







 本文介绍了 ACL 2020 上的一篇论文,研究了如何处理知识库问答中的多跳复杂问题,提出了一种改进的分阶段查询图生成方法,将约束和关系路径扩展相结合,以更有效地减少搜索空间,从而在三个基准 KBQA 数据集上达到最先进的水平。
本文介绍了 ACL 2020 上的一篇论文,研究了如何处理知识库问答中的多跳复杂问题,提出了一种改进的分阶段查询图生成方法,将约束和关系路径扩展相结合,以更有效地减少搜索空间,从而在三个基准 KBQA 数据集上达到最先进的水平。

©PaperWeekly 原创 · 作者|舒意恒
学校|南京大学硕士生
研究方向|知识图谱
先前从知识库回答复杂问题的工作通常分别解决两种类型的复杂性:具有约束的问题和具有多跳关系的问题。
在本文中,作者同时处理两种类型的复杂性。通过观察发现,尽早将约束条件纳入查询图可以更有效地减少搜索空间,作者提出了一种改进的分阶段查询图生成方法,该方法具有更灵活的生成查询图的方式。该文实验清楚地表明,其方法在三个基准 KBQA 数据集上达到了最先进的水平。

论文标题:Query Graph Generation for Answering Multi-hop Complex Questions from Knowledge Base
论文来源:ACL 2020
论文链接:https://www.aclweb.org/anthology/2020.acl-main.91.pdf

介绍
知识库问答尝试根据知识库回答事实类问题。它最近吸引了很多研究者的关注。知识库问答的早期研究,关注于只包含一个关系的简单问题。但是,真实的问题通常更加复杂,因此最近的研究关注于复杂的知识库文档。
当前有两种类型的复杂性被研究。
第一,带有约束的单关系问题。例如一个问题,谁是第 1 任美国总统?其中有一个简单的关系是,某个国家的总统。但也有一个约束,也就是第一个这个条件需要被满足。针对这种问题,分阶段的查询图生成方法已经被提出。它首先识别一条关系路径,然后将约束添加进去,生成一个查询图。
第二,有多跳关系的问题。例如一个问题,谁是 Facebook 创始者的妻子?这个答案与 Facebook 之间有两条关系。一个是创始者,另一个是妻子。为了回答这些问题,我们需要考虑更长的关系路径来获得正确的答案。
最主要的挑战是如何限制搜索空间,也就是减少要考虑的多跳关系路径的数量,因为搜索空间随着关系路径的长度,指数级的增长。一种解决方案是使用波束搜索。然而作者认为,几乎没有工作能够同时处理这两种复杂性。
在该文中,作者尝试同时处理两种复杂性,提出了修改分阶段的查询图生成方法以支持更长的关系路径。然而。相比在构建关系路径之后添加约束。作者尝试将添加约束和扩展关系路径同时进行。这使得算法能更有效的减少搜索空间。

方法
2.1 预备
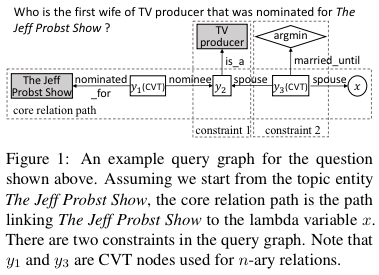
作者的方法很大程度上受启发于现有的分阶段查询图生成方法。一个查询图有 4 种类型的节点,实体(知识库中已有的实体),存在变量(未确定的实体),lambda 变量(未确定的实体,表示答案)和聚合函数(针对实体集合的处理)。一个查询图应该恰好有一个 lambda 变量,0 个或若干个存在变量和聚合函数。
作者将分阶段查询图生成方法总结如下。
第一,从一个问题中的实体开始,找到核心的关系路径,将主题实体和一个 lambda 变量连接。
第二,在第 1 步的基础上,从一个核心关系路径,连接一个或多个在问题中找到的约束。一个约束包含一个实体加关系或一个聚合函数加关系。
第三。在前 2 步的基础上。通过与问题的相似度,对查询图进行排序。这通常是由神经网络完成的,例如 CNN。
第四,执行排序最高的查询图,来获得答案实体。
2.2 动机
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









