






An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models
一种基于巢连接和空间/信道注意模型的红外可见光图像融合架构
作者:Hui Li, Xiao-Jun Wu and Tariq Durrani
期刊:IEEE Transactions on Instrumentation and Measurement (2020)
摘要
在本文中,提出了一种用于红外和可见光图像融合的新方法,其中开发了基于嵌套连接的网络和空间/通道注意模型。基于嵌套连接的网络可以从多尺度的角度保存来自输入数据的大量信息。该方法包括三个关键要素:编码器、融合策略和解码器。提出的融合策略中,开发了空间注意模型和通道注意模型,描述了每个空间位置和每个具有深层特征的通道的重要性。首先,将源图像馈送到编码器中以提取多尺度深度特征。然后开发新颖的融合策略,以融合每个规模的这些特征。最后,融合图像由基于嵌套连接的解码器重建。结果表明,提出的方法比其他最先进的方法具有更好的融合性能。
前言
当前基于深度学习的框架存在几个缺点 :
(1)网络没有下采样算子,无法提取多尺度特征, 深度特征没有得到充分利用;
(2)网络架构的拓扑结构需要改进以进行多尺度特征提取;
(3)融合策略没有精心设计来融合深层特征。
为了解决这些缺点,本文提出了一种新的嵌套连接的架构和新的空间注意力、通道注意力模型的融合框架。
UNet++嵌套连接架构
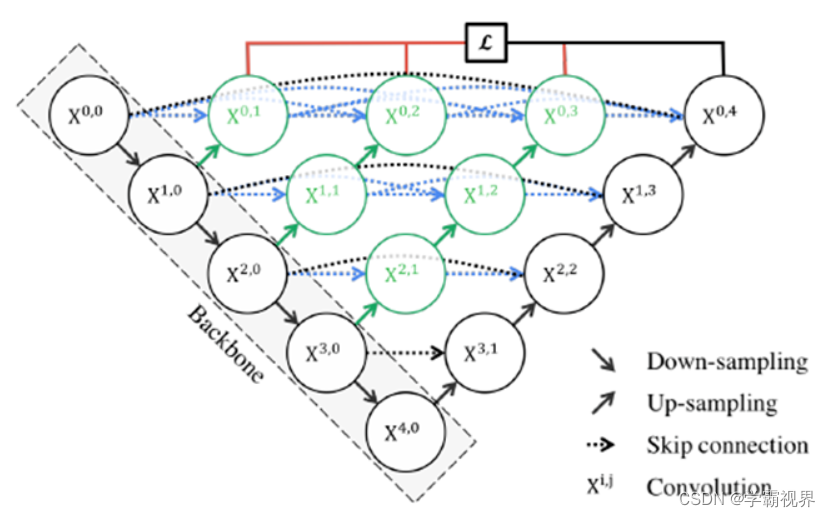
黑色部分为原始的UNet结构,包括编码器下采样、解码器上采样和黑色虚线的跳跃连接三个部分;绿色部分即嵌套的UNet子网络,包括卷积和上采样两部分,而蓝色虚线部分就是UNet++重新设计后的跳跃连接,这部分跟DenseNet的密集连接类似,这里是为子网络提供跳跃连接;最上面红黑连线则是UNet++补充的深监督机制,目的是为了网络能够顺利得到训练。
通过嵌套连接,约束了语义间隙的影响,保留了更多的信息以获得更好的分割结果。
本文方法框架
受UNet++的启发,本文将这种架构引入到图像融合任务中,并提出了一种基于巢连接的改进型巢连接融合框架和一种新颖的融合策略。
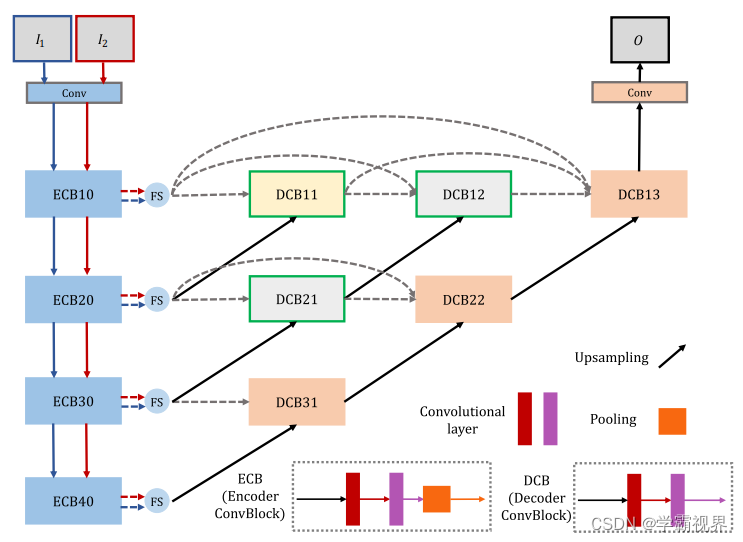
该融合网络包含三个主要部分:编码器 (蓝色方块)、融合策略(蓝色圆圈)和解码器(其他) 。在解码器网络中使用嵌套连接来处理由编码器提取的多尺度深度特征。“Conv”表示一个卷积层。“ECB”表示编码器卷积块,它包含两个卷积层和一个最大池化层。而“DCB”表示没有池化算子的解码器卷积块。首先,将两个输入图像分别输入编码器网络以获得多尺度深度特征。对于每个尺度特征,用新融合策略来融合所得特征。最后,利用融合的多尺度深度特征对融合后的图像进行重构。
训练阶段
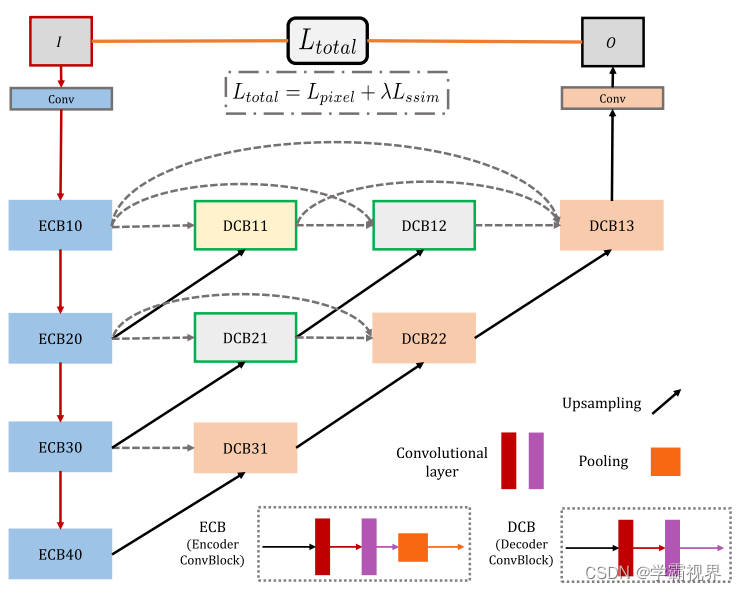
训练策略类似于DenseFuse。在训练阶段,融合策略被丢弃。损失函数 L total 定义为:
![]()
其中 L pixel 和 L ssim 分别表示输入图像 I 和输出图像 O 之间的像素损失和结构相似性 (SSIM ) 损失。λ 表示 L pixel 和 L ssim 之间的权值。
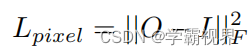
|| · || F 是 Frobenius 范数。L pixel 计算 O 和 I 之间的距离。此损失函数将确保重建图像在像素级别上与输入图像更相似。
![]()
训练阶段的目的是为编码器网络和解码器网络获得两个强大的工具。因此,训练阶段的输入图像类型不限于红外和可见图像。在训练阶段 ,用数据集 MS COCO训练该自动编码器网络。
融合策略
当融合策略被添加到测试阶段时, 融合网络变得更加灵活,然而,这些策略并不是为深度特征而设计的,并且还没有考虑注意力机制 。为了解决这个问题,本文介绍了一种基于两个阶段注意力模型的新融合策略。
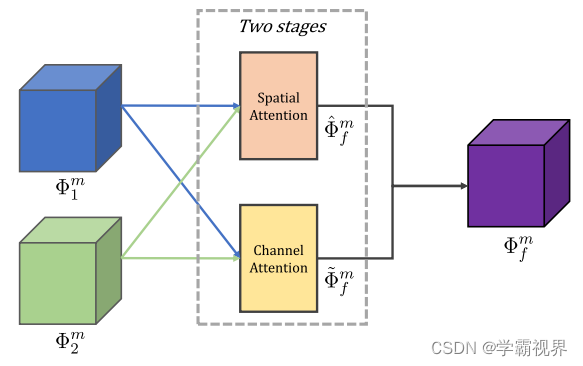
编码器分别从两输入图像中提取多尺度深度特征,分别通过空间注意模型和通道注意模型获得融合特征。最终的特征由下式生成:
![]()
空间注意模型
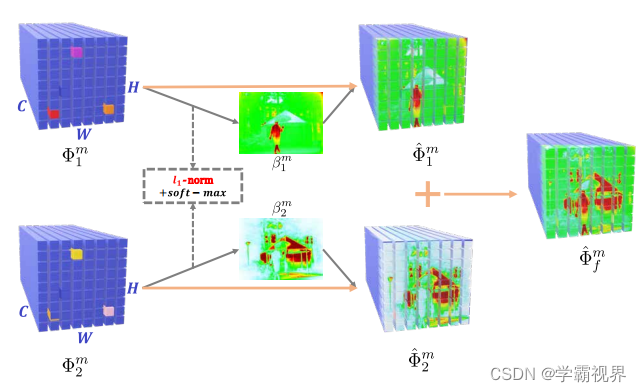
根据两个模态的特征图,使用I1-norm和softmax计算得到两个模态各自的权重图β,如下式。x和y是特征图上每个像素点的值,如果一个特征图包含C个通道,那么通过下式计算时点(x, y)对应一个长度为C的向量。
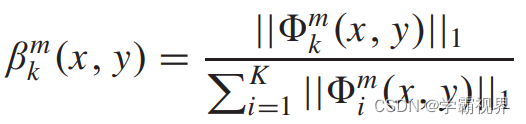
得到本模态下的权重图后与原特征图相乘,得到本模态的特征图,如下式。
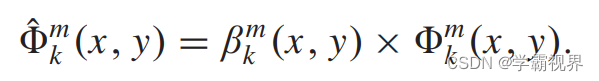
最后将两个模态的特征图相加,就能得到融合特征图了。
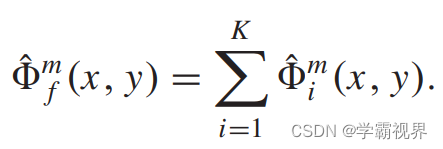
通道注意力模型
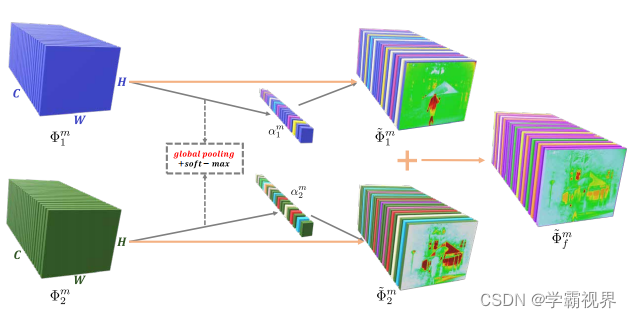
每个模态下的α通过全局池化和softmax计算得到,是一个长度为C的向量(C即特征图的通道数量)。
首先通过全局池化计算,如下式。本文采用了三种池化算子:1.平均池化;2.最大池化;3. nuclear-norm 池化(每个通道下所有像素值之和)。
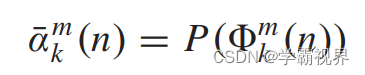
然后是softmax操作。
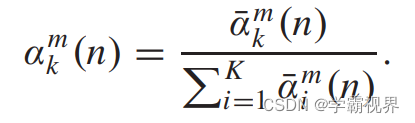
得到本模态下的权重图后与原特征图相乘,最后将两个模态的特征图相加,就能得到融合特征图了。
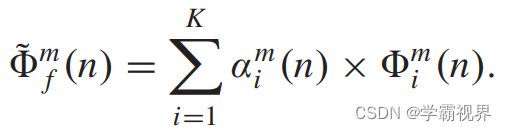

创新点
(1)本文基于嵌套连接的框架不同于现有的基于嵌套连接的框架。它分别包含三个部分 :编码器网络、融合策略和解码器网络。
(2)本文的嵌套连接架构充分利用了深度特征,保留了由编码器网络提取的更多不同尺度的特征信息。
(3)对于多尺度深度的特征融合,本文提出了一种基于空间注意力和通道注意力模型的新型融合策略。
结论
这种新颖的网络结构和多尺度深度特征融合策略,使更多的显著特征可以保留在重构过程中,并且融合性能也得到了提升。
不足
NestFuse虽然在解码器阶段使用了nest connection,不过和之前的有监督模型一样,可能针对模态之间的互补信息提取的较少,并且融合规则仍然是人工设计的方法。
文献阅读笔记的翻译是来自于: 学霸视界(xbsj.cool)推荐大家使用,可以免费翻译PDF!















 1375
1375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









