







1.训练集测试集划分方案
a)留出法hold-out
直接将原始数据集D划分为两个互斥集合,其中一个作为训练集S,另外一个作为测试集T,其中D=S并T,S交T=空。在划分的过程中应该尽量保持数据分布一致,即S,T的分布要和原始数据集一致,如原始数据集中正负样本比例为1:5,那么在S和T中正负样本比也应该为1:5。一般采用分层抽样的方案,即从正样本中抽取1份做训练集的正样本,从负样本中抽取1份做训练集的负样本。
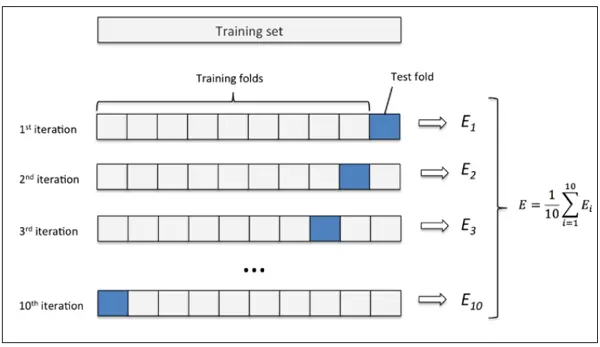
b)交叉验证法cross-validation
将原始数据集通过分层抽样划分为k个大小一致的互斥子集。然后,每次利用k-1各子集合的并集作为训练集,剩下的那个做测试集。这样就可以得到k个训练集/测试集的组合,从而可以进行k次训练和测试,最终返回的结果为k次测试结果的均值。
c)自助法bootstrapping
原始数据集包含m个样本,则有放回的抽样m次,组成一个包含m个样本的训练集D`,一个样本经过m次抽样任然没有被抽取到的概率为(1-1/m)**m=0.368,我们将D`作为训练集D-D`作为测试集,这样我们训练集和原始数据集一样有m个样本,同时测试集约有1/3的样本是训练集中没有出现过的。自助法在数据集较小、难以有效划分训练集/测试集时很有效;自助法能产生多个不同的训练集这对集成学习算法很有帮助;自助法改变了原始数据集的分布,因此在数据量足够的情况下,我们一般采用留出法和交叉验证法。
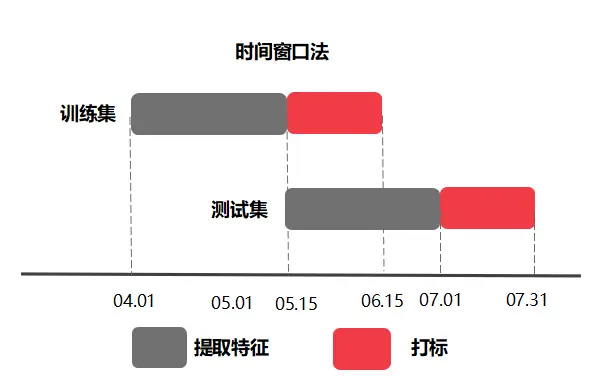
d)时间窗口划分法
在实际问题中,我们的做法一般是根据历史数据去预测未来某段时间发生的事情,在这种情况下,基于时间窗口的训练集测试集划分方案就很有用。我们根据线上线下一致性原则,将用户的历史数据按照时间窗口划分,例如选取4月到5月的数据为训练集,5月到6月的数据为测试集。一般在划分时分为标签窗口用于对待考察样本打标签,特征提取窗口用于对待考察样本提取特征。时间窗口划分法中的两个主要概念为窗口时间粒度的大小和窗口滑动的范围,粒度大小指包含了多少天,滑动的范围指从哪一天到哪一天。
2.偏差bias与方差variance
我们前面说过模型其实就是一个有x到y的函数映射f,我们通过已有数据训练得到这个映射f。偏差用于表征模型准不准,高偏差意味着模型精度较低;方差用于描述模型稳不稳&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









