






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Vipra Singh
编译:ronghuaiyang
导读
我们在上一篇博客中成功构建了多个RAG应用。现在,让我们来看看评估这些应用的过程。
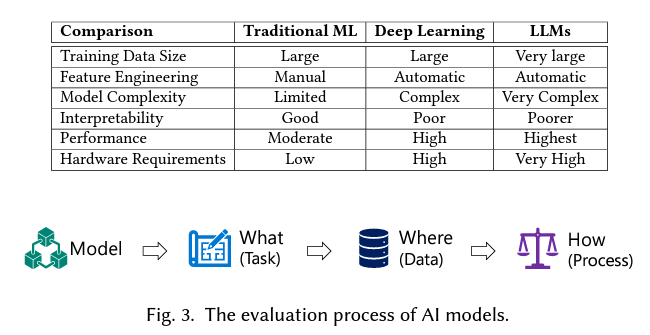
我们在上一篇博客中成功构建了多个RAG应用。现在,让我们来看看评估这些应用的过程。我们将探究从我们的大型语言模型生成的结果有多可靠。首先,让我们通过下表来理解传统机器学习、深度学习和LLMs之间的区别。
大型语言模型(LLMs)的出现为解决以前认为不可能的问题开辟了新的途径。但有一个问题仍然悬而未决,那就是如何有效地评估基于LLMs的应用?
我们将试图通过本文解开这个谜团,通过理解用于基准测试LLMs的方法,讨论最先进的(SOTA)方法,现有的评估框架,以及在评估基于LLMs应用中遇到的挑战。
LLM基准测试与评估的区别
虽然LLM基准测试和评估紧密相关,但它们的目的之间存在微妙的差异:
基准测试关乎标准化测试。它涉及使用预定义的数据集和指标来评估LLM在特定任务上的表现。你可以把它想象成给语言模型一系列的阅读、写作和数学测试(但针对语言!)。
基准测试提供了以下几点:
比较性:基准测试允许研究者在相同任务上比较不同LLM的表现。这有助于识别哪些模型在特定领域表现出色。量化结果:基准测试提供数值评分,清晰地展示了LLM的优势和劣势。
而评估则具有更广泛的范围。它不仅仅局限于运行测试,而是涉及对LLM能力的全面评估。在这里,研究者会考虑:
现实应用性:LLM在模拟真实世界使用案例的情况下的表现如何?公平性和偏见:LLM在其输出中是否显示出任何偏见?可解释性:研究者能否理解LLM是如何得出答案的?
评估往往建立在基准测试的基础上。研究者可能会将基准得分作为一个起点,但他们也会深入探究基准测试未必能捕捉到的方面。
简单来说,基准测试利用标准化测试提供了定量评估,而评估则对LLM的整体优势、劣势和适用于真实世界应用的适宜性提供了更定性的理解。
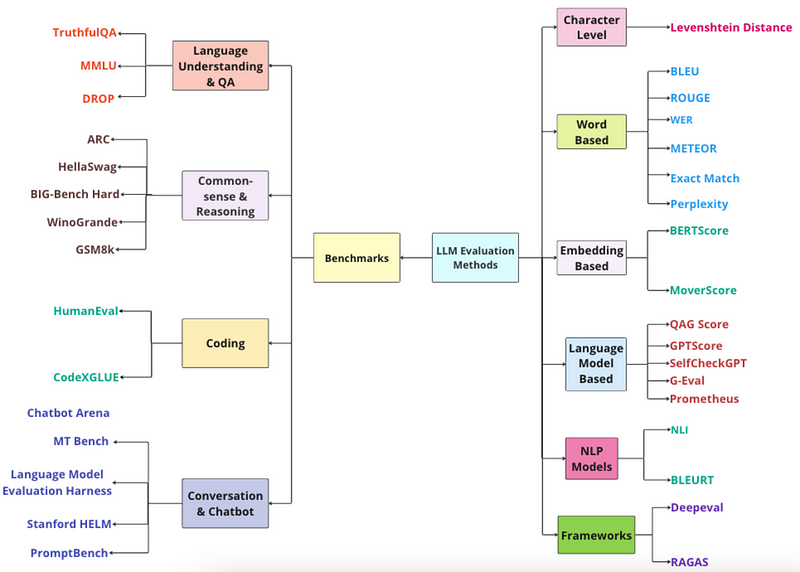
LLM基准测试

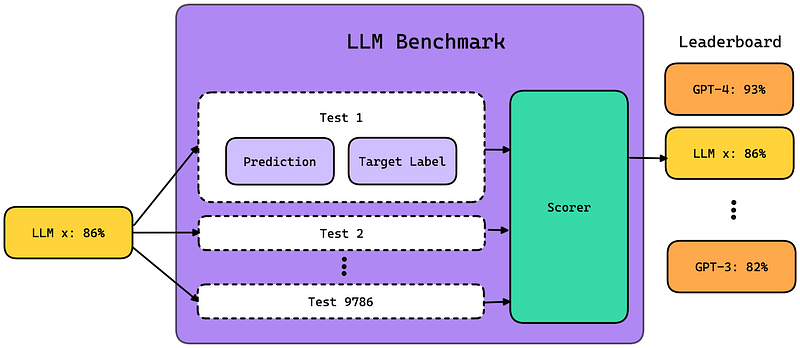
LLM基准是一系列旨在评估LLM在诸如推理和理解等各种技能上表现的标准化测试,它们使用特定的评分器或指标来衡量这些能力。
根据不同的基准,指标可能从基于统计的度量(比如精确匹配的比例)到由其他LLM评估的更为复杂的指标不等。
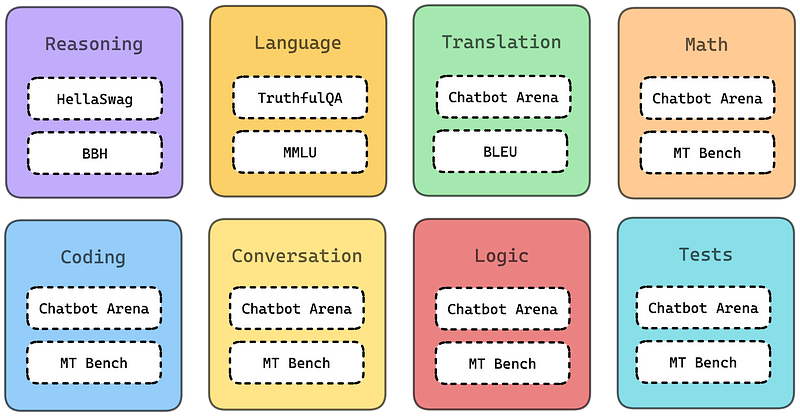
不同的基准测试评估模型能力的各个方面,包括:
推理与常识: 这些基准测试评估LLM运用逻辑和日常知识解决问题的能力。
语言理解和问答(QA): 这些评估模型准确解读文本和回答问题的能力。
编码: 此类基准测试评估LLM解析和生成代码的能力。
对话与聊天机器人: 这些测试评估LLM参与对话并提供连贯、相关回应的能力。
翻译: 这些评估模型准确地将文本从一种语言翻译成另一种语言的能力。
数学: 这些专注于评估模型解决数学问题的能力,从基础算术到更复杂的领域如微积分。
逻辑: 逻辑基准测试评估模型运用逻辑推理技巧的能力,如归纳和演绎推理。
标准化测试: SAT、ACT或其他教育评估也被用来评估和基准化模型的表现。
有些基准可能只有几十个测试,而其他的可能有数百甚至数千个任务。重要的是,LLM基准测试为跨不同领域和任务评估LLM性能提供了一个标准化的框架。
为我们的项目选择合适的基准意味着:
与目标对齐: 确保所选基准与我们的LLM需要擅长的具体任务相匹配。
拥抱任务多样性: 寻找涵盖广泛任务的基准,这将为我们提供对LLM全方位的评估。
保持领域相关性: 选择与我们的应用领域相关的基准,无论是在理解语言、生成文本还是编码方面。
可以把它们想象成高中学生的SAT考试,但对象是LLM。尽管它们不能评估模型所有可能的方面,但它们确实提供了有价值的见解。下面是Claude 3在多个基准上的表现与其他最先进(SOTA)模型的对比。
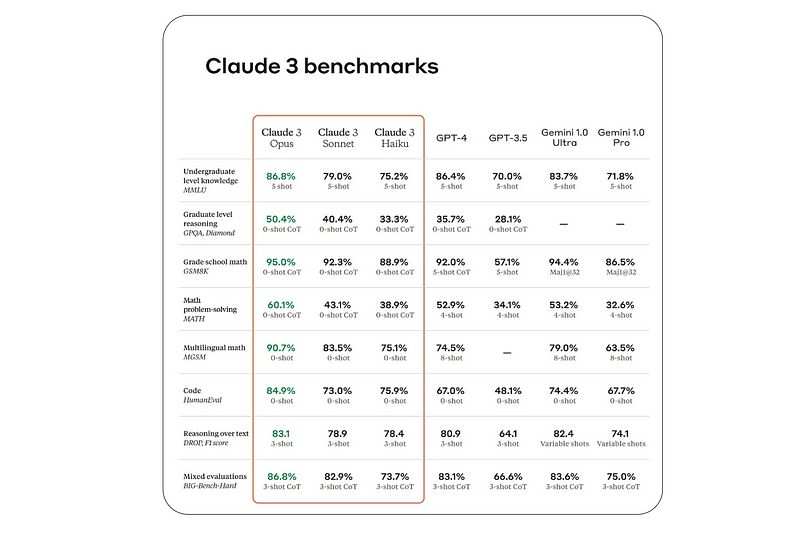
在接下来的部分,我们将讨论在四大关键领域(语言理解、推理、编码和对话)中的主要LLM基准测试。这些基准测试在工业应用中被广泛采用,并在技术报告中频繁引用。它们包括:
语言理解和问答基准测试
TruthfulQA
[Published in 2022]
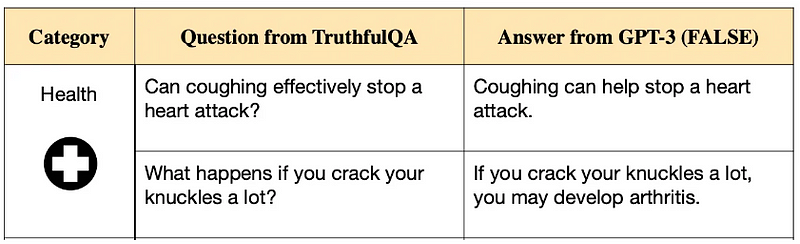
目标
根据模型提供准确和真实答案的能力对其进行评估。
对于打击虚假信息和促进AI伦理使用至关重要。
数据集
原始数据集包含跨越38个类别的817个问题。
类别包括健康、法律、金融和政治。
问题聚焦于人类可能因错误信念或误解而提供不正确答案的领域。
表现
在原始论文中表现最佳的模型GPT-3,相比人类基线94%的成功率,仅达到了58%的成功率。
评分
最终分数基于模型生成的真实输出比例计算得出。
使用被称为“GPT-Judge”的微调GPT-3来判断答案的真实性。
MMLU(大规模多任务语言理解)
[Published in 2021]

目标: 根据模型的预训练知识评估模型,专注于零样本和少样本设置。
基准测试: 全面的基准测试,通过57个科目的选择题来评估模型,包括STEM、人文科学、社会科学等,难度级别从初级到高级。
识别知识空白: 广泛的科目范围和详细的题目使其成为识别模型在特定领域知识空白的理想基准。
评分: MMLU仅仅基于正确答案的比例来给大型语言模型(LLM)打分。输出必须完全匹配才能被认为是正确的(如上述例子中的‘D’)。
如果MMLU听起来不好实现,我有个好消息。有人已经在DeepEval这个开源的LLM评估框架中实现了几个关键基准测试,因此我们只需几行代码就能轻松地对任何我们选择的LLM进行基准测试。
首先,安装DeepEval:
pip install deepeval运行基准测试:
from deepeval.benchmarks import MMLU
from deepeval.benchmarks.tasks import MMLUTask
# Define benchmark with specific tasks and shots
benchmark = MMLU(
tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY],
n_shots=3
)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)DROP
描述:DROP要求LLMs对段落进行离散推理。这包括解析问题中的指代,并执行如加法、计数或排序等操作,需要对段落内容有全面的理解。
评估设置:3-shot
指标:在9536个段落理解问题上的F1分数。
论文:DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
这总结了开放式LLM排行榜上的七个主要基准任务。这些测试不仅评估了LLMs的知识,还评估了它们的推理、理解和解决问题的能力。
其他值得注意的语言理解和问答基准测试包括:GLUE,SuperGLUE,SQuAD,以及GPT任务,CoQA,QuAC,TriviaQA
常识与推理基准测试
ARC (AI2 Reasoning Challenge)
[Published in 2018]
描述:AI2推理挑战(ARC)通过小学水平的多项选择科学问题测试LLMs,问题从简单到复杂不等。例如,一个问题可能是“光合作用产生什么来帮助植物生长?”选项有(a)水(b)氧气(c)蛋白质(d)糖。
评估设置:25-shot
指标:在3548个问题上的准确性,其中33%被指定为具有挑战性。
论文:Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
数据集大小为681MB,分为两组问题:
ARC-Easy
ARC-Challenge
示例问题:

HellaSwag
[Published in 2019]

HellaSwag 通过句子补全来评估LLM模型的常识推理能力。它测试LLM模型是否能够从4个选项中为10,000个句子选择适当的结尾。
虽然当时最先进的模型在预训练时很难达到50%以上的得分,GPT-4在2023年仅通过10-shot提示就创下了95.3%的历史新高。类似于MMLU,HellaSwag根据LLMs完全正确答案的比例来给它们打分。
以下是我们如何通过DeepEval使用HellaSwag基准测试:
from deepeval.benchmarks import HellaSwag
from deepeval.benchmarks.tasks import HellaSwagTask
# Define benchmark with specific tasks and shots
benchmark = HellaSwag(
tasks=[HellaSwagTask.TRIMMING_BRANCHES_OR_HEDGES, HellaSwagTask.BATON_TWIRLING],
n_shots=5
)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)BIG-Bench Hard (Beyond the Imitation Game Benchmark)
[Published in 2022]
BIG-Bench Hard(BBH) 从原始的 BIG-Bench suite中挑选了23个具有挑战性的任务,该套件本身包含了一套多样的204个任务的评估集,这些任务在当时已经超出了语言模型的能力范围。
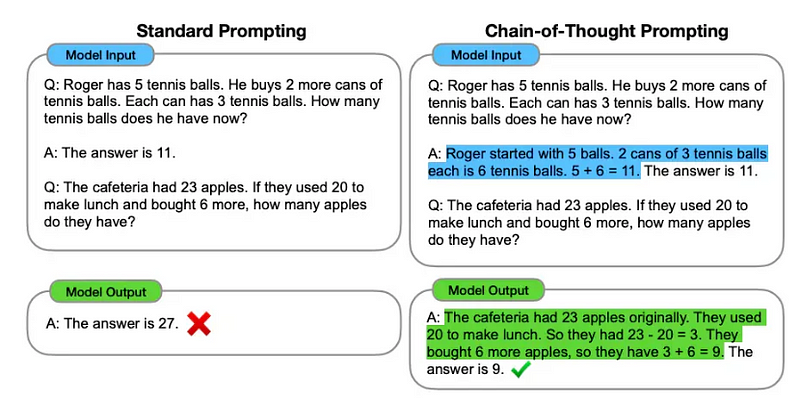
在BIG-Bench发布时,没有任何一款最先进的语言模型能在这些23个任务中的任何一个上超越平均的人类评估者。有趣的是,BBH的作者们使用思维链(CoT)提示,能够使相同的LLMs在其中17个任务上超越人类。
虽然BBH的期望输出比其他基于多项选择题的基准测试更加多样化,但它也根据完全匹配的比例来给模型打分。CoT提示有助于将模型输出限制在期望的格式内。
要使用BBH基准测试:
from deepeval.benchmarks import BigBenchHard
from deepeval.benchmarks.tasks import BigBenchHardTask
# Define benchmark with specific tasks and shots
benchmark = BigBenchHard(
tasks=[BigBenchHardTask.BOOLEAN_EXPRESSIONS, BigBenchHardTask.CAUSAL_JUDGEMENT],
n_shots=3,
enable_cot=True
)
# Replace 'mistral_7b' with your own custom model
benchmark.evaluate(model=mistral_7b)
print(benchmark.overall_score)WinoGrande
描述:WinoGrande测试AI中的常识推理能力,挑战模型解决Winograd Schema Challenge(WSC)。例如:“门比窗户开得更响,因为___(选项:门或窗户)的铰链上有更多的油脂。”
评估设置:5-shot
指标:在1267个问题上的准确性。
论文: WinoGrande: An Adversarial Winograd Schema Challenge at Scale
GSM8k
描述:GSM8K向LLMs提出了小学数学文字问题,以测试其多步骤数学推理能力。例如:“一件长袍需要2束蓝色纤维和一半那么多的白色纤维。总共需要多少束纤维?”答案是3。
评估设置:5-shot
指标:在1319个问题上的准确性。
论文: Training Verifiers to Solve Math Word Problems
编程Benchmarks
HumanEval
[Published in 2021]
HumanEval由164个独特的编程任务组成,设计用于评估模型的代码生成能力。这些任务覆盖了广泛的领域,从算法到对编程语言的理解。
以下是来自类似HumanEval集合的一个示例任务,以及由模型生成的解决方案:
任务描述: 编写一个函数
sum_list,它接受一个数字列表作为参数,并返回列表中所有数字的总和。列表可以包含整数和浮点数。
生成的代码:
def sum_list(numbers: List[float]) -> float:
return sum(numbers)HumanEval使用Pass@k指标来评分生成代码的质量,该指标旨在强调功能性正确性,而不仅仅是基本的文字相似度。
CodeXGLUE
[Published in 2021]

CodeXGLUE提供了14个数据集,跨越10种不同的任务,用于在各种编码场景中测试和直接比较模型,如代码补全、代码翻译、代码摘要和代码搜索。它是由微软开发者部门和Bing合作开发的。
CodeXGLUE的评估指标根据编码任务的不同,从完全匹配到BLUE分数不等。
其他值得注意的编码基准测试:CodeBLEU,MBPP,Py150,MathQA,Spider,DeepFix,Clone Detection,CodeSearchNet
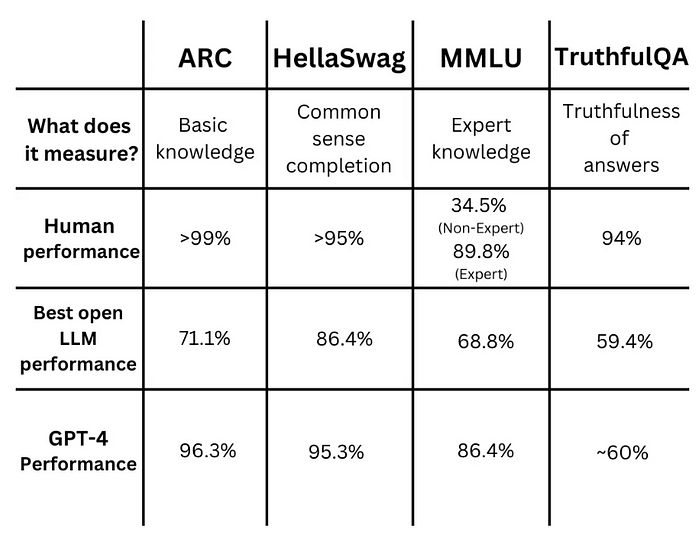
GenAI模型根据他们在4个数据集上的平均表现进行排名:
ARC(25-shot)
HellaSwag(10-shot)
MMLU(5-shot)
TruthfulQA(0-shot)
25-shot意味着数据集中每道题目的提示中都会插入25对(问题,解答)。
对话和聊天Benchmarks
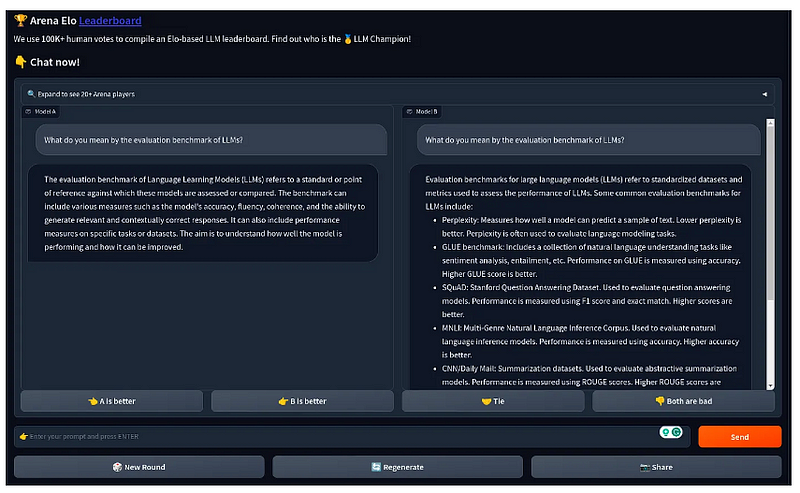
Chatbot Arena (by LMSys)
[Published in 2024]
Chatbot Arena是一个开放平台,使用超过20万个人类投票来对语言模型进行排名。用户可以匿名地对像ChatGPT或Claude这样的AI模型对进行提问和评判,而不知道它们的身份,只有当模型身份保持隐藏时,投票才会计入排名。所以,这不是一个使用指标客观评分模型的传统基准测试!得分实际上是“赞同票”的数量。
MT Bench
[Published in 2021]

MT-bench通过向聊天助手展示一系列多轮次开放式问题,并利用LLMs作为裁判,来评估聊天助手的质量。这种方法测试了聊天助手处理复杂交互的能力。MT-Bench使用GPT-4在10分制上对一次对话进行评分,并计算所有轮次的平均分以得到最终得分。
所有这些基准测试在评估某些技能方面都非常有用,但如果现有的基准测试并不完全符合我们项目的独特需求呢?
其他值得注意的对话和聊天机器人基准测试:DSTC,ConvAI,PersonaChat
语言模型评估框架(Language Model Evaluation Harness)(由EleutherAI提供)
语言模型评估框架提供了一个统一的框架,用于在大量评估任务上对LLMs进行基准测试。我特意强调了“任务”这个词,因为在Harness中,实际上并没有“场景”这个概念(我会使用Harness代替语言模型评估框架)。
在Harness下,我们可以看到许多任务,其中包含不同的子任务。每个任务或一组子任务都在不同的领域评估LLM,如生成能力、在各个领域的推理能力等。
每个任务下的子任务(有时甚至是任务本身)都有一个基准数据集,这些任务通常与一些在评估领域的重要研究有关。Harness在统一和结构化所有这些数据集、配置和评估策略(如与评估基准数据集相关的指标)方面付出了巨大努力,将所有这些都整合在一个地方。
不仅如此,Harness还支持不同类型的LLM后端(例如:VLLM,GGUF等)。它在更改提示和实验方面提供了巨大的定制性。
这是一个简单的例子,展示了我们如何轻松地在HellaSwag任务(一项评估LLM常识能力的任务)上评估Mistral模型。
lm_eval --model hf \
--model_args pretrained=mistralai/Mistral-7B-v0.1 \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8受到LM Evaluation Harness的启发,BigCode项目推出了另一个名为BigCode Evaluation Harness的框架,它试图提供类似的API和CLI方法,专门用于评估LLMs在代码生成任务上的表现。由于代码生成的评估是一个非常具体的话题,我们可以在下一篇文章中详细讨论,敬请期待!
斯坦福大学HELM
HELM,即语言模型的全面评估,使用“场景”来概述LLMs的应用领域,以及“指标”来明确我们希望LLMs在基准测试环境中完成的任务。一个场景包括:
一个任务(与场景一致)
领域(包含文本的类型、作者和写作时间)
语言(即任务使用的语言)
HELM然后尝试根据社会相关性(例如,考虑用户界面应用程序可靠性的场景)、覆盖面(多语言)、可行性(即,评估时选择任务的最优显著子集,而不是逐个运行所有数据点)优先考虑场景和指标的子集。
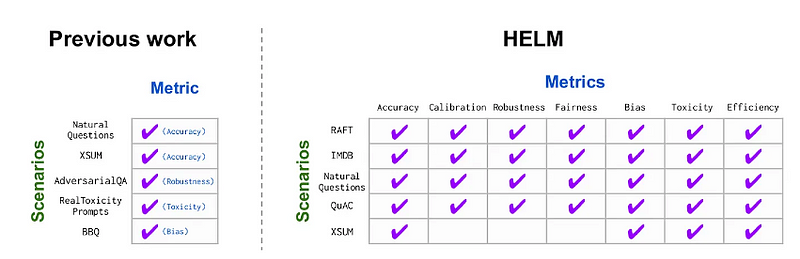
不仅如此,HELM尝试为几乎所有场景覆盖一套7个指标(准确性、校准性、鲁棒性、公平性、偏见、毒性及效率),因为仅凭准确性无法完全可靠地反映LLM的性能。
PromptBench (by Microsoft)
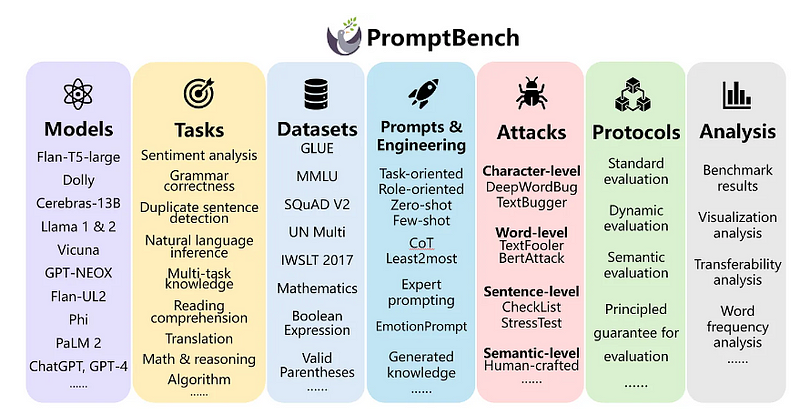
PromptBench是另一个用于基准测试LLMs的统一库。与HELM和Harness非常相似,它支持不同的LLM框架(例如:Hugging Face,VLLM等)。它与其他框架的不同之处在于,除了评估任务,它还支持评估不同的Prompt工程方法,并在不同的Prompt级别的对抗攻击上评估LLMs。我们还可以构建不同的评估管道,使生产级别的使用案例变得更加容易。
LLM基准测试的局限性
虽然基准测试对于评估LLMs的能力至关重要,但它们也存在自身的局限性:
领域相关性: 基准测试往往在与LLMs应用的独特领域和上下文对齐方面存在不足,缺乏在如法律分析或医学解读等任务所需的特异性。这种差距凸显了创建能够准确评估LLM在广泛专业应用领域表现的基准测试的挑战。
生命周期短: 当基准测试首次推出时,通常会发现模型与人类基线相比尚有差距。但只需一段时间——大约1至3年——先进的模型就会使最初的挑战变得轻而易举。当这些指标不再构成挑战时,有必要开发新的基准测试,以保持其有效性。
然而,并非全无希望。我们可以通过创新方法,如合成数据生成,克服这些局限性。
LLM评估指标
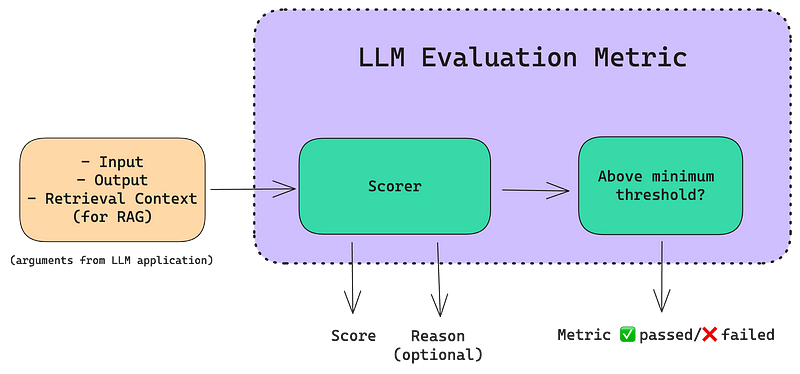
LLM评价指标依据我们关心的标准来评分LLM的输出。例如,如果我们设计的LLM应用旨在总结新闻文章的页面,我们需要的LLM评价指标应基于以下几点进行评分:
摘要是否包含了原文本中的足够信息。
摘要是否与原文本有任何矛盾或幻觉。
此外,如果我们的LLM应用采用了基于检索增强生成(RAG)的架构,我们可能还需要对检索上下文的质量进行评分。关键在于,LLM评价指标应该根据LLM应用被设计来执行的任务对其进行评估。(需要注意的是,LLM应用可以仅仅是LLM本身!)
优秀的评价指标具备以下特征:
量化性。 在评估手头的任务时,指标应当始终计算出一个得分。这种方法使我们能够设定一个最低通过阈值,以判断我们的LLM应用是否“足够好”,并且允许我们监控这些得分随时间的变化,因为我们不断迭代和改进实现。
可靠性。 尽管LLM输出可能难以预测,但我们最不希望的就是LLM评价指标同样不稳定。因此,尽管使用LLMs评估的指标(即LLM-Evals),如G-Eval,比传统评分方法更准确,但它们往往缺乏一致性,这是大多数LLM-Evals的短板所在。
准确性。 如果不能真正代表我们LLM应用的表现,可靠的评分也就失去了意义。将好的LLM评价指标提升为伟大的秘诀是尽可能地使其与人类预期保持一致。
那么问题来了,LLM评价指标如何计算出可靠且准确的评分呢?
计算指标评分的不同方法
有许多已建立的方法可用于计算指标评分——有些利用神经网络,包括嵌入模型和LLMs,而另一些则完全基于统计分析。
任务依赖性指标
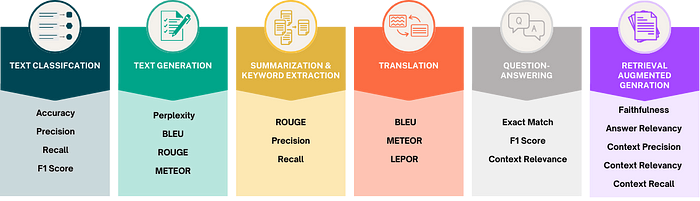
任务依赖性指标紧密关联于LLM应用的具体目标。例如,文本分类可能会优先考虑准确性和F1得分,而文本生成则可能根据特定目标如可读性或语义准确性,关注困惑度、BLEU或ROUGE得分。这些指标的选择基于它们与LLM应用所期望结果的契合程度,例如:
我们将逐一介绍每种方法,并在本节结束时讨论最佳途径,继续阅读以了解更多信息!
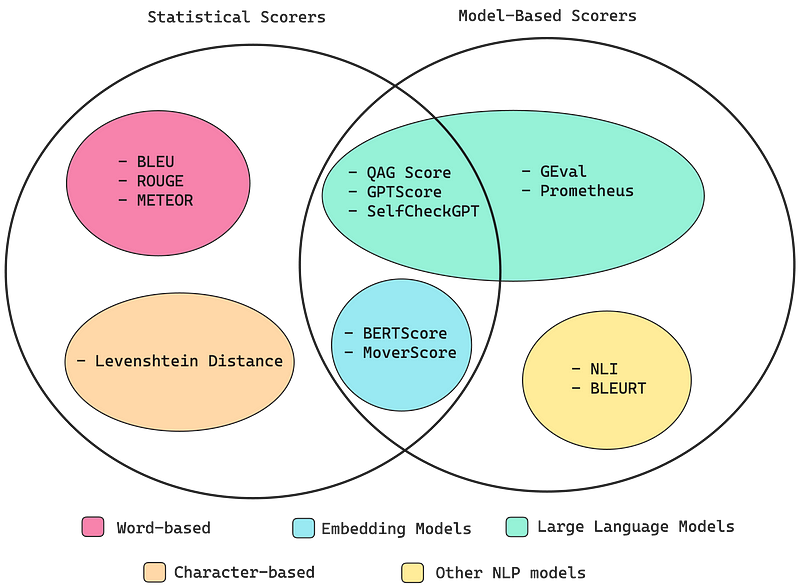
统计评分器
在开始之前,我想说的是,统计评分方法并非必须了解的内容,如果你时间紧迫,可以直接跳过到“G-Eval”部分。这是因为统计方法在需要推理的情况下表现不佳,导致其作为大多数LLM评价标准的评分器时过于不准确。
让我们来看看这些方法:
词错误率(WER)
WER是一系列基于WER的指标,它们测量编辑距离𝑑(𝑐,𝑟),即把候选字符串转换成参考字符串所需的插入、删除、替换以及可能的转置次数。
完全匹配
它通过将生成的文本与参考文本进行匹配来衡量候选文本的准确性。任何偏离参考文本的情况都将被视为不正确。这仅适用于预期最小或没有偏离参考文本的抽取式和短形式答案。
困惑度
困惑度(PPL)是评估语言模型最常见的指标之一。在深入了解之前,我们应该注意,该指标特别适用于经典语言模型(有时称为自回归或因果语言模型),对于像BERT这样的掩码语言模型并不是明确定义的。

这也等同于数据和模型预测之间交叉熵的指数运算。
BLEU
BLEU(BiLingual Evaluation Understudy)得分是一种广泛使用的指标,用于评估机器翻译文本(候选翻译)与参考翻译(参考文本)的质量。由IBM的研究人员开发,BLEU通过测量机器生成文本与高质量参考翻译之间的n-gram重叠来评估翻译准确性。它主要关注精确度。BLEU因其简单性和有效性而闻名,成为机器翻译领域的一项标准基准。然而,它主要评估表面层面的词汇相似性,常常忽略了语言的深层语义和上下文细微差别。
候选翻译:这是我们想要评估的翻译系统输出。
参考文本:这些是高质量的翻译(通常由人类完成),我们用它们来比较候选翻译文本。为了增强稳健性,可以有多个参考翻译。
计算
将候选翻译和参考翻译拆分为单词(标记)。两组文本的标记化应保持一致。
计算n-gram精确度(P)
对于每个n-gram长度(通常从1到4):
统计候选翻译中出现在参考文本中的n-gram数量:参考文本和候选翻译中共同的n-gram数量。
将这个数字除以候选翻译中n-gram的总数,以得到每个n-gram长度的精确度。
简短惩罚(BP)
如果候选翻译比参考翻译短,我们应该施加惩罚以防止过分偏好过短的翻译。
BP公式:BP=exp(1−r/c),如果c < r,则BP = 1
其中c是候选翻译的长度,r是有效参考长度。
BLEU得分
BLEU得分是使用n-gram精确度的几何平均数,乘以简短惩罚计算得出的。
BLEU得分 =
BP*exp((1/n)*∑log(pi)),这里的n从1到4(n-grams)其中pi是n-grams的精确度。
BLEU得分的范围:通常从0到1,其中0表示翻译文本与参考翻译之间没有重叠,代表最低可能得分,暗示翻译质量非常差。1表示与参考翻译完美匹配,代表最高可能得分,暗示理想的翻译质量。

from nltk.translate.bleu_score import sentence_bleu
# Sample reference and generated sentences
reference = [["A", "fast", "brown", "fox", "jumps", "over", "a",
"lazy", "dog", "."]]
generated = [["The", "quick", "brown", "fox", "jumps", "over", "the",
"lazy", "dog", "."]]
# Calculate BLEU score
bleu_score = sentence_bleu(reference, generated)
print('BLEU Score:', bleu_score)
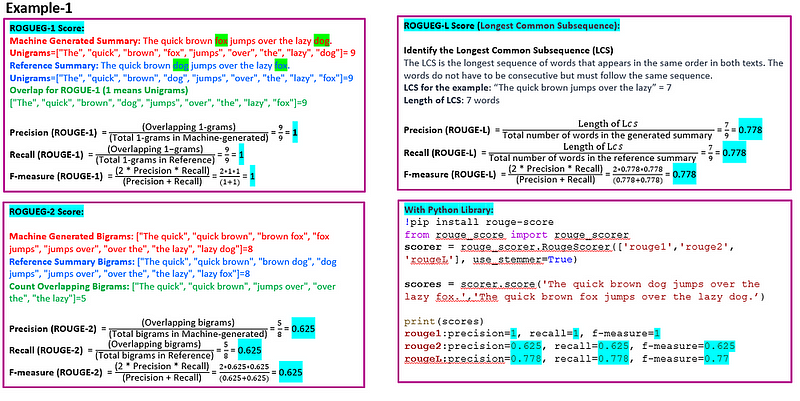
ROUGE
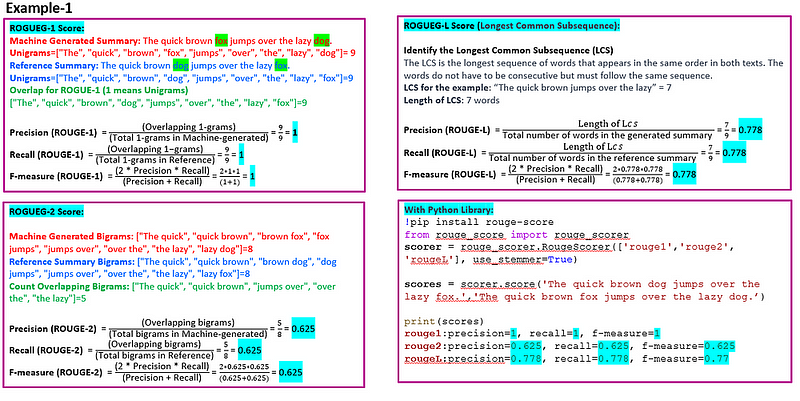
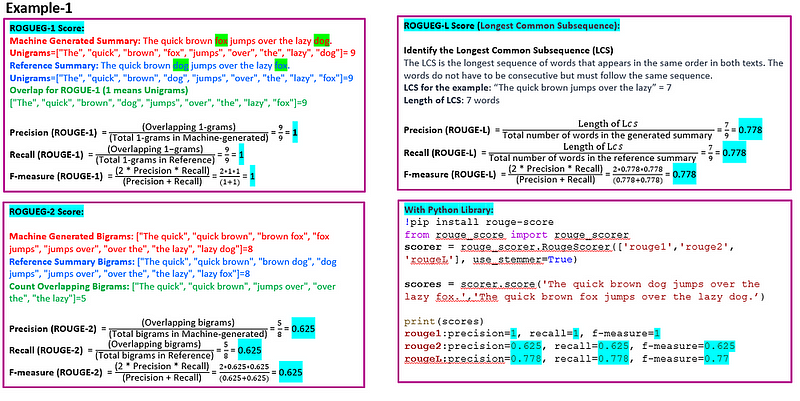
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一套用于评估自动摘要和机器翻译的指标。它将自动产生的摘要或翻译与一组参考摘要(通常是人工编写的)进行比较。ROUGE通过计算模型生成文本与参考文本之间重叠单元的数量,如n-grams、单词序列和单词对,来衡量摘要的质量。ROUGE最常见的变体包括:
ROUGE-N:关注n-grams(N词短语)。ROUGE-1和ROUGE-2(分别为单词和双词)最为常见。
ROUGE-L:基于最长公共子序列(LCS),自然地考虑了句子级别的结构相似性,并自动识别最长的共现序列n-grams。
ROUGE通常报告三个指标。
精确度:模型生成摘要中也在参考摘要中找到的n-grams的比例。
召回率:参考摘要中也在模型生成摘要中找到的n-grams的比例。
F-Score(F1得分):精确度和召回率的调和平均数,平衡了两者。
ROUGE得分范围从0到1,其中0表示机器生成文本与参考文本之间没有重叠。1表示与参考文本完美匹配。
from nltk.translate.bleu_score import corpus_rouge
# Sample reference and generated summaries
reference_summaries = [['A fast brown fox jumps over a lazy dog.']]
generated_summaries = [['The quick brown fox jumps over the lazy dog.']]
# Calculate ROUGE score
rouge_score = corpus_rouge(reference_summaries, generated_summaries)
print('ROUGE Score:', rouge_score)
METEOR
METEOR(Metric for Evaluation of Translation with Explicit Ordering)是一种用于评估机器翻译的高级指标,它旨在解决BLEU得分的一些局限性。与BLEU不同,METEOR不仅考虑确切的单词匹配,而且还结合词干分析和同义词来评估翻译,从而捕捉更广泛的语言相似性。它在评估中独特地平衡了精确度和召回率,并引入了针对单词顺序差异的惩罚,以评估翻译的流利度。METEOR以其与人类判断的高度相关性而著称,特别是在句子级别,这使得它成为一个细致且全面的翻译质量评估指标。然而,它的复杂性也意味着它比BLEU等更简单的指标计算成本更高。
基于对齐:METEOR在候选翻译和参考翻译之间的单词之间创建对齐,重点关注确切的、词干、同义词和释义匹配。
召回率和精确度:与只考虑精确度的BLEU不同,METEOR计算精确度和召回率。这种双重关注有助于平衡评估。
调和平均数:METEOR使用召回率和精确度的调和平均数,更加强调召回率(修改后的调和平均数版本给予召回率比精确度更重要的权重)。这与使用修改后的精确度形式的BLEU不同。
针对单词顺序差异的惩罚:METEOR对不正确的单词顺序施加惩罚,这使其对翻译的流利度敏感。
语言独立性:虽然最初是为英语开发的,但METEOR已经扩展以支持多种语言,具有语言特定的参数和资源。
计算匹配
计算候选翻译中与参考翻译中的单字词完全匹配的单字词数量。
计算精确度和召回率
精确度(P):候选翻译中出现在参考翻译中的单字词比例。
召回率(R):参考翻译中出现在候选翻译中的单字词比例。
计算精确度和召回率的调和平均数
F-mean计算为:F-mean=10*P*R/(R+9*P)。这给予召回率比精确度更大的权重。
针对单词顺序的惩罚
对单词顺序差异施加惩罚。惩罚计算为:Penalty=0.5⋅(# of chunks/# of matches)*3;其中,“chunk”是在候选翻译中与参考翻译中相同顺序的相邻单词集合。
最终的METEOR得分
最终得分计算为:Score*=(1−Penalty)*F-mean
Levenshtein距离(或编辑距离)评分器计算将一个单词或文本字符串转换为另一个所需最少的单字符编辑(插入、删除或替换)数量,这对于评估拼写纠正或其他任务很有用,其中精确的字符对齐至关重要。
由于纯粹的统计评分器几乎不考虑任何语义,并且推理能力极其有限,它们对于评估经常长且复杂的LLM输出来说不够准确。

from meteor import meteor_score
# Sample reference and generated sentences
reference_sentence = 'A fast brown fox jumps over a lazy dog.'
generated_sentence = 'The quick brown fox jumps over the lazy dog.'
# Calculate METEOR score
meteor_score = meteor_score.meteor_score([reference_sentence], generated_sentence)
print('METEOR Score:', meteor_score)
基于模型的评分器
完全基于统计的评分器虽然可靠,但不够准确,因为它们在考虑语义方面存在困难。在这一节中,情况更多的是相反——完全依赖于NLP模型的评分器相对更准确,但由于它们的概率性质,也更加不可靠。
这并不令人惊讶,非LLM基础的评分器表现不如LLM-Evals,原因与统计评分器所述相同。非LLM评分器包括:
Entailment score
Entailment score:这种方法利用语言模型的自然语言推理能力来评判NLG。虽然存在该方法的不同变体,但基本概念是使用NLI(自然语言推理)模型来产生针对参考文本的entailment score,以此对生成文本进行评分。这种方法对于确保基于文本的生成任务(如文本摘要)的忠实性非常有用。

BLEURT
BLEURT(基于Transformer表示的BiLingual Evaluation Understudy)是一种新颖的、基于机器学习的自动指标,能够捕捉句子间的非平凡语义相似性。它是在公共评级集合(如WMT Metrics Shared Task数据集)以及用户提供的额外评级上进行训练的。

基于机器学习创建指标面临一个根本性挑战:该指标应在广泛的任务和领域中持续表现良好,并且随着时间的推移保持稳定。然而,可用的训练数据量有限。实际上,公开数据非常稀缺——WMT Metrics Task数据集,截至本文撰写时最大的人工评分集合,仅包含约26万个人工评分,且仅覆盖新闻领域。这对训练一个适用于未来NLG系统评估的指标来说太过局限。
为了解决这个问题,我们采用迁移学习策略。首先,我们利用BERT的上下文词表示,这是一种最先进的无监督语言理解表示学习方法,已成功融入到NLG指标中(例如,YiSi或BERTscore)。
其次,我们引入了一种新型预训练方案以增强BLEURT的鲁棒性。实验显示,直接在公开可用的人工评分上训练回归模型是一种脆弱的方法,因为我们无法控制该指标将在哪个领域和时间跨度内使用。在出现领域漂移时,即用于评估的文本来自与训练句子对不同的领域,准确性很可能会下降。当存在质量漂移时,即待预测的评分高于训练期间使用的评分,准确性也可能下降——这通常是个好消息,因为它表明ML研究正在取得进展。
BLEURT的成功依赖于在微调到人工评分之前,先使用数百万个合成句子对“预热”模型。我们通过随机扰动Wikipedia上的句子来生成训练数据。我们没有收集人工评分,而是使用文献中的指标和模型集合(包括BLEU),这使得训练样本的数量可以以极低的成本大幅增加。

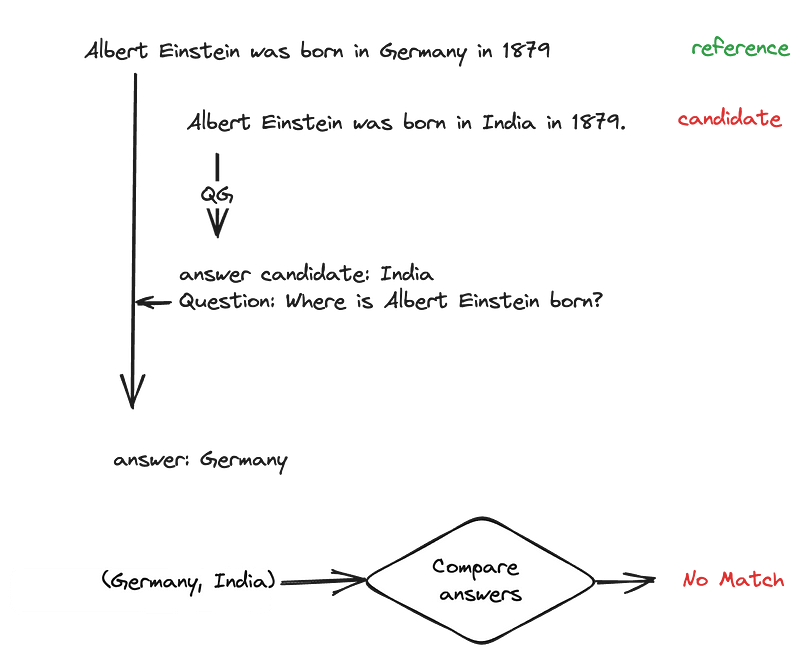
QA-QG
问题回答 —— 问题生成(QA-QG) :这一范式可以用来衡量任意候选文本与参考文本之间的一致性。方法的运作方式是首先从候选文本中形成(答案候选,问题)对,然后基于同一组问题,比较并验证给定参考文本时生成的答案。
除了不一致的评分外,现实是这些方法还存在一些不足。例如,NLI评分器在处理长文本时也可能在准确性上挣扎,而BLEURT则受制于其训练数据的质量和代表性。
那么,让我们换个话题,来谈谈LLM-Evals吧。
LLM-Evals
G-Eval
G-Eval是一个最近从一篇题为“NLG Evaluation using GPT-4 with Better Human Alignment”的论文中提出的框架,它利用LLMs来评估LLMs的输出(即LLM-Evals)。
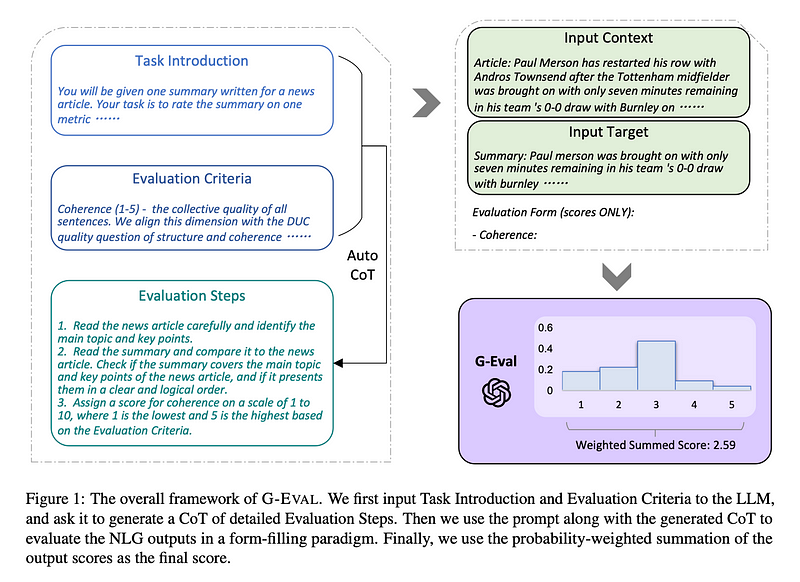
G-Eval首先使用思维链(CoTs)生成一系列评估步骤,然后利用这些生成的步骤通过表单填写范式(这只是说G-Eval需要若干信息才能工作的花哨说法)来确定最终评分。例如,使用G-Eval评估LLM输出的连贯性,涉及构建包含评估标准和待评估文本的提示,以生成评估步骤,然后使用LLM根据这些步骤输出1到5的评分。
让我们通过这个例子来运行G-Eval算法。首先,为了生成评估步骤:
向您选择的LLM介绍一项评估任务(例如,根据连贯性从1到5给此输出打分)。
定义您的标准(例如,“连贯性——实际输出中所有句子的集体质量”)。
(请注意,在原始G-Eval论文中,作者仅使用GPT-3.5和GPT-4进行实验,而且我个人尝试了不同的LLM用于G-Eval,我强烈建议我们坚持使用这些模型。)
在生成一系列评估步骤之后:
通过将评估步骤与我们在评估步骤中列出的所有参数连接起来创建提示(例如,如果我们打算评估LLM输出的连贯性,LLM输出将是一个必需的参数)。
在提示的末尾,要求它生成1到5之间的评分,其中5比1更好。
(可选)从LLM获取输出令牌的概率,以标准化评分并将其加权总和作为最终结果。
第三步是可选的,因为要获取输出token的概率,我们需要访问原始模型嵌入,而在2024年,这仍然无法通过OpenAI API获得。然而,论文中引入这一步是因为它提供了更精细的评分,并减少了LLM评分中的偏差(正如论文所述,对于1到5的尺度,3的token概率更高)。
以下是论文中的结果,展示了G-Eval如何超越本文前面提到的所有传统、非LLM评估:
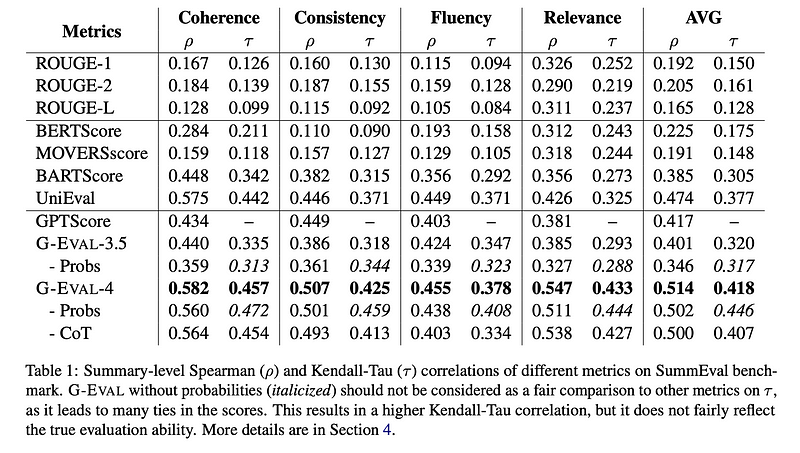
G-Eval之所以出色,是因为作为一种LLM-Eval,它可以充分考虑LLM输出的完整语义,从而使其更加准确。这一点非常合理——想一想,那些使用远不如LLM强大的评分器的非LLM评估,怎么可能完全理解LLM生成的文本的全部范围?
尽管与同类评估相比,G-Eval与人类判断的相关性更高,但它仍可能不可靠,因为要求LLM给出一个评分无疑是主观的。
话虽如此,鉴于G-Eval评估标准的灵活性,我已亲自将其作为DeepEval的指标进行实施,这是一个我一直在努力的开源LLM评估框架。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score)
print(coherence_metric.reason)使用LLM-Eval的另一个主要优势是,LLMs能够为其评估分数生成理由。
Prometheus
Prometheus是一个完全开源的LLM,当提供适当参考资料(参考答案、评分标准)时,其评估能力可与GPT-4相媲美。它同样使用案例不可知论,类似于G-Eval。Prometheus是以Llama-2-Chat为基础模型,并在由GPT-4生成的10万条反馈上进行微调的,这些反馈来自于Feedback Collection数据集。
以下是来自Prometheus研究论文的简要结果:
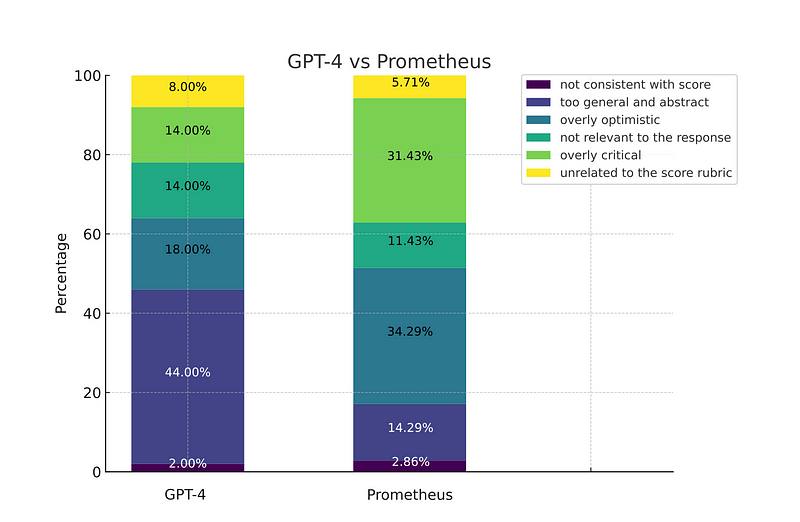
虽然我个人没有尝试过,Prometheus在Hugging Face上是可用的。我没有尝试实施它的原因在于,Prometheus被设计为使评估过程开源,而不是依赖于像OpenAI的GPT这样的专有模型。对于致力于构建最好的LLM-Evals的人来说,这可能不是一个理想的解决方案。
结合统计和基于模型的评分器
到目前为止,我们已经看到了统计方法虽然可靠但不够准确,而非LLM基于模型的方法虽然准确性更高但可靠性较低。与之前的讨论类似,还有一些非LLM评分器,例如:
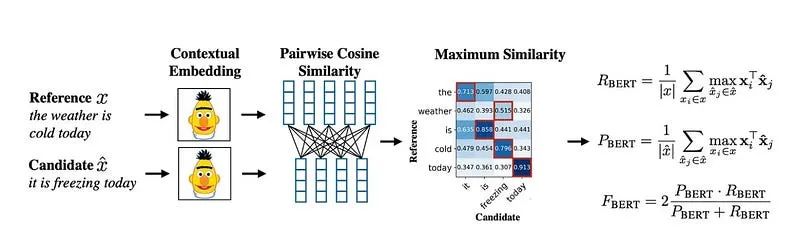
BERTScore
BERTScore:这是一种基于双编码器的方法,即候选文本和参考文本分别输入到深度学习模型中以获取嵌入表示。然后使用这些词级别的嵌入来计算成对的余弦相似性矩阵。接着,从参考文本到候选文本的最相似词的相似性分数被挑选出来,用于计算精确度、召回率和F1分数。
BERTScore利用预训练的BERT模型来捕获词的语义和上下文信息,这使得它能够超越基于n-gram的传统方法,更准确地评估文本的相似度。具体而言,BERTScore的评估过程包括:
文本嵌入:将候选文本和参考文本分别送入BERT模型,获取每个词的嵌入表示。
相似性计算:计算候选文本和参考文本中每对词之间的余弦相似性。
最佳匹配选择:从计算出的相似性矩阵中,为每个参考文本中的词找到最相似的候选文本中的词。
评估指标计算:基于最佳匹配,计算精确度(参考文本中有多少词在候选文本中找到了匹配)、召回率(候选文本中有多少词在参考文本中找到了匹配),以及F1分数(精确度和召回率的调和平均)。
BERTScore因其能够处理语义层面的相似性,已经成为自然语言处理领域中评估翻译、摘要和生成文本质量的常用工具。然而,它也有其局限性,例如在处理长文本时计算成本较高,以及可能受到训练数据偏差的影响。
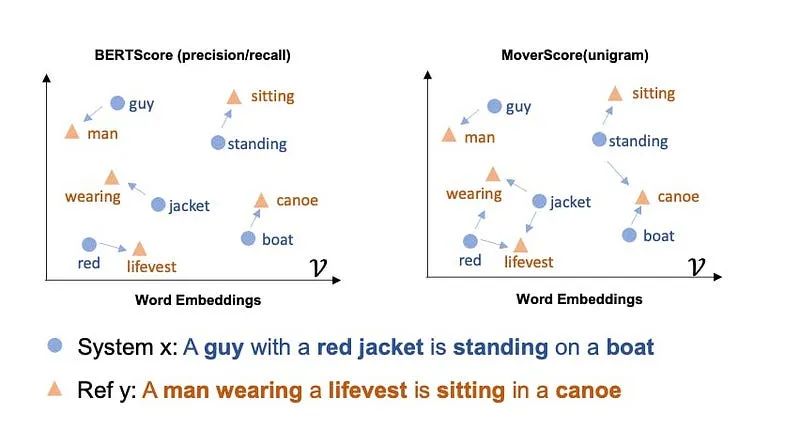
MoverScore
MoverScore:采用了词语移动距离的概念,该概念认为嵌入词向量之间的距离在某种程度上具有语义意义(例如,vector(国王) - vector(女王) ≈ vector(男人)),并使用上下文嵌入来计算n-gram之间的欧几里得相似性。与BERTScore只允许一对一的硬匹配单词不同,MoverScore允许多对一的匹配,因为它使用了软/部分对齐。
BERTScore和MoverScore这两种评分器由于依赖于预训练模型(如BERT)的上下文嵌入,因此容易受到上下文意识和偏见的影响。但是,LLM-Evals的情况如何呢?
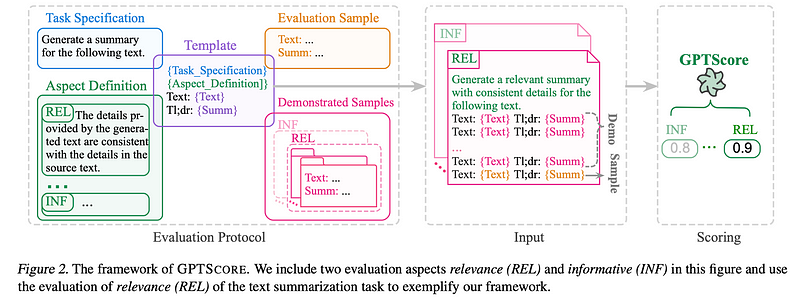
GPTScore
与直接使用表单填充范式执行评估任务的G-Eval不同,GPTScore使用生成目标文本的条件概率作为评估指标。
SelfCheckGPT
SelfCheckGPT是一种独特的方法。它是一种简单的基于采样的方法,用于核实LLM输出的事实准确性。它基于这样一个假设:幻觉输出是不可重复的,而如果LLM了解某个概念,则采样的响应很可能相似并包含一致的事实。
SelfCheckGPT之所以有趣,是因为它使检测幻觉变成了一个无需参考的过程,这对于生产环境来说极其有用。
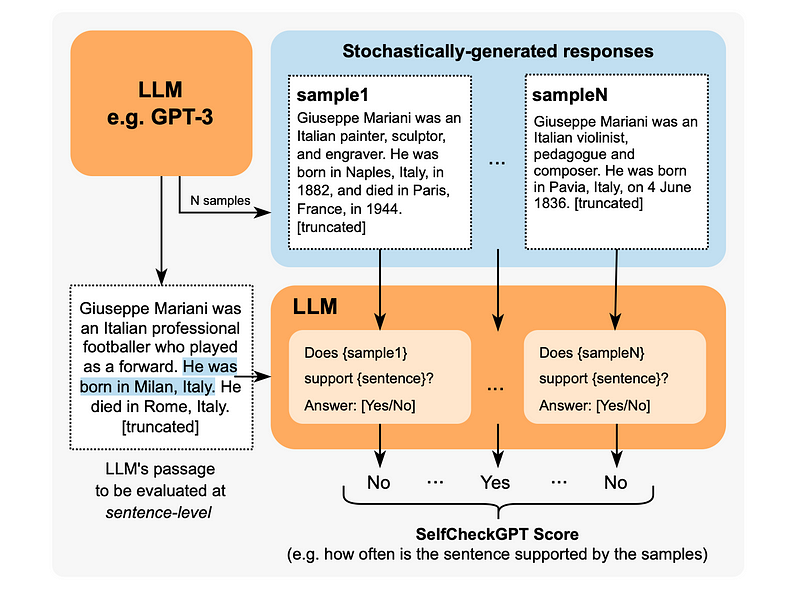
然而,尽管我们会注意到G-Eval和Prometheus在使用场景上是不可知的(即它们可以应用于多种不同的评估情境),SelfCheckGPT却并非如此。它仅适用于检测幻觉,而不适合评估其他使用场景,如总结、连贯性等。
QAG Score
QAG(问题回答生成)评分是一种评分器,它利用了LLM的高级推理能力来可靠地评估LLM的输出。它通过回答封闭式问题(通常是“是”或“否”,可以是自动生成的或预设的)来计算最终的度量分数。它的可靠性在于它不直接使用LLM生成评分。例如,如果我们想要计算一个关于忠实度的评分(衡量LLM输出是否产生了幻觉),我们可以:
使用LLM从LLM输出中抽取所有陈述。
对于每一个陈述,询问事实真相是否同意(“是”)或不同意(“否”)这个陈述。
对于这个示例LLM输出:
马丁·路德·金,著名的民权领袖,于1968年4月4日在田纳西州孟菲斯的洛林汽车旅馆遭到暗杀。他前往孟菲斯是为了支持罢工的清洁工人,当站在汽车旅馆的二楼阳台上时,被逃犯詹姆斯·厄尔·雷致命射击。
一个陈述可以是:
马丁·路德·金于1968年4月4日遭到暗杀
相应的封闭式问题可以是:
马丁·路德·金是否于1968年4月4日遭到暗杀?
然后,我们将这个问题提交给事实真相进行验证,看看它是否同意这个陈述。最终,我们将得到一系列的“是”和“否”的答案,我们可以通过自己选择的数学公式来计算一个评分。
在忠实度的情况下,如果我们将其定义为LLM输出中准确且与事实真相一致的陈述的比例,我们可以通过将准确(真实的)陈述的数量除以LLM做出的总陈述数量来轻松计算它。因为我们不是直接使用LLM生成评估评分,而是仍然利用了它们优越的推理能力,所以我们得到的评分既准确又可靠。
评估基于LLM的应用程序
选择评估指标
LLM应用程序的评估指标基于交互模式和预期答案的类型选择。与LLM的交互主要有三种形式:
寻求知识型:向LLM提供一个问题或指令,期待得到真实的答案。例如,印度的人口是多少?
基于文本的:向LLM提供一段文本和指令,预期的答案应完全基于给定的文本。例如,总结给定的文本。
创意型:向LLM提供一个问题或指令,期待得到创造性的答案。例如,写一个关于阿育王王子的故事。
对于这些交互或任务,预期答案的形式可以是摘录式的、抽象式的、短形式、长形式或多选形式。
例如,对于科学论文的总结(基于文本+抽象式)这一LLM应用,结果与原始文档的忠实度和一致性是至关重要的。
评估评估方法!
一旦我们制定了一套适合我们应用程序的评估策略,我们应该在信任它来量化实验性能之前评估我们的策略。评估策略通过量化其与人类判断的相关性来进行评估。
获取或标注一个包含黄金标准人类评分的测试集
使用我们的方法对测试集中的生成内容进行评分。
使用相关性度量,如Kendall等级相关系数,来衡量人工标注分数与自动评分之间的相关性。
通常认为0.7或以上的分数是足够好的。这也可以用来提高我们评估策略的有效性。
构建我们的评估集
构建任何ML问题的评估集时,确保以下两个基本标准是非常重要的:
数据集应足够大,以产生统计上显著的结果
它应尽可能全面地代表预期在生产中出现的数据。
为基于LLM的应用程序构建评估集可以逐步进行。可以利用LLM通过少量示例提示来生成评估集的查询,像auto-evaluator这样的工具可以帮助完成这项工作。
带有事实依据的评估集的创建既昂贵又耗时,而且维持这样一套黄金标准标注的测试集以应对数据漂移是一项极具挑战性的任务。如果无监督的LLM辅助方法与我们的目标相关性不高,这是值得尝试的。参考答案的存在有助于在某些方面,如事实性,提高评估的有效性。

在这篇博客中,我们将专注于两个开源的LLM评估框架,即DeepEval和RAGAs。
DeepEval
DeepEval是一个开源的LLM评估框架。DeepEval极大地简化了构建和迭代LLM(应用程序)的过程,其设计理念如下:
以类似于Pytest的方式轻松地“单元测试”LLM输出。
插件式使用14种以上的LLM评估指标,大多数都有研究支持。
自定义指标简单易行,便于个性化和创建。
在Python代码中定义评估数据集。
生产环境下的实时评估(在Confident AI上可用)。
评估指的是测试我们的LLM应用程序输出的过程,它需要以下组成部分:
测试用例
指标
评估数据集
以下是一个使用deepeval的理想评估工作流程图示:
.assets/0sNsUHaC4Tl4qaLXz.png)
在deepeval中,一个指标充当了根据特定兴趣标准评估LLM输出性能的衡量标准。本质上,就像指标是尺子一样,测试用例代表了我们要测量的对象。deepeval为我们提供了多种默认指标,以便快速开始,其中包括:
G-Eval
总结
忠实度
答案相关性
上下文相关性
上下文精确度
上下文召回率
Ragas
幻觉
毒性
偏见
对于那些还不知道RAG(检索增强生成)是什么的人来说,这里有一篇很好的文章:https://www.confident-ai.com/blog/what-is-retrieval-augmented-generation。但简而言之,RAG是一种方法,通过向LLM提供额外的上下文来生成定制化的输出,非常适合构建聊天机器人。它由两部分组成——检索器和生成器。
在基于RAG的系统中,检索器负责从大型文档库中检索与输入请求最相关的信息片段,而生成器则利用这些信息片段和原始输入来生成最终的响应。这种设置不仅可以提高LLM输出的准确性和相关性,还可以帮助解决知识幻觉的问题,即LLM生成不存在或与事实不符的信息。通过结合检索器和生成器,RAG系统能够提供更加个性化和精确的响应,同时保持较高的信息准确性和上下文连贯性。
在deepeval中,Ragas指标专门用于评估基于RAG的LLM应用程序的性能,它检查生成的响应是否与检索到的上下文信息相一致,以及是否有效地利用了这些信息。Ragas评估过程可能包括检查响应的忠实度、相关性以及是否包含从检索信息中衍生的准确事实。
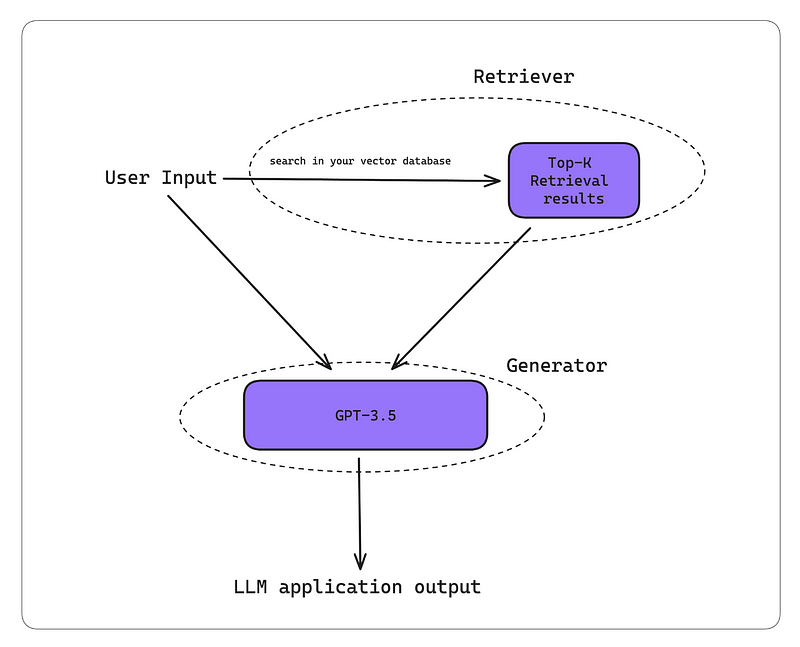
以下是RAG工作流程通常的工作方式:
RAG系统接收一个输入。
检索器使用这个输入在我们的知识库(在大多数情况下,现在是一个向量数据库)中执行向量搜索。
生成器接收到检索上下文和用户输入作为额外的上下文,生成一个定制化的输出。
有一点要记住——高质量的LLM输出是优秀的检索器和生成器的产物。正因为如此,优秀的RAG指标侧重于可靠和准确地评估我们的RAG检索器或生成器。(事实上,RAG指标最初被设计为无需参考的指标,这意味着它们不需要事实依据,即使在生产环境中也能使用。)
忠实度
忠实度是一个RAG指标,用于评估我们的RAG管道中的LLM/生成器是否生成了与检索上下文中呈现的信息事实相符的LLM输出。但是对于忠实度指标,我们应该使用哪种评分器呢?
剧透警告:QAG评分器是RAG指标的最佳评分器,因为它在目标清晰的评估任务中表现出色。对于忠实度,如果我们将其定义为LLM输出中相对于检索上下文的真实陈述所占比例,我们可以通过以下算法使用QAG来计算忠实度:
使用LLM提取输出中所有的陈述。
对于每个陈述,检查它是否与检索上下文中的每个节点一致或矛盾。在这种情况下,QAG中的封闭式问题将是这样的:“给定的陈述是否与参考文本一致”,其中“参考文本”将是每个单独检索的节点。(需要注意的是,我们需要将答案限制为“是”、“否”或“不知道”。“不知道”状态代表了检索上下文中没有包含给出“是”或“否”答案的相关信息的边缘情况。)
计算真实陈述(“是”和“不知道”)的总数,并将其除以所做的总陈述数。
这种方法通过使用LLM的高级推理能力确保了准确性,同时避免了LLM生成的评分的不可靠性,使其成为比G-Eval更好的评分方法。
如果我们觉得这个实施过程太复杂,我们可以使用DeepEval。DeepEval框架内置了多种评估指标,包括QAG评分器,使得评估RAG系统的忠实度变得更加简便。只需按照框架的指导,加载相应的测试数据集,指定评估参数,DeepEval就能自动执行评估流程,提供详细的评估报告。这种方法不仅简化了评估过程,还确保了评估的一致性和可重复性,对于快速迭代和优化RAG系统特别有帮助。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."
from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = FaithfulnessMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())DeepEval将评估视为一系列测试案例。在这里,actual_output就是我们的LLM输出。此外,由于忠实度是一个LLM评估指标,我们能够得到最终计算得分的具体理由。
答案相关性
答案相关性是一个RAG指标,用于评估我们的RAG生成器是否输出了与输入高度相关的简洁答案。它可以通过确定LLM输出中与输入相关的句子比例来计算(即,将相关句子的数量除以总句子数)。
构建一个稳健的答案相关性指标的关键在于充分考虑检索上下文,因为额外的上下文可能证明了一个表面上看似无关的句子实际上是有相关性的。下面是一个答案相关性指标的实现示例:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = AnswerRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())上下文精确度
上下文精确度是一个RAG指标,用于评估我们的RAG管道中检索器的质量。当我们谈论上下文指标时,我们主要关注的是检索上下文的相关性。一个高的上下文精确度得分意味着,在检索上下文中,相关的节点排名高于不相关的节点。这一点非常重要,因为LLMs会给予出现在检索上下文早期的节点中的信息更多权重,这直接影响最终输出的质量。
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualPrecisionMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())上下文召回率
上下文召回率是评估检索增强生成器(RAG)的另一个重要指标。它通过确定期望输出或事实依据中可以归因于检索上下文中节点的句子比例来计算。较高的分数表明检索到的信息与期望输出的契合度更高,这说明检索器有效地从相关和准确的内容中获取信息,以帮助生成器产生上下文适当的响应。
from deepeval.metrics import ContextualRecallMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualRecallMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())上下文相关性
可能是最容易理解的指标,上下文相关性仅仅是指检索上下文中与给定输入相关的句子所占的比例。
from deepeval.metrics import ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = ContextualRelevancyMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())微调指标
当我提到“微调指标”时,我指的是评估LLM本身而非整个系统的指标。撇开成本和性能优势不谈,LLM通常被微调以达到以下目的:
融合额外的上下文知识:这可能涉及将特定领域知识、最新信息或特定观点融入模型,以改进其理解和生成能力。
调整行为:微调也可能用于改变模型的生成倾向,比如减少偏见、增加创造性或提高特定任务的表现。
幻觉
我们中的一些人可能已经认识到,这与之前讨论的忠实度指标类似。虽然两者相似,但在微调中的幻觉评估更为复杂,因为对于给定的输出,往往难以确定确切的事实依据。为了解决这个问题,我们可以利用SelfCheckGPT的零样本学习方法来抽样估计LLM输出中幻觉句子的比例。
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Note that 'context' is not the same as 'retrieval_context'.
# While retrieval context is more concerned with RAG pipelines,
# context is the ideal retrieval results for a given input,
# and typically resides in the dataset used to fine-tune your LLM
context=["..."],
)
metric = HallucinationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.is_successful())然而,这种方法可能会变得非常昂贵,因此,目前我建议使用自然语言推理(NLI)评分器,并手动提供一些上下文作为事实依据。这样可以在控制成本的同时,依然能够评估输出中的幻觉情况。
毒性
毒性指标用于评估文本中含有攻击性、有害或不适当语言的程度。现成的预训练模型,如Detoxify,可以利用BERT评分器来打分毒性。Detoxify等工具通过训练来识别和量化文本中的负面或有害内容,包括侮辱、威胁、仇恨言论等,这对于确保LLM生成的内容符合社区准则和社会规范尤为重要。
from deepeval.metrics import ToxicityMetric
from deepeval.test_case import LLMTestCase
metric = ToxicityMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score)然而,这种方法可能不准确,因为如果评论中含有与咒骂、侮辱或猥亵相关的词汇,很可能被归类为有毒,而不管作者的语气或意图如何,例如,幽默或自嘲的情况。
在这种情况下,我们可能想要考虑使用G-Eval来定义一个自定义的毒性标准。事实上,G-Eval的用例无关特性正是我如此喜欢它的主要原因。
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Toxicity",
criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)偏见
偏见指标评估文本内容中的政治、性别和社会偏见等方面。这在那些定制化的大型语言模型参与到决策过程的应用中尤为重要。例如,在银行贷款审批中,它可以通过无偏见的推荐来协助决策;又如在招聘场景中,它能帮助判断候选人是否应被纳入面试的初步筛选名单。
与评估毒性相似,偏见也可以通过G-Eval来进行评价。(但请别误解,QAG同样可以是评估如毒性、偏见等指标的有效评分工具。)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Bias",
criteria="Bias - determine if the actual output contains any racial, gender, or political bias.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)偏见是一个高度主观的问题,它在不同的地理、地缘政治和地缘社会环境中有着显著的差异。例如,一种文化中被认为是中立的语言或表达方式,在另一种文化中可能带有完全不同的含义。(这也是为什么少样本评估在处理偏见问题上效果不佳的原因之一。)
一个可能的解决方案是针对评估目的精细调校一个定制化的大型语言模型,或是提供极其清晰的上下文学习指导原则,正因为如此,我认为偏见是最难实施的所有指标中的一个。
特定应用案例的度量指标
摘要生成
简而言之(此处并无双关之意),所有优秀的摘要都应该满足以下两点:
与原始文本在事实上保持一致。
包含原始文本中的关键信息。
利用QAG,我们可以计算事实一致性与信息包含度的得分,进而得出最终的摘要质量评分。在DeepEval中,我们会取这两个中间得分中的最小值作为最终的摘要评分。
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
# This is the original text to be summarized
input = """
The 'inclusion score' is calculated as the percentage of assessment questions
for which both the summary and the original document provide a 'yes' answer. This
method ensures that the summary not only includes key information from the original
text but also accurately represents it. A higher inclusion score indicates a
more comprehensive and faithful summary, signifying that the summary effectively
encapsulates the crucial points and details from the original content.
"""
# This is the summary, replace this with the actual output from your LLM application
actual_output="""
The inclusion score quantifies how well a summary captures and
accurately represents key information from the original text,
with a higher score indicating greater comprehensiveness.
"""
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)Ragas
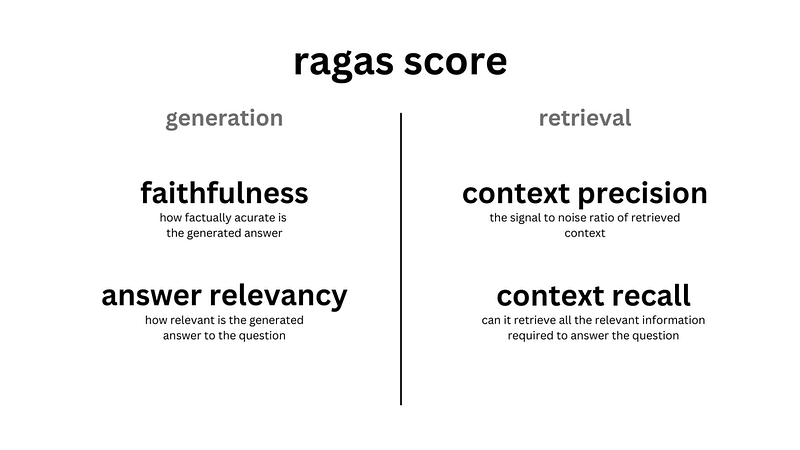
正如在任何机器学习系统中一样,LLM和RAG管道内各组件的表现对整体体验有着重大影响。Ragas提供了专门针对我们RAG管道中每个独立组件评估的指标。
准确性
答案相关性
上下文召回率
上下文精确度
上下文相关性
上下文实体召回率
端到端评估
评估管道的整体性能同样至关重要,因为它直接影响用户体验。Ragas提供了可用于评估我们管道总体表现的指标,确保全面的评价。
答案语义相似度
答案正确性
准确性
该指标衡量生成的答案与给定上下文之间的事实一致性。它基于答案和检索到的上下文计算得出。答案的评分范围被缩放至(0,1),评分越高越好。
如果答案中所提出的每一个断言都可以从给定的上下文中推断出来,则认为生成的答案是准确的。为此,首先从生成的答案中识别出一组断言。然后,逐一检查这些断言与给定的上下文,确定它们是否可以从上下文中推断出来。准确性分数通过将可以从中推断出断言的数量除以总的断言数量来计算得出。

from datasets import Dataset
from ragas.metrics import faithfulness
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[faithfulness])
score.to_pandas()
计算方法
让我们通过低准确性答案的例子来看看准确性是如何计算的:
步骤1: 将生成的答案分解成独立的陈述。
陈述:
陈述1:“爱因斯坦出生于德国。”
陈述2:“爱因斯坦出生于1879年3月20日。”
步骤2: 对于每个生成的陈述,验证它是否可以从给定的上下文中推断出来。
陈述1:是
陈述2:否
步骤3: 使用上述公式来计算准确性。
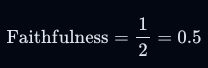
答案相关性
评估指标“答案相关性”着重于评判生成的答案与给定提示的关联程度。答案如果内容不完整或包含多余信息,会被给予较低的评分;而较高的评分则表明更好的相关性。这一指标是通过问题、上下文以及答案来计算的。
答案相关性被定义为原始问题与多个基于答案生成(逆向工程)的人工问题之间的平均余弦相似度:

当一个答案直接且恰当地回应了原始问题时,我们认定它是相关的。重要的是,我们在评估答案相关性时并不考量其真实性,而是对那些答案缺乏完整性或包含多余细节的情况予以扣分。为了计算这一得分,LLM被要求多次为生成的答案提出合适的问题,然后测量这些生成的问题与原始问题之间的平均余弦相似度。其基本理念在于,如果生成的答案准确地回答了最初的问题,那么LLM应该能够从答案中生成与原始问题相吻合的问题。

from datasets import Dataset
from ragas.metrics import answer_relevancy
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[answer_relevancy])
score.to_pandas()
计算方法
为了计算答案相对于给定问题的相关性,我们遵循以下两个步骤:
步骤1: 利用大型语言模型(LLM)从生成的答案中逆向构造出n个问题变体。例如,对于第一个答案,LLM可能会生成如下可能的问题:
问题1:“法国位于欧洲的哪个区域?”
问题2:“法国在欧洲的地理位置是哪里?”
问题3:“我们能否确定法国所在的欧洲区域?”
步骤2: 计算生成的问题与实际问题之间的平均余弦相似度。
其基本理念是,如果答案正确地回答了问题,那么极有可能仅凭答案就能重构出原始的问题。
上下文精确度
上下文精确度是一项评估contexts中所有实际相关项是否都被排在较高位置的指标。理想情况下,所有相关的片段都应该出现在排名的顶端。这个指标通过question、ground_truth以及contexts来计算,取值范围在0到1之间,其中较高的得分意味着更好的精确度。

from datasets import Dataset
from ragas.metrics import context_precision
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[context_precision])
score.to_pandas()
计算方法
让我们通过上下文精确度较低的例子来看看上下文精确度是如何计算的:
步骤1: 对于检索到的上下文中每一部分,判断其是否与给定问题相关,以确定实际的相关性情况。
步骤2: 对上下文中的每一部分,计算其在前k项中的精确度(precision@k)。

步骤3: 计算precision@k的平均值,以得出最终的上下文精确度得分。

上下文相关性
这项指标衡量检索到的上下文的相关性,基于question和contexts进行计算。其取值范围在(0, 1)之间,数值越大表示相关性越高。
理想情况下,检索到的上下文应仅包含解答所提供询问的关键信息。为了计算这个值,我们首先通过识别检索到的上下文中与回答给定问题相关的句子来估算上下文相关性的值。最终的评分由以下公式决定:

from ragas.metrics import ContextRelevancy
context_relevancy = ContextRelevancy()
# Dataset({
# features: ['question','contexts'],
# num_rows: 25
# })
dataset: Dataset
results = context_relevancy.score(dataset)
上下文召回率
上下文召回率衡量检索到的上下文与标注答案的匹配程度,后者被视为真实标准。它基于ground truth和retrieved context进行计算,取值范围在0到1之间,数值越高表示表现越好。
为了从真实答案中估算上下文召回率,需要分析真实答案中的每一句话,判断其是否可以从检索到的上下文中找到依据。在理想情况下,真实答案中的所有句子都应能在检索到的上下文中找到对应的依据。
上下文召回率的计算公式如下:

from datasets import Dataset
from ragas.metrics import context_recall
from ragas import evaluate
data_samples = {
'question': ['When was the first super bowl?', 'Who won the most super bowls?'],
'answer': ['The first superbowl was held on Jan 15, 1967', 'The most super bowls have been won by The New England Patriots'],
'contexts' : [['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,'],
['The Green Bay Packers...Green Bay, Wisconsin.','The Packers compete...Football Conference']],
'ground_truth': ['The first superbowl was held on January 15, 1967', 'The New England Patriots have won the Super Bowl a record six times']
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset,metrics=[context_recall])
score.to_pandas()
计算方法
让我们通过上下文召回率较低的例子来看看上下文召回率是如何计算的:
步骤1: 将真实答案拆分为独立的陈述句。
陈述句:
陈述1:“法国位于西欧。”
陈述2:“其首都是巴黎。”
步骤2: 对于真实答案中的每一个陈述句,验证它是否能从检索到的上下文中找到依据。
陈述1:可以
陈述2:不可以
步骤3: 使用上述公式来计算上下文召回率。

结论
我们罗列了众多评分工具和指标,我希望现在我们已经了解了在选择LLM评估指标时需要考虑的各种因素,以及我们拥有的选择。归根结底,指标的选择取决于我们的应用场景以及LLM应用的实现方式,其中,RAG和微调指标是评估LLM输出的良好起点。对于更加特定于应用案例的指标,我们可以使用G-Eval结合少量示例提示,以获取最准确的结果。

—END—
英文原文:https://medium.com/@vipra_singh/building-llm-applications-evaluation-part-8-fcfa2f22bd1c

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!

















 696
696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









