







EffNet: An efficient structure for convolutional neural network
Abstract: 随着卷积神经网络在客户产品中的应用不断增加,模型需要在嵌入式移动硬件上高效运行。 因此,较薄的模型已成为热门的研究课题,其各种方法从二进制网络到修订的卷积层变化。 我们为后者提供了贡献,并提出了一种新颖的卷积模块,它可以显着减少计算负担,同时超越当前的最新技术水平。 我们的模型,名为EffNet,针对开始时很小的模型进行了优化,旨在解决现有模型中的问题,如MobileNet和ShuffleNet
1. Introduction
由于3×3卷积现在是标准,它们成为优化的自然候选者。 论文[5](MobileNet)和[6](ShuffleNet)设置通过分离不同维度的计算来解决这个问题。 然而,在他们的方法中,他们留下了两个未解决的问题。 首先,两篇论文都报道了采用大型网络并使其更小,更高效。 将模型应用于更薄的网络时,结果会有所不同。 其次,两个提出的模型都为通过网络的数据流创造了一个积极的瓶颈[7]。 这种瓶颈在高冗余模型中可能是微不足道的,正如我们的实验所示,它对较小的模型具有破坏性影响。
2. Related work
该领域的大部分工作都集中在超参数优化上。 在目标算法和优化目标方面,这类算法相当普遍。[8] 通过最大化提高模型精度的概率,提出了黑盒算法的贝叶斯优化框架,如CNN和SVM。 这可以与[9]中的多目标优化相结合,以优化计算复杂性。 这些方法在正确初始化时大多运行良好,并且许多方法的搜索空间有限[10]。 使用强化学习,[11]训练了LSTM [12]来优化超参数,以提高准确性和速度。 这与最近的进化方法[13]相比,对搜索空间的限制较少,但需要额外的步骤使开发变得复杂。
….
最后和最类似于这项工作,[17],[5]和[6]的论文重新审视了共同卷积算子的本质。 这涉及卷积算子的尺寸分离dimension-wise,如[18]中所讨论的。 这里,使用明显更少的FLOP来近似原始操作。 [7]将3×3内核分成两个形状为3×1和1×3的连续内核.MobileNet模型[5]更进了一步,将信道方式与空间卷积分开,空间卷积也只是在深度方向上应用, 见图1b。 通过这样做,实现了FLOP的显着减少,同时大多数计算被转移到逐点层。 最后,ShuffleNet模型[6]通过以与[19]类似的方式将FLOP分成若干组来解决FLOP在积分层中的存储。 这导致FLOP的急剧减少,精度的影响相当小,见[6]和图1c中的图1。
….
3. Building blocks for increased model efficiency
The Bottleneck Structure
[21]中讨论的瓶颈结构将减少因子8应用于输出通道数量的块中输入通道的数量.SuffleNet块使用减少因子4 [6]。 然而,狭隘的模型往往没有足够的渠道进行如此大幅度的减少。 在我们的所有实验中,与更温和的减少相比,我们目睹了准确性的损失。 因此,我们建议使用瓶颈因子2。 另外,使用深度乘数为2的空间卷积(参见下面的段落)被发现是富有成效的,即第一深度卷积层也使信道量加倍。
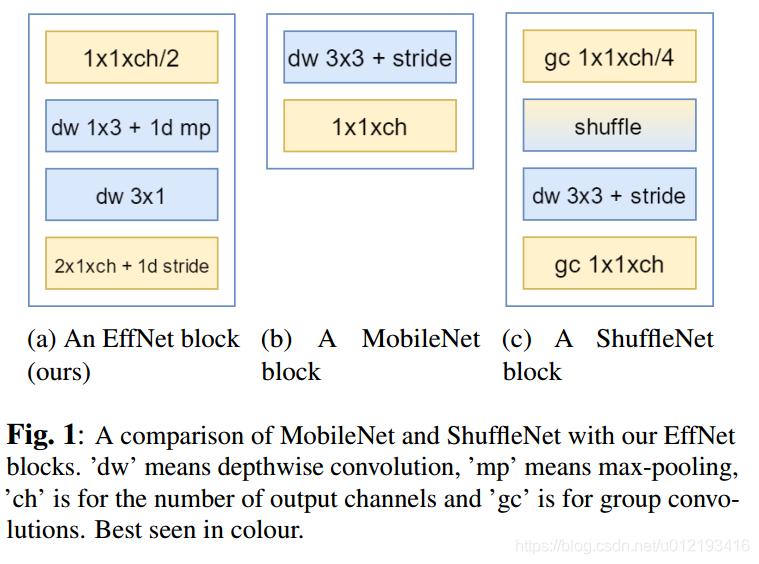
Strides and Pooling
Separable Convolutions
Residual Connections
Group Convolutions
Addressing the first layer
4. The effnet model
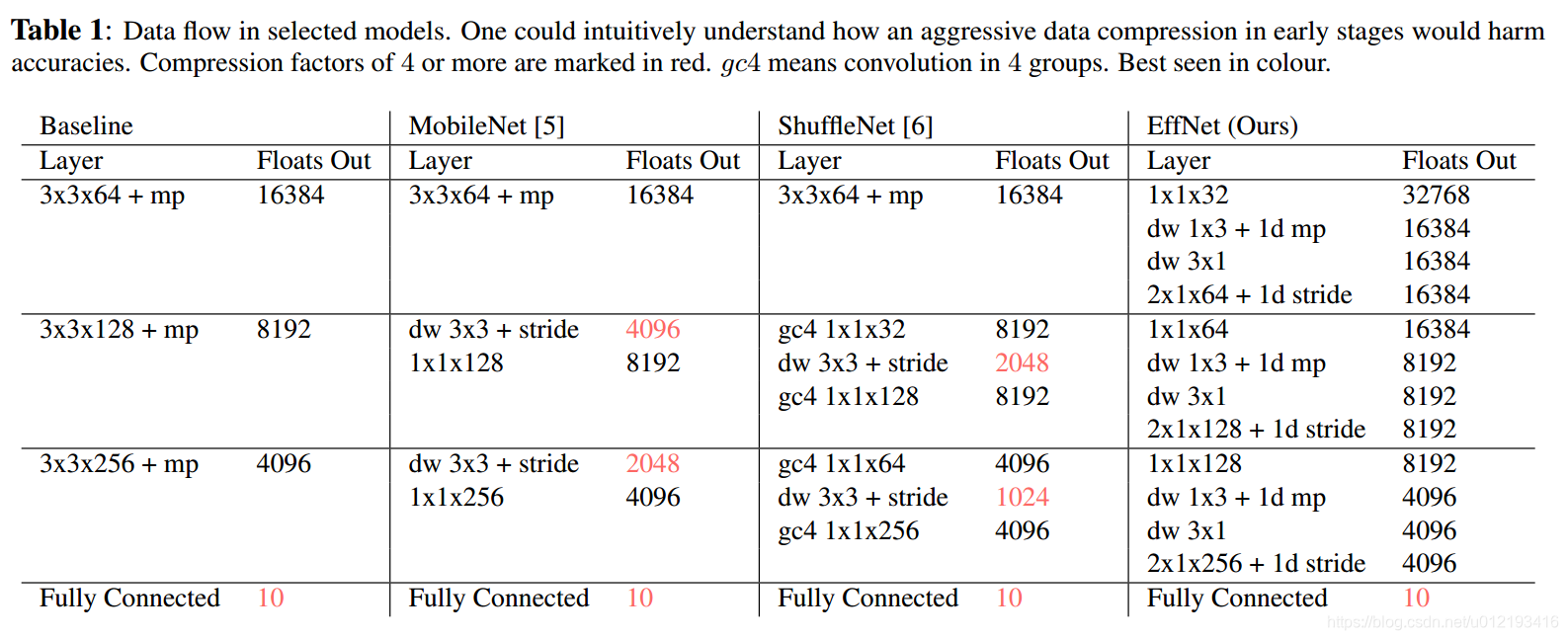
4.1 Data Compression
Each practice which led to larfer bottlenecks had also harmed the accuracies
4The effnet blocks
We propose an efficient convolutional block which both solves the issue of data compression and implements the insights from section 3. We design this block as a general construction to replace seamlessly the vanilla convolutional layers in, but not limited to, slim networks.
We start, in a similar manner to [7], by splitting the 3 × 3 depthwise convolution to two linear layers. This allows us to pool after the first spatial layer, thus saving computations in the second layer.
We then split the subsampling along the spatial dimensions. As seen in Table 1 and in Figure 1 we apply a 1×2 max pooling kernel after the first depthwise convolution. For the second subsampling we choose to replace the common pointwise convolution with 2 × 1 kernels and a corresponding stride.
This practically has the same amount of FLOPs yet leads to slightly better accuracies.Following the preliminary experiments in section 3, we decide to relax the bottleneck factor for the first pointwise convolution. Instead of using one fourth of the output channels,we recognise a factor of 0:5, with a minimal channel amount of 6, as preferable.

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









