






数据集是我们学习和研究机器学习不可或缺的基础,Scikit-learn库内置了丰富的数据集资源,非常适合初学者用来练习和验证机器学习算法的效果。
一、鸢尾花数据集
鸢尾花数据集(Iris Dataset)是机器学习领域中最著名的数据集之一,常被用于分类问题的演示和算法的测试。
数据集概览:
-
样本数量:150个样本
-
特征数量:4个特征,花瓣长度(Sepal Length)、花瓣宽度(Sepal Width)、花萼长度(Petal Length)、花萼宽度(Petal Width)
-
标签数量:3个标签类别,鸢尾草(Iris Setosa)、蝴蝶花(Iris Versicolour)、维吉尼亚鸢尾(Iris Virginica)
数据集的应用:
-
作为机器学习入门教学的实例数据集。
-
测试分类算法的性能,如K近邻(KNN)、支持向量机(SVM)、决策树、随机森林等。
-
进行数据可视化和降维的练习,例如使用散点图矩阵展示特征之间的关系,或使用PCA(主成分分析)进行数据降维。
在Scikit-learn中加载鸢尾花数据集的代码如下:
from sklearn.datasets import load_iris
# 加载鸢尾花数据集
iris = load_iris()
# 查看特征名称
print("特征名称:", iris.feature_names)
# 查看类别名称
print("标签名称:", iris.target_names)
# 显示数据集的形状
print("\n特征集形状:", iris.data.shape)
# 显示目标数据的形状
print("标签集形状:", iris.target.shape)
# 查看数据特征
print("\n前几个特征数据:\n", iris.data[:5])
# 查看目标标签
print("前几个标签数据:\n", iris.target[:5])-
输出结果:

二、手写数字数据集
手写数字数据集(Digits Dataset)是一个在机器学习和计算机视觉领域中非常流行的数据集,特别是在进行数字识别任务时。这个数据集包含了1797个8x8像素的灰度手写数字图像,每个图像都是一个介于0到9之间的数字。
数据集概览:
-
样本数量:1797个样本。
-
图像大小:8x8像素。
-
标签数量:10个(0到9的每个数字)。
-
颜色空间:灰度图像,即每个像素点只有一个灰度值。
数据集的应用:
-
分类任务:手写数字数据集通常用于监督学习中的分类任务,特别是多类分类。
-
数据可视化:由于图像大小较小,可以用于展示数据的分布和形态。
-
模型训练和测试:用于训练和测试不同的图像识别和分类算法。
在Scikit-learn中加载手写数字数据集的代码如下:
from sklearn.datasets import load_digits
# 加载手写数字数据集
digits = load_digits()
# 获取特征数据和目标数据
X_digits = digits.data
y_digits = digits.target
# 特征数据是8x8的像素值数组
# 目标数据是对应的数字标签,从0到9
# 显示特征名称
print("特征名称:", digits.feature_names)
# 显示目标名称
print("标签名称:", digits.target_names)
# 显示数据集的形状
print("\n特征数据形状:", X_digits.shape)
# 显示目标数据的形状
print("标签数据形状:", y_digits.shape)
print("\n前几个样本图像:")
# 显示前几个图像
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 10, figsize=(10, 3))
for i, ax in enumerate(axes):
ax.imshow(X_digits[i].reshape(8, 8), cmap=plt.cm.binary, interpolation='nearest')
ax.text(0.5, 0.5, str(y_digits[i]), color='red', fontweight='bold',
verticalalignment='center', horizontalalignment='center')
ax.axis('off')
plt.show()
-
输出结果:

三、葡萄酒数据集
葡萄酒数据集(Wine Dataset)是另一个在机器学习中常用的数据集,特别是在进行分类任务时。这个数据集最初由意大利伊斯普拉的C.N.R.研究所的Forina等人收集,用于化学和生物指标的分析。
数据集概览:
-
样本数量:178个样本。
-
特征数量:13个化学指标,包括酒精含量、苹果酸含量、柠檬酸含量、残留糖量、氯化物含量、游离硫、总硫、硫酸盐、密度、pH值和色度等。
-
标签数量:3个葡萄酒类别,基于葡萄酒的类型或品种。
数据集的应用:
-
分类任务:葡萄酒数据集通常用于分类任务,特别是多类分类问题。
-
模型训练和测试:用于训练和测试不同的分类算法,如决策树、随机森林、支持向量机等。
在Scikit-learn中加载葡萄酒数据集的代码如下:
from sklearn.datasets import load_wine
# 加载葡萄酒数据集
wine = load_wine()
# 获取特征数据和目标数据
X_wine = wine.data
y_wine = wine.target
# 显示特征名称
print("特征名称:", wine.feature_names)
# 显示目标名称
print("标签名称:", wine.target_names)
# 显示数据集的形状
print("\n特征数据形状:", X_wine.shape)
# 显示目标数据的形状
print("标签数据形状:", y_wine.shape)
# 显示前几个样本的数据和标签
print("\n前几个样本的特征数据:\n", X_wine[:5])
print("对应的标签数据:\n", y_wine[:5])
-
输出结果:

四、乳腺癌数据集
乳腺癌数据集(Breast Cancer Dataset)是一个重要的医学数据集,用于通过计算机辅助诊断来提高乳腺癌的诊断率。
数据集概览:
-
样本数量:569个样本,其中良性样本357个,恶性样本212个。
-
特征数量:30个数值型特征,这些特征描述了乳腺肿瘤的不同测量值,如肿瘤的半径、纹理、周长、面积、平滑度、紧密度、凹陷度、凹陷点数、对称性以及分形维数等 。
-
标签数量:2个标签,代表肿瘤的良性(benign)或恶性(malignant)状态,通常用"M"和"B"表示,其中"M"代表恶性,"B"代表良性 。
数据集的应用:
-
该数据集被用来训练和测试不同的机器学习模型,如LDA和XGBoost算法,以构建乳腺癌预测模型 。
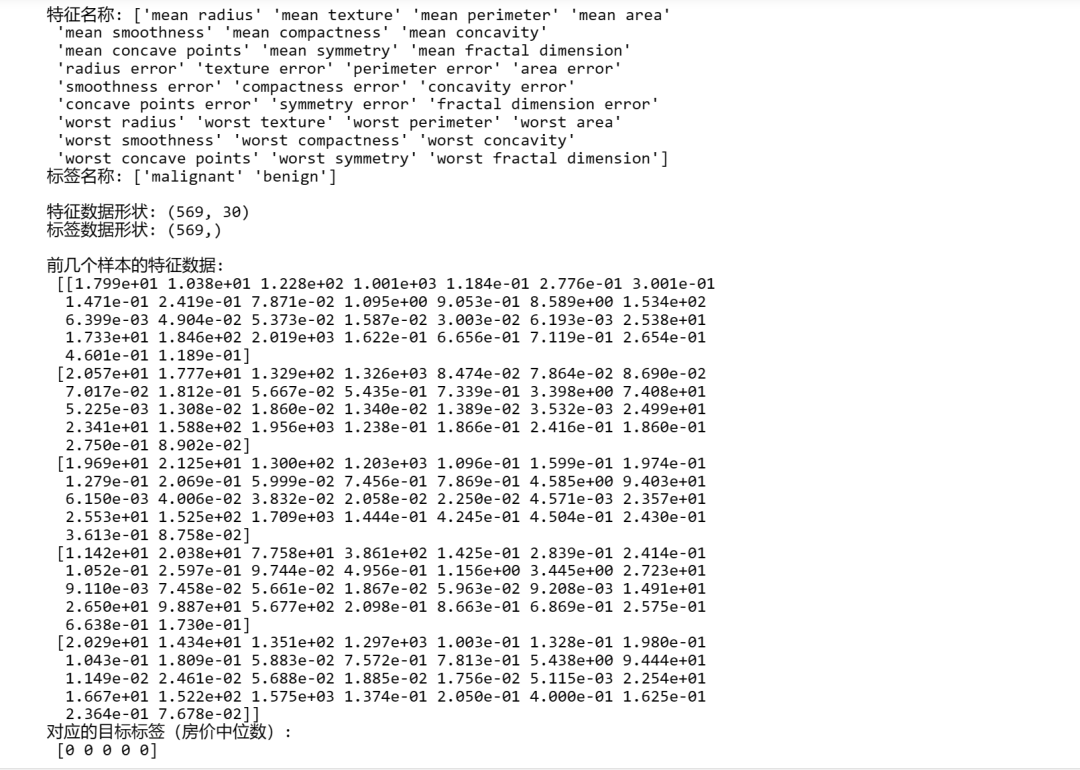
在Scikit-learn中加载乳腺癌数据集的代码如下:
from sklearn.datasets import load_breast_cancer
# 加载乳腺癌数据集
breast_cancer = load_breast_cancer()
# 查看特征名称
print("特征名称:", breast_cancer.feature_names)
# 查看目标名称
print("标签名称:", breast_cancer.target_names)
# 查看数据集的形状
print("\n特征数据形状:", breast_cancer.data.shape)
# 查看标签数据的形状
print("标签数据形状:", breast_cancer.target.shape)
# 显示前几个样本的数据和标签
print("\n前几个样本的特征数据:\n", breast_cancer.data[:5])
print("对应的目标标签(房价中位数):\n", breast_cancer.target[:5])
-
输出结果:
五、加州房价数据集
加州房价数据集(California Housing Dataset)是一个基于1990年加州人口普查数据构建的回归数据集。
数据集概览:
-
样本数量:20,640个样本。
-
特征数量:9个特征值,分别为经度(longitude)、纬度(latitude)、住房中位年龄(housing_median_age)、房间总数(total_rooms)、卧室总数(total_bedrooms,存在一些缺失值)、人口数(population)、家庭数(households)、收入中位数(median_income)和海洋接近度(ocean_proximity,一个分类特征)。
-
标签类别:房价中位数(median_house_value),以100,000美元为单位。
数据集的应用:
-
通常用于回归任务,预测房屋价格。
在Scikit-learn中加载葡萄酒数据集的代码如下:
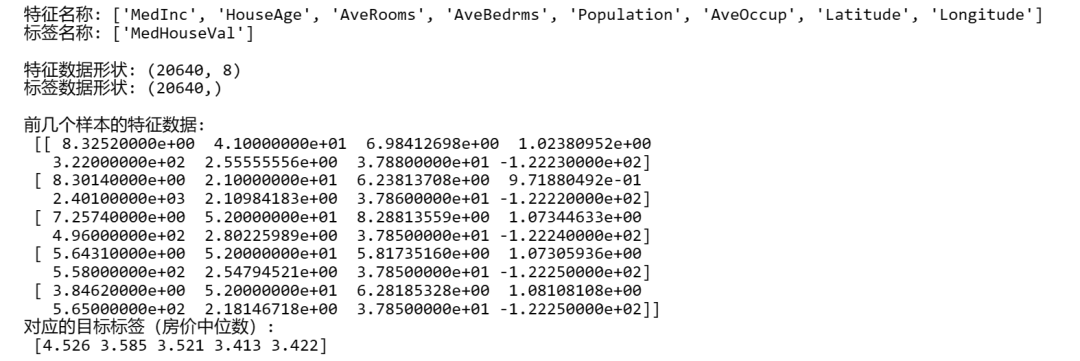
from sklearn.datasets import fetch_california_housing
# 加载加州房价数据集
california_housing = fetch_california_housing()
# 显示特征名称
print("特征名称:", california_housing.feature_names)
# 显示目标变量名称
print("标签名称:", california_housing.target_names)
# 显示数据集的形状
print("\n特征数据形状:", california_housing.data.shape)
# 显示目标数据的形状
print("标签数据形状:", california_housing.target.shape)
# 显示前几个样本的数据和标签
print("\n前几个样本的特征数据:\n", california_housing.data[:5])
print("对应的目标标签(房价中位数):\n", california_housing.target[:5])
-
输出结果:
总结
Scikit-learn内置的各种数据集为你的数据分析和机器学习项目提供强大支持。赶快动手尝试Scikit-learn内置数据集,开启你的机器学习之旅吧!
















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











