






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:EMMA NING
编译:ronghuaiyang
导读
微软刚刚开源了Transformer的突破性优化,大大提升了CPU和GPU上的推理速度。
用于自然语言处理的最流行的深度学习模型之一是BERT。由于需要大量的计算,在大规模推断上BERT计算量非常大,甚至在严格的延迟约束下都不可能。最近,我们分享了“Bing has improved BERT inference on GPU for its real-time”,在必应的延迟限制内,每秒服务超过100万个BERT推断。我们很高兴地宣布,微软已经在ONNX Runtime中开源了这些优化的增强版本,并将它们扩展到GPU和CPU上。
有了ONNX Runtime,人工智能开发人员现在可以很容易地在CPU和GPU硬件上生产出高性能的大型transformer模型,使用和微软一样的技术来服务客户。
Bing里的自然语言处理
为了向我们的客户提供最相关的结果,Bing使用了最先进的自然语言处理(NLP)技术来更好地理解用户查询、网页和其他文档。NLP的一个关键组件是语言表示模型,如BERT、RoBERTa或MT-DNN。必应开发和调优了自己的语言表征模型,用于网络搜索,问答,以及图像的描述等任务上面。
然而,在实时生产环境中使用大型的transformer network会带来延迟和成本方面的挑战,因为为每个查询运行12层或24层的BERT在计算上非常昂贵。正如去年11月宣布的那样,我们首先使用知识蒸馏将较大的模型浓缩成一个三层的BERT模型,没有显著的精度损失,显著降低了计算成本。但是,经过提炼的三层BERT模型仍然以77ms的延迟为基准,每秒运行数百万个查询和文档的速度仍然非常昂贵。为了进一步优化,使用c++ api重新实现了整个模型,充分利用了GPU架构,与CPU相比,该架构实现了800x的吞吐量提升。
一旦这些优化在Bing产品中成功使用,就有更多的事情要做。由于这些大型的transformer network可用于web搜索之外的更多NLP任务,所以我们需要一种简单的方法来为其他人共享这些有益的工作。当前的解决方案要求每个模型开发人员使用我们的c++库重新实现模型,这是非常耗时的。为了进一步普及transformer推理并使其他人能够从这些改进中获益,我们进一步优化了它们,将它们扩展到CPU,并在ONNX Runtime中开放它们的源代码。
使用ONNX Runtime实现17x BERT推理加速
ONNX Runtime是一个高性能的机器学习模型推理引擎。它与PyTorch、TensorFlow以及许多其他支持ONNX标准的框架和工具兼容。ONNX Runtime设计了一个开放和可扩展的体系结构,通过利用内置的图形优化和跨CPU、GPU和边缘设备的各种硬件加速功能,可以轻松地优化和加速推理。ONNX Runtime可以很容易地插入到你的技术堆栈中,因为它可以在Linux、Windows、Mac和Android上工作,并且为Python、c#、c++、C和Java提供了方便的api。
像BERT这样的Transformer模型由许多操作符组成。图形优化,从小的图形简化和节点清除到更复杂的节点融合和布局优化,是构建在ONNX Runtime中的一项基本技术。由于BERT模型主要由堆叠的Transformer单元组成,我们通过将多个基本运算符的关键子图融合成CPU和GPU的单一内核来优化每个单元,包括Self-Attention层、LayerNormalization层和Gelu层。这大大减少了大量基本计算之间的内存复制。
另外,在Self-Attention的CPU实现中,根据Self-Attention heads的数量对矩阵Q、K、V的列进行了划分。通过这种优化,我们可以显著提高并行性,并充分利用可用的CPU内核。并且,Q、K、V全连接后的转置运算可以在GEMM中进行计算,进一步降低了计算成本。
通过这些优化,ONNX Runtime在Azure标准NC6S_v3 (GPU V100)上对128个序列长度和批大小为1的BERT-SQUAD执行推理:
12层 fp16 BERT-SQUAD为1.7ms。
24层 fp16 BERT-SQUAD为4.0ms。
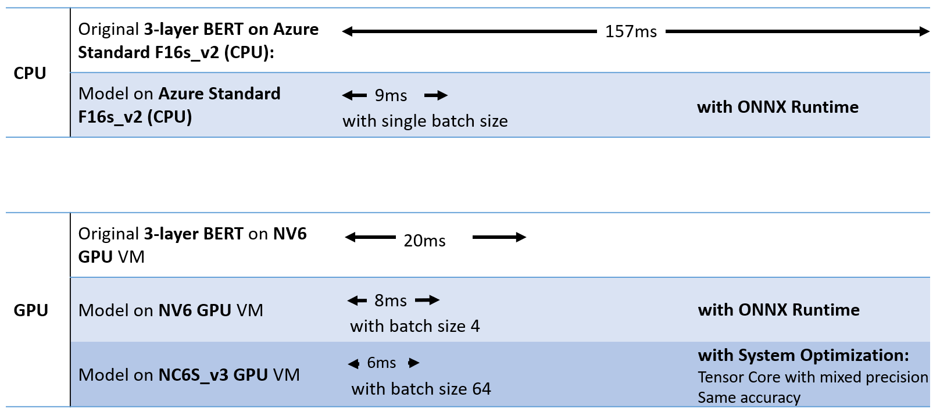
下面是ONNX Runtime上3层fp32 BERT与128序列长度的详细的性能数字。在CPU上,我们看到了17x的加速,在GPU上,我们看到了超过3倍的加速。
在全局大规模使用ONNX Runtime推理
随着最新的BERT优化在ONNX Runtime可用,Bing将transformer推理代码库转换为联合开发的ONNX Runtime。ONNX不仅在Bing流量范围内对大型transformer网络进行了推理,而且新的优化还降低了Bing的延时。此外,Bing发现ONNX Runtime更容易使用,并将新场景优化的重用时间从几天缩短到几个小时。
除了Bing之外,ONNX Runtime还被微软的数十种产品和服务所部署,包括Office、Windows、Cognitive services、Skype、Bing Ads和PowerBI等。ONNX Runtime用于计算机视觉、语音、语言处理、预测等各种模型。与以前的推理解决方案相比,团队在相同的硬件上实现了最多18倍的性能改进。
开始使用BERT加速
你可以利用微软的技术在你自己的产品中使用的相同的加速,不管你是针对云还是智能边缘,或者你是使用cpu还是gpu。我们开始:
使用或从流行的框架(如PyTorch或TensorFlow)加载预训练的模型。
通过从PyTorch导出或从TensorFlow/Keras转换为ONNX格式,为优化推断准备模型。
使用ONNX Runtime进行跨多个平台和硬件的高性能推理。
我们提供了PyTorch BERT加速:http://aka.ms/pytorchbertwithort和TensorFlow BERT加速:http://aka.ms/tfbertwithort的示例代码。

—END—
英文原文:https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()

















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









