





点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Kritin Vongthongsri
编译:ronghuaiyang
导读
如果我告诉你,现在有可能在几分钟内生成数千个高质量的测试案例,这些案例你过去可能要花费数周时间精心制作,你会怎么想?

构建大规模、全面的数据集来测试LLM输出可能是一个耗时、昂贵且充满挑战的过程,尤其是从零开始。但如果我告诉你,现在有可能在几分钟内生成数千个高质量的测试案例,这些案例你过去可能要花费数周时间精心制作,你会怎么想?
合成数据生成利用LLM来创建高质量数据,无需手动收集、清理和标注大量数据集。借助像GPT-4这样的模型,现在可以以远少于人工标记数据集所需的时间,合成出更全面、更多样化的数据集,这些数据集可用于借助一些LLM评估指标来为LLM(系统)设立基准。
在本文中,我将教你如何使用LLM生成合成数据集(例如,可用于评估RAG管道)。我们将探讨:
合成生成方法(蒸馏和自我提升)
数据演进 是什么,各种演进技术,以及它在合成数据生成中的作用
使用LLM从零开始创建高质量合成数据的分步教程。
如何使用DeepEval在不到5行代码的情况下生成合成数据集。
感兴趣了吗?让我们深入了解一下。
使用LLM的合成数据生成是什么?
使用LLM的合成数据生成涉及到使用LLM来创建人造数据,通常是可用于训练、微调甚至评估LLM自身的数据集。生成合成数据集不仅比搜索公共数据集更快,比人工注释更便宜,而且结果质量更高,数据多样性更大,这对于构建LLM评估框架至关重要。
这一过程始于合成查询的创建,这些查询是使用来自你的知识库(通常以文档形式)的上下文作为事实依据生成的。生成的查询随后会经历多次“演化”,使其复杂化并更加逼真,与原始上下文结合后,构成了最终的合成数据集。虽然可选,你也可以选择为每个合成查询-上下文对生成目标标签,这将作为给定查询下你LLM系统的预期输出。
在为评估生成合成数据集时,主要有两种方法:使用模型输出进行自我提升,或者从更高级模型进行蒸馏。
自我提升:涉及模型从自身输出迭代生成数据,不依赖外部资源
蒸馏:涉及使用更强的模型生成合成数据来评估较弱的模型
自我提升方法,如Self-Instruct或SPIN,受到模型能力的限制,可能会放大偏差和错误。相比之下,蒸馏技术仅受限于可用的最佳模型,确保了最高质量的生成。
数据优胜劣汰
让我们澄清一下数据演进是什么,以及为什么它对使用LLM的合成数据生成如此重要。数据演进,最初在Microsoft的Evol-Instruct中引入,涉及通过提示工程迭代增强现有的一组查询,生成更复杂和多样的查询。这一步骤对于确保数据集的质量、全面性、复杂性和多样性至关重要。正是它使得合成数据优于公共数据集或人工标注的数据集。
实际上,最初的作者仅从175个人工创建的查询中就成功产生了250,000条指令。有三种类型的数据演进:
深度演进:将简单的指令扩展为更详细和精致的版本。
广度演进:生成新的、多样化的指令以丰富数据集。
淘汰演进:移除效果较差或失败的指令。
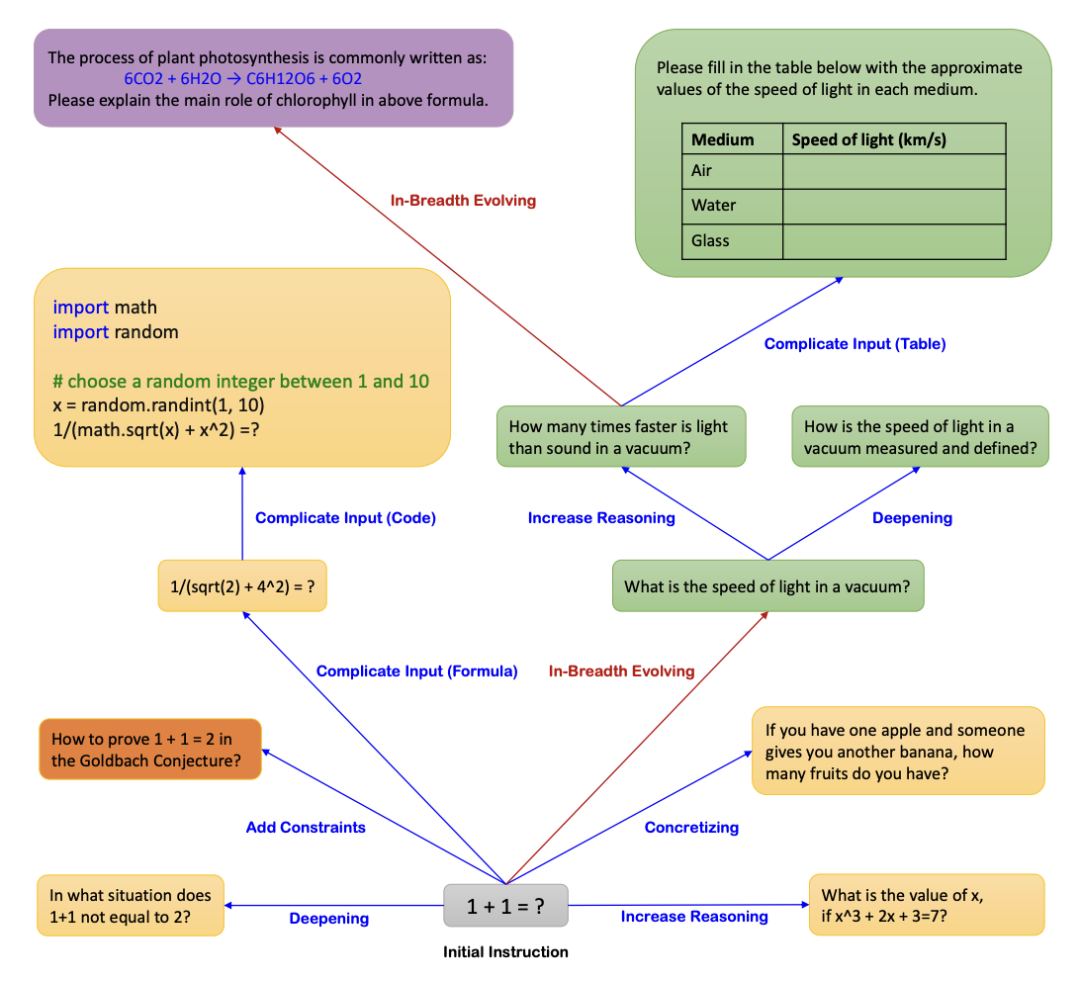
进行深度演进有几种方法,比如复杂化输入、增加推理需求,或者向完成任务添加多个步骤。每种方法都对生成数据的复杂程度做出了贡献。
深度演进确保创建出细致、高质量的查询,而广度演进增强了多样性和全面性。通过对每个查询或指令进行多次演进,我们增加了其复杂性,从而产生了一个丰富且多维的数据集。但说这么多,不如让我展示如何将所有内容付诸实践。
以这个查询为例:
1+1等于多少?
我们可以将其深度演进为:
在什么情况下1+1不等于2?
我希望我们都能同意,这比一般的1+1问题更复杂、更现实。在下一节中,我们将展示在生成合成数据集时如何实际运用这些演进方法。
分步指南:使用LLM生成合成数据
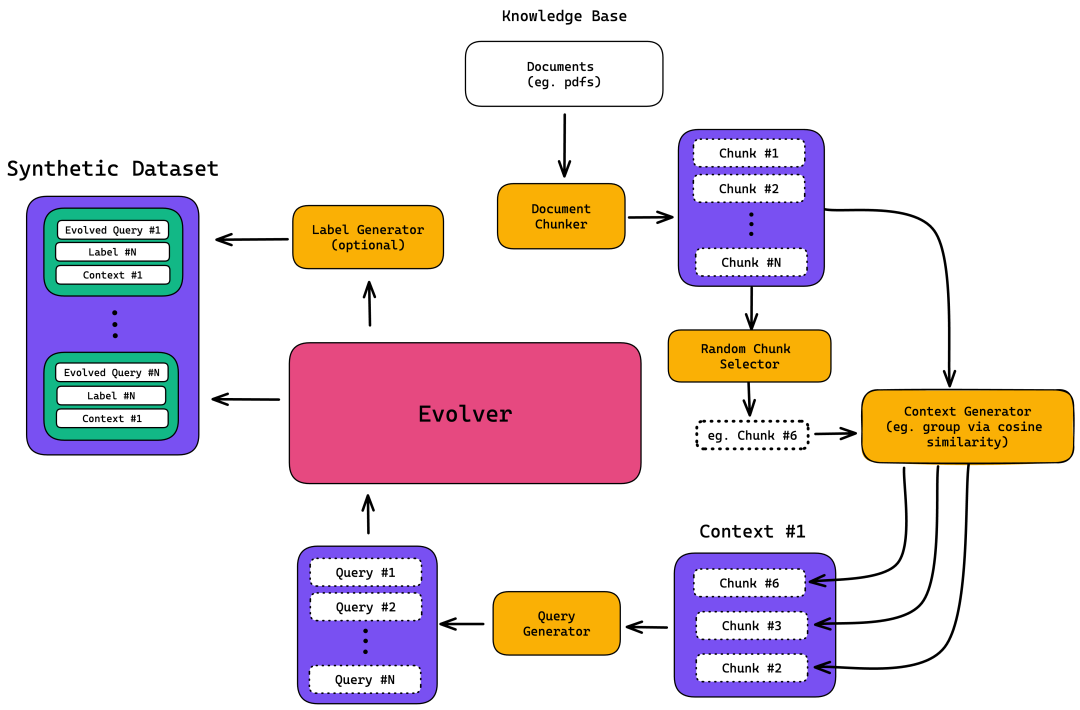
在开始之前,让我们回顾一下我们将要构建的数据合成器架构:
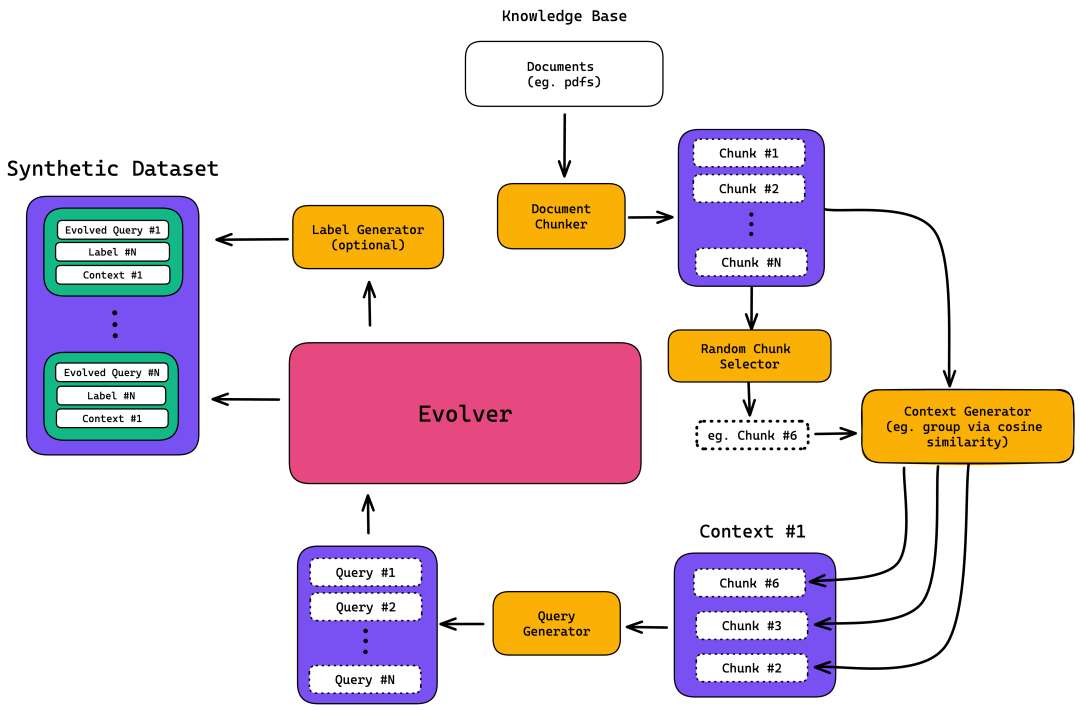
你会发现主要有五个步骤:
文档切块
上下文生成
查询生成
数据演进
标签/预期输出生成(可选)
当然,DeepEval已经有一个功能完备的数据合成器,准备好用于合成数据集的生成(稍后在最后一节我会展示给你),但对于那些好奇具体操作的人,让我们开始吧。
1. 文档切块
第一步是对文档进行切块。顾名思义,文档切块意味着将其分割成更小、更有意义的“块”。这样,你可以将大文档分解成易于管理的子文档,同时保持其上下文。切块还允许在超过嵌入模型令牌限制的文档中生成嵌入。
这一步骤至关重要,因为它有助于识别语义相似的块,并基于共享上下文生成查询或任务。
有几种切块策略,如固定大小切块和基于上下文的切块。你还可以调整超参数,如字符大小和块重叠。在下面的例子中,我们将使用基于令牌的切块,字符大小为1024,无重叠。以下是切块文档的方法:
请注意,这里的说明是通用指导,具体实现会根据使用的编程环境和技术栈有所不同。在实际操作中,你可能需要使用特定的库或工具来完成文档切块,例如Python中的spacy、nltk或专门的文档处理库。以下是一个使用Python和假设的文档切块函数的示例:
pip install langchain langchain_openai
# Step 1. Chunk Documents
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=1024, chunk_overlap=0)
loader = PyPDFLoader("chatbot_information.pdf")
raw_chunks = loader.load_and_split(text_splitter)一旦你有了这些分块,就需要将每一个块转换成嵌入(embeddings)。这些嵌入捕获了每个块的语义含义,并与块的内容相结合,形成一个Chunk对象的列表。
from langchain_openai import OpenAIEmbeddings
...
embedding_model = OpenAIEmbeddings(api_key="...")
content = [rc.page_content for rc in raw_chunks]
embeddings = embedding_model.embed_documents(content)2. 上下文生成
为了生成上下文,首先随机选择一段数据作为寻找相关信息的焦点锚点。
# Step 2: Generate context by selecting chunks
import random
...
reference_index = random.randint(0, len(embeddings) - 1)
reference_embedding = embeddings[reference_index]
contexts = [content[reference_index]]下面,设置一个相似性阈值并使用余弦相似度来识别出相关的块来构建上下文:
...
similarity_threshold = 0.8
similar_indices = []
for i, embedding in enumerate(embeddings):
product = np.dot(reference_embedding, embedding)
norm = np.linalg.norm(reference_embedding) * np.linalg.norm(embedding)
similarity = product / norm
if similarity >= similarity_threshold:
similar_indices.append(i)
for i in similar_indices:
contexts.append(content[i])这一步骤至关重要,因为它允许你通过多样化同一主题的信息来源来增强查询的稳健性。通过包含多个具有相似主题的数据块,你也为模型提供了关于该主题的更丰富、更细腻的信息。
这确保了你的查询全面覆盖主题,从而产生更全面、更准确的响应。
3. 查询生成
现在到了使用LLM的有趣部分。使用GPT模型,通过结构化提示为创建的上下文生成一系列任务或查询。
提供一个提示,要求模型扮演文案撰写者的角色,生成包含input键的JSON对象,这个键就是查询。每个输入应该要么是一个可以用提供的上下文回答的问题,要么是一个陈述句。
# Step 3. Generate a series of queries for similar chunks
from langchain_openai import ChatOpenAI
...
prompt = f"""I want you act as a copywriter. Based on the given context,
which is list of strings, please generate a list of JSON objects
with a `input` key. The `input` can either be a question or a
statement that can be addressed by the given context.
contexts:
{contexts}"""
query = ChatOpenAI(openai_api_key="...").invoke(prompt)这一步骤构成了你的查询基础,这些查询将经过演进而被包含在最终的数据集中。
4. 查询演进
最后,我们将使用多种演进模板来演进第三步中生成的查询。你可以定义尽可能多的模板,但我们将会专注于三个:多上下文理解、多步骤推理和假设情景
# Evolution prompt templates as strings
multi_context_template = f"""
I want you to rewrite the given `input` so that it requires readers to use information from all elements in `Context`.
1. `Input` should require information from all `Context` elements.
2. `Rewritten Input` must be concise and fully answerable from `Context`.
3. Do not use phrases like 'based on the provided context.'
4. `Rewritten Input` should not exceed 15 words.
Context: {context}
Input: {original_input}
Rewritten Input:
"""
reasoning_template = f"""
I want you to rewrite the given `input` so that it explicitly requests multi-step reasoning.
1. `Rewritten Input` should require multiple logical connections or inferences.
2. `Rewritten Input` should be concise and understandable.
3. Do not use phrases like 'based on the provided context.'
4. `Rewritten Input` must be fully answerable from `Context`.
5. `Rewritten Input` should not exceed 15 words.
Context: {context}
Input: {original_input}
Rewritten Input:
"""
hypothetical_scenario_template = f"""
I want you to rewrite the given `input` to incorporate a hypothetical or speculative scenario.
1. `Rewritten Input` should encourage applying knowledge from `Context` to deduce outcomes.
2. `Rewritten Input` should be concise and understandable.
3. Do not use phrases like 'based on the provided context.'
4. `Rewritten Input` must be fully answerable from `Context`.
5. `Rewritten Input` should not exceed 15 words.
Context: {context}
Input: {original_input}
Rewritten Input:
"""正如你所见,每个模板对输出施加了特定的约束。你可以根据希望评估查询在最终数据集中呈现的方式自由调整这些模板。我们将使用这些模板多次演进原始查询,每次随机选择模板。
# Step 4. Evolve Queries
...
example_generated_query = "How do chatbots use natural language understanding?"
context = contexts
original_input = example_generated_query
evolution_templates = [multi_context_template, reasoning_template, hypothetical_scenario_template]
# Number of evolution steps to apply
num_evolution_steps = 3
# Function to perform random evolution steps
def evolve_query(original_input, context, steps):
current_input = original_input
for _ in range(steps):
# Choose a random (or using custom logic) template from the list
chosen_template = random.choice(evolution_templates)
# Replace the placeholders with the current context and input
evolved_prompt = chosen_template.replace("{context}", str(context)).replace("{original_input}", current_input)
# Update the current input with the "Rewritten Input" section
current_input = ChatOpenAI(openai_api_key="...").invoke(evolved_prompt)
return current_input
# Evolve the input by randomly selecting the evolution type
evolved_query = evolve_query(original_input, context, num_evolution_steps)就这样,我们得到了最终的演进查询!重复这一过程以生成更多查询并进一步完善你的数据集。为了评估目的,你需要将这些输入查询和上下文适当地格式化,融入一个合适的测试框架中。
5. 预期输出生成
尽管这一步骤是可选的,但我强烈建议为每个演进查询生成预期输出。这是因为对于人类评估者来说,校正和标注预期输出比从零开始创建它们更容易。
# Step 5. Generate Expected Output
...
# Define prompt template
expected_output_template = f"""
I want you to generate an answer for the given `input`. This answer has to be factually aligned to the provided context.
Context: {context}
Input: {evolved_query}
Answer:
"""
# Fill in the values
prompt = expected_output_template.replace("{context}", str(context)).replace("{evolved_query}", evolved_query)
# Generate expected output
expected_output = ChatOpenAI(openai_api_key="...").invoke(prompt)作为最后一步,将演进后的查询、上下文和预期输出组合成你合成数据集中的一行数据。
from pydantic import BaseModel
from typing import Optional, List
...
class SyntheticData(BaseModel):
query: str
expected_output: Optional[str]
context: List[str]
synthetic_data = SyntheticData(
query=evolved_query,
expected_output=expected_output,
context=context
)
# Simple implementation of synthetic dataset
synthetic_dataset = []
synthetic_dataset.append(synthetic_data)现在,你所需要做的就是重复步骤1至5,直到你拥有了一个足够大的合成数据集,之后你可以使用它来评估和测试你的LLM(系统)!
使用DeepEval生成合成数据集
在本节的最后,我想向你展示一个经过实战考验的数据合成器,我已经在DeepEval中开源了它。这包括从合成数据生成到将其格式化为准备好的测试案例,用于LLM评估和测试,你只需两行代码就能做到这一切。最棒的是,你可以利用任何你选择的LLM。以下是如何使用DeepEval进行合成数据集生成的方法:
pip install deepeval
from deepeval.synthesizer import Synthesizer
synthesizer = Synthesizer()
synthesizer.generate_goldens_from_docs(
document_paths=['example.txt', 'example.docx', 'example.pdf'],
max_goldens_per_document=2
)你可以在DeepEval的文档中阅读更多关于如何使用DeepEval的合成器来生成合成数据集的详细信息,但总的来说,DeepEval接收你的文档,为你完成所有的切块和上下文生成工作,然后生成合成的“金标准”数据行,这些数据行最终构成你的合成数据集。是不是很简单?
结论
使用LLM生成合成数据集很棒,因为这是一种快速且成本低廉的方式来获取大量数据。然而,生成的数据可能看起来非常重复,很多时候无法充分代表底层数据分布,以至于被认为不够有用。在本文中,我们讨论了如何通过首先从文档中选择相关上下文,然后利用它来生成可用于测试和评估你的LLM系统的查询,来解决这个问题。
我们还探讨了数据演进,我们用它来使合成查询更加逼真。如果你正在从零开始构建数据合成器,这篇文章将是一个很好的教程。然而,如果你正在寻找更强大、更适用于生产环境的解决方案,你可以使用DeepEval。它是开源的,极其容易使用(真的),并且有一整套评估和测试工具,你可以使用生成的合成数据集无缝地测试和评估你的LLM系统。

—END—
英文原文:https://www.confident-ai.com/blog/the-definitive-guide-to-synthetic-data-generation-using-llms

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









