现优化,下面是其他方面来优化梯度下降。
其他优化方法

批规范化:特征值输入网络的时候都要经过归一化,但是仅仅是针对于第一层隐含层有用,对于多层神经网络,隐藏层的输出不再是归一化的数据,数据的差异可能越来越大,导致数据不平衡,所以批规范化就是在每个隐含层输出后添加了一个夹层,用于归一化隐含层的输出,并记录归一化的系数,后面就用规范化后的数据进行训练。这样每一层的输入数据都成了归一化后的数据。


高斯分布的方差需要越来越小,人为地增加衰减,下图可知,t越大,衰减越多。

参考链接来源
感谢原作者的优秀工作。
https://blog.csdn.net/weixin_40170902/article/details/80092628
https://www.bilibili.com/video/BV1fW411T7GP?from=search&seid=3191228025220819159















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









