






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Prajwal Shreyas
编译:ronghuaiyang
导读
对于列表型的数据,使用深度学习的方法来进行预处理的方法。
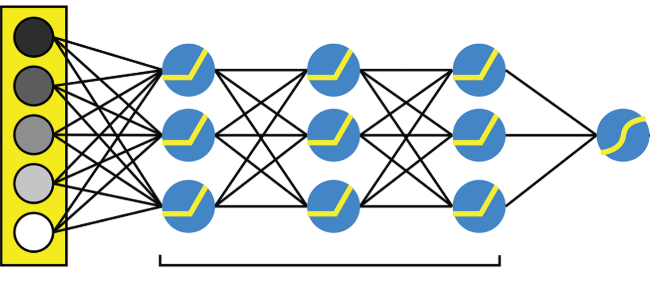
在本博客中,我将带你通过keras上的深度学习网络,了解创建分类变量嵌入的步骤。
传统的嵌入
在我们使用的大多数数据源中,我们主要会遇到两种类型的变量:
连续变量:这些通常是整数或小数,有无限个可能的值,例如计算机内存单元,比如1GB, 2GB等。
分类变量:这些是离散变量,用于根据某些特征分割的数据。计算机内存的类型,如RAM内存、内部硬盘、外部硬盘等。
当我们构建一个ML模型时,通常需要对分类变量进行转换,然后才能在算法中使用它。应用的转换对模型的性能有很大的影响,特别是当数据具有大量类别的分类特征时。一些常见的转换的例子包括:
One-Hot编码:这里我们为每个类别值转换为一个新列,并为该列分配一个' 1 '或' 0 ' (True/False)值。
二进制编码:这样创建的特性少于one-hot,同时保留列中值的一些唯一性。它能很好地处理高维有序数据。
然而,这些常用的转换并没有捕获分类变量之间的关系。
数据
为了演示深度嵌入的应用,让我们以Kaggle中的bike sharing数据为例。

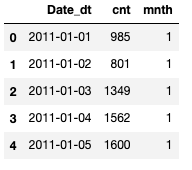
我们可以看到数据集中有很多列。为了演示这个概念,我们只使用数据中的date_dt、cnt和mnth列。
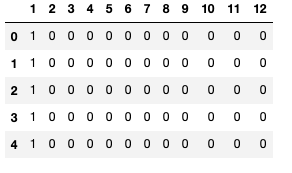
传统的one-hot编码将产生12列,每个月1列。然而在这种类型的嵌入中,每周的每一天都同样重要,每个月之间没有关系。
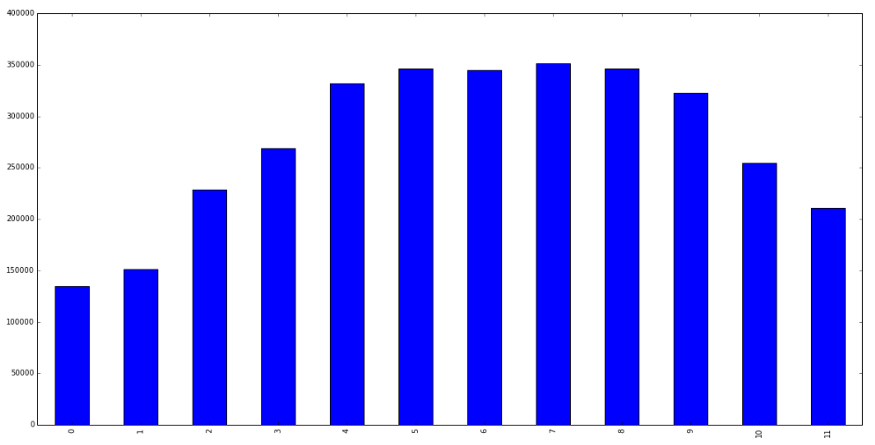
在下面的图表中,我们可以看到每个月的季节模式。我们可以看到第4到9个月是高峰期。第0、1、10、11个月是自行车租赁需求较低的几个月。
此外,当我们绘制每个月的日常使用情况时,用不同的颜色表示,我们可以看到每个月中的一些每周模式。
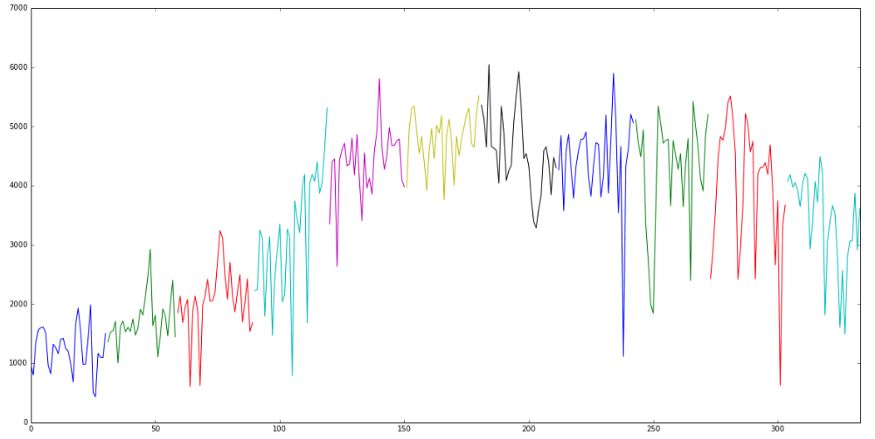
理想情况下,我们希望通过使用嵌入来捕获这种关系。在下一节中,我们将研究如何使用构建在keras之上的深度网络来生成这些嵌入。
深度嵌入
代码如下所示,我们将建立一个感知器网络与dense层网络和一个 ‘relu’ 激活函数。
网络的输入,即' x '变量,为月号。这是一年中每个月的数字表示,范围从0到11。因此,input_dim被设置为12。
网络的输出即' y '是缩放后的' cnt '值。也可以增加 ‘y’的维度以包含其他连续变量。在这里,当我们使用一个连续变量时,我们将把最后输出的dense层的节点设为1。我们将进行50个epoch来训练模型。
embedding_size = 3
model = models.Sequential()
model.add(Embedding(input_dim = 12, output_dim = embedding_size, input_length = 1, name="embedding"))
model.add(Flatten())
model.add(Dense(50, activation="relu"))
model.add(Dense(15, activation="relu"))
model.add(Dense(1))
model.compile(loss = "mse", optimizer = "adam", metrics=["accuracy"])
model.fit(x = data_small_df['mnth'].as_matrix(), y=data_small_df['cnt_Scaled'].as_matrix() , epochs = 50, batch_size = 4)
模型参数

嵌入层:这里我们为分类变量指定嵌入大小。在本例中是3,如果我们增加它,它将捕获更多关于分类变量之间关系的细节。Jeremy Howard提出了以下选择嵌入大小的解决方案:
# m is the no of categories per feature
embedding_size = min(50, m+1/ 2)
我们使用“adam“优化器,使用均方误差损失函数。Adam比sgd(随机梯度下降)更受欢迎,因为它具有更快的自适应学习速度。
结果
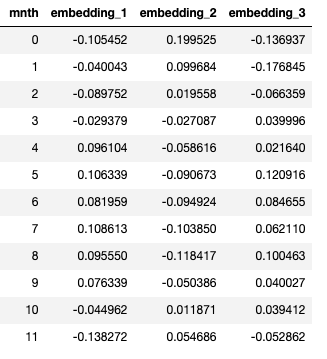
每个月的最终嵌入结果如下。这里“0”代表一月,“11”代表十二月。
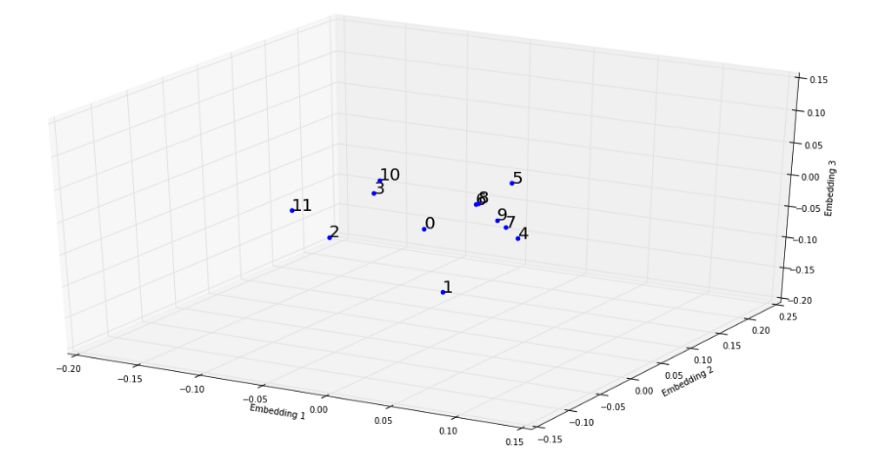
当我们用3D图来观察这一点时,我们可以清楚地看到月份之间的关系。具有相似“cnt”的月份被更紧密地分组在一起,例如第4个月到第9个月彼此非常相似。
总结
综上所述,我们已经看到,通过使用Cat2Vec(分类变量到向量),我们可以使用低维嵌入来表示高基数的分类变量,同时保持每个类别之间的关系。

—END—
英文原文:https://towardsdatascience.com/deep-embeddings-for-categorical-variables-cat2vec-b05c8ab63ac0

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 6638
6638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









