






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Cem Dilmegani
编译:ronghuaiyang
导读
本文将解释大型视觉模型的概念、结构及潜在的商业应用场景。
大型视觉模型(LVMs)已经在计算机视觉领域取得了重大进展。起初,这些模型擅长理解和解释复杂的图像数据。然而,它们在不同行业间有效扩展的能力构成了一项挑战。解决方案是开发更为专业化、面向特定领域的模型。这些先进的模型不仅在处理和分析视觉数据方面高效,还能适应不同业务领域的需求。
本文将解释大型视觉模型的概念、结构及潜在的商业应用场景。
什么是大型视觉模型(LVM)?
大型视觉模型(LVMs)是指专为处理和解释视觉数据(通常是图像或视频)而设计的先进人工智能(AI)模型。可以将它们视为视觉版的大规模语言模型(LLMs)。这些模型之所以被称为“大型”,是因为它们拥有大量的参数,通常达到数百万乃至数十亿级别,从而使它们能够学习视觉数据中的复杂模式。
结构与设计
大型视觉模型采用先进的神经网络架构构建而成。最初,卷积神经网络(CNNs)因其处理像素数据和检测层级模式(例如低层的边缘和高层的复杂对象)的能力而在图像处理中占据主导地位。近年来,最初为自然语言处理设计的Transformer模型也被广泛应用于多种视觉任务,某些情况下表现更佳。
训练
训练大型视觉模型涉及为其提供大量的视觉数据,如互联网图像或视频,以及相关的标签或注释。训练者会对庞大的图像库进行标注,供模型学习。例如,在图像分类任务中,每张图像都会被标记为其所属的类别。模型通过调整其参数以最小化预测与实际标签之间的差异来学习。这一过程需要强大的计算能力和大规模的多样化数据集,以确保模型能够很好地泛化到新的、未见过的数据上。
大型视觉模型的例子有哪些?
在计算机视觉和人工智能领域内广受认可的三个最著名的大型视觉模型例子包括:
OpenAI 的 CLIP(对比语言-图像预训练)
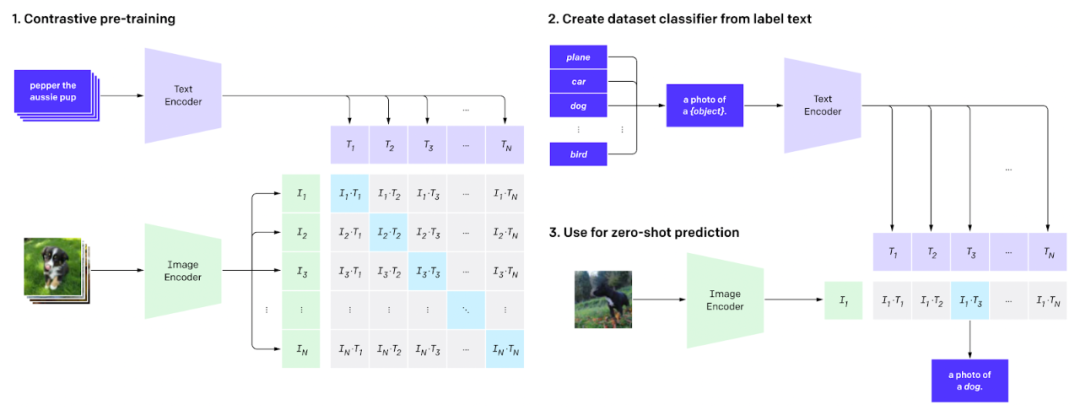
CLIP 是一种神经网络,它在多种图像和文本标题上进行训练。该模型学习理解并以符合自然语言描述的方式描述图像的内容。CLIP能够执行各种视觉任务,包括零样本分类,通过理解图像的自然语言上下文来实现。
它是在4亿对(图像,文本)的数据集上进行训练的,这使得它能够有效地连接计算机视觉任务和自然语言处理。这使得它能够在没有明确针对这些具体任务进行训练的情况下执行诸如标题预测或图像摘要的任务。
Landing AI 的 LandingLens
LandingLens是一个旨在简化计算机视觉模型开发和部署的平台。它允许用户为视觉数据创建和测试AI项目,适用于一系列行业,无需深入的AI知识或复杂的编程技能。
该平台标准化了深度学习解决方案,减少了开发时间,并且可以轻松地在全球范围内扩展项目。用户可以在不影响生产速度的情况下构建自己的深度学习模型并优化检查准确性。Landing AI的LVMs专注于将开发时间从几个月缩短到几周,简化了标签、训练和部署模型的过程。
它提供了一个逐步的用户界面,简化了开发流程,使团队能够在不需要深入技术知识的情况下创建面向特定领域的LVMs。
Google 的 Vision Transformer (ViT)
Vision Transformer是一种将Transformer架构(最初用于自然语言处理)应用于图像识别任务的模型。它以类似于Transformer处理单词序列的方式处理图像,表现出从图像数据中学习相关特征以进行分类和分析任务的有效性。
在Vision Transformer中,图像被视为一系列patch。每个patch被展平为一个单独的向量,类似于Transformer在文本中使用词嵌入的方式。这种方法允许ViT独立地学习图像的结构并预测类别标签。
大型视觉模型的应用案例有哪些?
1- 医疗保健和医学影像
疾病诊断:从X光片、MRI或CT扫描等医学影像中检测疾病。例如,识别肿瘤、骨折或异常情况。
病理学:在病理学中分析组织样本以寻找癌症等疾病的迹象。
眼科:辅助基于视网膜图像诊断疾病。
2- 自动驾驶汽车和机器人
导航和障碍物检测:通过解释实时视觉数据帮助自动驾驶汽车和无人机导航和避免障碍物。
制造业中的机器人: 基于AI视觉的应用可以帮助机器人完成诸如分拣、组装和质量检验等任务。
3- 安全和监控
面部识别: 在安全系统中用于身份验证和追踪。
活动监测:分析视频流以检测异常或可疑行为。
4- 零售和商业
视觉搜索:使客户能够使用图像而非文本搜索产品。
库存管理: 通过视觉识别自动化监控和管理库存的过程。
5- 农业
作物监测与分析:使用无人机或卫星影像监测作物健康状况和生长情况。
害虫检测:识别影响作物的害虫和疾病。
6- 环境监测
野生动物跟踪:识别和跟踪野生动物以支持保护工作。
土地利用和覆盖分析:监测随时间变化的土地利用和植被覆盖情况。
7- 内容创作与娱乐
电影和视频编辑:自动化视频编辑和后期制作的部分环节。
游戏开发:增强现实环境和角色的创建。
照片和视频增强:提升图像和视频的质量。
内容审核:自动检测并标记不当或有害的视觉内容。
大型视觉模型面临的挑战是什么?
计算资源:训练和部署这些模型需要大量的计算能力和内存,这使得它们资源密集型。
数据需求:它们需要大量且多样化的数据集进行训练。收集、标注和处理如此庞大的数据集可能既具挑战性又昂贵。然而,众包公司可以帮助处理这些问题。
偏见与公平性:模型可能会继承训练数据中存在的偏见,导致不公平或不道德的结果,特别是在面部识别等敏感应用中。
可解释性和透明度:理解这些模型如何做出决策可能很困难,这对于需要透明度的关键应用而言是一大关注点。
泛化能力:尽管它们在与训练集相似的数据上表现良好,但在完全新类型的数据上可能会遇到困难。
隐私担忧:尤其是在监控和面部识别中使用大型视觉模型会引发重大的隐私担忧。
监管和伦理挑战:确保这些模型的使用符合法律和伦理标准变得越来越重要,尤其是随着它们越来越多地融入社会。

—END—
英文原文:https://research.aimultiple.com/large-vision-models/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









