







1. 分段机制概述
对于分段机制,要从Intel的微处理器的8086开始说起,刚开始内存空间比较小,内存寻址采用的是直接访问物理地址的方式。由于技术的发展,计算机做的事情越来越多,程序也越来越大,为了更大的内存空间,把地址总线扩展到20位。但是,对于内存设计,一个很尴尬的问题产生了,之前的设计CPU的ALU宽度只有16位,也就是说,ALU不能访问20位的地址空间,那时就设计了段机制来处理这种情况。为了坚持这种兼容性,386依然运用段机制,直至现在的64位处理器已经看不到段机制的身影。
1.1 分段机制产生的原因
为了保持兼容,分段机制的被引入,我们来实际的理解分段机制解决了什么实质性的问题呢?在分段机制还没有出现的时候,程序运行是需要从内存分配出足够多的连续内存,然后整个程序装载进去。例如:
某个程序大小是100M,然后我们就需要有连续的100M内存空间才能把这个程序装载到内存里面。如果无法找到连续的100M内存空间,就无法把这个程序装载进内存空间,程序就无法得到运行。
假设我们的内存可以提供连续的区域来使得程序运行,那么我们来看一下还会存在有什么问题呢?
地址空间不隔离(安全性):如何有两个程序运行A和B,程序A在内存的地址假设为0x0->0x100,而程序B在内存中的地址假设为0x100->0x199。那么假设程序员A本来想存在属于A的地址0x50,而不小心访问到属于B的地址0x150,那么不好的事情就将发生了,A和B程序都异常了。对于程序员B来说,是飞来横祸,同时也很难定位到问题,这种情况会导致程序能访问所有的内存空间,恶意修改数据可能超成安全问题。
程序运行时地址不确定(动态链接):程序每次要运行的时候,都是需要装载到内存中的,假设你在程序中写死了要操作某个地址的内存,例如你要地址0x150。但是问题来了,你能够保证你操作的地址0x150真的就是你原来想操作的那个位置吗?很可能程序第一次装载进内存的位置是0x100->0x199,而程序第二次运行的时候,这个程序装载进内存的位置变成了0x0->0x100,而你操作的0x150地址压根就不是属于这个程序所占有的内存。
内存使用率低下(内存共享):假设我们写了3个程序其中程序A大小为10M,程序B为70M,程序C的大小为30M你的计算机的内存总共有100M。这三个程序加起来有110M,显然这三个程序是无法同时存在于内存中的。并且最多只能够同时运行两个程序。可能是这样的,程序A占有的内存空间是0x00000000~0x00000009,程序B占有的内存空间是0x00000010~0x00000079。假设这个时候程序C要运行该怎么做?可以把其中的一个程序换出到磁盘上,然后再把程序C装载到内存中。假设是把程序A换出,那么程序C还是无法装载进内存中,因为内存中空闲的连续区域有两块,一块是原来程序A占有的那10M,还有就是从0x00000080~0x00000099这20M,所以,30M的程序C无法装载进内存中。那么,唯一的办法就是把程序B换出,保留程序A,但是,此时会有60M的内存无法利用起来。
为了解决这一些问题,分段的概念应运而生。在计算机科学领域,任何的问题都可以通过增加一个间接的中间层来解决问题,那么为了实现分段的这个技术,就需要引入虚拟地址空间的概念。
我们来了解下,虚拟地址空间和物理地址空间的概念,简单的说来,对于可以寻址的一片空间,如果这个空间是虚拟的,我们就叫做虚拟的地址空间;如果这个空间是真实存在的,我们就叫做物理地址空间。虚拟地址空间是虚拟的,所有就决定了他可以是任意的大,而物理地址空间必须是真实存在的,是由实际的硬件决定的。
1.2 硬件分段机制
分段是一种隔离不同的代码、数据、栈模块的机制,能够保证不同进程或任务不会互相干扰。我们可以为一个进程分配属于它的段集合,CPU 的硬件机制会保证其代码不会越权访问段,也不会访问到段外的地址。
分段机制就是把虚拟地址空间中的虚拟内存组织成一些长度可变的的段的内存单元,80386虚拟地址空间中的逻辑地址由一个段部分和一个段内偏移部分构成,段是虚拟地址空间到线性地址转换的基础。每个段都有3个参数定义
段基地址:指定段在线性地址空间中的开始地址,基地址是线性地址对应于段中偏移0处
段限长:是虚拟地址空间中段内最大可用偏移地址,定义了段的长度
段属性:指定段的特性,如该段是否可读,可写或可执行,段的特权级等
当需要访问处理器地址空间的某个字节时,段选择符指定了该字节所在的段,偏移量制定了该字节在段中相对于段基址的位置,处理器把逻辑地址转化成一个线性地址的过程如下:
1.使用段选择符中的偏移值(在GDT(全局描述符表) 或 LDT(局部描述符表)中定位相应的段描述符
2.利用段描述符校验段的访问权限和范围,以确保该段是可以访问的并且偏移量位于段界限内
3.利用段描述符中取得的段基地址加上偏移量,形成一个线性地址
1.2.1 段选择符
段选择符(或称段选择子)是段的一个十六位标志符,如下图所示。段选择符并不直接指向段,而是指向段描述符表中定义段的段描述符。
段选择符包括 3 个字段的内容:
请求特权级RPL([0:1])
表指引标志TI([2])TI = 0 ,表示描述符在GDT中,TI = 1,表示描述符在LDT中
索引值,给出了描述符在GDT或LDT表中的索引项号
下面是一些段选择符的示例:
1.2.2 段描述符
段描述符表是段描述符的一个数组,如下图所示。描述符表的长度可变,最多可以包含8192个 8 byte 描述符。有两个描述符表: 全局描述符表GDT (Global descriptor table); 局部描述符表 LDT (Local descriptor table),由段选择符的bit[2]会选择到对应的GDT表还是LDT表去拿到对应的段基址。
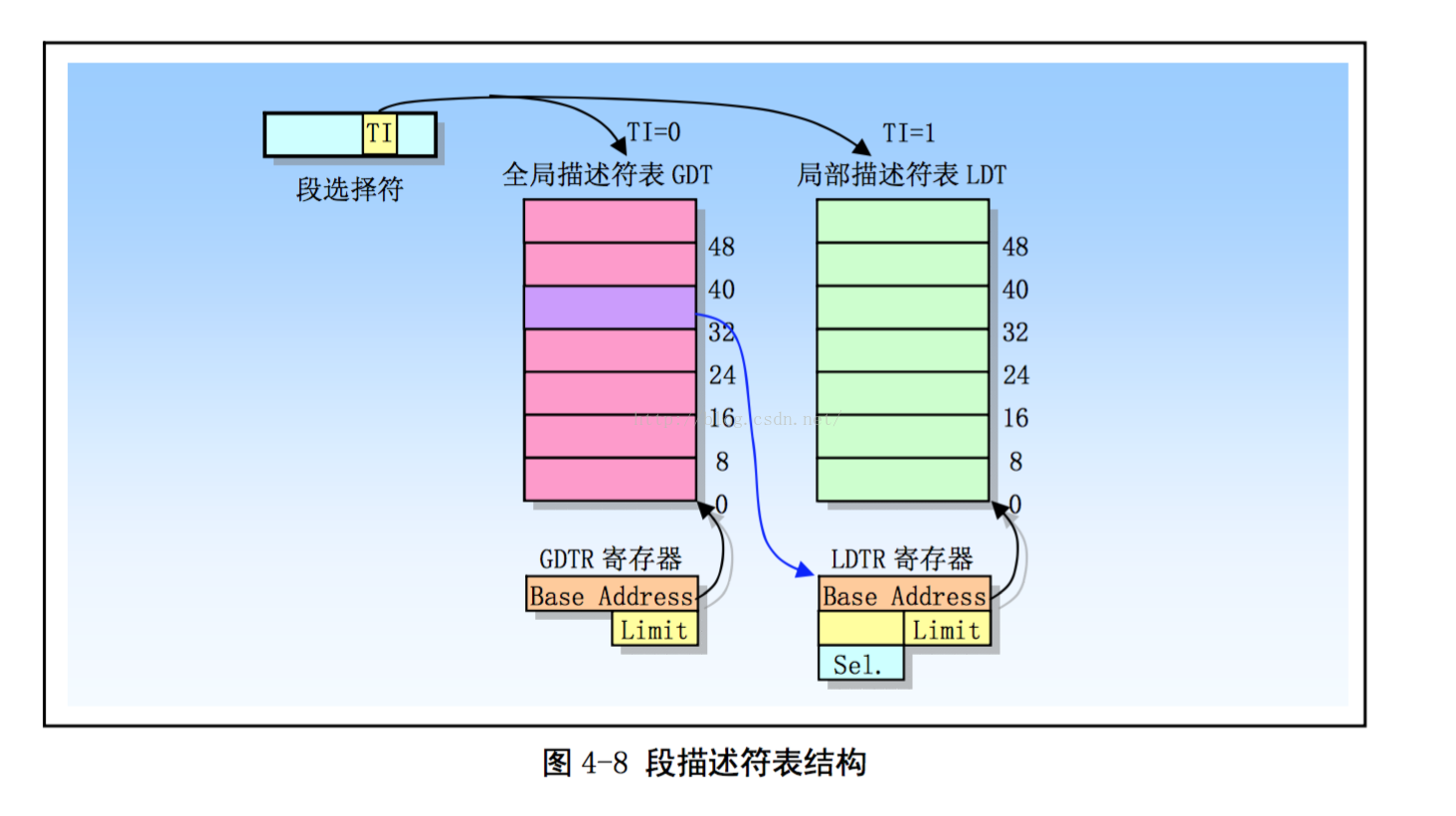
而对于段描述符,每个段描述符长度是 8 字节,含有三个主要字段:段基地址、段限长和段属性。段描述符通常由编译器。链接器、加载器或者操作系统来创建,绝不可能由应用程序来创建。
段描述符通用格式如下:
了解了这个过程,我们来总体的梳理下,如果使用分段机制,那么怎么使虚拟地址空间转到对应的物理地址空间呢?转换过程如下图所示
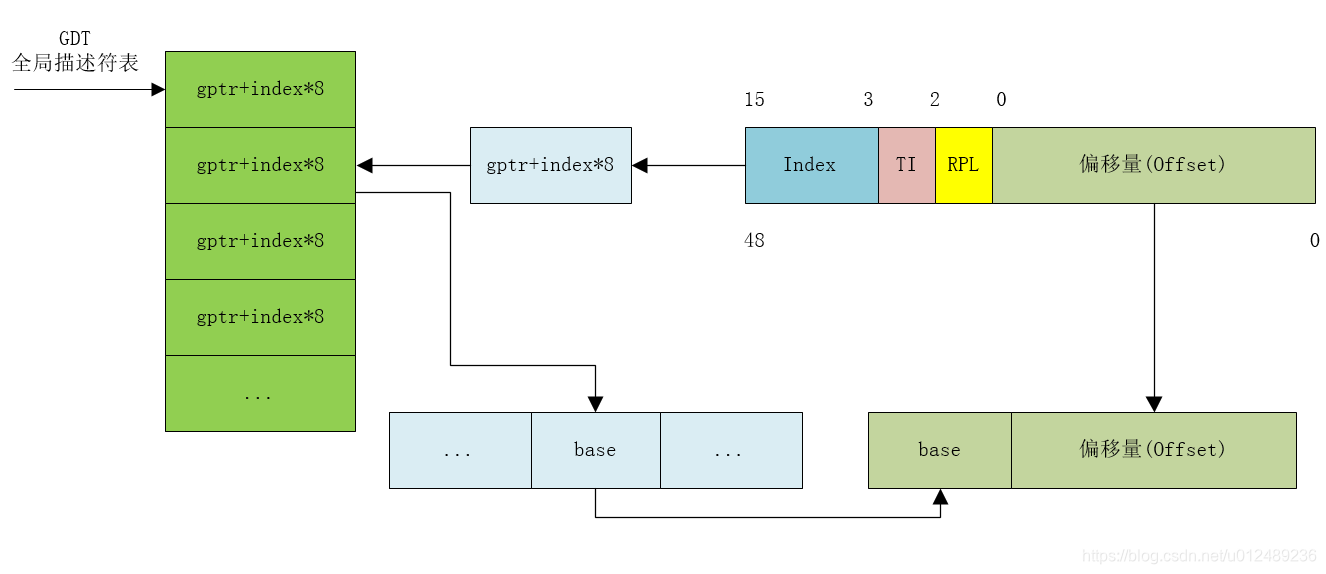
1.取出虚拟地址空间中的段选择符,根据TI位判断段描述符是存储在GDT还是LDT中
2.段选择符中的index*8,也就是左移3位,就是段描述符在GDT中的位置,在加上GDT的基地址,就是段描述符的地址,从而去除段描述符
3.段描述符中保存了该段的基地址,加上虚拟地址中的偏移量就是对应到的物理地址空间。
2. Linux中分段的实现原理
上一节讨论了80x86如何从硬件上提供分段机制的支持,而本节讨论下linux如何使用分段机制。最开始的时候,操作系统不支持分段,内存的换入换出都是以整个进程的内存空间为单位,导致系统非常的耗时,同时利用率也不高,当内存不足,很容易导致内存交换失败。后来有了分段技术,把内存空间分成多个模块:代码段、数据段,或者是一个大的数据块,段成了内存交换的单位,在一定程度上增加了内存利用率。那时候还没有分页技术,虚拟地址(线性地址)是直接映射到物理空间的。
引入分页机制后,目前linux很少使用分段,分段和分页在某些方面是冗余的,因为他们都可以把物理地址空间分割成不同部分:分段给每个进程分配不同的逻辑地址空间,而分页可以把相同的逻辑地址空间映射到不同的物理地址上。因此,Linux优先采用了分页(分页操作系统),基于以下原因:
内存管理更简单:所有进程使用相同段寄存器值,也就是相同的线性地址集
出于兼容大部分硬件架构的考虑,RISC架构对分段支持的不是很好
所以自从x86-64起,除了在“传统模式”下,分段机制已被认为是过时的且不再被支持。虽然在x86-64的本机模式下仍然有分段机制的某些痕迹,但大多只是为了兼容,且它们不再具起到同样的作用,也不再提供真正的分段。
那么linux内核是怎么支持分段机制呢?我们来看上节的分段机制的原理图如下
比如,我们将虚拟地址空间分成4个段,用0-3来编号,每个段在段表中有一个项,在物理空间中,段的排列如下图所示
如果要访问段2中偏移量为600的虚拟地址,我们可以计算出物理地址为段基地址+偏量=2000+600=2600
3. Linux分段机制的软件实现
Linux对段机制的应用效果是等价于几乎绕过了段基址。在Linux中仅有4个段,用户代码段、数据段和内核代码段、数据段。
Segment Base G Limit Type DPL S D/B P
user code 0x00000000 1 0xfffff 10 3 1 1 1
user data 0x00000000 1 0xfffff 2 3 1 1 1
kernel code 0x00000000 1 0xfffff 10 0 1 1 1
kernel data 0x00000000 1 0xfffff 2 0 1 1 1
这些段相应的选择器分别由以下宏定义:_USER_CS, __USER_DS, __KERNEL_CS, 和__KERNEL_DS。举例来说,如果要定位内核代码段,内核只需要加载__KERNEK_CS宏的值到cs寄存器中。 接下来我们看一下linux代码吧,进入保护模式的函数go_to_protected_mode:
void go_to_protected_mode(void)
{
/* Hook before leaving real mode, also disables interrupts */
realmode_switch_hook();
/* Enable the A20 gate */
if (enable_a20()) {
puts("A20 gate not responding, unable to boot...\n");
die();
}
/* Reset coprocessor (IGNNE#) */
reset_coprocessor();
/* Mask all interrupts in the PIC */
mask_all_interrupts();
/* Actual transition to protected mode... */
setup_idt();
setup_gdt();
protected_mode_jump(boot_params.hdr.code32_start,
(u32)&boot_params + (ds() << 4));
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
里面的函数略带一下吧,realmode_switch_hook()根据注释和函数命名可以知道这是在实模式切换前的钩子函数调用的地方;enable_a20()这个太熟悉了,就开启A20;reset_coprocessor()是把协处理器重置一下mask_all_interrupts()则是把中断关了,避免切换过程中出现状况。其中setup_idt()和setup_gdt()是本节的重点,函数名字告诉我们这是设置idt和gdt的,看一下两者具体代码吧:
static void setup_idt(void)
{
static const struct gdt_ptr null_idt = {0, 0};
asm volatile("lidtl %0" : : "m" (null_idt));
}
1
2
3
4
5
根据setup_idt()的实现,可以明显看到这没做什么,纯粹置一下idt为空的描述符表。
static void setup_gdt(void)
{
/* There are machines which are known to not boot with the GDT
being 8-byte unaligned. Intel recommends 16 byte alignment. */
static const u64 boot_gdt[] __attribute__((aligned(16))) = {
/* CS: code, read/execute, 4 GB, base 0 */
[GDT_ENTRY_BOOT_CS] = GDT_ENTRY(0xc09b, 0, 0xfffff),
/* DS: data, read/write, 4 GB, base 0 */
[GDT_ENTRY_BOOT_DS] = GDT_ENTRY(0xc093, 0, 0xfffff),
/* TSS: 32-bit tss, 104 bytes, base 4096 */
/* We only have a TSS here to keep Intel VT happy;
we don't actually use it for anything. */
[GDT_ENTRY_BOOT_TSS] = GDT_ENTRY(0x0089, 4096, 103),
};
/* Xen HVM incorrectly stores a pointer to the gdt_ptr, instead
of the gdt_ptr contents. Thus, make it static so it will
stay in memory, at least long enough that we switch to the
proper kernel GDT. */
static struct gdt_ptr gdt;
gdt.len = sizeof(boot_gdt)-1;
gdt.ptr = (u32)&boot_gdt + (ds() << 4);
asm volatile("lgdtl %0" : : "m" (gdt));
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
首先,我们看看之前的GDT entry的结构图如下:
GDT_ENTRY的定义如下:
/* Constructor for a conventional segment GDT (or LDT) entry */
/* This is a macro so it can be used in initializers */
#define GDT_ENTRY(flags, base, limit) \
((((base) & 0xff000000ULL) << (56-24)) | \
(((flags) & 0x0000f0ffULL) << 40) | \
(((limit) & 0x000f0000ULL) << (48-16)) | \
(((base) & 0x00ffffffULL) << 16) | \
(((limit) & 0x0000ffffULL)))
1
2
3
4
5
6
7
8
可以清楚得看到,base, limit和flag通过位移和或组成了GDT_ENTRY。其中flags代表了40-47位的access byte和52-55位的flags。
CS和DS的flags为0xc0,所以G=1,意味着4K为一个页面,B/D为1,1-32位段;
CS的Access Byte=0x9b,意味着P=1(合法的Entry Pr必须为1),DPL=0,S=1,这里该段只能在Ring 0下访问,该段是代码段
DS的Access Byte=0x93,意味着P=1(合法的Entry Pr必须为1),DPL=0,S=1,这里该段只能在Ring 0下访问,该段是数据段
linux中逻辑地址等于线性地址。为什么这么说呢?因为Linux所有的段(用户代码段、用户数据段、内核代码段、内核数据段)的线性地址都是从 0x00000000 开始,长度4G,这样 线性地址=逻辑地址+ 0x00000000,也就是说逻辑地址等于线性地址了。通过分析,我们发现,所有的段的起始地址都是一样的,都是 0。这算哪门子分段嘛!所以,在 Linux 操作系统中,并没有使用到全部的分段功能。那分段是不是完全没有用处呢?分段可以做权限审核,例如用户态 DPL 是 3,内核态 DPL 是 0。当用户态试图访问内核态的时候,会因为权限不足而报错。
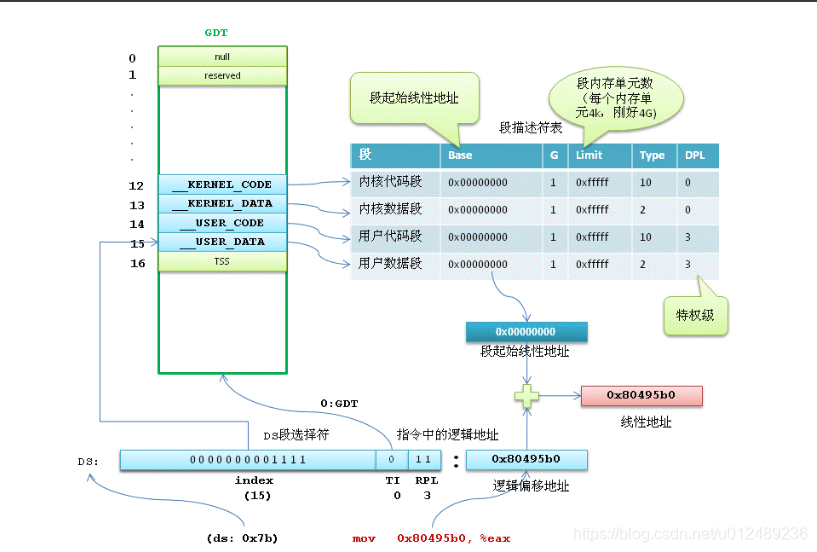
还是以 mov 0x80495b0, %eax 中的地址为例分析一下转换过程:
1.首先段选择符中的TI为0,表明段描述符在GDT表中,使用段选择符中的偏移值定位到相应的段描述符,找到15这个位置
2.从15号位置的段描述符,找到对应的访问权限,访问基地址(0)和访问范围(0xffff)
3.利用段描述符中去得到的段基址0x0000000,加上逻辑地址偏移0x80495b0,形成线性地址0x80495b0。
所以Linux没有采用严格的分段机制,已经慢慢的弱化分段机制,而使用分页机制来替换分段机制。
4. 分段机制的优缺点
现在大致了解了分段的基本原理,系统运行时,地址空间中不同段被重定位到物理内存中,与之前的整个物理地址空间中只有一个基地址+偏移量的方式相比,大量的节省了物理内存。同时分段管理就是将一个程序按照逻辑单元分成多个程序段,每一个段使用自己单独的虚拟地址空间。例如,对于编译器来说,我们可以给其5个段,占用5个虚拟地址空间,如下图所示

如此,一个段占用一个虚拟地址空间,不会发生空间增长时碰撞到另一个段的问题,从而避免因空间不够而造成编译失败的情况。如果某个数据结构对空间的需求超过整个虚拟之地所能够提供的空间,则编译仍将失败,开编提到的问题1好像得到了完美解决。
正是因为这种映射,使得程序无需关注物理地址是多少,只要虚拟地址没有改变,那么程序就不会操作地址不当,问题2也好像可以很好的解决。
但是问题3,是换入换出的问题,这个问题的关键是能不能在换出一个完整程序之后,把另外一个程序换进来,而这种分段机制,就存在一个很严重的问题。
物理内存很快就会被许多空间空间的小块,因为很难分配给新的段,或扩大已有的段,这种问题被成为外部碎片
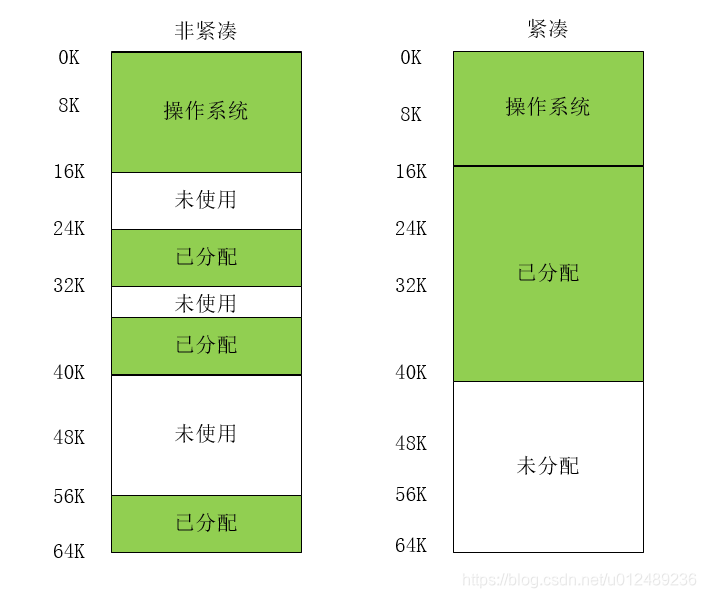
分段机制采用的是分段,这就导致一个问题,已分配的段有大有小,未使用的段也有大有小,将要分配的段也有大有小,各方需求不一定,理想的情况,但系统中的程序比较少,内存没有完全使用的情况下会如紧凑型分配。但是在程序运行过程中,有些程序运行完后,要释放新已分配的内存空间,当使用一段时间后,可能会出现非紧凑的情况,在这个例子中,一个进程需要分配一个20K的段,当前有24K的空闲,却不连续,因此操作系统无法满足这20K的请求。这也就是外部碎片,其特征如下:
外部碎片是指还没有被分配出去(不属于任何进程),但是由于太小了,无法分配给申请内存空间的新进程的内存空闲区域。
虽然这些存储块的总和可以满足当前申请的长度的要求,但是由于他们的地址不连续或者其他原因,使得系统无法满足当前的申请。
5. 分段机制的改进之路
紧凑物理内存,重新安排原有的段,例如,操作系统先终止运行的进程,将他们的数据复制到连续的内存区域中去,改变他们的段寄存器中的值,指向新的物理地址,从而得到足够大的连续空闲空间。这样做,大大提高了成本,系统开销也很大,会占用大量的处理器时间。
软件优化的算法,一种更简单的做法是利用空闲列表管理算法,保留打的内存块用于分配,相关的算法很多,例如传统的最优匹配(从空闲链表中找到最接近需要分配空间的空闲块返回)、最坏匹配、首次匹配以及伙伴算法等。但是遗憾的是,无论算法多么精妙,都无法完全的消除外部碎片。
无论如何分段机制解决了上面两个问题,是一个很大的进步,但是对于内存效率问题仍然无能为力,同时也产生了内存的外部碎片。为了解决分段机制存在的问题,更为合理的分页机制就应运而生,后面的章节我们会接着讨论。
6. 总结
分段机制解决了一些问题,帮助我们实现了更高效的虚拟内存。不只是动态重定位,通过避免地址空间的逻辑段之间的大量潜在的内存浪费,分段机制更好的支持了虚拟地址空间。分段机制有好














 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









