







Spark当中做二次排序非常简单,因为有大量的现成函数已经实现了,只需要进行组合运用就好
在这里进行一下二次排序的总结
如果对两列或多列同时进行升序或降序排序的话比较容易实现
初始数据

1.两次升序或降序
val dataset = //your dataset
//1
dataset.map(x => (x._1, x._2)).sortBy(x => x, false).collect.foreach(println)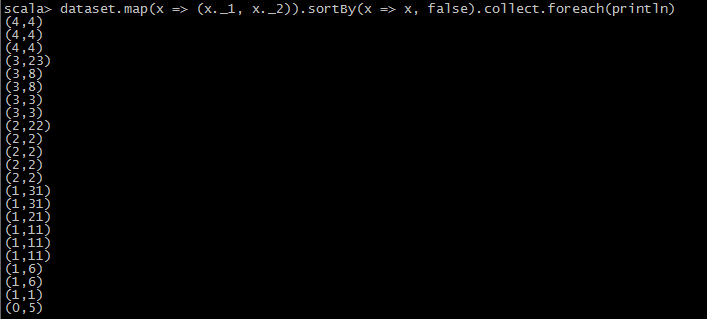
2.一次升序一次降序
class SortByTwice(val first: Int, val second: Int) extends Ordered[SortByTwice] with Serializable {
def compare(that: SortByTwice): Int = {
if (this.first - that.first != 0) {
return that.first - this.first
} else {
return this.second - that.second
}
}
}
val dataset = //your dataset
dataset.map(line => (new SortByTwice(line._1.toInt, line._2.toInt))).sortBy(x => x).map(x => (x.first, x.second)).collect.foreach(println)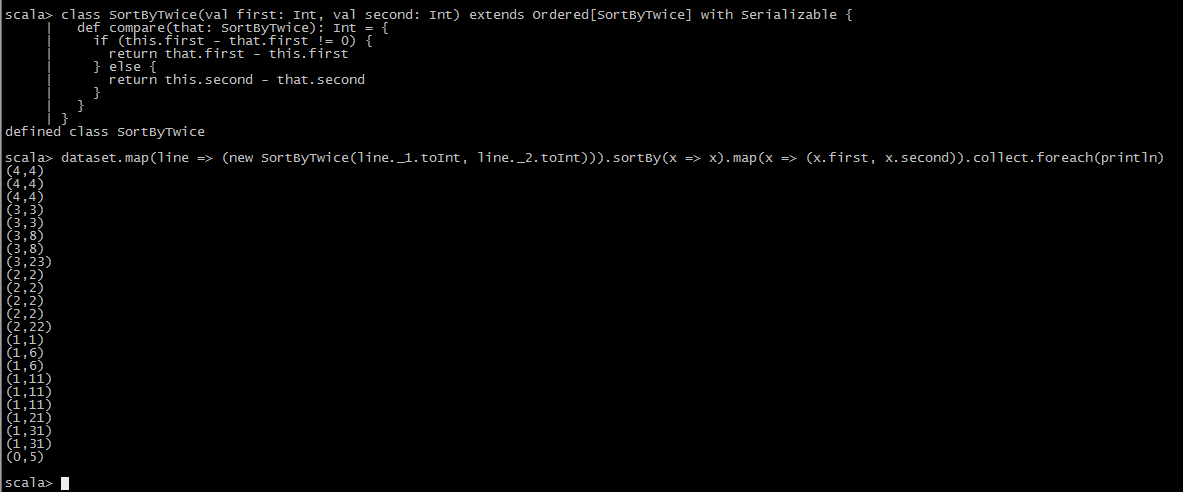
3.通过groupBy进行二次排序
也有一种情况是需要将Key进行groupBy的Key,Value二次排序
val dataset = //your dataset
dataset.groupByKey.map(x => (x._1, x._2.toList.sortWith(_ > _))).collect.foreach(println)















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









