







窗口函数中的排名函数与分析函数实在是太好用了,尤其是row_number和lead
全局表如下:
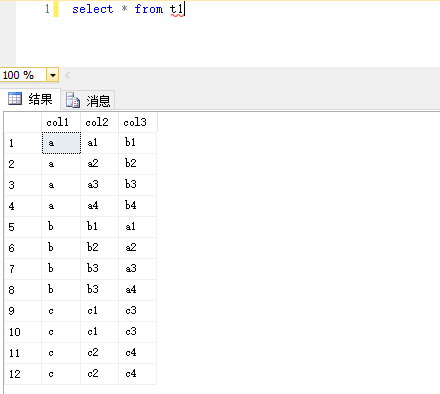
排名函数
1.row_number
ROW_NUMBER() over (partition by name order by testid) (partition by 是可选的)
其他排名函数相同
按照order排序 返回顺序
select ROW_NUMBER() over(order by col1) rowNumber,* from t1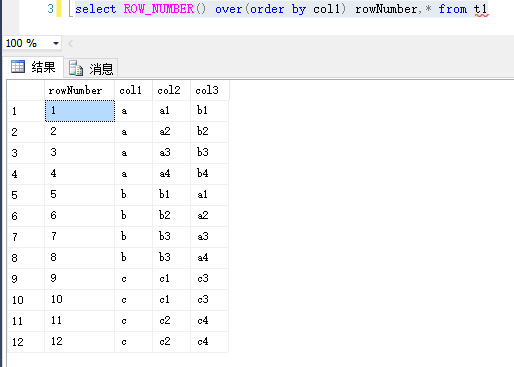
select ROW_NUMBER() over(partition by col1 order by col1) rowNumber,* from t1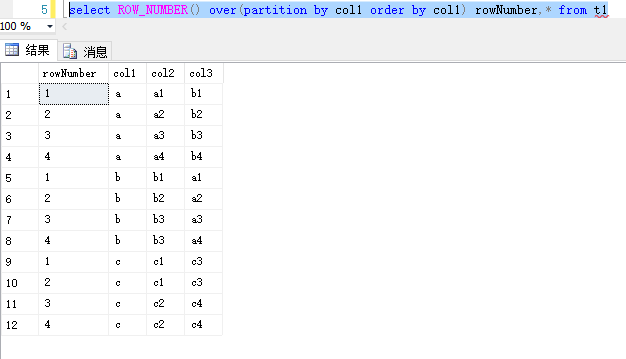
2.rank
按照order排序 返回排名,相同情况下排名相同
select rank() over(order by col1) rank_,* from t1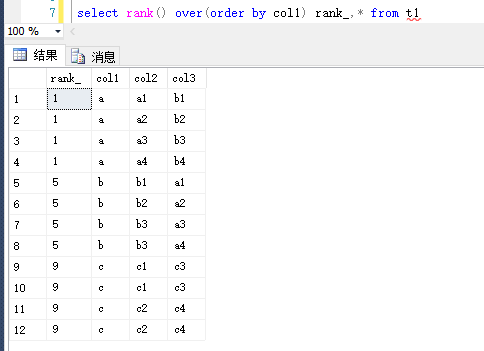
select rank() over(partition by col1 order by col1) rank_,* from t1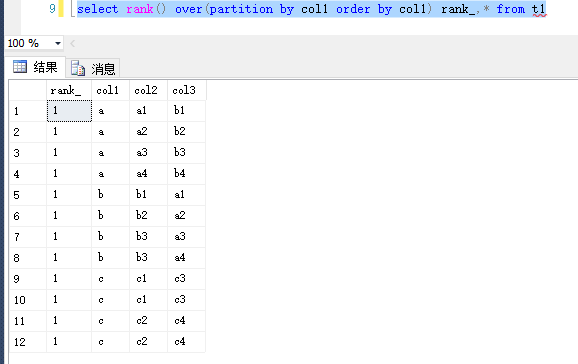
3.dense_rank
看图比较和rank的区别
select dense_rank() over(order by col1) rank_,* from t1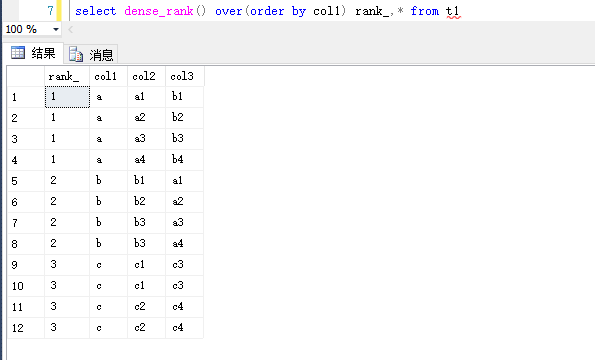
4.ntile
ntile函数,将数据强制分成n份,可结合case when 转为阶段百分比
例如:25%,50%等
select ntile(4) over(order by col1) rank_,* from t1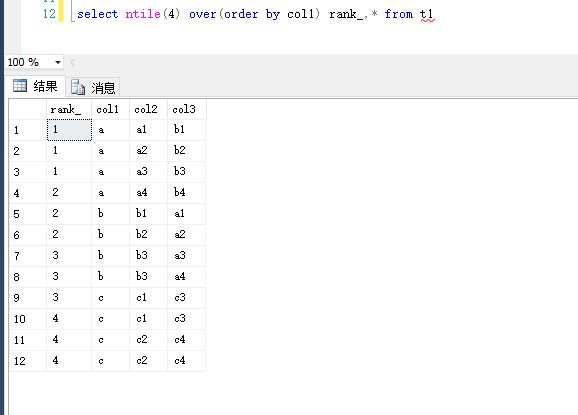
分析函数
1.cume_dist
计算累计分布
,计算某指定值在一组值中的相对位置,值相同的情况按照最后一个值的位置计算
select cume_dist() over(order by col1) as cume_dist,* from t1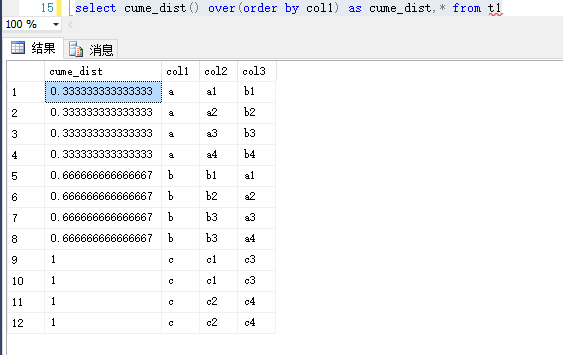
2.first_value 3.last_value
取首尾数据
这个我在别的地方看到一个很好的解释,就不再重复实验了
例:查询部门最早发生销售记录日期和最近发生的销售记录日期
SQL> select *from criss_sales order by dept_id,sale_date;
DEPT_ID SALE_DATE GOODS_TYPE SALE_CNT
------- ----------- ---------- -----------
D01 2014/3/4 G00 700
D01 2014/4/8 G01 200
D01 2014/4/30 G03 800
D01 2014/5/4 G02 80
D01 2014/6/12 G01
D02 2014/3/6 G00 500
D02 2014/4/8 G02 100
D02 2014/4/27 G01 300
D02 2014/5/2 G03 900SQL> select
2 dept_id
3 ,sale_date
4 ,goods_type
5 ,sale_cnt
6 ,first_value(sale_date) over (partition by dept_id order by sale_date) first_value
7 ,last_value(sale_date) over (partition by dept_id order by sale_date desc) last_value
8 from criss_sales;
DEPT_ID SALE_DATE GOODS_TYPE SALE_CNT FIRST_VALUE LAST_VALUE
------- ----------- ---------- ----------- ----------- -----------
D01 2014/3/4 G00 700 2014/3/4 2014/3/4
D01 2014/4/8 G01 200 2014/3/4 2014/4/8
D01 2014/4/30 G03 800 2014/3/4 2014/4/30
D01 2014/5/4 G02 80 2014/3/4 2014/5/4
D01 2014/6/12 G01 2014/3/4 2014/6/12
D02 2014/3/6 G00 500 2014/3/6 2014/3/6
D02 2014/4/8 G02 100 2014/3/6 2014/4/8
D02 2014/4/27 G01 300 2014/3/6 2014/4/27
D02 2014/5/2 G03 900 2014/3/6 2014/5/2
看结果first_value()很直观,不用多解释
但是,last_value()值,部门D01不是应该为2014/6/12,部门D02不是应该为2014/5/2吗?为什么会每条记录都不一样?
可以这样去理解:last_value()默认统计范围是 rows between unbounded preceding and current row
但是,last_value()值,部门D01不是应该为2014/6/12,部门D02不是应该为2014/5/2吗?为什么会每条记录都不一样?
可以这样去理解:last_value()默认统计范围是 rows between unbounded preceding and current row
验证一下:
SQL> select
2 dept_id
3 ,sale_date
4 ,goods_type
5 ,sale_cnt
6 ,first_value(sale_date) over (partition by dept_id order by sale_date) first_value
7 ,last_value(sale_date) over (partition by dept_id order by sale_date desc) last_value
8 ,last_value(sale_date) over (partition by dept_id order by sale_date rows between unbounded preceding and unbounded following) last_value_all
9 from criss_sales;
DEPT_ID SALE_DATE GOODS_TYPE SALE_CNT FIRST_VALUE LAST_VALUE LAST_VALUE_ALL
------- ----------- ---------- ----------- ----------- ----------- --------------
D01 2014/3/4 G00 700 2014/3/4 2014/3/4 2014/6/12
D01 2014/4/8 G01 200 2014/3/4 2014/4/8 2014/6/12
D01 2014/4/30 G03 800 2014/3/4 2014/4/30 2014/6/12
D01 2014/5/4 G02 80 2014/3/4 2014/5/4 2014/6/12
D01 2014/6/12 G01 2014/3/4 2014/6/12 2014/6/12
D02 2014/3/6 G00 500 2014/3/6 2014/3/6 2014/5/2
D02 2014/4/8 G02 100 2014/3/6 2014/4/8 2014/5/2
D02 2014/4/27 G01 300 2014/3/6 2014/4/27 2014/5/2
D02 2014/5/2 G03 900 2014/3/6 2014/5/2 2014/5/2
全统计的情况下得到的last_value()值,部门D01为2014/6/12,部门D02为2014/5/24.lag 5.lead
取第前n行或第后n行,越界值用默认值代替
三个参数 列名 偏移量 默认值
SQL> select * from kkk;
ID NAME
---------- --------------------
1 1name
2 2name
3 3name
4 4name
5 5name
SQL> select id,name,lag(name,1,0) over ( order by id ) from kkk;
ID NAME LAG(NAME,1,0)OVER(ORDERBYID)
---------- -------------------- ----------------------------
1 1name 0
2 2name 1name
3 3name 2name
4 4name 3name
5 5name 4name
SQL> select id,name,lead(name,1,0) over ( order by id ) from kkk;
ID NAME LEAD(NAME,1,0)OVER(ORDERBYID)
---------- -------------------- -----------------------------
1 1name 2name
2 2name 3name
3 3name 4name
4 4name 5name
5 5name 0
SQL>
SQL> select id,name,lead(name,2,0) over ( order by id ) from kkk;
ID NAME LEAD(NAME,2,0)OVER(ORDERBYID)
---------- -------------------- -----------------------------
1 1name 3name
2 2name 4name
3 3name 5name
4 4name 0
5 5name 0
SQL>
SQL> select id,name,lead(name,1,'alsdfjlasdjfsaf') over ( order by id ) from kkk;
ID NAME LEAD(NAME,1,'ALSDFJLASDJFSAF')
---------- -------------------- ------------------------------
1 1name 2name
2 2name 3name
3 3name 4name
4 4name 5name
5 5name alsdfjlasdjfsaf 














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









