






公众号 系统之神与我同在
摘要
过去,知识库中的复杂问题通常被分为两类:有约束的问题和有多重关系的问题。在本文中,我们提出一种方法能够同时处理这两类问题。由于早期在查询图中加入约束可以更有效的修剪搜索空间,我们基于这个观点,提出了一种改进的,分阶段的查询图生成方法。实验结果表明,该方法在三个基准知识库问答数据集上达到了先进水平。
- 导言
知识库问题回答(KBQA)旨在回答知识库(KB)中的仿真问题。近年来,这一方向受到大量关注(Bordes et al., 2014; Xu et al., 2016; Yu et al.,2017; Liang et al., 2017; Hu et al., 2018; Petrochukand Zettlemoyer, 2018.)。早期关于知识库问题回答(KBQA)的工作侧重于包含单一关系的简单问题(Yih et ai.,2014;Bordes et ai.,2015;Dong et ai.,2015;Hao et ai.,2017)。然而,现实问题往往更加复杂,近年来有学者针对复杂的知识库问答(KBQA)展开了研究。
近些年的研究针对两种复杂问题:(1)有约束的单步关系的问题。例如,在问句“谁是美国第一任总统?”答案实例“总统”和问题实例“美国”之间只有单步关联,同时,我们又有“第一任”总统的约束需要满足。对于这类复杂问题,前人已经提出了一种分阶段的查询图生成方法,该方法首先识别单步关系的路径,然后对其添加约束以形成查询图(Yih et ai.,2015;Bao et ai.,2016;Euo et ai.,2018)。(2)具有多步关系的问题。例如,在问题“谁是Facebook创始人的妻子?”中,答案与“Facebook”有关,经过了“创始人”和“妻子”两步的关系。为了回答这类多步关系(multiple hops)问题,我们需要考虑更长的关系路径,以便获得正确的答案。这里的主要挑战是如何限制搜索空间,即减少要考虑的多步关系路径的数目,因为搜索空间随着关系路径的长度成指数增长。一个想法是使用束搜索(beam shearch)。例如,Chen et ai(2019)和Ean et ai(2019b)建议在扩展关系路径时仅考虑最佳匹配关系,而不是考虑所有关系。然而,几乎没有人提出能够同时处理这两种复杂问题的方法。
本文针对复杂知识库问答(KBQA)问题,提出了一种能够同时处理约束问题和多步问题的方法。我们提出了改进的分段查询图生成方法,使得该方法可以处理更长的关系路径。然而,我们不是在构造关系路径之后才添加约束,而是同时引入约束和扩展关系路径。这允许我们更有效地减少搜索空间。在 ComplexWebQuestions数据集上,我们的方法大大优于现有的方法,在 Prec@1中改进了 3.3 个百分点,在 F1中改进了 3.9个百分点。在另外两个基准知识库问答数据集上,我们的
方法也不低于以前的方法(达到了the-state-of-art)。
- 方法
- 预备知识
一个知识库(KB)可以表示为一个三元数组K.={(h,r,t)}。其中h和t是来自实例集ε的实例,和r是来自关系集R的一个关系。对于问题Q,知识库问答(KBQA)试图找到一个实例α∈ε回答该问题。
我们的方法很大程度上受到现有的分阶段的查询图生成方法的启发(Yih et ai,2015;Bao et ai,2016;Loo et ai,2018),我们在这里简要介绍这种方法。查询图有四种类型的节点:基础实例(阴影矩形)是知识库(KB)中现有的实例。存在变量(existential variables)(白底矩形)是一个不连续的实例(ungrounded entity)。lambda变量(圆)也是一个不连续的(ungrounded)实例,但它代表答案。最后,聚合函数(菱形)是对一组实体进行求和操作的函数,如argmin和count。查询图的边是来自关系集R的一个关系。查询图应恰好具有一个lambda变量来表示答案,至少一个基础实体,以及零个或多个存在变量和聚合函数。图 1 显示了“谁是 JeffProbst Show提名的TV制片人的第一任妻子”这一问题的示例查询图。
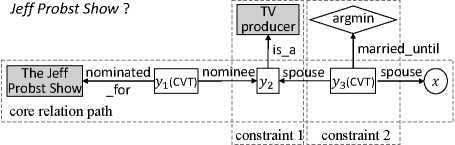
谁是被提名电视制片人的第一任妻子?
图1:上面显示的是一个问题的查询图的例子。假设我们从话题实例JeffProbstShow开始,核心关系路径是将JeffProbstShow链接到lambda变量x的路径。查询图中有两个约束。注意,y1和y3是用于n元关系的CVT节点。
我们将分阶段查询图的生成方法总结如下。(详见Yih et al., 2015; Bao et al., 2016)。
- 首先,从问题中找到的基础实体(称为主题实体),标识出将主题实体链接到lambda变量的核心关系路径2。现有研究考虑了包含单一关系的核心关系路径(Yih et ai, 2015; Bao et ai, 2016; Loo et ai, 2018)
- 在步骤1中标识的核心关系路径中,添加问题里的一个或多个约束。一个约束包含基础实例,聚合函数和一个关系。
- 对于从步骤1和步骤2生成的所有候选查询图,通过测量它们与问题的相似度来对它们排序。这通常通过诸如CNN的神经网络模型来完成(Yih et ai,2015;Bao et ai,2016)。
- 选取知识库(KB)执行排名最高的查询图以获得答案实体。

动机
图2:延伸连接和集合体注意,查询图(d)对应于“谁是第一个被提名为候选人”的问题JeffProbst秀?”
当直接将上面概述的现有方法应用于受限多跳知识库问题回答(KBQA)时,我们面临的主要挑战是,包含多跳关系的问题(例如图1中的示例)不能被处理,因为现有工作仅考虑具有单跳的核心关系路径(或具有一个CVT节点的两跳)。如果我们通过允许核心关系路径更长来进行简单的修改,搜索空间会突然变得大得多。例如,在ComplexWebQuestions数据集上,如果我们允许核心关系路径高达3跳,那么平均而言,每个问题将有大约10,000个核心关系路径,这在计算上非常昂贵。
最近关于多跳知识库问答(KBQA)的工作通过定向搜索来解决该问题,即,在生成(t+l)跳关系路径之前仅保留前K项t-跳关系路径(Chen et al., 2019; Lanet al., 2019b)。然而,这种方法在生成关系路径时忽略了约束。我们观察到,在问题中发现的约束往往有助于减少搜索空间,并引导核心关系路径的生成朝着正确的方向发展。
以图1中的问题为例。给定一个部分核心关系路径(JeffProbstShow,natimated_for,y1,nominee,y2),如果我们要在y2扩展该路径,再增加一个关系,那么我们需要考虑与y2的绑定相关联的知识库(KB)中的所有关系,该知识库包括所有被JeffProbstShow提名的实体。但是如果我们先把约束(is_a,电视制片人)附加到y2,那么我们只需要考虑那些与“被提名参加JeffProbst秀的电视制片人”相关的关系。
因此,我们提出了一种改进的分阶段查询图生成方法,它不需要等待每个核心关系路径的完全生成再给其附加约束。这种更灵活的查询图生成方式,结合定向搜索机制和语义匹配模型来指导修剪,探索更小的搜索空间,同时仍然保持找到正确查询图的高几率。
- 查询图生成
形式上,我们的方法使用定向搜索迭代地生成候选查询图。我们假设第t次迭代产生一组K个查询图,记为为Gt。在第(t+l)次迭代中,对于每个g∈Gt,我们应用{extend、connect、aggregate}动作中的一个(在下面解释)来将g扩展到一个或更多的边缘和节点。我们为所有g∈Gt和适用于每个g的所有动作这样做。设G’t+1表示所有结果查询图的集合。然后,我们使用评分函数(在第2.4节中解释)对G’t+1中的所有查询图进行排序,并将它们的前K个放在Gt+1中。我们继续迭代直到不存在g∈Gt+1的得分比g∈Gt的得分高。
我们使用以下操作生成查询图。图2显示了这些操作的示例。
- 扩展操作(extend):通过R中的一个或者多个关系来扩展核心路径。如果当前查询图仅包含主题实体e,则扩展操作在知识库(KB)中找到与e相连的关系r,并增长路径r。它还使r的另一端成为lambda变量x。如果当前查询图具有lambda变量x,则扩展动作将x改变为存在变量y,通过对知识库(KB)执行当前查询图来在知识库(KB)中找到y的所有绑定,找到链接到这些实体之一的关系r,并且最后将r附加到y。r的另一端成为新的lambda变量x。
- 连接操作(connect):除了当前核心关系路径开始时的主题实体外,问题中经常发现其他基础实体。连接操作将这种基础实体e链接到任一个lambda变量x或者一个与x相连的存在变量的CVT节点6。为了决定使用哪个关系r来链接e和x,我们再次可以通过执行当前查询图来找到x的所有绑定,然后找到这些实体之一和e之间存在的关系。
- 聚合操作(aggregate):继Looet ai(2018)之后,我们可以使用一组预定义关键字从问题中检测聚合函数。聚合动作将检测到的聚合函数作为新节点附加到lambda变量x或一个CVT节点上(CVT节点:与x相连的存在变量)。
我们方法的新颖之处在于,扩展动作可以在连接和集合动作之后应用,而以前的方法不允许这样做。
- 查询图排序
在第t次迭代结束时,我们对G’t中的候选查询图进行排序。排序的方法是:为每个g∈G’t导出一个7维的特征向量vg,并将这些向量输入到一个全连接层,通过softmax函数导出p(g|Q)。
vg的第一个维度来自一个基于BERT的语义匹配模型。具体地说,我们通过构造g的一系列操作将g转换为一个关键词(token)序列,并在每个步骤向序列中依次添加实体和关系的文本描述。存在变量和lambda变量被忽略。例如,本文图2(a)所示的查询图被转换成以下序列:(jeff、probst、show、destination、for、adement)7
6在这里我们只考虑与lambda变量连接的存在变量,因为我们应该在过去的迭代中已经考虑其他存在变量。
7这个例子是为了说明目的。在实际的数据中,关系描述与图1中所展示的有所不同。因此,对于该示例,实际的token序列是不同的。我们还将问题转换为一系列标记。例如,“谁是Facebook创始人的妻子?”成为facebook创始人的妻子。然后,我们将查询图序列和问题序列连接成一个序列。
v的其他6个维度如下:第一个维度是查询图中所有基础实体的累计链接得分。第二个是查询图中出现的基础实体的数量。第三类至第三类分别是查询图中的实体类型、时间表达式和最高值。最后一个特性是查询图的回答实体的数量。
- 学习
为了训练我们的模型,我们使用成对的问题和正确答案,没有任何实际的真实查询图。在Daset ai(2018)框架下,我们使用REINFORCE算法以端到端的方式学习策略函数p_theta(g|Q),其中theta是我们想要学习的参数集,包括要更新的BERT参数和7维向量vg与全连接层的连接权重。我们使用Fl得分作为奖励函数。
实验实验
-
- 实施细则
我们的方法要求从问题中识别出实体,并将其链接到知识库(KB)中的相应条目。为了命名实体链接,我们使用ComplexWebQuestions数据集的现有链接工具8,以及与其他两个数据集的数据集一起发布的已经提取的主题实体。对于实体类型的链接,我们利用训练问题集和他们的答案来学习链接模型。对于时间表达式和最高链接,我们只是使用正则表达式和最高单词列表。最高级的单词人为映射到两个聚合函数:argmax和argmin。
我们使用BERT基础模型9来初始化排名器中的BERT模块。其它参数被随机初始化。对于BERT模型中的超参数,将丢弃率设置为0.1,隐层大小设置为768。神经元层数和多头注意力数被分别设置为6和12。我们使用最新的Freebase作为全部数据的知识库(KB),对于beam搜索,我们设置beam的大小K=3。
使用特殊的令牌[CLS]分隔它们。然后,我们使用标准的BERT模型(Devlin et ai..2019)处理整个序列,并在顶层获得分数。注意,我们在学习期间调整预训练的BERT参数。
- 数据集
我们使用三个数据集来评估我们的方法:ComplexWebQuestons(CWQ)(Talmor和Berant),
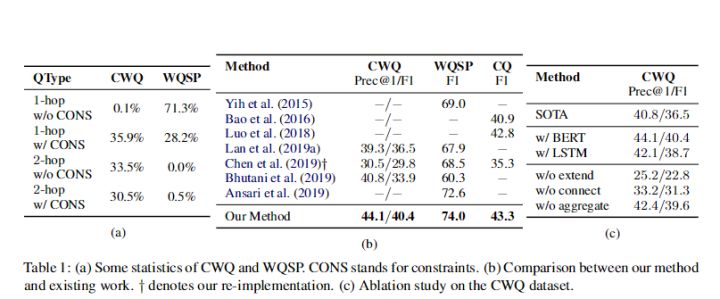
- 、WebQuestionsSP(WQSP)(Yih等人,2015年)和复杂问题(CQ)(Bao等人,2016年)。我们把ComplexWebQuestons(CWQ)作为主要的评估数据集,因为ComplexWebQuestons(CWQ)具有多跳关系和约束的复杂问题的比例非常高,如表1a.11所示。注意,我们不能为复杂问题(CQ)数据集收集类似的统计数据,因为它没有提供基础真值查询图,但我们观察到复杂问题(CQ)中的主要问题为1跳关系。
- 比较方法
我们将我们的方法和下面的现有方法相比较。首先,我们比较现有的无法处理多跳问题的分阶段查询图生成方法(Yih et ai,2015;Bao et ai,2016;Loo et ai,2018)。接下来,我们与(Lan et ai.,2019a)进行比较,后者可以处理约束并考虑多跳关系路径,但没有使用波束搜索或约束来减少搜索空间。我们还与(Chen et al.,2019)进行比较,它使用波束大小为1的波束搜索来处理多跳问题,但没有处理约束问题。最后,我们与(Bhutaniet al., 2019)和(Ansari et al., 2019)进行比较。Bhutaniet (2019)将复杂的问题分解为简单的问题,并在CWQ12上实现了Prec@1的SOTA。Ansari et ai(2019)通过从问题token逐个生成查询程序,在WebQuestionsSP(WQSP)上实现了SOTA。
- 主要结果
我们在表1b中显展示了总体比较。我们可以看到,在ComplexWebQuestons(CWQ)数据集上,我们的方法在F1和Prec@1上取得了最佳的效果,并且取得提升也很大,在Prec@1上有3.3%的提升,在F1上有3.9%的提升。这验证了我们的假设,即我们的方法特别适用于具有约束和多跳关系的复杂问题。对于其他两个数据集,WebQuestionsSP(WQSP)和复杂问题(CQ),我们的方法也达到了SOTA,优于以往的方法 ,证明了我们的方法的鲁棒性。
8该工具可以在https://developers.google.com/知识图上找到。
9预先训练的BERT基础模型可以在https://github.com/huggingface/pyphotor-transformers上找到。
10 知识库(KB)可从https://developers.google.com/freebase/下载。
11 注意,我们将具有CVT节点的2跳关系路径视为1跳路径。
12我们注意到,在ComplexWebQuestons(CWQ)的领导板中,Sun et ai(2019)实现了最好的Prec1。然而,它们的方法使用带注释的主题实体,因此这里不可比。
(c)
- 消融研究
我们还进行了一次消融研究以便更好地理解我们的模型。为了验证该方法的有效性不是由于BERT的使用,我们用LSTM代替了BERT。从表lc中可以看出,基于LSTM的方法的版本仍然可以胜过现有技术。这表明,我们的模型的有效性不仅仅是由于BERT的使用。我们还测试了我们方法的三个版本,每个版本都删除了一个操作,以便了解是否需要所有三个操作。结果也显示在表lc中。我们可以看到,聚合动作是最不重要的动作,而扩展动作是最重要的。然而,我们需要将所有三个行动结合在一起,以实现最佳性能。
- 误差分析
我们随机抽取100个错误案例进行人工检查。我们将错误归纳为以下几类。
排序错误:65%的错误来自查询图的错误预测。我们仔细观察这些错误案例。我们发现即使用人类的判断力也难以发现某些关系。例如,我们的模型错误地预测了“谁是尼克松的副总统?”正确的关系是“副总裁”。理解“副总裁”是“副总裁”的缩写,如果在培训数据中没有观察到这种映射,则需要外部知识。主题链接错误:我们观察到由于实体或表达式链接错误而出现的错误有27%以上。例如,“科里·泰勒弹什么吉他?”具有约束类型“吉他”,但是在链接过程中没有检测到它。生成限制:查询图生成策略的限制导致6%以上的错误。对于“约翰·亚当斯担任总统之前有哪些工作”的问题,我们不可能找到与我们的策略相匹配的查询图。
- 结论
本文针对多跳关系和约束的复杂问题,提出了一种改进的分段查询图生成方法。通过早期将约束引入查询图中,结合束搜索,可以限制搜索空间。实验表明,在ComplexWebQuestions数据集上,我们的方法明显优于现有的方法,在另外两个知识库问题回答(KBQA)数据集上也优于现有技术。















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









