









This tracker is able to track objects at 100 fps. This real-time speed is due to two factors.
First, most previous neural network trackers are trained online. However, training neural networks is a slow process, leading to slow tracking. In contrast, our tracker is trained offline to learn a generic relationship between appearance and motion, so no online training is required.
Second, most trackers take a classification-based approah, classifying many image patches to find the target object. In contrast, this tracker used a regression-based approach, requiring just a single feed-forward pass through the network to regresses directly to the location of the target object.
The combination of offline training and one-pass regression leads to a significant speed-up compared to previous approaches and allows it to track objects at real-time speeds.
下面这个是train使用的网络,跟deploy有点不一样哦。

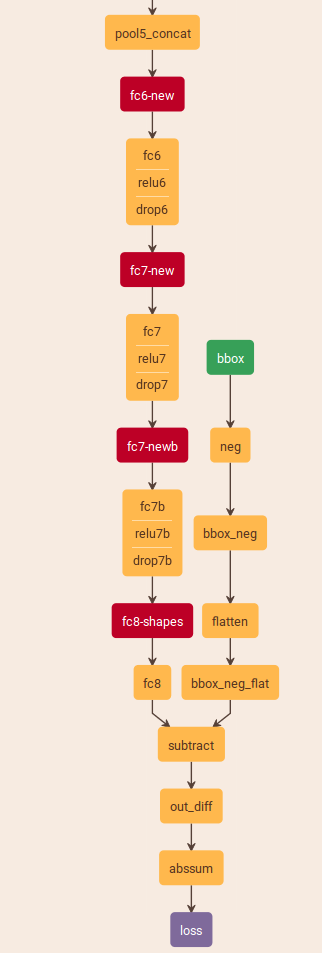
自己根据这个模型和网络实现的test过程,使用的是vot2014的数据库进行的测试,在测试过程中,在序列检测的过程中使用除第一帧(使用gounding truth)外,其他都是使用前一帧的结果进行target的获取,这使用过程中,发现,GOTURN回出现当相似的物体相遇之后,跟踪有时候回出现跳转到另外一个物体(分析:可以是在序列过程中误差的叠加造成forward时候的target一些偏差导致跟踪错误),还有,对于可形变物体跟踪效果也不好。(使用的时候要注意,输出的结果要除以10,才是得到的是左上角,和右下角相对于patch的位置)。
#include <string>
#include <vector>
#include "boost/algorithm/string.hpp"
#include "google/protobuf/text_format.h"
#include <opencv2/opencv.hpp>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/common.hpp"
#include "caffe/net.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/util/db.hpp"
#include "caffe/util/format.hpp"
#include "caffe/util/io.hpp"
#include <stdio.h>
#include <malloc.h>
#include <fstream>
#include <boost/progress.hpp>
#include <fstream>
#include <stdio.h>
#include <boost/math/special_functions/next.hpp>
#include <boost/random.hpp>
#include <limits>
#include "caffe/common.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/util/rng.hpp"
//#include "caffe/util/math_functions.hpp"
using caffe::Blob;
using caffe::Caffe;
using caffe::Datum;
using caffe::Net;
using caffe::Layer;
using std::string;
namespace db = caffe::db;
void loaddata_target(boost::shared_ptr<Net<float> >& net, std::string image_path);
void loaddata_image(boost::shared_ptr<Net<float> >& net, std::string image_path);
void loaddata_target(boost::shared_ptr<Net<float> >& net, cv::Mat image);
void loaddata_image(boost::shared_ptr<Net<float> >& net, cv::Mat image);
//int lap(int x1_min,int x1_max,int x2_min,int x2_max);
int main(int argc, char** argv){
Caffe::set_mode(Caffe::GPU);
boost::shared_ptr<Net<float> > net(new Net<float>(argv[1], caffe::TEST));
net->CopyTrainedLayersFromBinaryProto(argv[2]);
//argv[3]表示的是包含pictures的文件夹
cv::Mat target, image;
cv::Mat pre_image, cur_image;
cv::Point point1, point2;
float coord;
char* filepath = new char[100];
std::ifstream in;//;(string(string(argv[3])));
sprintf(filepath, "%s/groundtruth.txt",argv[3]);
in.open(filepath);
delete [] filepath;
in >> coord;
in >> coord;
in >> coord;
point1.x = int(coord);
in >> coord;
point1.y = int(coord);
in >> coord;
in >> coord;
in >> coord;
point2.x = int(coord);
in >> coord;
point2.y = int(coord);
in.close();
char* image_path = new char[100];
int count = 1;
int cols,rows;
int w,h;
while(1){
//std::cout << point1 << " " << point2 << std::endl;
sprintf(image_path,"%s/%.8d.jpg",argv[3],count++);
pre_image = cv::imread(image_path);
//std::cout << image_path << std::endl;
sprintf(image_path,"%s/%.8d.jpg",argv[3],count++);
cur_image = cv::imread(image_path);
cols = cur_image.cols;
rows = cur_image.rows;
if(cols == 0 || rows == 0) break;
w = point2.x - point1.x;
h = point2.y - point1.y;
//std::cout << w <<" h=" << h << std::endl;
point1.x = point1.x - w/2;
point1.y = point1.y - h/2;
point2.x = point2.x + w/2;
point2.y = point2.y + h/2;
//std::cout << point1 << " " << point2 << std::endl;
point1.x = point1.x < 0 ? 0 : point1.x;
point1.y = point1.y < 0 ? 0 : point1.y;
point2.x = point2.x > cols ? cols : point2.x;
point2.y = point2.y > rows ? rows : point2.y;
// std::cout << point1 << " " << point2 << std::endl;
target = pre_image(cv::Rect(point1,point2));
image = cur_image(cv::Rect(point1,point2));
loaddata_target(net,target);
loaddata_image(net,image);
net->Forward();
Blob<float>* output_layer = net->output_blobs()[0];
std::vector<int> points;
points.push_back(int(image.cols*((output_layer->cpu_data()[0]/10))));
points.push_back(int(image.rows*((output_layer->cpu_data()[1]/10))));
points.push_back(int(image.cols*((output_layer->cpu_data()[2]/10))));
points.push_back(int(image.rows*((output_layer->cpu_data()[3]/10))));
point2.x = point1.x + points[2];
point2.y = point1.y+ points[3];
point1.x += points[0];
point1.y += points[1];
cv::rectangle(cur_image, cv::Rect(point1,point2),cv::Scalar(0,225,255),1);
cv::imshow("target",target);
cv::imshow("image",cur_image);
if(count == 3)
cv::waitKey(0);
cv::waitKey(33);
//std::cout << image_path << std::endl;
//target = pre_image();
// break;
}
delete [] image_path;
return 1;
}
void loaddata_target(boost::shared_ptr<Net<float> >& net, std::string image_path){
Blob<float>* input_layer = net->input_blobs()[0];
int width, height;
width = input_layer->width();
height = input_layer->height();
int size = width*height;
cv::Mat image = cv::imread(image_path,-1);
cv::Mat image_resized;
cv::resize(image, image_resized, cv::Size(height, width));
float* input_data = input_layer->mutable_cpu_data();
int temp,idx;
for(int i = 0; i < height; ++i){
uchar* pdata = image_resized.ptr<uchar>(i);
for(int j = 0; j < width; ++j){
temp = 3*j;
idx = i*width+j;
input_data[idx] = (pdata[temp+2]);
input_data[idx+size] = (pdata[temp+1]);
input_data[idx+2*size] = (pdata[temp+0]);
}
}
//cv::imshow("image",image_resized);
}
void loaddata_image(boost::shared_ptr<Net<float> >& net, std::string image_path){
Blob<float>* input_layer = net->input_blobs()[1];
int width, height;
width = input_layer->width();
height = input_layer->height();
int size = width*height;
cv::Mat image = cv::imread(image_path,-1);
cv::Mat image_resized;
cv::resize(image, image_resized, cv::Size(height, width));
float* input_data = input_layer->mutable_cpu_data();
int temp,idx;
for(int i = 0; i < height; ++i){
uchar* pdata = image_resized.ptr<uchar>(i);
for(int j = 0; j < width; ++j){
temp = 3*j;
idx = i*width+j;
input_data[idx] = (pdata[temp+2]);
input_data[idx+size] = (pdata[temp+1]);
input_data[idx+2*size] = (pdata[temp+0]);
}
}
//cv::waitKey(0);
//cv::imshow("image",image_resized);
}
void loaddata_target(boost::shared_ptr<Net<float> >& net, cv::Mat image){
Blob<float>* input_layer = net->input_blobs()[0];
int width, height;
width = input_layer->width();
height = input_layer->height();
int size = width*height;
//cv::Mat image = cv::imread(image_path,-1);
cv::Mat image_resized;
cv::resize(image, image_resized, cv::Size(height, width));
float* input_data = input_layer->mutable_cpu_data();
int temp,idx;
for(int i = 0; i < height; ++i){
uchar* pdata = image_resized.ptr<uchar>(i);
for(int j = 0; j < width; ++j){
temp = 3*j;
idx = i*width+j;
input_data[idx] = (pdata[temp+2])-104;
input_data[idx+size] = (pdata[temp+1])-117;
input_data[idx+2*size] = (pdata[temp+0])-123;
}
}
//cv::imshow("image",image_resized);
}
void loaddata_image(boost::shared_ptr<Net<float> >& net, cv::Mat image){
Blob<float>* input_layer = net->input_blobs()[1];
int width, height;
width = input_layer->width();
height = input_layer->height();
int size = width*height;
//cv::Mat image = cv::imread(image_path,-1);
cv::Mat image_resized;
cv::resize(image, image_resized, cv::Size(height, width));
float* input_data = input_layer->mutable_cpu_data();
int temp,idx;
for(int i = 0; i < height; ++i){
uchar* pdata = image_resized.ptr<uchar>(i);
for(int j = 0; j < width; ++j){
temp = 3*j;
idx = i*width+j;
input_data[idx] = (pdata[temp+2])-104;
input_data[idx+size] = (pdata[temp+1])-117;
input_data[idx+2*size] = (pdata[temp+0])-123;
}
}
//cv::waitKey(0);
//cv::imshow("image",image_resized);
}
deploy.prototxt
name: "CaffeNet"
input: "target"
input: "image"
#target
input_dim: 1
input_dim: 3
input_dim: 227
input_dim: 227
#image
input_dim: 1
input_dim: 3
input_dim: 227
input_dim: 227
layer {
name: "conv1" type: "Convolution" bottom: "target" top: "conv1" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 96 kernel_size: 11 stride: 4 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 0 }
}
}
layer {
name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" }
layer {
name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
layer {
name: "norm1" type: "LRN" bottom: "pool1" top: "norm1" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 }
}
layer {
name: "conv2" type: "Convolution" bottom: "norm1" top: "conv2" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256 pad: 2 kernel_size: 5 group: 2 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu2" type: "ReLU" bottom: "conv2" top: "conv2" }
layer {
name: "pool2" type: "Pooling" bottom: "conv2" top: "pool2" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
layer {
name: "norm2" type: "LRN" bottom: "pool2" top: "norm2" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 }
}
layer {
name: "conv3" type: "Convolution" bottom: "norm2" top: "conv3" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384 pad: 1 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 0 }
}
}
layer {
name: "relu3" type: "ReLU" bottom: "conv3" top: "conv3" }
layer {
name: "conv4" type: "Convolution" bottom: "conv3" top: "conv4" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu4" type: "ReLU" bottom: "conv4" top: "conv4" }
layer {
name: "conv5" type: "Convolution" bottom: "conv4" top: "conv5" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu5" type: "ReLU" bottom: "conv5" top: "conv5" }
layer {
name: "pool5" type: "Pooling" bottom: "conv5" top: "pool5" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
layer {
name: "conv1_p" type: "Convolution" bottom: "image" top: "conv1_p" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 96 kernel_size: 11 stride: 4 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 0 }
}
}
layer {
name: "relu1_p" type: "ReLU" bottom: "conv1_p" top: "conv1_p" }
layer {
name: "pool1_p" type: "Pooling" bottom: "conv1_p" top: "pool1_p" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
layer {
name: "norm1_p" type: "LRN" bottom: "pool1_p" top: "norm1_p" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 }
}
layer {
name: "conv2_p" type: "Convolution" bottom: "norm1_p" top: "conv2_p" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256 pad: 2 kernel_size: 5 group: 2 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu2_p" type: "ReLU" bottom: "conv2_p" top: "conv2_p" }
layer {
name: "pool2_p" type: "Pooling" bottom: "conv2_p" top: "pool2_p" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
layer {
name: "norm2_p" type: "LRN" bottom: "pool2_p" top: "norm2_p" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 }
}
layer {
name: "conv3_p" type: "Convolution" bottom: "norm2_p" top: "conv3_p" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384 pad: 1 kernel_size: 3 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 0 }
}
}
layer {
name: "relu3_p" type: "ReLU" bottom: "conv3_p" top: "conv3_p" }
layer {
name: "conv4_p" type: "Convolution" bottom: "conv3_p" top: "conv4_p" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 384 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu4_p" type: "ReLU" bottom: "conv4_p" top: "conv4_p" }
layer {
name: "conv5_p" type: "Convolution" bottom: "conv4_p" top: "conv5_p" param { lr_mult: 0 decay_mult: 1 }
param {
lr_mult: 0 decay_mult: 0 }
convolution_param {
num_output: 256 pad: 1 kernel_size: 3 group: 2 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu5_p" type: "ReLU" bottom: "conv5_p" top: "conv5_p" }
layer {
name: "pool5_p" type: "Pooling" bottom: "conv5_p" top: "pool5_p" pooling_param { pool: MAX kernel_size: 3 stride: 2 }
}
layer {
name: "concat" type: "Concat" bottom: "pool5" bottom: "pool5_p" top: "pool5_concat" concat_param { axis: 1 }
}
layer {
name: "fc6-new" type: "InnerProduct" bottom: "pool5_concat" top: "fc6" param { lr_mult: 10 decay_mult: 1 }
param {
lr_mult: 20 decay_mult: 0 }
inner_product_param {
num_output: 4096 weight_filler { type: "gaussian" std: 0.005 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu6" type: "ReLU" bottom: "fc6" top: "fc6" }
layer {
name: "drop6" type: "Dropout" bottom: "fc6" top: "fc6" dropout_param { dropout_ratio: 0.5 }
}
layer {
name: "fc7-new" type: "InnerProduct" bottom: "fc6" top: "fc7" param { lr_mult: 10 decay_mult: 1 }
param {
lr_mult: 20 decay_mult: 0 }
inner_product_param {
num_output: 4096 weight_filler { type: "gaussian" std: 0.005 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu7" type: "ReLU" bottom: "fc7" top: "fc7" }
layer {
name: "drop7" type: "Dropout" bottom: "fc7" top: "fc7" dropout_param { dropout_ratio: 0.5 }
}
layer {
name: "fc7-newb" type: "InnerProduct" bottom: "fc7" top: "fc7b" param { lr_mult: 10 decay_mult: 1 }
param {
lr_mult: 20 decay_mult: 0 }
inner_product_param {
num_output: 4096 weight_filler { type: "gaussian" std: 0.005 }
bias_filler {
type: "constant" value: 1 }
}
}
layer {
name: "relu7b" type: "ReLU" bottom: "fc7b" top: "fc7b" }
layer {
name: "drop7b" type: "Dropout" bottom: "fc7b" top: "fc7b" dropout_param { dropout_ratio: 0.5 }
}
layer {
name: "fc8-shapes" type: "InnerProduct" bottom: "fc7b" top: "fc8" param { lr_mult: 10 decay_mult: 1 }
param {
lr_mult: 20 decay_mult: 0 }
inner_product_param {
num_output: 4 weight_filler { type: "gaussian" std: 0.01 }
bias_filler {
type: "constant" value: 0 }
}
}














 8442
8442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









