







本文采用两个网络进行训练,连个网络模型结构一样,分别命名为teacher,student网络。student网络参数根据损失函数梯度下降法更新得到;teacher网络参数通过student网络的参数迭代得到。
训练数据:
有标签样本x1,y1,以及无标签样本x2.
训练策略:
将有标签数据x1,y1输入student,从而计算loss1.
将无标签数据x2输入student,从而计算得到label1
将无标签数据x2输入teacher,从而计算得到label2
我们希望两个网络的预测标签尽量相等,因此根据lable1,label2得到损失函数loss2.
根据loss=loss1+loss2更新student网络。
在每个step中,更新student网络参数后,再利用student网络的参数更新teacher网络参数,
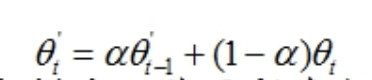















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









