







1.SVM(支持向量机)
以下内容转载文章:[SVM支持向量机入门及数学原理]https://blog.csdn.net/Datawhale/article/details/94598943
1.1简介
SVM名字由来:
在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量。
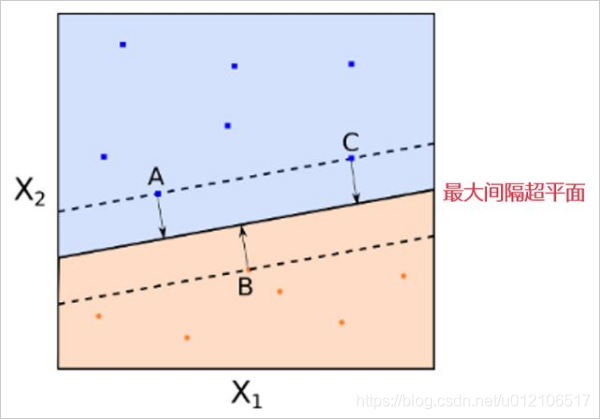
图中有红色和蓝色两类样本点。黑色的实线就是最大间隔超平面。在这个例子中,A,B,C 三个点到该超平面的距离相等。
注意,这些点非常特别,这是因为超平面的参数完全由这三个点确定。该超平面和任何其他的点无关。如果改变其他点的位置,只要其他点不落入虚线上或者虚线内,那么超平面的参数都不会改变。A,B,C 这三个点被称为支持向量(support vectors)。
而“机”主要是machine这个词翻译的有点唬人,如果翻译为“算法”就舒服多了。
支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
1.2线性可分支持向量机
给定训练样本集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) D=(x1,y1),(x2,y2),⋯,(xm,ym)D=(x1,y1),(x2,y2),⋯,(xm,ym) D=(x1,y1),(x2,y2),⋯,(xm,ym)D=(x1,y1),(x2,y2),⋯,(xm,ym),其中 y i ∈ ( − 1 , + 1 ) , y i ∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5834
5834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









