







对机器学习的一些理解
仿生算法:神经网络里的连接矩阵里记录了变换(卷积核是局部连接,全连接是全面连接,transformer是稀疏的全连接,RNN是加入了时间维度的全连接),神经细胞胞体里的激活函数记录了非线性变换。
网络的本质:
- 信息的容器,
- 信息过滤算法容器。
输入真实世界的数据,用适合的容器,用合适的算法才能容纳、处理数据,例如卷积(高效)、RNN(时间维度的引入)、词嵌入(高效)、transformer(联想),yolo(端到端的思想),gan(压缩到基本维度,从稀疏矩阵到稠密矩阵,再次扩张到稀疏矩阵)
工程实现的条件:
- 更多的数据 --更好的表征世界,
- 更大的模型 -学习更多内容,网络有更多容量
- 更强的算力 更高的每瓦算力,更快的训练速度和推力速度,(cpu,gpu,忆阻器)
- 更好的算法框架(学习能力)
- 更好的可解释性,安全性。视觉化--聚类算法,0shot 先验知识的植入--gpt的预训练+微调
- 成本、速度、能耗的平衡
todo 如果用教师网络(多个)做自动标签,是否可以训练出一个能够 充分提取照片信息的网络 ?
进而,是否能够做到网络的可追因性?可解释性?
每个实例只有很少维度信息,但是数据集包含多个维度信息,
FPN(Feature Pyramid Networks):特征金字塔网络 能够从不同几何尺度提取信息
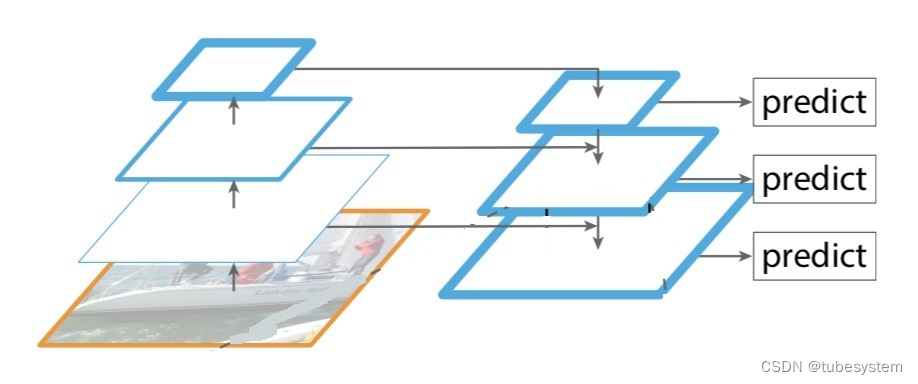
todo 深度网络和详细标签的探索
目的
现在的深度网络仅仅提取了一部分的照片信息,原因是标签不充分.
如果用教师网络(多个)做自动标签,是否可以训练出一个能够充分提取照片信息的网络?进而,是否能够做到网络的可追因性?可解释性?
输入,
人脸,
输出,
五官
性别,年龄,肤色,种族,发型,
饰品(眼镜,耳环,刺青),
表情,
人脸3D位姿,相机3D位姿,眼睛的视线3D位姿
灯光todo 算法 attention 里面有很多被transformer (或 RNN) 瓶颈算法 压缩的高维信息 ,是否可以用于计算机视觉里多物体表征

todo 建立一个模型 抽取双目视差图片的立体信息
- 先分割再融合双目以降低算量
- 同时分割+双目,以补充深度信息,更有利于分割。
- 人类V1区有左右眼叠层结构,构建空间感。辅助算法:光圈blur、双目对准,多次视觉焦点跳跃、三维空间记忆。
双目或多目包含了立体场景的一部分信息,为了减少计算量,可以用双目表征立体.
用一层或多层的卷积网络去抽取双目视差图片的立体信息
一层,得到一个好的卷积核
多层,得到一个网络
某些维度和方向的卷积计算todo yolo 是不是已经有了逆向预测的雏形,或者是预测训练并记忆了全息信息
yolo 1 最后输出了
7格子x 7格子x (5预测框+ 5预测框+ 20类别)
yolo 同时预测了 类别, 和位置(+置信度)
虽然不是预测了类别+位置 然后逆推各个部件,然后看逆推的部件和输入的部件是否匹配,
但是也可以认为,在训练阶段已经隐式地做了这个工作,并将信息记录在网格当中.
可以结合2阶段模型改进yolo,让第一阶段预测出实体,第二阶段 看逆推的部件和输入的部件位姿是否匹配 ,部件是否匹配
也许会极大的改善top1的正确率. 也许还能改进top5正确率
需要很好的标注数据集,,全景实例分割(全图全类别标注)
为降低标注成本,可以用电脑动画生成.
改造yolo
让yolo预测主体的位姿,并预测各个子部件的位姿,可以更充分地挖掘训练集的信息
关键点骨架模型也许可以帮助自动标注图片,完善训练集,
也可以用电脑动画生成.todo 如何用简单的规则,实现复杂的好结果?
压缩扩张(复现)结构,gan和视觉分割使用了这个思想。
todo 多对比试验,确定瓶颈容量的大小, 手位姿,人体位姿,物体分割
端到端的结构,yolo训练的结果是同时输出 标注物体类别和位置。不再用二级网络。
ResNet论文 中 添加了一个短路的路径,相当与魔改了网络的结构,让网络实现了长程的联想,记忆和注意力,最后得到了好的效果.
沿着这个思路, 向网络中添加简单的结构,添加空间和时间,添加逆向的联想(大部件的子部件),添加和谐度检测(五官的朝向是否一致,异常的不符合预期的物品乱放),手动或自动嵌入100个词
todo 如何添加这种简单结构
GAN 生成输出
MAE 补全图片
YOLO 端到端的结构
生物脑中的位置细胞和网格细胞
谐度检测
从正向的角度,如果各个元素的和谐度很高,说明世界符合神经网络的记忆
从逆向预测的角度,如果各个元素的和谐度很高,说明网络的输出和判断是正确的.可以用这种方法,从几个预测结果中挑出一个对的.
=============================
todo 数据集的分析,
看训练数据集覆盖了多少
从角度(位姿)
从灯光
从色彩
从人物动作
然后统计一个图表或空洞图,空洞表示数据集没有覆盖的空间人类生活在3维空间和1维时间中, 因为有立体视觉(立体听觉),能够正确的反映真实世界的数据分布。
todo Hinton 的路由网络试图将世界表征为 3维,有改进空间。
先讨论3维空间
人眼为何水平生长,因为地平线的方向信息更多,动物关心不太关心脚下和天空
蜻蜓等昆虫 有接近360度x180度视角,
食草动物有 有接近300度x150度视角,
人类视角在
双眼视角极限大约为垂直方向150度,水平方向230度
双眼的水平视角最大可达188度。(两眼重合视域有124度),
图像的垂直方向视角为20度,水平方向的视角为36度时,就会有非常好的视觉临场感,而且 也不因为频繁转动眼球造成疲倦
单眼的水平视角最大可达156度,
单眼舒适视域为60度,注视点30度以外的周边部分称为周边视野,
人眼可以感知3维空间, 图片分割非常方便(自训练),图片分割后再处理信息语义性更强,可以代表一个个概念。预测的算法,作用
1,减少计算量,
能在低分辨率情况下,不使用高分辨率。不在每一帧里都使用预测。
计算的稀疏性:根据外部客观环境的持续性,仿生青蛙对运动物体敏感性,自动过滤不运动的物体。
2,增加算法的有效性
对客观环境的高分辨率,对环境中前景和背景3D位姿判别、3D协调性的判别,都需要大量计算,
可以抽取间隔帧计算,在保持算法有效性的同时减低计算量。
另外,加入记忆和预测,在slam中平滑环境的特征点,特征点的数量和位置不产生跳变。
算法 反向解析
一个音轨可以理解为一种乐器演奏。音乐是由几个到几十个音轨组成。这些音轨是随时间变化的机械波,一旦机械波组合起来(相加),反向解析成各自音轨的音符+音色就变的异常困难。
需要设计一个网络,解决这个问题
基本组件, 多级时间片(金字塔)傅立叶变换(高时间分辨率和高频率分辨率)----加上时间得到二维图片----再次通过cnn(傅立叶变换)过滤出不同乐器(音色).不同音高















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









