







背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 介绍
要想理解好Linux的页表映射,MMU的机制是需要去熟悉的,因此将这两个模块放到一起介绍。
关于ARMv8 MMU的相关内容,主要参考文档:《ARM Cortex-A Series Programmer’s Guide for ARMv8-A》。
2. ARMv8 MMU
2.1 MMU/TLB/Cache概述
MMU:完成的工作就是虚拟地址到物理地址的转换,可以让系统中的多个程序跑在自己独立的虚拟地址空间中,相互不会影响。程序可以对底层的物理内存一无所知,物理地址可以是不连续的,但是不妨碍映射连续的虚拟地址空间。TLB:MMU工作的过程就是查询页表的过程,页表放置在内存中时查询开销太大,因此专门有一小片访问更快的区域用于存放地址转换条目,用于提高查找效率。当页表内容有变化的时候,需要清除TLB,以防止地址映射出错。Cache:处理器和存储器之间的缓存机制,用于提高访问速率,在ARMv8上会存在多级Cache,其中L1 Cache分为指令Cache和数据Cache,在CPU Core的内部,支持虚拟地址寻址;L2 Cache容量更大,同时存储指令和数据,为多个CPU Core共用,这多个CPU Core也就组成了一个Cluster。
下图浅黄色部分描述的就是一个地址转换的过程。
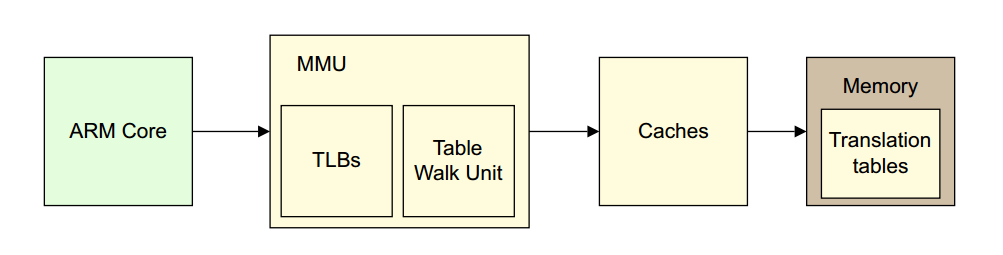
由于上图没有体现出L1和L2 Cache和MMU的关系,所以再来一张图吧:
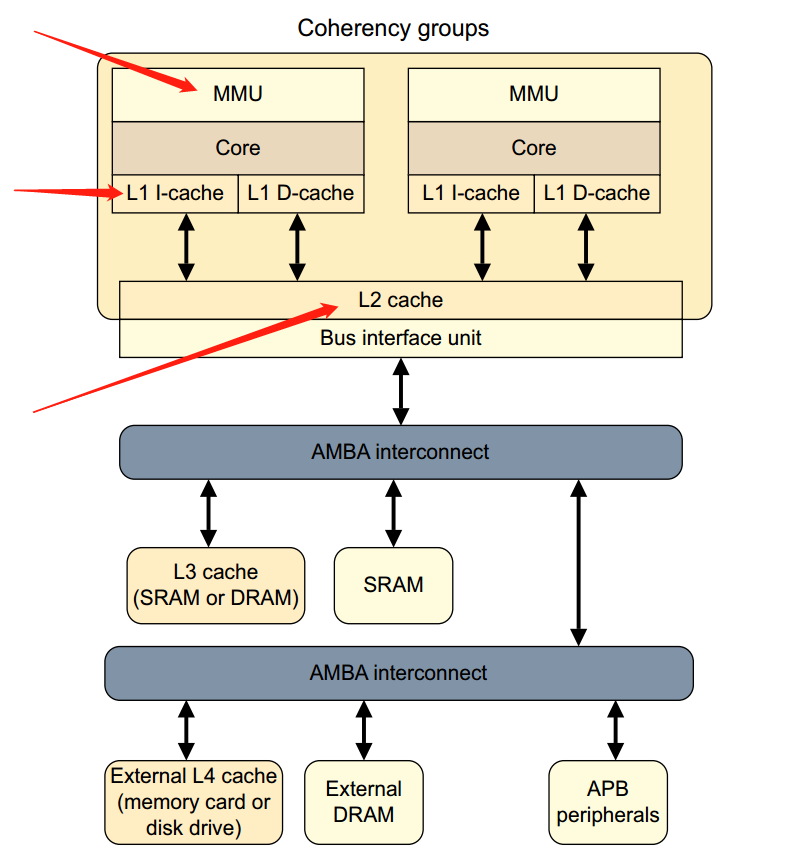
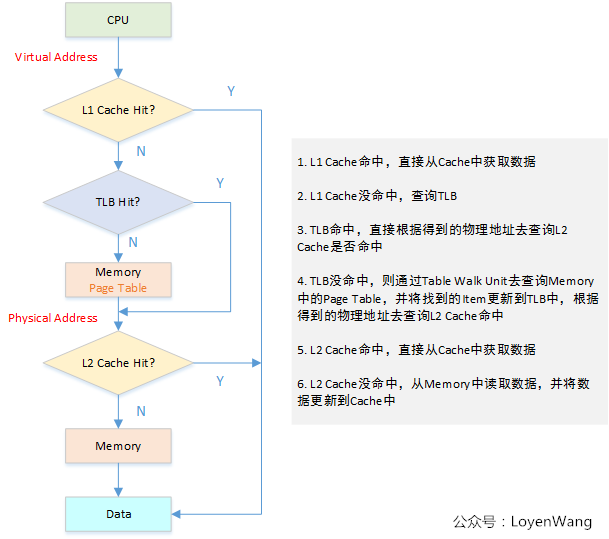
那具体是怎么访问的呢?再来一张图:
2.2 虚拟地址到物理地址的转换
虚拟地址到物理地址的映射通过查表的机制来实现,ARMv8中,Kernel Space的页表基地址存放在TTBR1_EL1寄存器中,User Space页表基地址存放在TTBR0_EL0寄存器中,其中内核地址空间的高位为全1,(0xFFFF0000_00000000 ~ 0xFFFFFFFF_FFFFFFFF),用户地址空间的高位为全0,(0x00000000_00000000 ~ 0x0000FFFF_FFFFFFFF)
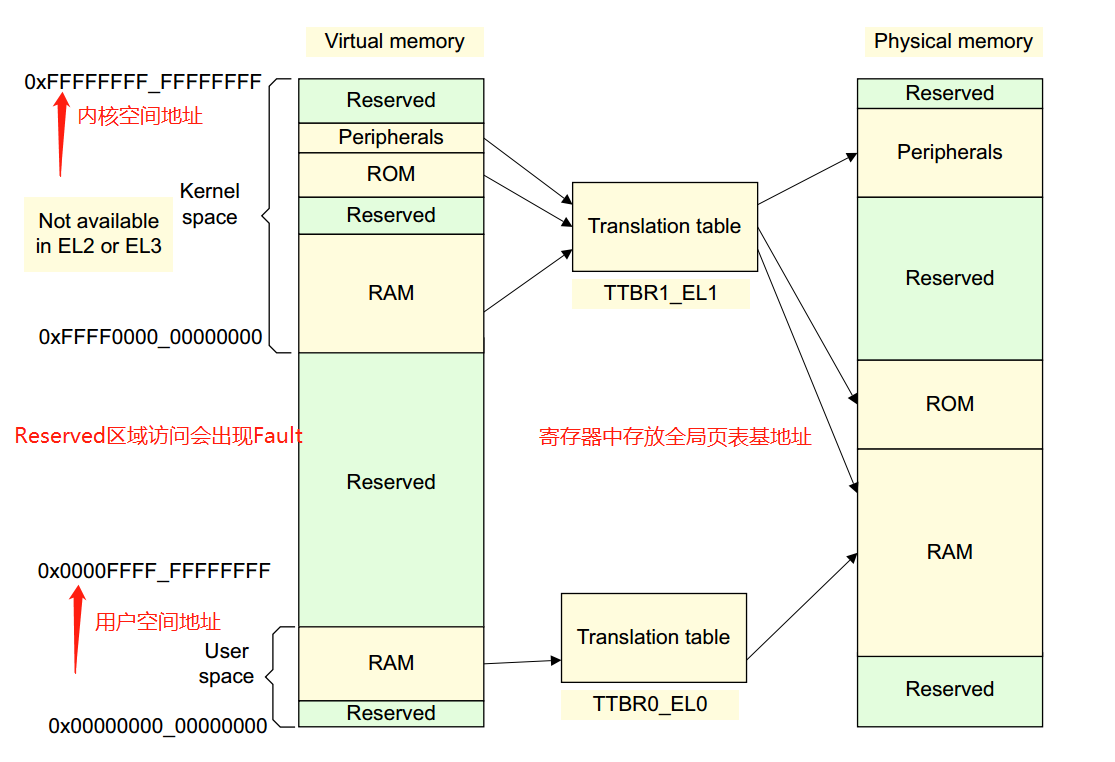
ARMv8中:
-
虚拟地址支持
64位虚拟地址中,并不是所有位都用上,除了高16位用于区分内核空间和用户空间外,有效位的配置可以是:36, 39, 42, 47。这可决定Linux内核中地址空间的大小。比如我使用的内核中有效位配置为CONFIG_ARM64_VA_BITS=39,用户空间地址范围:0x00000000_00000000 ~ 0x0000007f_ffffffff,大小为512G,内核空间地址范围:0xffffff80_00000000 ~ 0xffffffff_ffffffff,大小为512G。 -
页面大小支持
支持3种页面大小:4KB, 16KB, 64KB。 -
页表支持
支持至少两级页表,至多四级页表,Level 0 ~ Level 3。
结合有效虚拟地址位, 页面大小,页表的级数,可以组合成不同的页表映射方式。
我使用的内核配置为:39位有效位,4KB大小页面,3级页表,所以我会以这个组合来介绍。
在ARMv8的手册中刚好找到了下图,描述了整个translation的过程,简直完美:
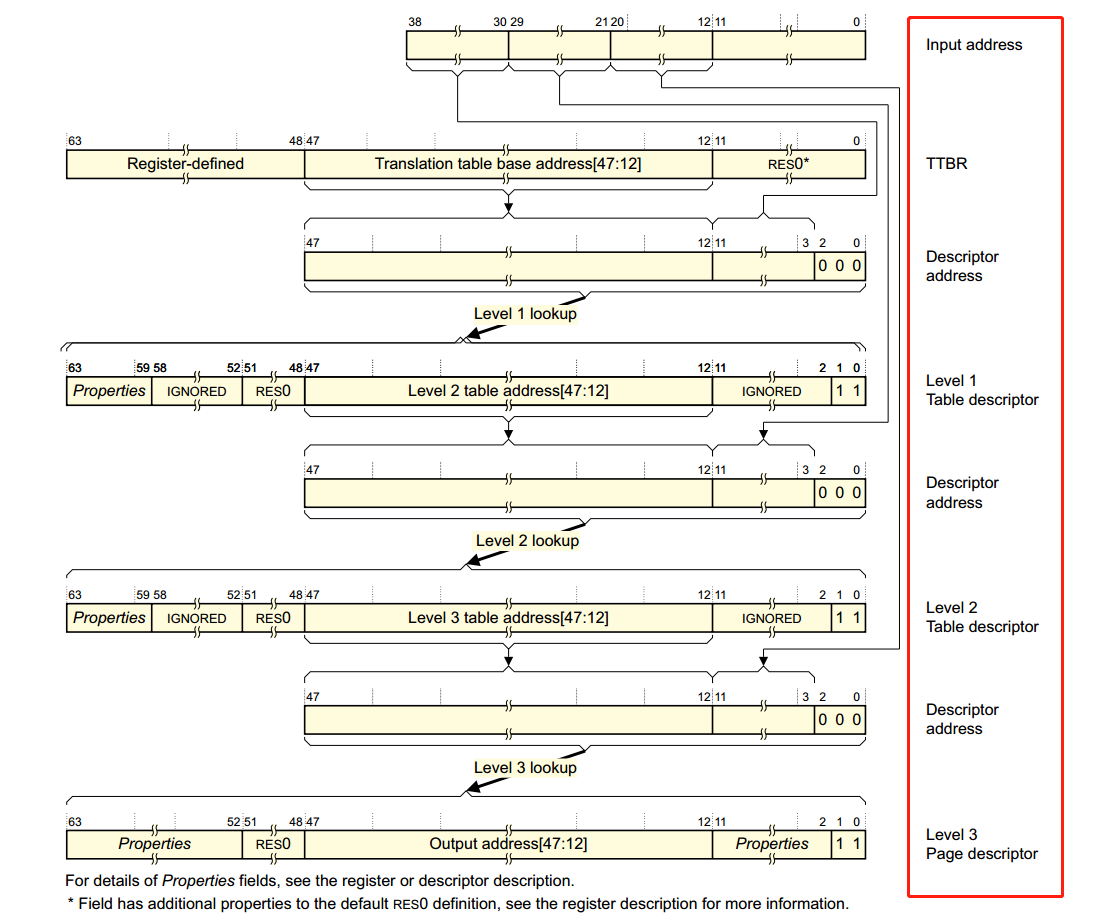
- 虚拟地址[63:39]用于区分内核空间与用户空间,从而选择不同的
TTBRn寄存器来获取Level 1页表基地址; - 虚拟地址[38:30]放置
Level 1页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取Level 2页表基地址; - 虚拟地址[29:21]
Level 2页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取Level 3页表基地址; - 虚拟地址[20:12]
Level 3页表中的索引,从而找到对应的描述符地址并获取描述符内容,根据描述符中的内容获取物理地址的高36位,以4K地址对齐; - 虚拟地址[11:0]放置的是物理地址的偏移,结合获取的物理地址高位,最终得到物理地址。
讲到这里还没有完,是时候看一下Table Descriptor了,也就是页表中存放的内容,有以下四种类型:
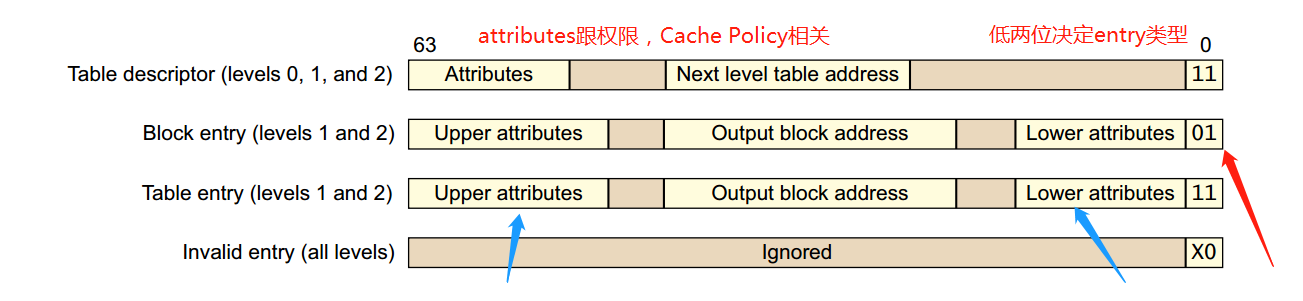
类型有低两位来决定,其中Level 0中的Table Descriptor只能输出Level 1页表的地址,Level 3中的Table Descriptor只能输出block addresses。
看到图中的attributes了吗,这些可以用于memory的权限控制,memory ordering,cache policy的操作等。
在ARMv8中,与页表相关的寄存器有:TCR_EL1, TTBRx_EL1.
3. Linux页表映射
3.1 Linux页表基本操作
看过《深入理解Linux内核》的同学应该很熟悉下边这张图片,Linux的分页模式(图中以X86为例,页表基地址由CR3寄存器指定):
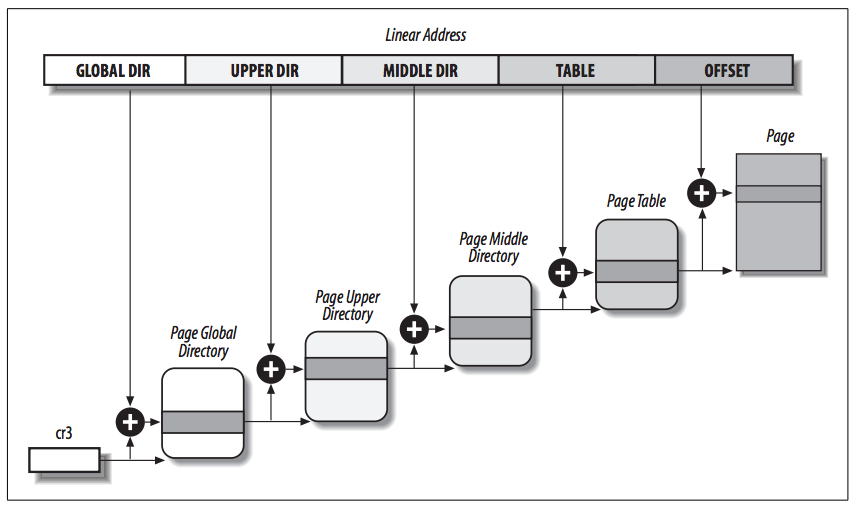
在Linux内核中支持4级页表的模型,同时适用于32位和64位系统。
那么ARMv8与Linux内核是怎么结合的呢?以我实际使用的设置(39位有效位,4KB大小页面,3级页表)为例,如下图所示:
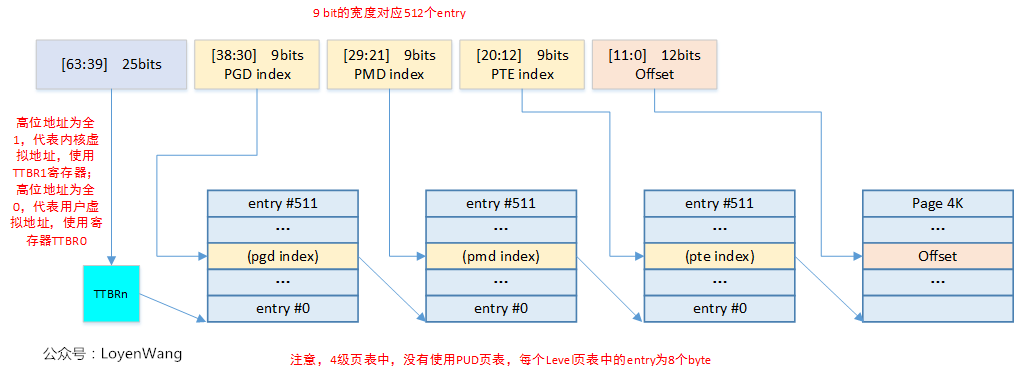
基本上内核中关于页表的操作都会围绕着上图进行操作,似乎脱离了代码有点不太合适,那么就来一波fucking source code解析吧,主要讲讲各类page table相关的API。
代码路径:
arch/arm64/include/asm/pgtable-types.h:定义pgd_t, pud_t, pmd_t, pte_t等类型;arch/arm64/include/asm/pgtable-prot.h:针对页表中entry中的权限内容设置;arch/arm64/include/asm/pgtable-hwdef.h:主要包括虚拟地址中PGD/PMD/PUD等的划分,这个与虚拟地址的有效位及分页大小有关,此外还包括硬件页表的定义, TCR寄存器中的设置等;arch/arm64/include/asm/pgtable.h:页表设置相关;
在这些代码中可以看到,
- 当
CONFIG_PGTABLE_LEVELS=4时:pgd-->pud-->pmd-->pte; - 当
CONFIG_PGTABLE_LEVELS=3时,没有PUD页表:pgd(pud)-->pmd-->pte; - 当
CONFIG_PGTABLE_LEVELS=2时,没有PUD和PMD页表:pgd(pud, pmd)-->pte
常用的宏定义
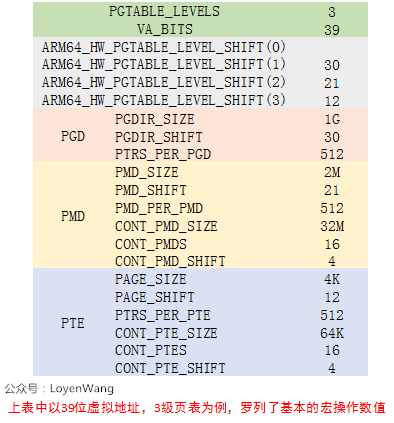
页表处理
/*描述各级页表中的页表项*/
typedef struct { pteval_t pte; } pte_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
/* 将页表项类型转换成无符号类型 */
#define pte_val(x) ((x).pte)
#define pmd_val(x) ((x).pmd)
#define pud_val(x) ((x).pud)
#define pgd_val(x) ((x).pgd)
/* 将无符号类型转换成页表项类型 */
#define __pte(x) ((pte_t) { (x) } )
#define __pmd(x) ((pmd_t) { (x) } )
#define __pud(x) ((pud_t) { (x) } )
#define __pgd(x) ((pgd_t) { (x) } )
/* 获取页表项的索引值 */
#define pgd_index(addr) (((addr) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1))
#define pud_index(addr) (((addr) >> PUD_SHIFT) & (PTRS_PER_PUD - 1))
#define pmd_index(addr) (((addr) >> PMD_SHIFT) & (PTRS_PER_PMD - 1))
#define pte_index(addr) (((addr) >> PAGE_SHIFT) & (PTRS_PER_PTE - 1))
/* 获取页表中entry的偏移值 */
#define pgd_offset(mm, addr) (pgd_offset_raw((mm)->pgd, (addr)))
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
#define pud_offset_phys(dir, addr) (pgd_page_paddr(*(dir)) + pud_index(addr) * sizeof(pud_t))
#define pud_offset(dir, addr) ((pud_t *)__va(pud_offset_phys((dir), (addr))))
#define pmd_offset_phys(dir, addr) (pud_page_paddr(*(dir)) + pmd_index(addr) * sizeof(pmd_t))
#define pmd_offset(dir, addr) ((pmd_t *)__va(pmd_offset_phys((dir), (addr))))
#define pte_offset_phys(dir,addr) (pmd_page_paddr(READ_ONCE(*(dir))) + pte_index(addr) * sizeof(pte_t))
#define pte_offset_kernel(dir,addr) ((pte_t *)__va(pte_offset_phys((dir), (addr))))
3.2 head.S中的页表映射
3.2.1 idmap_pg_dir和swapper_pg_dir临时页表
是时候来个实例分析了,看看页表的创建过程,代码路径:arch/arm64/kernel/head.S。
内核启动过程中,在真正的物理内存尚未添加进系统,以及页表还未初始化之前,为了保证系统能正常运行,需要建立两个临时全局页表:idmap_pg_dir和swapper_pg_dir:
其中两个全局页表的定义在arch/arm64/kernel/vmlinux.lds.S中,放置在BSS段之后:
. = ALIGN(PAGE_SIZE);
idmap_pg_dir = .;
. += IDMAP_DIR_SIZE;
swapper_pg_dir = .;
. += SWAPPER_DIR_SIZE;
/* 定义了连续的几个页,分别存放PGD,PMD,PTE等,连续在一起,这个也是head.S中填充的 */
#define SWAPPER_DIR_SIZE (SWAPPER_PGTABLE_LEVELS * PAGE_SIZE)
#define IDMAP_DIR_SIZE (IDMAP_PGTABLE_LEVELS * PAGE_SIZE)
-
idmap_pg_dir
从名字可以看出,identify map,也就是物理地址和虚拟地址是相等的。为什么需要这么一个映射呢?我们都知道在MMU打开之前,CPU访问的都是物理地址,那么当MMU打开后访问的就是虚拟地址了,这段页表的映射就是从CPU到打开MMU之前的这段代码物理地址的映射,防止开启MMU后,无法获取页表。可以从System.map文件中查看这些代码: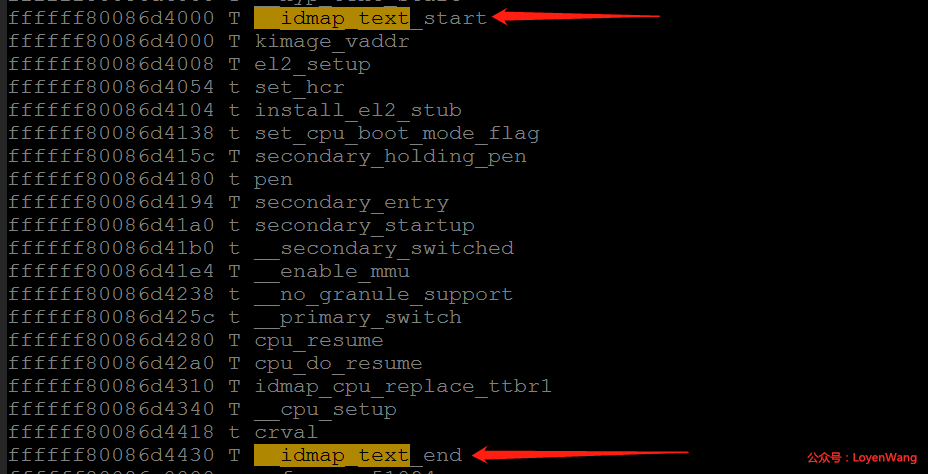
-
swapper_pg_dir
Linux内核编译后,kernel image是需要进行映射的,包括text,data等各种段。
3.2.2 页表创建
在head.S中,创建页表相关的有三个宏:
create_pgd_entry
/*
* Macro to populate the PGD (and possibily PUD) for the corresponding
* block entry in the next level (tbl) for the given virtual address.
*
* Preserves: tbl, next, virt
* Corrupts: tmp1, tmp2
*/
.macro create_pgd_entry, tbl, virt, tmp1, tmp2
create_table_entry \tbl, \virt, PGDIR_SHIFT, PTRS_PER_PGD, \tmp1, \tmp2
#if SWAPPER_PGTABLE_LEVELS > 3
create_table_entry \tbl, \virt, PUD_SHIFT, PTRS_PER_PUD, \tmp1, \tmp2
#endif
#if SWAPPER_PGTABLE_LEVELS > 2
create_table_entry \tbl, \virt, SWAPPER_TABLE_SHIFT, PTRS_PER_PTE, \tmp1, \tmp2
#endif
.endm
上述函数主要是调用create_table_entry,由于SWAPPER_PGTABLES配置为3,因此相当于创建了pgd和pmd两级页表,此处需要注意一点,create_table_entry函数执行后,tbl参数会自动加上PAGE_SIZE,也就是说pgd和pmd两级页表是物理连续的。
create_block_map
/*
* Macro to populate block entries in the page table for the start..end
* virtual range (inclusive).
*
* Preserves: tbl, flags
* Corrupts: phys, start, end, pstate
*/
.macro create_block_map, tbl, flags, phys, start, end
lsr \phys, \phys, #SWAPPER_BLOCK_SHIFT
lsr \start, \start, #SWAPPER_BLOCK_SHIFT
and \start, \start, #PTRS_PER_PTE - 1 // table index
orr \phys, \flags, \phys, lsl #SWAPPER_BLOCK_SHIFT // table entry
lsr \end, \end, #SWAPPER_BLOCK_SHIFT
and \end, \end, #PTRS_PER_PTE - 1 // table end index
9999: str \phys, [\tbl, \start, lsl #3] // store the entry
add \start, \start, #1 // next entry
add \phys, \phys, #SWAPPER_BLOCK_SIZE // next block
cmp \start, \end
b.ls 9999b
.endm
上述函数主要是往block中填充pte entry,真正创建虚拟地址到物理地址的映射,映射区域:start ~ end。
create_table_entry
/*
* Macro to create a table entry to the next page.
*
* tbl: page table address
* virt: virtual address
* shift: #imm page table shift
* ptrs: #imm pointers per table page
*
* Preserves: virt
* Corrupts: tmp1, tmp2
* Returns: tbl -> next level table page address
*/
.macro create_table_entry, tbl, virt, shift, ptrs, tmp1, tmp2
lsr \tmp1, \virt, #\shift
and \tmp1, \tmp1, #\ptrs - 1 // table index
add \tmp2, \tbl, #PAGE_SIZE
orr \tmp2, \tmp2, #PMD_TYPE_TABLE // address of next table and entry type
str \tmp2, [\tbl, \tmp1, lsl #3]
add \tbl, \tbl, #PAGE_SIZE // next level table page
.endm
上述函数创建页表项,并且返回下一个Level的页表地址。
上述三个孤立的函数并不直观,所以,图来了:
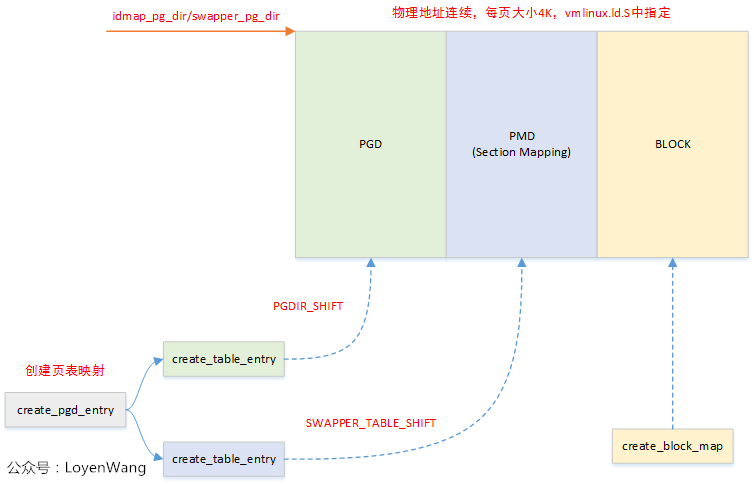
总体来说,页表的创建过程相对来说还是比较易懂的,掌握好几级页表及各级页表index所占的位域,此外熟悉各个Level页表中entry的格式,理解起来就会顺畅很多了。
一抠细节深似海,点到为止,防止一叶障目不见泰山,收工!
硬件分段分页管理机制
分段
分段机制引入与原因
1. 分段机制概述
对于分段机制,要从Intel的微处理器的8086开始说起,刚开始内存空间比较小,内存寻址采用的是直接访问物理地址的方式。由于技术的发展,计算机做的事情越来越多,程序也越来越大,为了更大的内存空间,把地址总线扩展到20位。但是,对于内存设计,一个很尴尬的问题产生了,之前的设计CPU的ALU宽度只有16位,也就是说,ALU不能访问20位的地址空间,那时就设计了段机制来处理这种情况。为了坚持这种兼容性,386依然运用段机制,直至现在的64位处理器已经看不到段机制的身影。
1.1 分段机制产生的原因
为了保持兼容,分段机制的被引入,我们来实际的理解分段机制解决了什么实质性的问题呢?在分段机制还没有出现的时候,程序运行是需要从内存分配出足够多的连续内存,然后整个程序装载进去。例如:
某个程序大小是100M,然后我们就需要有连续的100M内存空间才能把这个程序装载到内存里面。如果无法找到连续的100M内存空间,就无法把这个程序装载进内存空间,程序就无法得到运行。
假设我们的内存可以提供连续的区域来使得程序运行,那么我们来看一下还会存在有什么问题呢?
地址空间不隔离(安全性):如何有两个程序运行A和B,程序A在内存的地址假设为0x0->0x100,而程序B在内存中的地址假设为0x100->0x199。那么假设程序员A本来想存在属于A的地址0x50,而不小心访问到属于B的地址0x150,那么不好的事情就将发生了,A和B程序都异常了。对于程序员B来说,是飞来横祸,同时也很难定位到问题,这种情况会导致程序能访问所有的内存空间,恶意修改数据可能超成安全问题。
程序运行时地址不确定(动态链接):程序每次要运行的时候,都是需要装载到内存中的,假设你在程序中写死了要操作某个地址的内存,例如你要地址0x150。但是问题来了,你能够保证你操作的地址0x150真的就是你原来想操作的那个位置吗?很可能程序第一次装载进内存的位置是0x100->0x199,而程序第二次运行的时候,这个程序装载进内存的位置变成了0x0->0x100,而你操作的0x150地址压根就不是属于这个程序所占有的内存。
内存使用率低下(内存共享):假设我们写了3个程序其中程序A大小为10M,程序B为70M,程序C的大小为30M你的计算机的内存总共有100M。这三个程序加起来有110M,显然这三个程序是无法同时存在于内存中的。并且最多只能够同时运行两个程序。可能是这样的,程序A占有的内存空间是0x00000000~0x00000009,程序B占有的内存空间是0x00000010~0x00000079。假设这个时候程序C要运行该怎么做?可以把其中的一个程序换出到磁盘上,然后再把程序C装载到内存中。假设是把程序A换出,那么程序C还是无法装载进内存中,因为内存中空闲的连续区域有两块,一块是原来程序A占有的那10M,还有就是从0x00000080~0x00000099这20M,所以,30M的程序C无法装载进内存中。那么,唯一的办法就是把程序B换出,保留程序A,但是,此时会有60M的内存无法利用起来。
为了解决这一些问题,分段的概念应运而生。在计算机科学领域,任何的问题都可以通过增加一个间接的中间层来解决问题,那么为了实现分段的这个技术,就需要引入虚拟地址空间的概念。
我们来了解下,虚拟地址空间和物理地址空间的概念,简单的说来,对于可以寻址的一片空间,如果这个空间是虚拟的,我们就叫做虚拟的地址空间;如果这个空间是真实存在的,我们就叫做物理地址空间。虚拟地址空间是虚拟的,所有就决定了他可以是任意的大,而物理地址空间必须是真实存在的,是由实际的硬件决定的。
1.2 硬件分段机制
分段是一种隔离不同的代码、数据、栈模块的机制,能够保证不同进程或任务不会互相干扰。我们可以为一个进程分配属于它的段集合,CPU 的硬件机制会保证其代码不会越权访问段,也不会访问到段外的地址。
分段机制就是把虚拟地址空间中的虚拟内存组织成一些长度可变的的段的内存单元,80386虚拟地址空间中的逻辑地址由一个段部分和一个段内偏移部分构成,段是虚拟地址空间到线性地址转换的基础。每个段都有3个参数定义
段基地址:指定段在线性地址空间中的开始地址,基地址是线性地址对应于段中偏移0处
段限长:是虚拟地址空间中段内最大可用偏移地址,定义了段的长度
段属性:指定段的特性,如该段是否可读,可写或可执行,段的特权级等

当需要访问处理器地址空间的某个字节时,段选择符指定了该字节所在的段,偏移量制定了该字节在段中相对于段基址的位置,处理器把逻辑地址转化成一个线性地址的过程如下:
1.使用段选择符中的偏移值(在GDT(全局描述符表) 或 LDT(局部描述符表)中定位相应的段描述符
2.利用段描述符校验段的访问权限和范围,以确保该段是可以访问的并且偏移量位于段界限内
3.利用段描述符中取得的段基地址加上偏移量,形成一个线性地址

1.2.1 段选择符
段选择符(或称段选择子)是段的一个十六位标志符,如下图所示。段选择符并不直接指向段,而是指向段描述符表中定义段的段描述符。

段选择符包括 3 个字段的内容:
请求特权级RPL([0:1])
表指引标志TI([2])TI = 0 ,表示描述符在GDT中,TI = 1,表示描述符在LDT中
索引值,给出了描述符在GDT或LDT表中的索引项号
下面是一些段选择符的示例:

1.2.2 段描述符
段描述符表是段描述符的一个数组,如下图所示。描述符表的长度可变,最多可以包含8192个 8 byte 描述符。有两个描述符表: 全局描述符表GDT (Global descriptor table); 局部描述符表 LDT (Local descriptor table),由段选择符的bit[2]会选择到对应的GDT表还是LDT表去拿到对应的段基址。

而对于段描述符,每个段描述符长度是 8 字节,含有三个主要字段:段基地址、段限长和段属性。段描述符通常由编译器。链接器、加载器或者操作系统来创建,绝不可能由应用程序来创建。
段描述符通用格式如下:

了解了这个过程,我们来总体的梳理下,如果使用分段机制,那么怎么使虚拟地址空间转到对应的物理地址空间呢?转换过程如下图所示

1.取出虚拟地址空间中的段选择符,根据TI位判断段描述符是存储在GDT还是LDT中
2.段选择符中的index*8,也就是左移3位,就是段描述符在GDT中的位置,在加上GDT的基地址,就是段描述符的地址,从而去除段描述符
3.段描述符中保存了该段的基地址,加上虚拟地址中的偏移量就是对应到的物理地址空间。
2. Linux中分段的实现原理
上一节讨论了80x86如何从硬件上提供分段机制的支持,而本节讨论下linux如何使用分段机制。最开始的时候,操作系统不支持分段,内存的换入换出都是以整个进程的内存空间为单位,导致系统非常的耗时,同时利用率也不高,当内存不足,很容易导致内存交换失败。后来有了分段技术,把内存空间分成多个模块:代码段、数据段,或者是一个大的数据块,段成了内存交换的单位,在一定程度上增加了内存利用率。那时候还没有分页技术,虚拟地址(线性地址)是直接映射到物理空间的。
引入分页机制后,目前linux很少使用分段,分段和分页在某些方面是冗余的,因为他们都可以把物理地址空间分割成不同部分:分段给每个进程分配不同的逻辑地址空间,而分页可以把相同的逻辑地址空间映射到不同的物理地址上。因此,Linux优先采用了分页(分页操作系统),基于以下原因:
内存管理更简单:所有进程使用相同段寄存器值,也就是相同的线性地址集
出于兼容大部分硬件架构的考虑,RISC架构对分段支持的不是很好
所以自从x86-64起,除了在“传统模式”下,分段机制已被认为是过时的且不再被支持。虽然在x86-64的本机模式下仍然有分段机制的某些痕迹,但大多只是为了兼容,且它们不再具起到同样的作用,也不再提供真正的分段。
那么linux内核是怎么支持分段机制呢?我们来看上节的分段机制的原理图如下

比如,我们将虚拟地址空间分成4个段,用0-3来编号,每个段在段表中有一个项,在物理空间中,段的排列如下图所示

如果要访问段2中偏移量为600的虚拟地址,我们可以计算出物理地址为段基地址+偏量=2000+600=2600
3. Linux分段机制的软件实现
Linux对段机制的应用效果是等价于几乎绕过了段基址。在Linux中仅有4个段,用户代码段、数据段和内核代码段、数据段。
Segment Base G Limit Type DPL S D/B P
user code 0x00000000 1 0xfffff 10 3 1 1 1
user data 0x00000000 1 0xfffff 2 3 1 1 1
kernel code 0x00000000 1 0xfffff 10 0 1 1 1
kernel data 0x00000000 1 0xfffff 2 0 1 1 1
这些段相应的选择器分别由以下宏定义:_USER_CS, __USER_DS, __KERNEL_CS, 和__KERNEL_DS。举例来说,如果要定位内核代码段,内核只需要加载__KERNEK_CS宏的值到cs寄存器中。 接下来我们看一下linux代码吧,进入保护模式的函数go_to_protected_mode:
void go_to_protected_mode(void)
{
/* Hook before leaving real mode, also disables interrupts */
realmode_switch_hook();
/* Enable the A20 gate */
if (enable_a20()) {
puts("A20 gate not responding, unable to boot...\n");
die();
}
/* Reset coprocessor (IGNNE#) */
reset_coprocessor();
/* Mask all interrupts in the PIC */
mask_all_interrupts();
/* Actual transition to protected mode... */
setup_idt();
setup_gdt();
protected_mode_jump(boot_params.hdr.code32_start,
(u32)&boot_params + (ds() << 4));
}里面的函数略带一下吧,realmode_switch_hook()根据注释和函数命名可以知道这是在实模式切换前的钩子函数调用的地方;enable_a20()这个太熟悉了,就开启A20;reset_coprocessor()是把协处理器重置一下mask_all_interrupts()则是把中断关了,避免切换过程中出现状况。其中setup_idt()和setup_gdt()是本节的重点,函数名字告诉我们这是设置idt和gdt的,看一下两者具体代码吧:
static void setup_idt(void)
{
static const struct gdt_ptr null_idt = {0, 0};
asm volatile("lidtl %0" : : "m" (null_idt));
}
根据setup_idt()的实现,可以明显看到这没做什么,纯粹置一下idt为空的描述符表。
static void setup_gdt(void)
{
/* There are machines which are known to not boot with the GDT
being 8-byte unaligned. Intel recommends 16 byte alignment. */
static const u64 boot_gdt[] __attribute__((aligned(16))) = {
/* CS: code, read/execute, 4 GB, base 0 */
[GDT_ENTRY_BOOT_CS] = GDT_ENTRY(0xc09b, 0, 0xfffff),
/* DS: data, read/write, 4 GB, base 0 */
[GDT_ENTRY_BOOT_DS] = GDT_ENTRY(0xc093, 0, 0xfffff),
/* TSS: 32-bit tss, 104 bytes, base 4096 */
/* We only have a TSS here to keep Intel VT happy;
we don't actually use it for anything. */
[GDT_ENTRY_BOOT_TSS] = GDT_ENTRY(0x0089, 4096, 103),
};
/* Xen HVM incorrectly stores a pointer to the gdt_ptr, instead
of the gdt_ptr contents. Thus, make it static so it will
stay in memory, at least long enough that we switch to the
proper kernel GDT. */
static struct gdt_ptr gdt;
gdt.len = sizeof(boot_gdt)-1;
gdt.ptr = (u32)&boot_gdt + (ds() << 4);
asm volatile("lgdtl %0" : : "m" (gdt));
}
首先,我们看看之前的GDT entry的结构图如下:
GDT_ENTRY的定义如下:
/* Constructor for a conventional segment GDT (or LDT) entry */
/* This is a macro so it can be used in initializers */
#define GDT_ENTRY(flags, base, limit) \
((((base) & 0xff000000ULL) << (56-24)) | \
(((flags) & 0x0000f0ffULL) << 40) | \
(((limit) & 0x000f0000ULL) << (48-16)) | \
(((base) & 0x00ffffffULL) << 16) | \
(((limit) & 0x0000ffffULL)))可以清楚得看到,base, limit和flag通过位移和或组成了GDT_ENTRY。其中flags代表了40-47位的access byte和52-55位的flags。
CS和DS的flags为0xc0,所以G=1,意味着4K为一个页面,B/D为1,1-32位段;
CS的Access Byte=0x9b,意味着P=1(合法的Entry Pr必须为1),DPL=0,S=1,这里该段只能在Ring 0下访问,该段是代码段
DS的Access Byte=0x93,意味着P=1(合法的Entry Pr必须为1),DPL=0,S=1,这里该段只能在Ring 0下访问,该段是数据段
linux中逻辑地址等于线性地址。为什么这么说呢?因为Linux所有的段(用户代码段、用户数据段、内核代码段、内核数据段)的线性地址都是从 0x00000000 开始,长度4G,这样 线性地址=逻辑地址+ 0x00000000,也就是说逻辑地址等于线性地址了。通过分析,我们发现,所有的段的起始地址都是一样的,都是 0。这算哪门子分段嘛!所以,在 Linux 操作系统中,并没有使用到全部的分段功能。那分段是不是完全没有用处呢?分段可以做权限审核,例如用户态 DPL 是 3,内核态 DPL 是 0。当用户态试图访问内核态的时候,会因为权限不足而报错。

还是以 mov 0x80495b0, %eax 中的地址为例分析一下转换过程:
1.首先段选择符中的TI为0,表明段描述符在GDT表中,使用段选择符中的偏移值定位到相应的段描述符,找到15这个位置
2.从15号位置的段描述符,找到对应的访问权限,访问基地址(0)和访问范围(0xffff)
3.利用段描述符中去得到的段基址0x0000000,加上逻辑地址偏移0x80495b0,形成线性地址0x80495b0。
所以Linux没有采用严格的分段机制,已经慢慢的弱化分段机制,而使用分页机制来替换分段机制。
4. 分段机制的优缺点
现在大致了解了分段的基本原理,系统运行时,地址空间中不同段被重定位到物理内存中,与之前的整个物理地址空间中只有一个基地址+偏移量的方式相比,大量的节省了物理内存。同时分段管理就是将一个程序按照逻辑单元分成多个程序段,每一个段使用自己单独的虚拟地址空间。例如,对于编译器来说,我们可以给其5个段,占用5个虚拟地址空间,如下图所示

如此,一个段占用一个虚拟地址空间,不会发生空间增长时碰撞到另一个段的问题,从而避免因空间不够而造成编译失败的情况。如果某个数据结构对空间的需求超过整个虚拟之地所能够提供的空间,则编译仍将失败,开编提到的问题1好像得到了完美解决。
正是因为这种映射,使得程序无需关注物理地址是多少,只要虚拟地址没有改变,那么程序就不会操作地址不当,问题2也好像可以很好的解决。
但是问题3,是换入换出的问题,这个问题的关键是能不能在换出一个完整程序之后,把另外一个程序换进来,而这种分段机制,就存在一个很严重的问题。
物理内存很快就会被许多空间空间的小块,因为很难分配给新的段,或扩大已有的段,这种问题被成为外部碎片

分段机制采用的是分段,这就导致一个问题,已分配的段有大有小,未使用的段也有大有小,将要分配的段也有大有小,各方需求不一定,理想的情况,但系统中的程序比较少,内存没有完全使用的情况下会如紧凑型分配。但是在程序运行过程中,有些程序运行完后,要释放新已分配的内存空间,当使用一段时间后,可能会出现非紧凑的情况,在这个例子中,一个进程需要分配一个20K的段,当前有24K的空闲,却不连续,因此操作系统无法满足这20K的请求。这也就是外部碎片,其特征如下:
外部碎片是指还没有被分配出去(不属于任何进程),但是由于太小了,无法分配给申请内存空间的新进程的内存空闲区域。
虽然这些存储块的总和可以满足当前申请的长度的要求,但是由于他们的地址不连续或者其他原因,使得系统无法满足当前的申请。
5. 分段机制的改进之路
紧凑物理内存,重新安排原有的段,例如,操作系统先终止运行的进程,将他们的数据复制到连续的内存区域中去,改变他们的段寄存器中的值,指向新的物理地址,从而得到足够大的连续空闲空间。这样做,大大提高了成本,系统开销也很大,会占用大量的处理器时间。
软件优化的算法,一种更简单的做法是利用空闲列表管理算法,保留打的内存块用于分配,相关的算法很多,例如传统的最优匹配(从空闲链表中找到最接近需要分配空间的空闲块返回)、最坏匹配、首次匹配以及伙伴算法等。但是遗憾的是,无论算法多么精妙,都无法完全的消除外部碎片。
无论如何分段机制解决了上面两个问题,是一个很大的进步,但是对于内存效率问题仍然无能为力,同时也产生了内存的外部碎片。为了解决分段机制存在的问题,更为合理的分页机制就应运而生,后面的章节我们会接着讨论。
6. 总结
分段机制解决了一些问题,帮助我们实现了更高效的虚拟内存。不只是动态重定位,通过避免地址空间的逻辑段之间的大量潜在的内存浪费,分段机制更好的支持了虚拟地址空间。分段机制有好
分页
上一章学习了操作系统的分段机制,将程序分成不同的段进行管理,我们编程访问内存地址时,访问的其实是操作系统抽象给我们的虚拟地址,通过段基址:段偏移的方式访问内存虚拟地址,极大了简化了程序员的编程结构,解决了之前操作系统存在的两个问题:
地址空间没有隔离
程序运行的地址不确定
但是分段机制也存在严重的问题,在分段的映射方法中,并没有解决内存使用效率的问题。如果应用程序过多,或者内存碎片过多,又或者曾经被换出到硬盘的内存段需要再重新装载到内存,可内存中找不到合适大小的区域,要如何解决这个问题,就引入了分页机制。
1. 分页实现原理
分页的基本方法是将地址空间等分成某一个固定大小的页;每一页大小由硬件来决定,或者是由操作系统来决定(如果硬件支持多种大小的页)。
1.将进程的逻辑地址空间分成若干个大小相等的片,称为页面或页
2.内存空间分成与页大小相等的若干个存储块,称为物理块或页框
3.在为进程分配内存时,以块为单位,将进程中的若干页分别装入多个可以不相邻的块中
关于进程分页,当我们把进程的虚拟地址空间按页来分割,常用的数据和代码会被装在到内存;暂时没用到的是数据和代码则保存在磁盘中,需要用到的时候,再从磁盘中加载到内存中即可.
1.1 硬件分页机制
对于最简单的分页机制,硬件上使用一级页表的方式是最简单的,访问效率也最高,页面的大小一般为 4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址,就能对于内存中的每个位置进行访问了,其访问流程图如下:

虚拟地址分为两部分,页号§和页内偏移(o)。页号(用高 20 位表示)作为页表的索引,页表包含物理页每页所在物理内存的基地址。这个基地址与页内偏移(低 12 位)的组合就形成了物理内存地址。一级页表这么简单,只要经过一次的地址转换就能找到对应的物理地址,访问效率应该是最好的。
我们假设在32位环境下,虚拟的地址空间为4GB,如果采用一级页表,采用4KB为一个页,那就需要1M个页表。每一个页表需要4个字节来存储,那么整个4GB的地址空间的映射就需要4MB的内存来存储映射表。如果每个进程都有自己的映射表,100个进程就需要400MB的内存,对于内核来说,确实有点大。
这个问题在64位体系结构下, 情况会更加糟糕. 而每个进程都需要自身的页表, 这导致系统中大量的所有内存都用来保存页表。
1.2 多级页表
对于页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。为减少页表的大小并容许忽略不需要的区域, 计算机体系结构的就使用了多级页表,下面以二级页表,看硬件上怎么实现的。

第一级表称为页目录,存放在一页 4K 大小的页面中,具有 2^10 个 4 字节长度的表项。 这些表象指向对应的二级表。 线性地址的最高 10 位(31-22)用作以及表中的索引。
第二级称为页表,长度也是 4K 大小的一个页面,最多有 1K 个 4 字节的表项。 每个 4 字节的表项含有相关页面的 20 位物理基地址。 二级页表使用线性地址的中间 10 位(21-12)作为表项索引值,以获取含有页面 20 物理地址基地址的表项。 该20位页面物理基地址和线性地址中的低12位(页内偏移)组合在一起就得到了分页转换过程的输出值,即对应的的最终物理地址。
对于给定的线性地址,CR3 寄存器指定页目录表的基地址。线性地址的高10位用于索引这个页目录表,以获得指向相关第二级页表的指针。线性地址空间中间10位用于索引二级页表,以获得物理地址的高20位。线性地址的低12位直接作为物理地址的低12位,从而组成一个完整的32位物理地址。
那么二级页表怎么解决页表过大的问题呢?我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的 1M 个页表项共 4M 的内存,但是如果使用了页目录,页目录需要 1K 个全部分配,占用内存 4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多 4K,这样内存就节省多了。
页目录和页表的表项格式如下图所示,其中位32-12含有物理地址的高20位,用于定位物理地址空间中一个页面(也叫页帧)的物理基地址。表项的低 12 位含有页属性信息。


上图就是页目录项和页表项的格式。可以看出,由于页表或者页的物理地址都是4KB对齐的(低12位全是零),所以上图中只保留了物理基地址的高20位(bit[31:12])。低12位可以安排其他用途。
【P】存在位,表示该页是在内存还是在磁盘。为1表示页表或者页位于内存中。否则,表示不在内存中,必须先予以创建或者从磁盘调入内存后方可使用。
【R/W】:读写标志。为1表示页面可以被读写,为0表示只读。当处理器运行在0、1、2特权级时,此位不起作用。页目录中的这个位对其所映射的所有页面起作用。
【PWT】:缓冲写策略。Page级的Write-Through标志位。为1时使用Write-Through的Cache类型;为0时使用Write-Back的Cache类型。当CR0.CD=1时(Cache被Disable掉),此标志被忽略。对于我们的实验,此位清零。
【PCD】:禁止缓存位。Page级的Cache Disable标志位。为1时,物理页面是不能被Cache的;为0时允许Cache。当CR0.CD=1时,此标志被忽略。对于我们的实验,此位清零。
【D】:修改位。该位由处理器固件设置,用来指示此表项所指向的页是否写过数据。
【A】:访问位。该位由处理器固件设置,用来指示此表项所指向的页是否已被访问(读或写),一旦置位,处理器从不清这个标志位。这个位可以被操作系统用来监视页的使用频率。
正常来说, 对于32位的系统两级页表已经足够了, 但是对于64位系统的计算机, 这远远不够.
首先假设一个大小为4KB的标准页, 所以offset字段需要12位.这样线性地址空间就剩下64-12=52位分配给页中间表Table和页目录表Directory。如果我们现在决定仅仅使用64位中的48位来寻址(这个限制其实已经足够了, 2^48=256TB,即可达到256TB的寻址空间)。剩下的48-12=36位被分配给Table和Directory字段, 即使我们现在决定位两个字段各预留18位,那么每个进程的页目录和页表都包含218个项, 即超过256000个项.
基于这个原因, 所有64位处理器的硬件分页系统都使用了额外的分页级别. 使用的级别取决于处理器的类型
2.小结
操作系统引入分页的概念,作为虚拟内存挑战的解决方案。与以前的方法(如分段),分页有很多的优点
分页机制解决了分段机制的效率问题,因为分页将内存划分为固定大小的单元,它不会产生外部碎片
非常灵活,支持稀疏虚拟地址空间
但是虽然分页机制也有它的局限性,例如它会产生内碎片,内碎片的大小由分页机制的最小物理内存决定的,比如来说,我们每个进程都只需要几个字节,那么对于现在的分页机制也是按照一个页大小来分配,但是相对于分段机制的浪费也小了很多。
对于多级页表虽然解决了内存浪费的问题,但是页表存放在主存中,因此程序每次訪存至少须要两次:一次访问获取物理地址,第二次访问才获得数据。内存访问的速度就减半。在大多数情况下,这种延迟是无法忍受的。操作系统不得不努力设计出一个更好的分页机制,它不仅可以工作,而且工作的更好,对于这种情况,硬件又基于页表的访问局限性设计了TLB来解决这个问题,下一章会针对这个问题进行讨论。
MMU机理
ARM MMU页表框架
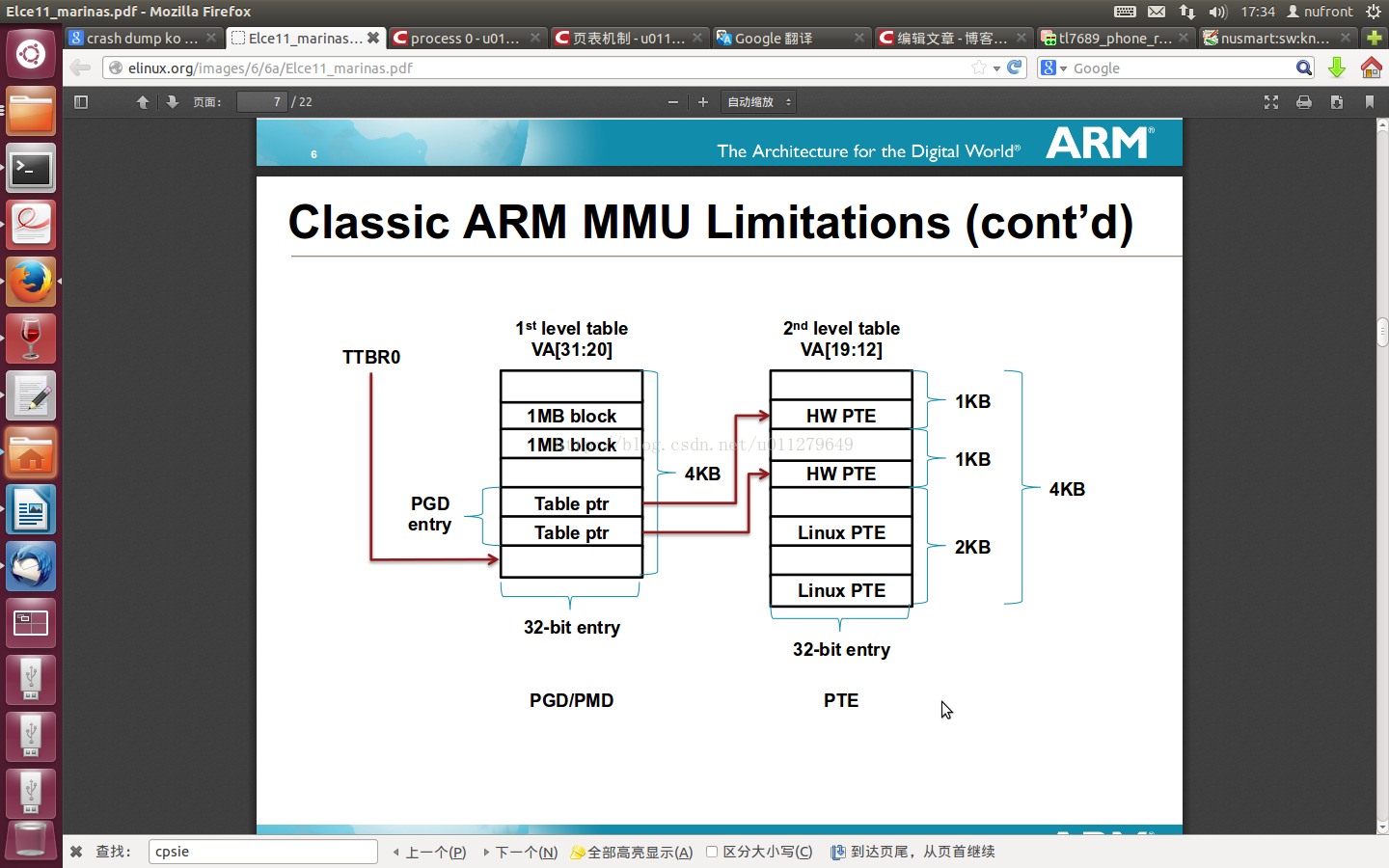
先上一张arm mmu的页表结构的通用框图(以下的论述都由该图来逐渐展开):

以上是arm的页表框图的典型结构:即是二级页表结构:
其中第一级页表(L1)是由虚拟地址的高12bit(bits[31:20])组成,所以第一级页表有4096个item,每个item占4个字节,所以一级页表的大小为16KB,而在第一级页表中的每个entry的最低2bit可以用来区分具体是什么种类的页表项,2bit可以区分4种页表项,具体每种页表项的结构如下:
简而言之L1页表的页表项主要有两大类:

第一大类是指向第二级页表(L2页表)的基地址;
第二类直接指向1MB的物理内存。
在L1页表中每个表项可以覆盖1MB的内存,由于有4096K个选项(item),所以总计可以覆盖4096K*1MB=4GB的内存空间。
具体对应到linux,由于linux的软件架构是支持3级页表结构,而arm架构实际只有2级的页表结构,所以linux代码中的中间级页表的实现是空的。在linux代码中,第一级的页表的页目录表项用pgd表示,中间级的页表的页目录表项用pud表示(arm架构其实不需要),第三级的页表的页目录表项用pmd表示(由于中间pud是空的,所以pgd=pmd),另外目前arm体系的移动设备中RAM的page大小一般都是4KB/page,所以L1页表中的页表项都是指向fine page table的。
但在linux内核启动的初始化阶段,临时建立页表(initial page tables)以供linux内核初始化提供执行环境,这时L1的页表项使用的就是第二种页表项(section enty),他直接映射的是1M的内存空间。具体的可以参考arch/arm/kernel/head.S中的__create_page_tables函数,限于篇幅,这里就不展开说了。
针对这种section page translation,mmu硬件执行虚拟地址转物理地址的过程如下:

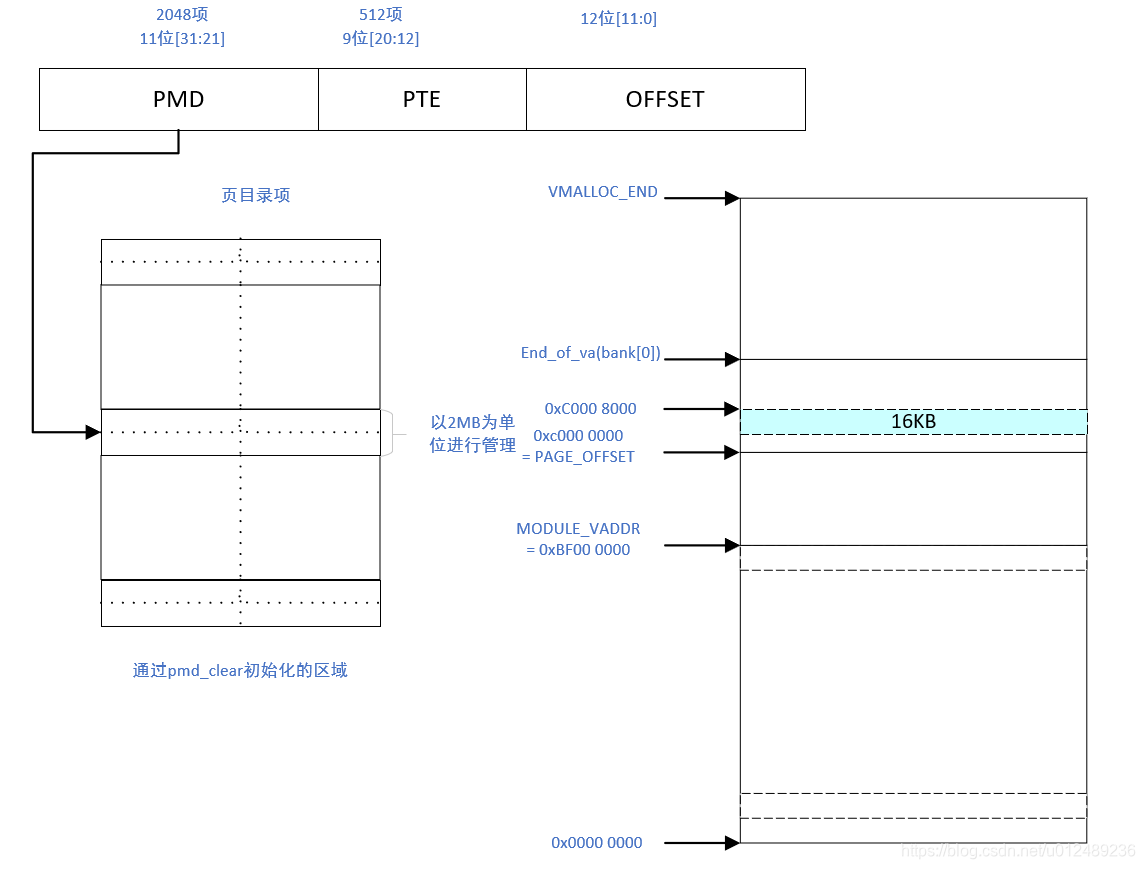
以上在初始化过程使用的临时页表(initial page tables),在内核启动的后期会被覆盖掉,即在paging_init--->map_lowmem函数中会重新建立页表,该函数为物理内存从0地址到低端内存(lowmem_limit)建立一个一一映射的映射表。所谓的一一映射就是物理地址和虚拟地址就差一个固定的偏移量,该偏移量一般就是0xc0000000(呵呵,为什么是0xc0000000?)
说到这里引入一个重要的概念,就是与低端内存相对的高端内存,什么是高端内存?为什么需要高端内存?为了解析这个问题,我们假设我们使用的物理内存有2GB大小,另外由于我们内核空间的地址范围是从3G-4G的空间,并且前面也说到了,linux内核的低端内存空间都是一一映射的,如果不引入高端内存这个概念,全部都使用一一映射的方式,那内核只能访问到1GB的物理内存,但实际上,我们是需要内核在内核空间能够访问所有的4GB的内存大小的,那怎么做到呢?
方法就是我们不让3G-4G的空间都使用一一映射,而是将物理地址的[0x00,fix_addr](fix_addr<1GB)映射到内核空间虚拟地址[0x00+3G,fix_addr+3G],然后将[fix_addr+3G,4G]这段空间保留下来用于动态映射,这样我们可以通过这段虚拟地址来访问从fix_addr到4GB的物理内存空间。怎么做到的呢?
譬如我们想要访问物理地址[fix_addr,4GB]这段区间中的任何一段,我就用宝贵的内核虚拟地址[fix_addr+3G,4G]的一段去映射他,建立好mmu硬件使用的页表,访问完后,将映射清除,将内核的这段虚拟地址释放,以供下次访问其他的物理内存使用。这样就可以达到访问所有4GB的物理内存的目的。
那么内核代码是如何建立映射表的呢?
我们着重从arch/arm/mm/mmu.c中的create_mapping函数来分析。在分析之前我们先看下arm mmu硬件是如何在二级页表结构中,实现虚拟地址转物理地址的。

先贴出原代码(arch/arm/mm/mmu.c):
该函数的功能描述如下:
Create the page directory entries and any necessary
page tables for the mapping specified by `md'. We
are able to cope here with varying sizes and address
offsets, and we take full advantage of sections and
supersections.

line737-line742:参数合法性检查,该函数不为用户空间的虚拟地址建立映射表(记得多问自己一个为什么?)
line744-line750:如果是iomemory,则映射的虚拟地址范围应属于高端内存区间,由于我们这里是常规的memory,即type为MT_MEMORY,所以不会进入该分支
line775: 获得该虚拟地址addr属于第一级页表(L1)的哪个表项,详细跟踪pgd_offset_k函数(定义在:arch/arm/include/asm/pgtable.h),你会发现,我们内核的L1页目录表的基地址位于0xc0004000,而我们的内核代码则是放置在0xc0008000开始的位置。而从0xc0004000到0xc0008000区间大小是16KB,刚好就是L1页表的大小(见文章开头的描述)
在这里需要注意一个概念:内核的页目录表项和进程的页目录表项,内核的页目录表项是对系统所有进程都是公共的;而进程的页目录表项则是跟特定进程相关的,每个应用进程都有自己的页目录表项,但各个进程对应的内核空间的页目录表相都是一样的。正是由于每个进程都有自己的页目录表相,所以才能做到每个进程都可以独立拥有属于自己的[0,3GB]的内存空间。
line778 pgd_addr_end()确保[addr,next]地址不会跨越一个L1表项所能映射的最大内存空间2MB(为什么是2MB而不是1MB呢?这个是linux的一个处理技巧,以后再详细展开说)
line780 alloc_init_pud()函数为定位到的L1页目录表项pgd所指向的二级页表(L2)建立映射表
line784 pdg++下移L1页目录表项pgd,映射下一个2MB空间的虚拟地址到对应的2MB的物理空间。
在这里解析下,为什么L1页目录表项pgd能够映射2MB的虚地地址空间。
在本文的第一个图中,他是arm典型的mmu映射框架图,但并不是linux的,linux映射框架图在它的基础做了些调整和优化。
linux所做的调整描述如下(以下摘自linux内核:arch/arm/include/asm/pgtable-2level.h中提供的注释说明):
/*
* Hardware-wise, we have a two level page table structure, where the first
* level has 4096 entries, and the second level has 256 entries. Each entry
* is one 32-bit word. Most of the bits in the second level entry are used
* by hardware, and there aren't any "accessed" and "dirty" bits.
*
* Linux on the other hand has a three level page table structure, which can
* be wrapped to fit a two level page table structure easily - using the PGD
* and PTE only. However, Linux also expects one "PTE" table per page, and
* at least a "dirty" bit.
*
* Therefore, we tweak the implementation slightly - we tell Linux that we
* have 2048 entries in the first level, each of which is 8 bytes (iow, two
* hardware pointers to the second level.) The second level contains two
* hardware PTE tables arranged contiguously, preceded by Linux versions
* which contain the state information Linux needs. We, therefore, end up
* with 512 entries in the "PTE" level.
*
* This leads to the page tables having the following layout:
*

重要调整说明如下:
L1页表从4096个item变为2048个item,但每个item的大小从原来的4字节变为8个字节。
一个page中,放置2个L2页表,每个还是256项,每项是4个字节,所以总计是256*2*4=2KB,放置在page页的下半部,而上部分放置对应的linux内存管理系统使用的页表,mmu硬件是不会去使用它的。所以刚好 占满一个page页的大小(4KB),这样就不浪费空间了。
有了上面基础,下面再详细的分析以上的line780的函数alloc_init_pud,该函数会最终调用到alloc_init_pte函数:

line598 early_pte_alloc函数判断对应的pmd所指向的L2页表是否存在,如果不存在就分配L2页表,如果存在就返回L2页表所在page页的虚地址。

line572 判断pmd所指向的L2页表是否存在,不存在则通过early_alloc 函数分配PTE_HWTABLE_OFF(512*4=2KB)+PTE_HWTABLE_SIZE(512*4=2KB)总计4KB的一个物理页来存储2个linuxpet 页表+2个hwpte页表。
line574返回这个物理页所在虚拟地址
回到alloc_init_pte函数的line599:

line183 pte_index用来确定该虚拟地址在L2页表中的偏移量。即虚拟地址的bit[12~21]共计9个bit,刚好用于寻址两个L2页表(总计512项)
回到alloc_init_pte函数,其中line605行,是设置L2页表中addr所定位到的页表项(即pte),主要工作就是填充对应物理页的物理地址,以供mmu硬件来实现地址的翻译。
line604~line607循环填充完两个hwpte页表,完成一个2M物理内存的映射表的建立。
line608 将最终调用如下函数:static inline void __pmd_populate(pmd_t *pmdp, phys_addr_t pte, pmdval_t prot)

在执行这个函数之前,2个L2页表已经建立,该函数的作用就是设置L1页表的对应表项,使其指向刚建立的2个L2页表(hwpte0,hwpte1),正如前面所说,由于linux的L1页表项是8个字节大小,所以:
line133 将头4个字节指向hwpte0页表,
line135 将后4个字节指向hwpte1页表,至此L1---〉L2页表的关联已经建立。
line137 是刷新TLB缓冲,使系统的cpu都可以看见该映射的变化
至此已完成struct map_desc *md结构体所指定的虚拟地址到物理地址的映射关系的建立,以供硬件mmu来自动实现虚拟到物理地址的翻译。
以上过程,有选择的将某些细节给省略了,限于篇幅,另外如果明白了这个过程,很细节的可以自己去看相关的代码。譬如上面的set_pte_ext函数,会调用的汇编函数来实现pte表项的设置。
TLB硬件原理
前一章节,我们学习了分页机制的硬件原理,从虚拟内存地址到物理内存地址的转换,我们通过页表来处理。为了节约页表的内存存储空间,我们会使用多级页表。但是,多级页表虽然节约了我们的存储空间,但是却存在问题:
原本我们对于只需要进行一次地址转换,只需要访问一次内存就能找到对应的物理页号了,算出物理地址
现在我们需要多次访问内存,才能找到对应的物理页号。
最终带来了时间上的开销,变成了一个“以时间换空间”的策略,极大的限制了内存访问性能问题。所以为了解决这种问题导致处理器性能下降的问题,计算机工程师们专门在 CPU 里放了一块缓存芯片,这块缓存芯片我们称之为TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer)
1. TLB介绍
TLB是Translation Lookaside Buffer的简称,可翻译为“地址转换后援缓冲器”,也可简称为“快表”。简单地说,TLB就是页表的Cache,属于MMU的一部分,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。处理器在取指或者执行访问memory指令的时候都需要进行地址翻译,即把虚拟地址翻译成物理地址。而地址翻译是一个漫长的过程,需要遍历几个level的Translation table,从而产生严重的开销。为了提高性能,我们会在MMU中增加一个TLB的单元,把地址翻译关系保存在这个高速缓存中,从而省略了对内存中页表的访问。

TLB存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,我们可以直接在 TLB 里面查询结果,而不需要多次访问内存来完成一次转换。
TLB其实本质上也是一种cache,既然是一种cache,其目的就是为了提供更高的performance。而与我们知道的指令cache和数据cache又又什么不同呢?
1.指令cache:解决cpu获取main memory中的指令数据的速度比较慢的问题而设立
2.数据cache:解决cpu获取main memory中的数据的速度比较慢的问题而设立
Cache为了更快的访问main memory中的数据和指令,而TLB是为了更快的进行地址翻译而将部分的页表内容缓存到了Translation lookasid buffer中,避免了从main memory访问页表的过程。
2. TLB的转换过程
TLB中的项由两部分组成:
标识区:存放的是虚地址的一部
数据区:存放物理页号、存储保护信息以及其他一些辅助信息
对于数据区的辅助信息包括以下内容:
有效位(Valid):对于操作系统,所有的数据都不会加载进内存,当数据不在内存的时候,就需要到硬盘查找并加载到内存。当为1时,表示在内存上,为0时,该页不在内存,就需要到硬盘查找。
引用位(reference):由于TLB中的项数是一定的,所以当有新的TLB项需要进来但是又满了的话,如果根据LRU算法,就将最近最少使用的项替换成新的项。故需要引用位。同时要注意的是,页表中也有引用位。
脏位(dirty):当内存上的某个块需要被新的块替换时,它需要根据脏位判断这个块之前有没有被修改过,如果被修改过,先把这个块更新到硬盘再替换,否则就直接替换。

下面我们来看一下,当存在TLB的访问流程:
当CPU收到应用程序发来的虚拟地址后,首先去TLB中根据标志Tag寻找页表数据,假如TLB中正好存放所需的页表并且有效位是1,说明TLB命中了,那么直接就可以从TLB中获取该虚拟页号对应的物理页号。
假如有效位是0,说明该页不在内存中,这时候就发生缺页异常,CPU需要先去外存中将该页调入内存并将页表和TLB更新
假如在TLB中没有找到,就通过上一章节的方法,通过分页机制来实现虚拟地址到物理地址的查找。
如果TLB已经满了,那么还要设计替换算法来决定让哪一个TLB entry失效,从而加载新的页表项。
引用位、脏位何时更新?
1. 如果是TLB命中,那么引用位就会被置1,当TLB或页表满时,就会根据该引用位选择适合的替换位置
2. 如果TLB命中且这个访存操作是个写操作,那么脏位就会被置1,表明该页被修改过,当该页要从内存中移除时会先执行将该页写会外存的操作,保证数据被正确修改。
1
2
3
3. 如何确定TLB match
我们选择Cortex-A72 processor来描述ARMv8的TLB的组成结构以及维护TLB的指令

A72实现了2个level的TLB,
绿色是L1 TLB,包括L1 instruction TLB(48-entry fully-associative)和L1 data TLB(32-entry fully-associative)。
黄色block是L2 unified TLB,它要大一些,可以容纳1024个entry,是4-way set-associative的。当L1 TLB发生TLB miss的时候,L2 TLB是它们坚强的后盾
通过上图,我们还可以看出:对于多核CPU,每个processor core都有自己的TLB。

假如不做任何的处理,那么在进程A切换到进程B的时候,TLB和Cache中同时存在了A和B进程的数据。
对于kernel space其实无所谓,因为所有的进程都是共享的
对于A和B进程,它们各种有自己的独立的用户地址空间,也就是说,同样的一个虚拟地址X,在A的地址空间中可以被翻译成Pa,而在B地址空间中会被翻译成Pb,如果在地址翻译过程中,TLB中同时存在A和B进程的数据,那么旧的A地址空间的缓存项会影响B进程地址空间的翻译
因此,在进程切换的时候,需要有tlb的操作,以便清除旧进程的影响,具体怎样做呢?
当系统发生进程切换,从进程A切换到进程B,从而导致地址空间也从A切换到B,这时候,我们可以认为在A进程执行过程中,所有TLB和Cache的数据都是for A进程的,一旦切换到B,整个地址空间都不一样了,因此需要全部flush掉
这种方案当然没有问题,当进程B被切入执行的时候,其面对的CPU是一个干干净净,从头开始的硬件环境,TLB和Cache中不会有任何的残留的A进程的数据来影响当前B进程的执行。当然,稍微有一点遗憾的就是在B进程开始执行的时候,TLB和Cache都是冰冷的(空空如也),因此,B进程刚开始执行的时候,TLB miss和Cache miss都非常严重,从而导致了性能的下降。我们管这种空TLB叫做cold TLB,它需要随着进程的运行warm up起来才能慢慢发挥起来效果,而在这个时候有可能又会有新的进程被调度了,而造成TLB的颠簸效应。
我们采用进程地址空间这样的术语,其实它可以被进一步细分为内核地址空间和用户地址空间。对于所有的进程(包括内核线程),内核地址空间是一样的,因此对于这部分地址翻译,无论进程如何切换,内核地址空间转换到物理地址的关系是永远不变的,其实在进程A切换到B的时候,不需要flush掉,因为B进程也可以继续使用这部分的TLB内容(上图中,橘色的block)。对于用户地址空间,各个进程都有自己独立的地址空间,在进程A切换到B的时候,TLB中的和A进程相关的entry(上图中,青色的block)对于B是完全没有任何意义的,需要flush掉。
在这样的思路指导下,我们其实需要区分global和local(其实就是process-specific的意思)这两种类型的地址翻译,因此,在页表描述符中往往有一个bit来标识该地址翻译是global还是local的,同样的,在TLB中,这个标识global还是local的flag也会被缓存起来。有了这样的设计之后,我们可以根据不同的场景而flush all或者只是flush local tlb entry。
4. 多核的TLB操作
完成单核场景下的分析之后,我们一起来看看多核的情况。进程切换相关的TLB逻辑block示意图如下

在多核系统中,进程切换的时候,TLB的操作要复杂一些,主要原因有两点:其一是各个cpu core有各自的TLB,因此TLB的操作可以分成两类,一类是flush all,即将所有cpu core上的tlb flush掉,还有一类操作是flush local tlb,即仅仅flush本cpu core的tlb。另外一个原因是进程可以调度到任何一个cpu core上执行(当然具体和cpu affinity的设定相关),从而导致task处处留情(在各个cpu上留有残余的tlb entry)。
我们了解到地址翻译有global(各个进程共享)和local(进程特定的)的概念,因而tlb entry也有global和local的区分。如果不区分这两个概念,那么进程切换的时候,直接flush该cpu上的所有残余。这样,当进程A切出的时候,留给下一个进程B一个清爽的tlb,而当进程A在其他cpu上再次调度的时候,它面临的也是一个全空的TLB(其他cpu的tlb不会影响)。当然,如果区分global 和local,那么tlb操作也基本类似,只不过进程切换的时候,不是flush该cpu上的所有tlb entry,而是flush所有的tlb local entry就OK了。
5. PCID
按照这种思路走下去,那就要思考,有没有别的办法能够不刷新TLB呢?有办法的,那就是PCID。
PCID(进程上下文标识符)是在Westmere架构引入的新特性。简单来说,在此之前,TLB是单纯的VA到PA的转换表,进程1和进程2的VA对应的PA不同,不能放在一起。加上PCID后,转换变成VA + 进程上下文ID到PA的转换表,放在一起完全没有问题了。这样进程1和进程2的页表可以和谐的在TLB中共处,进程在它们之前切换完全不需要预热了!
所以新的加载CR3的过程变成了:如果CR4的PCID=1,加载CR3就不需要Flush TLB。
6. TLB shootdown
一切看起来很美好,PCID这个在多年前就有了的技术,现在已经在每个Intel CPU中生根了,那么是不是已经被广泛使用了呢?而实际的情况是Linux在2017年底才在4.15版中真正全面使用了PCID(尽管在4.14中开始部分引入PCID,见参考资料1),这是为什么呢?
PCID这么好的技术也有副作用。在它之前的日子里,Linux在多核CPU上调度进程时候,因为每次进程调度都会刷掉进程用户空间的TLB,并没有什么问题。如果支持PCID的话,TLB操作变得很简单,或者说我们没有必要去执行TLB的操作,因为在TLB的搜索的时候已经区分各个进程,这样TLB不会影响其他任务的执行。
在单核系统中,这样的操作确实能够获得很好的性能,例如场景为A—>B—>A,如果TLB足够大,TLB再两个进程中反复切换,极大的提升了性能。
但是在多核系统重,如果CPU支持PCID,并且在进程切换的时候不flush tlb,那么系统中各个CPU中的TLB entry则保留各个进程的TLB entry,当在某个CPU上,一个进程被销毁了,或者该进程修改了自己的页表的时候,就必须将该进程的TLB从系统中请出去。这时候,不仅仅需要flush本CPU上对应的TLB entry,还需要flush其他CPU上和该进程相关的残余。而这个动作就需要通过IPI实现,从而引起了系统开销,此外PCID的分配和管理也会带来额外的开销。再加上PCID里面的上下文ID长度有限,只能够放得下4096个进程ID,这就需要一定的管理以便申请和放弃。如此种种,导致Linux系统在应用PCID上并不积极,直到不得不这样做。
7. 结论
TLB的引入解决了分页机制的性能问题,但是如何提高TLB的性能问题,但是如何提高TLB的命中确成为一个新的技术难题,对于X86提供了PCID的方式,而ARM采用的ASID技术,但是对于现在日益复杂的应用场景,这些都未能彻底的解决这些问题。
Linux内核三级映射
Linux内核中一般采用的是3级映射模型,第一层是页面目录(PDG),第二层是中间目录(PMD),页表(PTE),其三级映射的框图如下:

对于IMX6UL架构中,可以采用按段来映射,这时候采用的是一级页表,内存中有一个映射段,表中有4096个表项,每个表项大小为4Byte,所以这个映射表的大小为16KB,而且其位置必须是16KB边界对齐,每个段表项可以寻址1MB的大小的地址空间。当CPU访问内存时,32位的虚拟地址的高12位(bit[31:20])用作访问段映射表的索引,从表中找到对应的表项,每个表项提供一个12Bit的物理短地址,以及相应的标志位,如可读,可写等标志位。将这个12bit的物理地址和虚拟地址的低20bit拼凑在一起,就得到32bit的物理地址。但是在ARM32系统中只用到了两层映射,所以软件上就会跳过PMD表,其映射框图如下图

32位的虚拟地址的高12位(bit[31:20])作为访问一级页表的索引值,通过TTBRx找到PGD页表项的基地址,然后加上索引值,就可以找到二级页表的基地址。以虚拟地址的次8位(bit[19:12])作为二级页表的索引值,得到相应的页表项,从这个页表项中找到20位的物理页面地址,最后将这个20位的物理页面地址和虚拟地址的低12Bit拼在一起,最终就得到了32位物理地址。整个过程由MMU硬件完成,软件不需要接入。我们从ARM Linux内核建立具体内存区间的页面映射过程来看页表的映射是如何实现的。
在map_lowmem()使用create_mapping()创建页表映射,这个函数的参数结构是struct map_desc,下面来研究它的相关结构体,有助于理解内核是如何处理页表映射的。
struct map_desc {
unsigned long virtual;
unsigned long pfn;
unsigned long length;
unsigned int type;
};
结构变量 含义
virtual 表示这个区间的虚拟地址的起始地址
pfn 物理地址开始地址的页帧号
length 内存区间长度
type 内存区间的属性
而对于内存区间的属性type指向类型位struct mem_type的mem_types数组
struct mem_type {
pteval_t prot_pte;
pteval_t prot_pte_s2;
pmdval_t prot_l1;
pmdval_t prot_sect;
unsigned int domain;
};
结构变量 含义
prot_pte PTE的属性
prot_pte_s2 定义CONFIG_ARM_LPAE才有效
prot_pl1 PMD属性
prot_sect section类型映射
domain 定义ARM不同的域
对于domain成员用于ARM中定义的不同的域,ARM linux只是用了3个
#define DOMAIN_KERNEL 2
#define DOMAIN_USER 1
#define DOMAIN_IO 0
DOMAIN_KERNEL属于系统空间,DOMAIN_IO用于I/O地址域,实际也属于系统空间,DOMAIN_USER则属于用户空间。下面重点关注对于二级映射中的一级页表和二级页表,对于ARMV7中,下面是first-level descriptor详细说明

prot_pl1成员用于一级页表项的控制位和标志位,具体的定义如下:
#define PMD_TYPE_MASK (_AT(pmdval_t, 3) << 0)
#define PMD_TYPE_FAULT (_AT(pmdval_t, 0) << 0)
#define PMD_TYPE_TABLE (_AT(pmdval_t, 1) << 0)
#define PMD_TYPE_SECT (_AT(pmdval_t, 2) << 0)
#define PMD_PXNTABLE (_AT(pmdval_t, 1) << 2) /* v7 */
#define PMD_BIT4 (_AT(pmdval_t, 1) << 4)
#define PMD_DOMAIN(x) (_AT(pmdval_t, (x)) << 5)
#define PMD_PROTECTION (_AT(pmdval_t, 1) << 9) /* v5 */
1
2
3
4
5
6
7
8
下面是second-level descriptor的详细说明:

prot_pte成员用于页面表项的控制位和标志位,其具体的定义如下:
/*
* + Level 2 descriptor (PTE)
* - common
*/
#define PTE_TYPE_MASK (_AT(pteval_t, 3) << 0)
#define PTE_TYPE_FAULT (_AT(pteval_t, 0) << 0)
#define PTE_TYPE_LARGE (_AT(pteval_t, 1) << 0)
#define PTE_TYPE_SMALL (_AT(pteval_t, 2) << 0)
#define PTE_TYPE_EXT (_AT(pteval_t, 3) << 0) /* v5 */
#define PTE_BUFFERABLE (_AT(pteval_t, 1) << 2)
#define PTE_CACHEABLE (_AT(pteval_t, 1) << 3)
1
2
3
4
5
6
7
8
9
10
11
对于系统中定义了一个全局的mem_type[]数组来描述所有的内存区间类型,定义如下
static struct mem_type mem_types[] __ro_after_init = {
[MT_DEVICE] = { /* Strongly ordered / ARMv6 shared device */
.prot_pte = PROT_PTE_DEVICE | L_PTE_MT_DEV_SHARED |
L_PTE_SHARED,
.prot_pte_s2 = s2_policy(PROT_PTE_S2_DEVICE) |
s2_policy(L_PTE_S2_MT_DEV_SHARED) |
L_PTE_SHARED,
.prot_l1 = PMD_TYPE_TABLE,
.prot_sect = PROT_SECT_DEVICE | PMD_SECT_S,
.domain = DOMAIN_IO,
},
...
[MT_MEMORY_DMA_READY] = {
.prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY |
L_PTE_XN,
.prot_l1 = PMD_TYPE_TABLE,
.domain = DOMAIN_KERNEL,
},
}
create_mapping的参数是struct map_desc类型,用于描述一个虚拟地址区域线性映射到物理区域。基于这块区域创建PGD/PTE,下面我们就进入map_lowmem。
static void __init map_lowmem(void)
{
struct memblock_region *reg; --------------(1)
#ifdef CONFIG_XIP_KERNEL
phys_addr_t kernel_x_start = round_down(__pa(_sdata), SECTION_SIZE);
#else
phys_addr_t kernel_x_start = round_down(__pa(_stext), SECTION_SIZE);
#endif
phys_addr_t kernel_x_end = round_up(__pa(__init_end), SECTION_SIZE);
/* Map all the lowmem memory banks. */
for_each_memblock(memory, reg) { ----------------(2)
phys_addr_t start = reg->base;
phys_addr_t end = start + reg->size;
struct map_desc map;
if (memblock_is_nomap(reg))
continue;
if (end > arm_lowmem_limit)
end = arm_lowmem_limit;
if (start >= end)
break;
if (end < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RWX;
create_mapping(&map);
} else if (start >= kernel_x_end) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
} else {
/* This better cover the entire kernel */
if (start < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = kernel_x_start - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
}
map.pfn = __phys_to_pfn(kernel_x_start);
map.virtual = __phys_to_virt(kernel_x_start);
map.length = kernel_x_end - kernel_x_start;
map.type = MT_MEMORY_RWX;
create_mapping(&map);
if (kernel_x_end < end) {
map.pfn = __phys_to_pfn(kernel_x_end);
map.virtual = __phys_to_virt(kernel_x_end);
map.length = end - kernel_x_end;
map.type = MT_MEMORY_RW;
create_mapping(&map);
}
}
}
}
如果memblock region的起始地址包含了kernel _stext到init_end区间,则需要调用三次create mapping()建立映射
如果memblock region只包含kernel _stext到init_end区间的一部分,则需要调用三次create mapping()建立映射
如果memblock region不包含kernel _stext到init_end区间,则只需要调用一次create mapping()建立映射
kernel的text段起始物理地址和init段结束的物理地址区间需要单独映射,而对于IMX6系列,kernel_x_start=80200000,kernel_x_end=81000000,而memory中定义了内存的地址空间为80000000~a0000000,采用的是直接映射的方式
0x8000 0000 ~ 0x8020 0000空间第一次使用create_mapping()建立映射,对于kernel的代码段,使用MT_MEMORY_RW属性,对应的物理页面是0x80000,虚拟地址为0xc000 0000~0xc020 0000
0x8020 0000 ~ 0x8100 0000空间第二次使用create_mapping()建立映射,使用MT_MEMORY_RWX属性,对应的物理页面是0x80200,虚拟地址为0xc020 0000 ~ 0xc100 0000
0x8100 0000 ~ 0xa000 0000空间第三次使用create_mapping()建立映射,使用MT_MEMORY_RW属性,对应的物理页面是0x81000,虚拟地址为0xc100 0000 ~ 0xe000 0000
通过定义了3个内存区间,然后调用create_mapping时,以此数据结构指针为调用参数,那么我们来看看create_mapping
static void __init create_mapping(struct map_desc *md)
{
if (md->virtual != vectors_base() && md->virtual < TASK_SIZE) { --------------(1)
pr_warn("BUG: not creating mapping for 0x%08llx at 0x%08lx in user region\n",
(long long)__pfn_to_phys((u64)md->pfn), md->virtual);
return;
}
if ((md->type == MT_DEVICE || md->type == MT_ROM) && --------------(2)
md->virtual >= PAGE_OFFSET && md->virtual < FIXADDR_START &&
(md->virtual < VMALLOC_START || md->virtual >= VMALLOC_END)) {
pr_warn("BUG: mapping for 0x%08llx at 0x%08lx out of vmalloc space\n",
(long long)__pfn_to_phys((u64)md->pfn), md->virtual);
}
__create_mapping(&init_mm, md, early_alloc, false); ---------------(3)
}
首先判断虚拟地址是否合法,判断虚拟地址在用户区域,并且不是中断向量表(中断向量表可以在虚拟地址0开始的地方)
判断映射类型是否合法 ,内存类型为IO和ROM类型的不允许映射在低端内存或高于VMALLOC_END区域,只能映射在vmalloc区域
参数检查后,调用__create_mapping进行实际的映射
static void __init __create_mapping(struct mm_struct *mm, struct map_desc *md,
void *(*alloc)(unsigned long sz),
bool ng)
{
unsigned long addr, length, end;
phys_addr_t phys;
const struct mem_type *type;
pgd_t *pgd;
type = &mem_types[md->type]; -------------------(1)
#ifndef CONFIG_ARM_LPAE
/*
* Catch 36-bit addresses
*/
if (md->pfn >= 0x100000) {
create_36bit_mapping(mm, md, type, ng);
return;
}
#endif
addr = md->virtual & PAGE_MASK;
phys = __pfn_to_phys(md->pfn);
length = PAGE_ALIGN(md->length + (md->virtual & ~PAGE_MASK));
if (type->prot_l1 == 0 && ((addr | phys | length) & ~SECTION_MASK)) {
pr_warn("BUG: map for 0x%08llx at 0x%08lx can not be mapped using pages, ignoring.\n",
(long long)__pfn_to_phys(md->pfn), addr);
return;
}
pgd = pgd_offset(mm, addr); -------------------(2)
end = addr + length;
do { -------------------(3)
unsigned long next = pgd_addr_end(addr, end);
alloc_init_pud(pgd, addr, next, phys, type, alloc, ng); --------------------(4)
phys += next - addr;
addr = next;
} while (pgd++, addr != end);
}
创建地址映射需要首先明确地址空间,不同的进程有不同的地址空间,而我们这里对内核虚拟地址空间而创建地址映射,因此传递的参数是init_mm。其处理流程为:
1.根据type找到对应的struct mem_type,然后虚拟地址采用4K地址对其方式,通过物理页面找到对应物理地址,然后进行参数合法性检查
2.根据addr找到对应虚拟地址对应的pgd地址
3.(addr,length)这个虚拟地址范围可能需要占用多个PGD entry,因此采用一个循环,不断的调用alloc_init_pud函数来完成(addr,length)这个虚拟地址范围的映射。 pgd_addr_end(addr, end); 获取addr后下一个2M的虚拟起始地址,保证不超过end,如果超过end,则返end
4.一是填充pgd entry,二是创建后续的pud translation table(如果需要的话)并进行下游Translation table的建立,对于ARM32 ,该PGD表项不存在,所以只会执行一次,接下来创建下一级页表。对于4级页表的处理器,这个会创建PGD的表项。
首先我们来看看,pdg_offset,入参是mm和addr,获去所属的页面目录项PGD,内核的页表存放在swapper_pg_dir 地址中,可以通过init_mm数据结构来获得。
/* to find an entry in a page-table-directory */
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
这个 swapper_pg_dir 是 pgd 的入口,前面章节已经介绍过,其值是0xc000 4000,内核的pgd的起始地址在0xc000 4000, 所以(init_mm)->pgd+(add >> 21) = (pgd_t) 0xc000 4000 + (addr >> 21)。如果addr的值是0xc000 0000,那么右移21位值为0x600,最后就为0xc000 4000 + 0x600 * 4 = 0xc000 7000,总之pdg_offset_k()可以从init_mm数据结构所指定的页面目录中找到地址addr所属的页面目录项指针pgd。首先通过init_mm结构得到页表的基地址,然后通过addr右移21得到pgd的索引值,最后在一级页表中找到对应的页表项pgd。
在计算得到虚拟地址的结束地点end = addr + length,这里是为了取得addr开始,PGDIR_SIZE为步长,end为结束标志位来进行while循环,所以对于while循环,此处按照2MB步长,遍历[virtual, virtual+length)空间创建PDG页表和PTE。
#define pgd_addr_end(addr, end) \
({ unsigned long __boundary = ((addr) + PGDIR_SIZE) & PGDIR_MASK; \
(__boundary - 1 < (end) - 1)? __boundary: (end); \
})
1
2
3
4
接下来,我们看看alloc_init_pud的处理流程
static void __init alloc_init_pud(pgd_t *pgd, unsigned long addr,
unsigned long end, phys_addr_t phys,
const struct mem_type *type,
void *(*alloc)(unsigned long sz), bool ng)
{
pud_t *pud = pud_offset(pgd, addr);
unsigned long next;
do {
next = pud_addr_end(addr, end);
alloc_init_pmd(pud, addr, next, phys, type, alloc, ng);
phys += next - addr;
} while (pud++, addr = next, addr != end);
}
根据pgd中找到对应的PUD项,然后计算PUD的结束地址,给PUD建立PMD,然后循环,其处理流程与PGD类似,由对于ARM32,PUD也不存在。
由于是2级映射,这里的pud=pgd,接着调用alloc_init_pmd
static void __init alloc_init_pmd(pud_t *pud, unsigned long addr,
unsigned long end, phys_addr_t phys,
const struct mem_type *type,
void *(*alloc)(unsigned long sz), bool ng)
{
pmd_t *pmd = pmd_offset(pud, addr); -----------------(1)
unsigned long next;
do {
/*
* With LPAE, we must loop over to map
* all the pmds for the given range.
*/
next = pmd_addr_end(addr, end);
/*
* Try a section mapping - addr, next and phys must all be
* aligned to a section boundary.
*/
if (type->prot_sect &&
((addr | next | phys) & ~SECTION_MASK) == 0) { -----------------(2)
__map_init_section(pmd, addr, next, phys, type, ng);
} else {
alloc_init_pte(pmd, addr, next,
__phys_to_pfn(phys), type, alloc, ng); -----------------(3)
}
phys += next - addr;
} while (pmd++, addr = next, addr != end);
}
1.通过pud拿到对应的二级页表的PMD
2.如果当前的物理地址,虚拟地址以及下一个将要映射的起始地址是按照2MB对齐,同时prot_sect代表主页表是以段映射方式,则可以按照段映射方式,不需要按照二级映射的方式
3.对应的是二级页表的初始化,pte表的初始化
回到我们开头,在map_lowmem创建了3段映射,都是采用段映射的方式,其映射方式如下,其的段映射地址空间,起始地址为0xc000 7000,大小为0x800。
物理地址范围 段表地址范围 虚拟地址范围
0x8000 0000 ~ 0x8020 0000 0xc000 7000 0xc000 0000 ~ 0xc020 0000
0x8020 0000 ~ 0x8100 0000 0xc000 7008 ~ 0xc000 7038 0xc020 0000 ~ 0xc100 0000
0x8100 0000 ~ 0xa000 0000 0xc000 7040 ~ 0xc000 77f8 0xc100 0000 ~ 0xe000 0000
下面我们来看看arm-linux采用的是两级页表的映射,跳过了PUD和PMD,所以我们就直接到alloc_init_pte创建PTE表,其处理为
static void __init alloc_init_pte(pmd_t *pmd, unsigned long addr,
unsigned long end, unsigned long pfn,
const struct mem_type *type,
void *(*alloc)(unsigned long sz),
bool ng)
{
pte_t *pte = arm_pte_alloc(pmd, addr, type->prot_l1, alloc);
do {
set_pte_ext(pte, pfn_pte(pfn, __pgprot(type->prot_pte)),
ng ? PTE_EXT_NG : 0);
pfn++;
} while (pte++, addr += PAGE_SIZE, addr != end);
}
pmd参数传递L1页表地址
addr和end分别指明被映射到虚拟地址的起止地址
pfn是将被映射的物理地址的页框
type参数指明映射的类型
arm_pte_alloc函数使用port_l1作为参数,创建PGD页表目录,返回addr对应的pte地址,后面的跟之前的PMD的原理一样,遍历(addr,end)区间内存,以PAGE_SIZE为步长。
static pte_t * __init arm_pte_alloc(pmd_t *pmd, unsigned long addr,
unsigned long prot,
void *(*alloc)(unsigned long sz))
{
if (pmd_none(*pmd)) { ----------------(1)
pte_t *pte = alloc(PTE_HWTABLE_OFF + PTE_HWTABLE_SIZE);
__pmd_populate(pmd, __pa(pte), prot);
}
BUG_ON(pmd_bad(*pmd));
return pte_offset_kernel(pmd, addr); ----------------(2)
}
判断pmd所指向的L2页表,不存在就直接通过alloc函数分配,PTE_HWTABLE_OFF(5124=2KB)+PTE_HWTABLE_SIZE(5124=2KB)总计4KB的一个物理页来存储2个linux pet 页表+2个hw pte页表。然而最开始使用 va[31:20] 一共 12 bits 来表征 1 级表项的 index_1,va[19:12] 8 bits 表征 2级表项 index_2,也就是说,1 级表项一共有 2 的 12 次幂这么多个 entry,也就是 4096 个,2 级表项有 2 的 8 次幂个 entry,也就是 256 个。这个特性是 ARM 的 MMU 硬件特性。而为什么我们alloc分配的时候,分配了2个512呢?
我们看看 Linux 的 pgtable-2level.h 的部分代码注释
* This leads to the page tables having the following layout:
*
* pgd pte
* | |
* +--------+
* | | +------------+ +0
* +- - - - + | Linux pt 0 |
* | | +------------+ +1024
* +--------+ +0 | Linux pt 1 |
* | |-----> +------------+ +2048
* +- - - - + +4 | h/w pt 0 |
* | |-----> +------------+ +3072
* +--------+ +8 | h/w pt 1 |
* | | +------------+ +4096
*
* See L_PTE_xxx below for definitions of bits in the "Linux pt", and
* PTE_xxx for definitions of bits appearing in the "h/w pt".
*
* PMD_xxx definitions refer to bits in the first level page table.
*
针对二级页表呢,分配了 512 + 512 个,其实真正的 ARM MMU 的二级是 256 个,他们的对应关系如上面的简要的图所示,pgd 对应到了 h/w pt 0 和 h/w pt 1,他们都是 256 的(每个 pte 是 4 个 Bytes,所以图中看到是 1K 的 Step),另外的两个是 Linux OS 对页面的一些描述信息,同他们放到一起,正好组成了 4K ,即一个页面。分配好内存后,那么就使用__pmd_populate(),生成pmd页表目录,并刷入RAM。
根据所属的页目录项的地址和address,返回相应的 PTE 表项
从 arm_pte_alloc 函数返回到 alloc_init_pte 后,继续调用 set_pte_ext,这个和结构体系相关,在 ARMv7-A架构的处理器,它的实现是在汇编函数中,其中入参如下
r0 ptep pointer to level 2 translation table entry
r1 pte PTE value to store
r2 ext value for extended pte bits
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] @ linux version ----------将r1的值存入r0地址的内存中
bic r3, r1, #0x000003f0 ----------清除r1的bit[9:4],存入r3
bic r3, r3, #PTE_TYPE_MASK ----------PTE_TYPE_MASK为0x03,记清除低2位
orr r3, r3, r2 ----------r3与r2或,存入r3
orr r3, r3, #PTE_EXT_AP0 | 2 ----------这里将bit1和bit4置位,所以是Small page。
tst r1, #1 << 4 ----------判断r1的bit4是否为0
orrne r3, r3, #PTE_EXT_TEX(1) ----------设置TEX为1
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX ----------设置AP[2]
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1 ----------设置AP[1]
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN ----------设置XN位
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID
eorne r1, r1, #L_PTE_NONE
tstne r1, #L_PTE_NONE
moveq r3, #0
ARM( str r3, [r0, #2048]! -) ---------并没有写入r0,而是写入r0+2048Bytes的偏移。
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext)
要理解是如何设置PTE表项,就需要参照B3.3.1 Translation table entry formants中关于Second-level descriptors的描述。

本章比较长,主要是针对的是map_lowmem进行了分析,该函数主要的是完成低端内存的映射的过程,也就是lowmem : 0xc0000000 - 0xe0000000 ( 512 MB),对于这个区域,对于不同的芯片,低端内存的空间是可以配置的。针对该函数对于内存空间通过create_mapping进行了映射,对内核整个映射的过程进行了初步的梳理,对于arm32,内核是支持4级页表映射,如图下所示

而对于iMx6UL,其采用的是二级映射的方式,对于PGD和PUD均为空,对于低端内存主要使用的是段映射方式,我们也大致梳理了下二级映射的一些原理,后面会详细的介绍。
MMU虚拟地址转换 - 基本流程
在Linux,Windows等操作系统中,为什么不直接使用Physical Address(物理地址),而要用Virtual Address(虚拟地址)呢(在intel的手册中也被称为Linear Address,具体原因请参考这篇文章)?
因为使用虚拟地址可以带来诸多好处:
- 在支持多进程的系统中,如果各个进程的镜像文件都使用物理地址,则在加载到同一物理内存空间的时候,可能发生冲突。
- 直接使用物理地址,不便于进行进程地址空间的隔离。
- 物理内存是有限的,在物理内存整体吃紧的时候,可以让多个进程通过分时复用的方法共享一个物理页面(某个进程需要保存的内容可以暂时swap到外部的disk/flash),这有点类似于多线程分时复用共享CPU的方式。
既然使用虚拟地址,就涉及到将虚拟地址转换为物理地址的过程,这需要MMU(Memory Management Unit)和页表(page table)的共同参与。
MMU
MMU是处理器/核(processer)中的一个硬件单元,通常每个核有一个MMU。MMU由两部分组成:TLB(Translation Lookaside Buffer)和table walk unit。

Page Table
page table是每个进程独有的,是软件实现的,是存储在main memory(比如DDR)中的。
Address Translation
因为访问内存中的页表相对耗时,尤其是在现在普遍使用多级页表的情况下,需要多次的内存访问,为了加快访问速度,系统设计人员为page table设计了一个硬件缓存 - TLB,CPU会首先在TLB中查找,因为在TLB中找起来很快。TLB之所以快,一是因为它含有的entries的数目较少,二是TLB是集成进CPU的,它几乎可以按照CPU的速度运行。
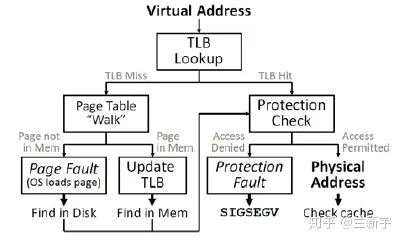
如果在TLB中找到了含有该虚拟地址的entry(TLB hit),则可从该entry【1】中直接获取对应的物理地址,否则就不幸地TLB miss了,就得去查找当前进程的page table(这里其实可能用到paging structure caches)。这个时候,组成MMU的另一个部分table walk unit就被召唤出来了,这里面的table就是page table。
使用table walk unit硬件单元来查找page table的方式被称为hardware TLB miss handling,通常被CISC架构的处理器(比如IA-32)所采用。它要在page table中查找不到,出现page fault的时候才会交由软件(操作系统)处理。
与之相对的通常被RISC架构的处理器(比如Alpha)采用的software TLB miss handling,TLB miss后CPU就不再参与了,由操作系统通过软件的方式来查找page table。使用硬件的方式更快,而使用软件的方式灵活性更强。IA-64提供了一种混合模式,可以兼顾两者的优点。
如果在page table中找到了该虚拟地址对应的entry的p(present)位是1,说明该虚拟地址对应的物理页面当前驻留在内存中,也就是page table hit。找到了还没完,接下来还有两件事要做:
- 既然是因为在TLB里找不到才找到这儿来的,自然要更新TLB。
- 进行权限检测,包括可读/可写/可执行权限,user/supervisor模式权限等。如果没有正确的权限,将触发SIGSEGV(Segmantation Fault)。
如果该虚拟地址对应的entry的p位是0,就会触发page fault,可能有这几种情况:
- 这个虚拟地址被分配后还从来没有被access过(比如malloc之后还没有操作分配到的空间,则不会真正分配物理内存)。触发page fault后分配物理内存,也就是demand paging,有了确定的demand了之后才分,然后将p位置1。
- 对应的这个物理页面的内容被换出到外部的disk/flash了,这个时候page table entry里存的是换出页面在外部swap area里暂存的位置,可以将其换回物理内存,再次建立映射,然后将p位置1。
关于在TLB中具体是怎么找的,在page table中又是怎么"walk"的,请看下回分解。
注【1】:entry有入口的意思,对于TLB和单级页表的一个entry,就是指向对应page的首地址(入口);对于后文介绍的多级页表的一个entry,就是指向下一级页表的首地址(入口)。
原创文章,转载请注明出处。
MMU虚拟地址转换[二] - 具体实现
关于上文提到的“关于在TLB中具体是怎么找的,在page table中又是怎么"walk"的问题,下面通过一个简单的例子说明一下。
假设当前CPU支持的虚拟地址是14位,物理地址是12位,page size为64字节(这里要说明一下,通常情况下呢,虚拟地址和物理地址的位数是一样的,但其实并不一定需要一样,因为本来就可以多个虚拟地址指向同一个物理地址嘛)。
不管是虚拟地址还是物理地址,因为最小管理单位都是page,在转换过程中,代表page内的偏移地址(offset)的低位bits部分是不需要参与的,需要转换的只是代表page唯一性标识的高位bits部分,称作page number。由此产生了4个概念:VPN(virtual page number),PPN(physical page number),VPO(virtual page offset)和PPO(physical page offset)
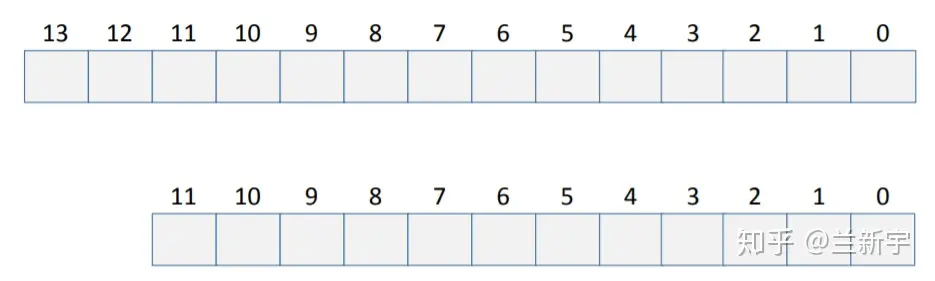
VPO和PPO占的bit位数为 ���2� ,p为page size大小,即64,因而VPO和PPO的值为6。因为所有pages都是同样大小的,所以VPO始终等于PPO。
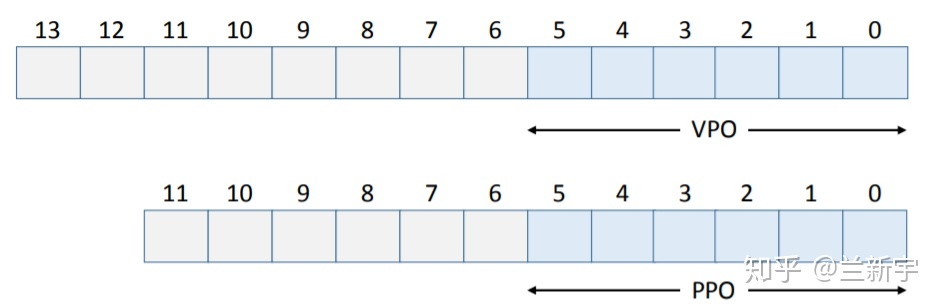
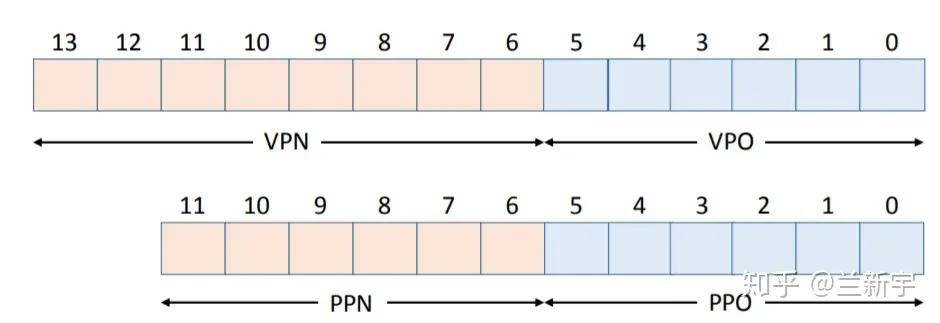
虚拟地址中剩下的bit位就成了VPN,物理地址中剩下的bit位就成了PPN。
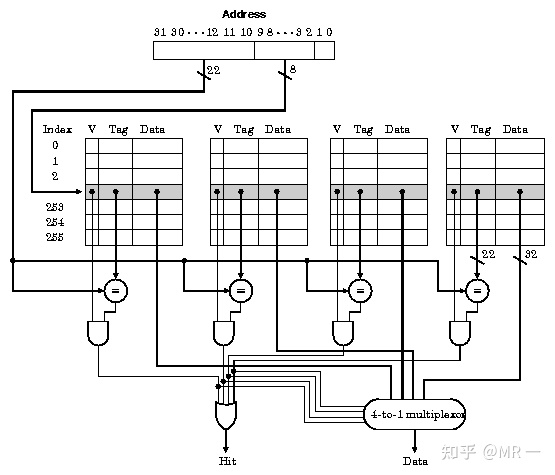
假设我们的TLB一共有16个entries,是4路组相关(4-way set associative)的,则有16/4=4个sets。TLB本身就是一个hardware cache, 关于cache中way, set, index, tag的基础概念,如果还不熟悉的,可以参考这两篇文章:浅谈Cache Memory和cache之虚虚实实。
TLB Index(以下简称TI)的值为 ���24 =2,剩下的bit位就成了TLB Tag(以下简称TT)。

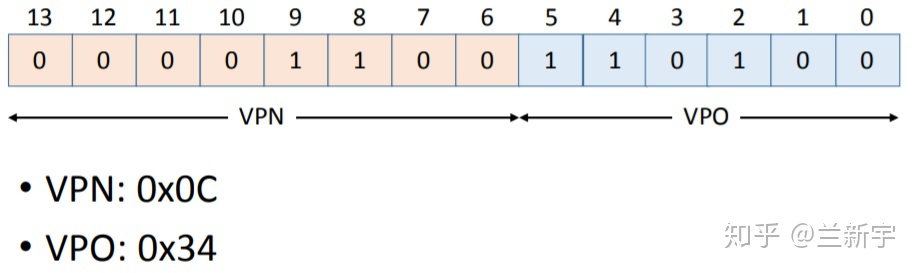
下面,我们准备读取虚拟地址为0x0334处的内容。
- 将这一地址分割成VPN和VPO
2. 将VPN分割成TT和TI
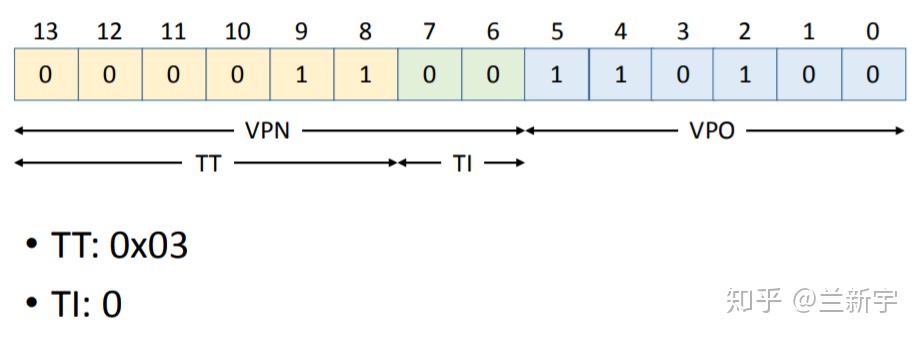
3. 使用TT (0x03) 和TI (0) 在TLB中查找。一个TLB entry的构成如下:

作为cache,TLB index是用来索引的,不会存储在TLB entry中,TLB entry中存的只有tag, 权限位,有效位和内容(对于TLB来说就是PPN)。
假设现在TLB中的内容是这样的(这里为了简化,省略了permission bits):
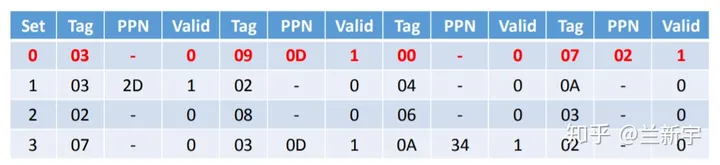
虽然在set/index为0这一行,找到了tag为03的一个entry,但这个entry中PPN是不存在的,整个entry目前是invalid的,也就是说TLB miss了,需要去page table中找。
注:上图对应硬件实现结构可以参考下面 4-ways set-assossiative cache 结构。一共16个Cache line (TLB entries) 则下图8bits index 因该是2 bits。TAG为6bits。 由于PAGE为64BYTEs 则OFFSET(PAGE SIZE决定)为6bits.
4. 使用VPN (0x0C) 作为index在page table中查找。一个只有one level的page table(单级页表)构成如下:
index作为索引,也是不会存储于page table entry中的,PTE存的只有权限位,有效位和内容(对于PTE来说也是PPN)。
假设现在的page table是这样的(同样为了简化,省略了permission bits):
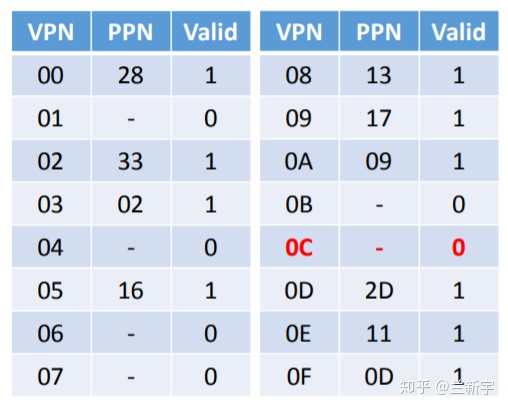
对应的PTE(page table entry)中的PPN不存在,依然是invalid的,这将触发一个page fault。
实现的细节展开后,上文中的图也可以展开了(只用关注左半部分)
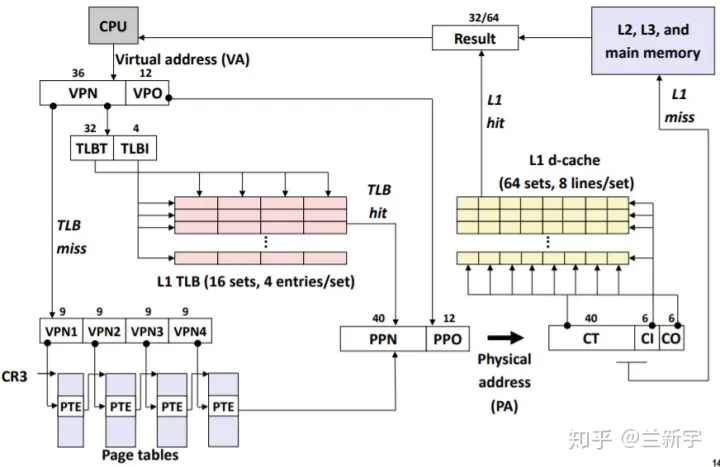
对比一下,你可能会发现一个TLB entry比一个page table entry多了一个tag,TLB使用的是tag比对【1】,而页表使用的是index索引,在PTE数目很大的情况下这会带来一系列问题,详情请看下回分解。
注【1】:如果是full associative的TLB,则只有tag没有index;如果是n-way set associative的TLB,则先通过index索引,再进行tag比对。
说明:本文例子来源于https://courses.cs.washington.edu
虚拟地址转换[三] - 多级页表
使用单级页表的问题
上文为了演示的需要,使用的是一个单级页表。事实上,若内存容量较大,按照常规的4KB的page大小的话,page table entry的数目将会很大。因为page table是按照VPN(virtual page number)来索引查找的,如果把单级页表视作一个big array,则VPN就相当于数组下标,因此page table本身需要在内存中是连续分布的,而且即便没有使用到的page,也会占用一个entry。
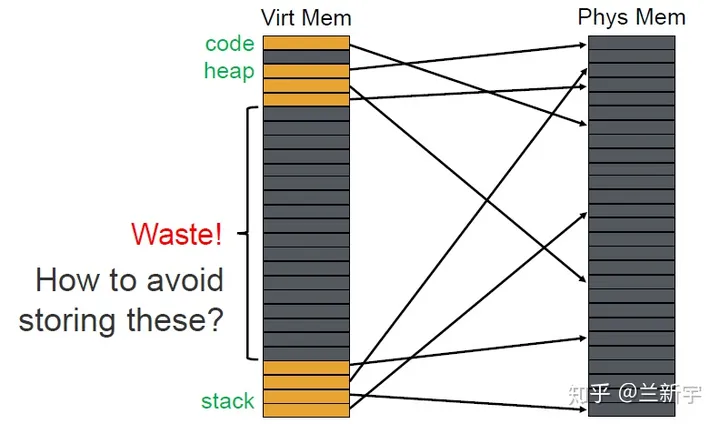
为了解决这些问题,在现代32/64位处理器中,通常使用的都是多级页表,操作系统的实现中也提供了对多级页表的支持。
多级页表的查找方法
MMU中的table walk unit使用虚拟地址中位域的子集做为index,顺着页表层次结构的各个级别往下查找。以一个虚拟地址为30位,第一级页表PD(Page Directory)占8 bits,第二级页表PT(Page Table)占10 bits,页大小为4KB(占12 bits)的系统为例,
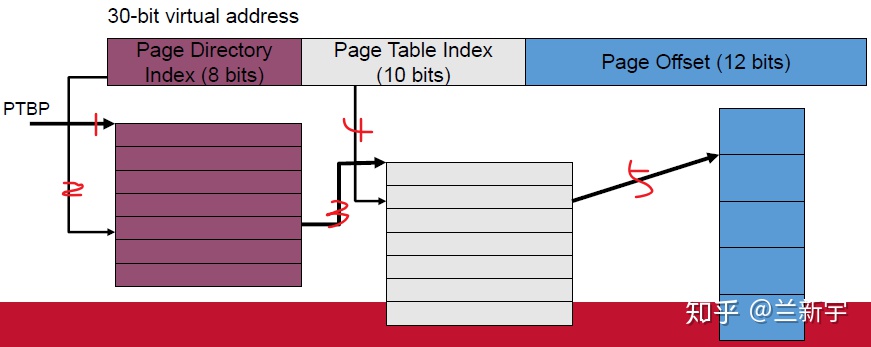
- 通过PTBP(Page Table Base Register)寄存器获得PD页表的起始物理地址(如果页表自己都用虚拟地址,那岂不是还得另外有个页表来转换,陷入死循环了……),然后从待转换的虚拟地址中取出高8位作为index找到对应的PD entry, 这个PD entry中存放的是它对应的PT页表的起始物理地址。
- 从待转换的虚拟地址中取出中间10位作为index在PT表中找到对应的PT entry,这个PT entry中存放的是就是物理页面号(PPN, Physical Page Number)了。
在多级页表系统中,其实每级页表都可以视为一种“虚拟地址”向“物理地址”的转换,只是这里的“虚拟地址”是待转换的虚拟地址的一个位域子集,而除了最后一级页表PTE是直接指向物理页面的,其他级别页表里的“物理地址”都是指向对应下一级页表的首地址。
再举一个更加鲜活的带有实际地址的例子,为了便于演示,使用一个PD,PT,page offset分别占4 bits, 4bits, 12bits的系统。
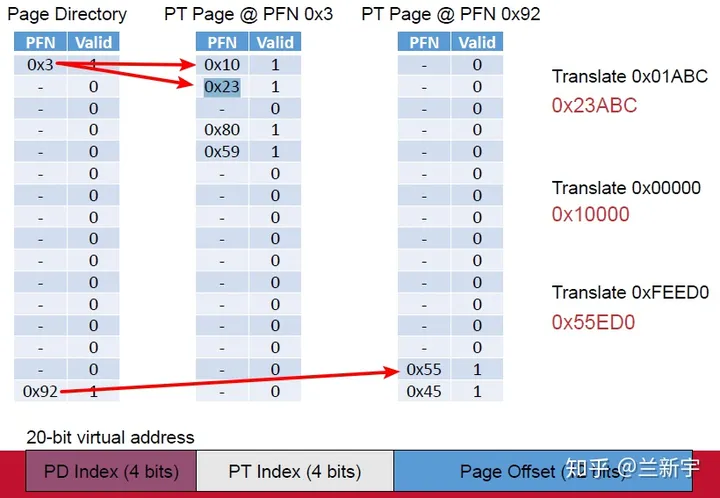
对于虚拟地址0x01ABC,其中“ABC”为page offset, 真正用来转换的只有高8位“0x01”。PD index为0,对应PFN为第一行的0x3,然后找到0x3对应的PT表,PT index为1,对应PFN为第二行的0x23,这样就得到了PPN为0x23,加上page offset就是最后的物理地址0x23ABC。另外两个虚拟地址0x00000和0xFEED0的查找过程也是一样的。
如果真的只有这3个地址所在的page被用到,那么只需要 24+2∗24=48 个entries就可以了,而如果采用单级页表,则需要 28=256 个entries。在32位系统中,进程的虚拟地址空间为4GB,但某个进程实际使用的页只占其中的一小部分,其分布是稀疏的,因此非常适合使用多级页表这种稀疏的级联数组(radix tree)来表示。
多级页表使用现状
在32位处理器中,采用4KB的page大小,则虚拟地址中低12位为page offest,剩下高20位给页表,分成两级,每个级别占10个bit(10+10)。为什么32位系统的页表每级占10位,每个页的大小被设定为4KB而不是2KB或者8KB?
页表本身也是放在内存中的,也要占用内存空间,如果index为10位,则其可索引的范围是1024个entris,32位系统中,每级页表的每个entry的大小为4个字节,则每个页表的大小刚好是4KB。页表首地址也是要按页对齐的,如果占不满一个页,页中剩下的空间也就浪费了。80386引入分页机制的时候应该就考虑过把页设置为多大是最合适的,显然4KB的页大小对内存的利用是最充分的。
对于intel的PAE(Physical Address Extension)模式,支持32位虚拟地址(为了保持和普通32位系统的程序兼容性)和36位物理地址,采用三级页表(2+9+9)。对于64位处理器,intel的IA32-e(x86-64)和ARMv8-A最开始都是只使用低48位,因而剩下中间的36位给页表,分成四级页表,每个级别占9个bit(9+9+9+9)。
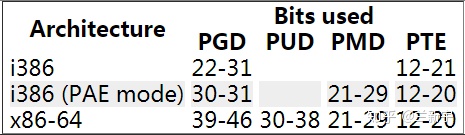
之前intel的手册中称这3种paging模式分别为32-bit paging,PAE paging和IA-32e paging,但现在的IA-32e已经支持使用低57位的五级页表模式,每个级别依然占9个bit(9+9+9+9+9),所以IA-32e paging被改成为4-level paging【1】。
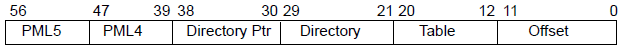
为什么64位系统的页表每级占9位呢?为了和硬件配合,基于i386编写的linux也采用4KB的页大小作为内存管理的基本单位。处理器进入64位时代后,其实可以不再使用4KB作为一个页帧的大小,但可能为了提供硬件的向前兼容性以及和操作系统的兼容性吧,大部分64位处理器依然使用4KB作为默认的页大小(ARMv8-A还支持16KB和64KB的页大小)。因为64位系统中,每级页表的每个entry的大小为8个字节,如果index为9位,则每个页表的大小也刚好是4KB。
那为什么64位系统就要采用四级或者五级页表,而不是和32位系统一样采用两级页表呢?我们来试下如果采用两级页表会怎样。以采用48位虚拟地址为例,中间的36位若分给两级页表,则每级页表占18位(18+18),那么每级页表需要多达 218 (262144)个entries。其实多级页表可理解位一种时间换空间的技术,所以设计每级页表具体占多大,就是一种时间和空间的平衡。
每级页表指向的下一级都是按页对齐的,因此低12位就被空了出来。如果是采用48位虚拟地址的64位系统,则高16位也被空了出来。

这些空余的位空间可以被作为各种flag标识利用起来,关于这些flag的使用,请参考这篇文章。
操作系统支持
为了支持处理器的四级页表模式,linux内核在之前PGD(page global directory),PMD(page middle directory),PTE(page table entry)三级页表的基础上,于2005年release的2.6.11版本加入了PUD(page upper directory) 。
为了支持处理器的五级页表模式,又于2017年release的4.12版本加入了P4D。PGD依然是顶层目录(关于为什么是向内插而不是向外插,请参考这篇文章),通过进程的mm_struct结构体获取到。当发生进程切换时,换入进程的页表的PGD的物理地址被装入CR3(for x86)/TTBRx(for ARM)寄存器中。关于linux中页表的具体实现和使用,请参考这篇文章。
多级页表访问优化
使用多级页表的方式对于减少页表自身占用的内存空间确实是非常有效的。然而,为此付出的代价就是增加了地址转换过程中对内存的访问次数,进而增加了转换时间。那在除了前面介绍的TLB之外,还有哪些可以减少内存访问次数,加快地址转换的方法呢?
一个是使用大页(large page),一个是使用paging structure caches,具体将在本系列之后的文章介绍。
注【1】:从level的编号上看,是越高位bits的level编号越大,而在ARM里这是反过来的。不知是有意还是无意,x86里是数字越低代表特权级越高(ring 0 ~ ring3),而ARM里也是反过来的(EL0 ~ EL3)。
说明:本文部分例子来自 https://compas.cs.stonybrook.edu/~nhonarmand/courses/fa17/cse306/slides/06-paging.pdf
参考:
[1] Four-level page tables
[2] Five-level page tables
[3] intel官方手册《5-Level Paging and 5-Level EPT》
[4] https://www.kernel.org/doc/Documentation/x86/x86_64/5level-paging.txt,讲linux中如何配置使用五级页表的。
什么是SMMU?
SMMU(system mmu),是I/O device与总线之间的地址转换桥。
它在系统的位置如下图:
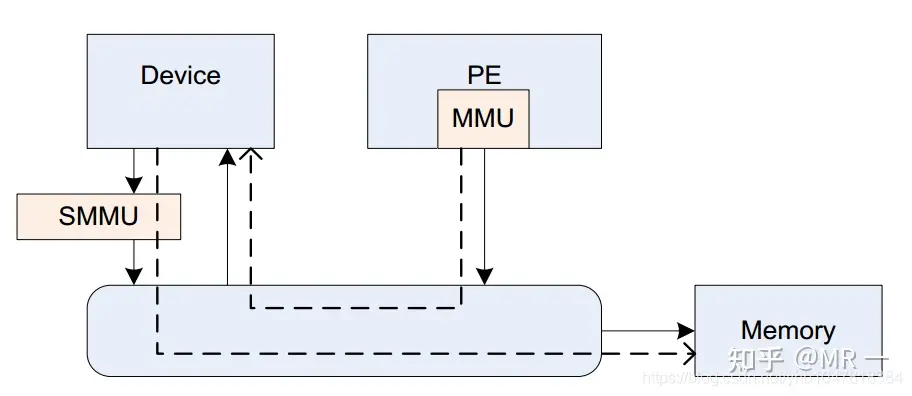
它与mmu的功能类似,可以实现地址转换,内存属性转换,权限检查等功能。
2. 为什么需要SMMU?
了解SMMU出现的背景,需要知道系统中的两个概念: DMA和虚拟化。
DMA:((Direct Memory Access),直接内存存取, 是一种外部设备不通过CPU而直接与系统内存交换数据的接口技术 。外设可以通过DMA,将数据批量传输到内存,然后再发送一个中断通知CPU取,其传输过程并不经过CPU, 减轻了CPU的负担。但由于DMA不能像CPU一样通过MMU操作虚拟地址,所以DMA需要连续的物理地址。
虚拟化: 在虚拟化场景, 所有的VM都运行在中间层hypervisor上,每一个VM独立运行自己的OS(guest OS),Hypervisor完成硬件资源的共享, 隔离和切换。
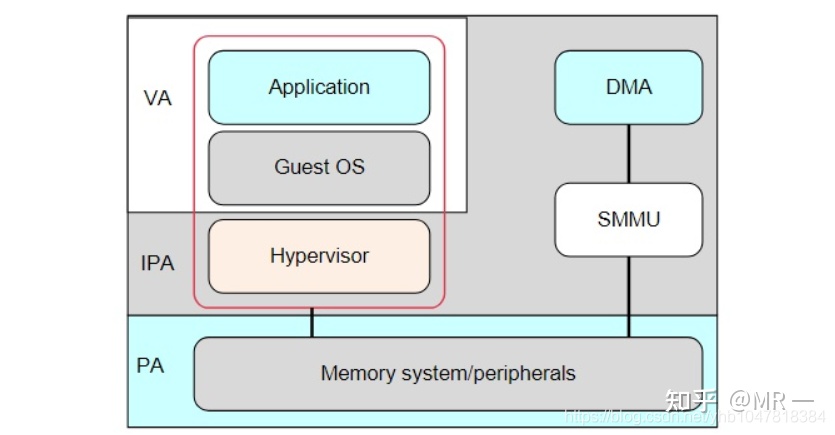
但对于Hypervisor + GuestOS的虚拟化系统来说, guest VM使用的物理地址是GPA, 看到的内存并非实际的物理地址(也就是HPA),因此Guest OS无法正常的将连续的物理地址分给硬件。
因此,为了支持I/O透传机制中的DMA设备传输,而引入了IOMMU技术(ARM称作SMMU)。
总而言之,SMMU可以为ARM架构下实现虚拟化扩展提供支持。它可以和MMU一样,提供stage1转换(VA->PA), 或者stage2转换(IPA->PA),或者stage1 + stage2转换(VA->IPA->PA)的灵活配置。
*[VA:虚拟地址; IPA: 中间物理地址; PA:物理地址]
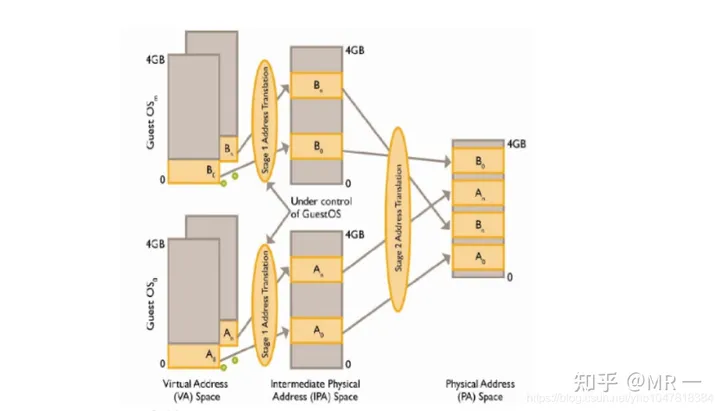
3. SMMU常用概念
术语概念
StreamID 一个平台上可以有多个SMMU设备,每个SMMU设备下面可能连接着多个Endpoint, 多个设备互相之间可能不会复用同一个页表,需要加以区分,SMMU用StreamID来做这个区分( SubstreamID的概念和PCIe PASID是等效的)
STE Stream Table Entry, STE里面包含一个指向stage2地址翻译表的指针,并且同时还包含一个指向CD(Context Descriptor)的指针.
CD Context Descriptor, 是一个特定格式的数据结构,包含了指向stage1地址翻译表的基地址指针
4. SMMU数据结构查找
SMMU翻译过程需要使用多种数据结构,如STE, CD等。
4.1 SID查找STE
Stream Table是存放在内存中的一张表,在SMMU驱动初始化时由驱动程序创建好。
Stream table有两种格式,一种是Linear Stream Table, 一种是2-level Stream Table.
1. Linear Stream Table
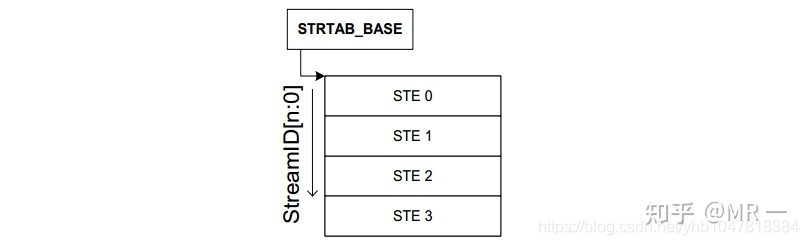
Linear Stream Table是将整个stream table在内存中线性展开成一个数组, 用Stream Id作为索引进行查找.
Linear Stream Table 实现简单,只需要一次索引,速度快; 但是平台上外设较少时,浪费连续的内存空间。
2. 2-level Stream Table
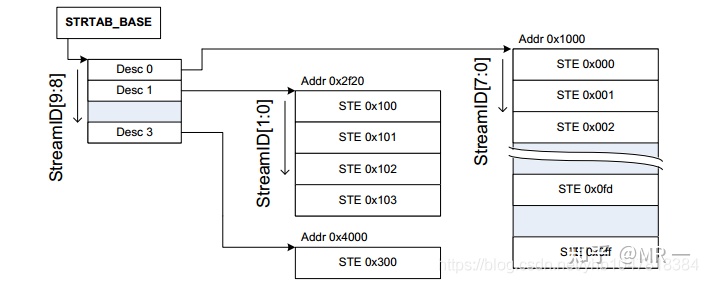
2-level Stream Table, 顾名思义,就是包含2级table, 第一级table, 即STD,包含了指向二级STE的基地址STD。 第二级STE是Linear stream Table. 2-level Stream Table的优点是更加节省内存。
SMMU根据寄存器配置的STRTAB_BASE地址找到STE, STRTAB_BASE定义了STE的基地值, Stream id定义了STE的偏移。如果使用linear 查找, 通过STRTAB_BASE + sid * 64(一个STE的大小为64B)找到STE; 若使用2-level查找, 则先通过sid的高位找到L1_STD(STRTAB_BASE + sid[9:8] * 8, 一个L1_STD的大小为8B), L1_STD定义了下一级查找的基地址,然后通过sid 找到具体的STE(l2ptr + sid[7:0] * 64).
最终找到的STE如下所示,表中的信息包含属性相关信息, 翻译模式信息(是否 stream bypass, 若否,选择stage1, stage2或者stage1 + stage2翻译模式)。
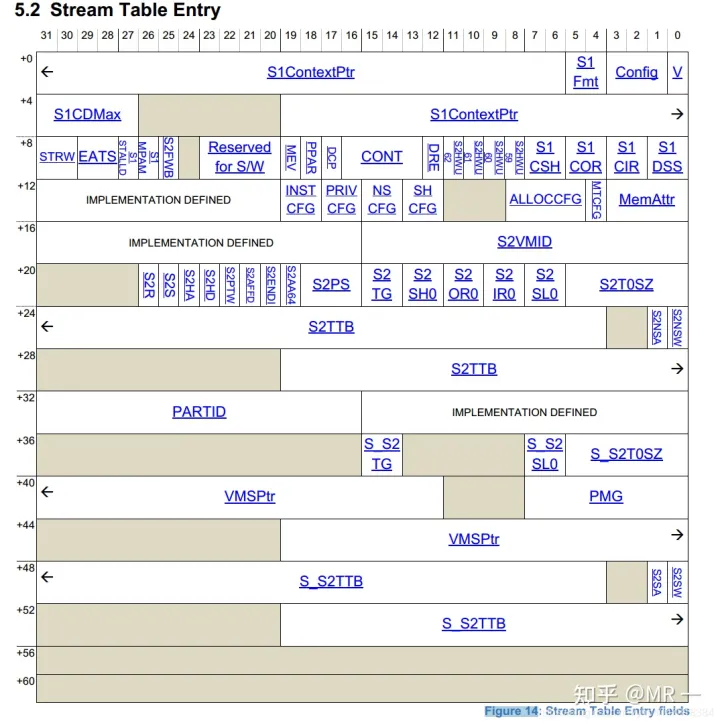
找到STE后可以进一步开始S1翻译或S2翻译.
4.2 SSID查找CD
CD包含了指向stage1地址翻译表的基地址指针.
如下图所示, STE指明了CD数据结构在DDR中的基地址S1ContextPTR, SSID(substream id)指明了CD数据结构的偏移,如果SMMU选择进行linear, 则使用S1ContextPTR + 64 * ssid 找到CD。如果SMMU选择2-level, 则使用ssid进行二级查找获得CD(与上节STE的方式一致)。
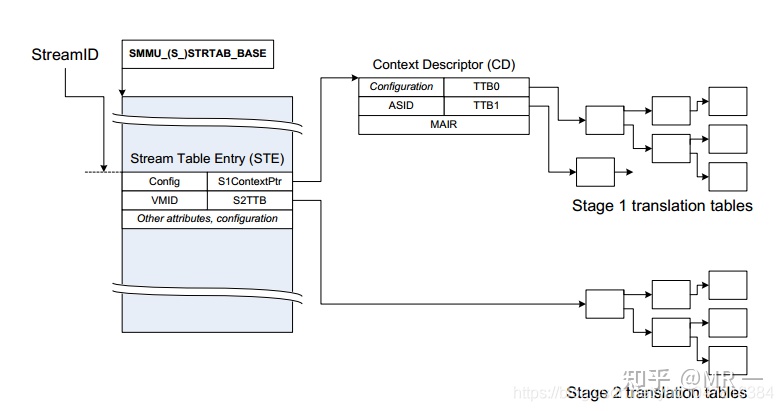
关键点:
StreamID: device 通过物理线连接到SMMU ,这个StreamID就是用来标识SMMU上连接的设备。想象一个8 ports hub上连接了8个物理设备,这8个设备就可以通过portID来标识,比如port 0代表第一个设备,同理steamID
STE: stream Table Entry,可以理解为SMMU页表转换的第一级索引,每一个streamID代表着一个STE,通过这个STE指向的连接可以找到真正的虚地址==》物理地址转换的页表。假设SMMU上连接着8个具体设备,每个设备都有自己的StreamID,那就有至少8个STE表项。
CD: Context Descriptor, stage 1的页表配置项,它其中的TTB0指向了真正的页表信息,比如PGD, PMD, PTE等,完全和MMU的页表转换原理一样
查找过程:
假设stream ID为16的设备发起了DMA操作(如下动作完全自动完成,前提是之前配置好了SMMU中所有的表项):
StreamID=16, 所以从寄存器strtab_base指向的地址中找到偏移为16的STE表项
该表项中的s1ContexPtr指向了下一级的stage 1转换地址CD(Context Descriptor)
CD中的TTB0指向了一个页表转换的基地址PGD
PGD-àPMD-àPTE 完成了虚拟地址到物理地址的转换(和MMU工作原理一样)
注:
其中引入的VMID, ASID的原因和MMU一样,都是为了在TLB中加于区别,防止cache bouncing
Stage2 的转换原理基本和Stage 1一致,不过没有额外的CD
由于懒,文中有些图从网上直接扣的,抱歉。如有侵权,请告知
参考:
————————————————
版权声明:本文为CSDN博主「finicswang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/FinicsWang/article/details/96107339
最终找到的CD如下所示:

表中信息包含memory属性,翻译控制信息,异常控制信息以及Page table walk(PTW)的起始地址TTB0, TTB1, 找到TTBx后,就可以PTW了。
5. SMMU地址转换
5.1 单stage的地址转换:
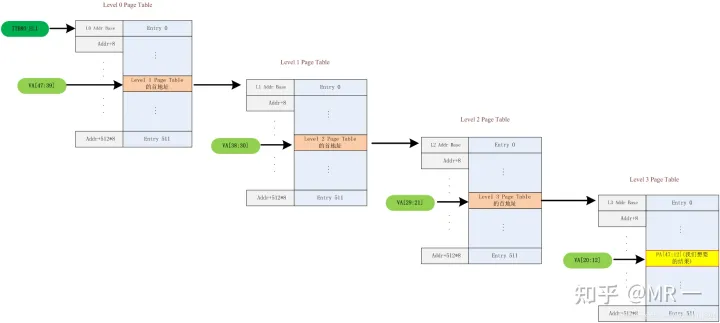
TTB 和 VA[47:39]组成获取Level0页表的地址PA;
Level0页表中的next-level table address 和 VA[38:30]组成获取Level1的页表地址PA;
Level1页表中的next-level table address 和 VA[29:21]组成获取Level2的页表地址PA;
Level2页表中的next-level table address 和 VA[20:12]组成获取Leve3的页表地址PA;
level3页表中的output address和va[12:0]组成获取组后的钻换地址
在stage1地址翻译阶段:硬件先通过StreamID索引到STE,然后用SubstreamID索引到CD, CD里面包含了stage1地址翻译(把进程的GVA/IOVA翻译成IPA)过程中需要的页表基地址信息、per-stream的配置信息以及ASID。 在stage1翻译的过程中,多个CD对应着多个stage1的地址翻译,通过Substream去确定对应的stage1地址翻译页表。 所以,Stage1地址翻译其实是一个(RequestID, PASID) => GPA的映射查找过程。
5.2 stage1+stage2的地址转换:
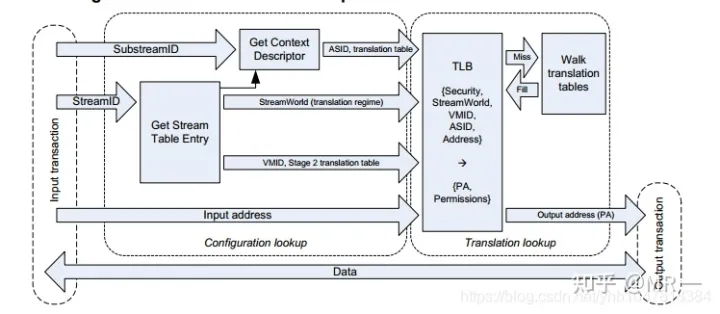
在使能SMMU两阶段地址翻译的情况下,stage1负责将设备DMA请求发出的VA翻译为IPA并作为stage2的输入, stage2则利用stage1输出的IPA再次进行翻译得到PA,从而DMA请求正确地访问到Guest的要操作的地址空间上。
在stage2地址翻译阶段:STE里面包含了stage2地址翻译的页表基地址(IPA->HPA)和VMID信息。 如果多个设备被直通给同一个虚拟机,那么意味着他们共享同一个stage2地址翻译页表。
在两阶段地址翻译场景下, 地址转换流程步骤:
Guest驱动发起DMA请求,这个DMA请求包含VA + SID前缀
DMA请求到达SMMU,SMMU提取DMA请求中的SID就知道这个请求是哪个设备发来的,然后去StreamTable索引对应的STE
从对应的STE表中查找到对应的CD,然后用ssid到CD中进行索引找到对应的S1 Page Table
IOMMU进行S1 Page Table Walk,将VA翻译成IPA并作为S2的输入
IOMMU执行S2 Page Table Walk,将IPA翻译成PA,地址转化结束。
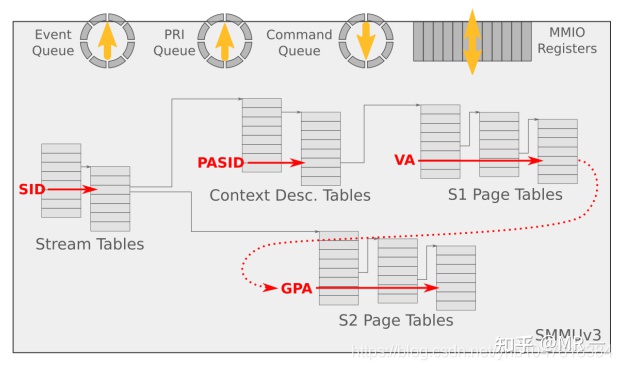
6. SMMU command queue 与 event queue
系统软件通过Command Queue和Event Queue来和SMMU打交道,这2个Queue都是循环队列。
Command queue用于软件与SMMU的硬件交互,软件写命令到command queue, SMMU从command queue中 地区命令处理。
Event Queue用于SMMU发生软件配置错误的状态信息记录,SMMU将配置错误信息写到Event queue中,软件通过读取Event queue获得配置错误信息并进行配置错误处理。
作者:coolboy
链接:https://www.zhihu.com/question/594833508/answer/3003968094
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在SMMU中,TBU(Translation Buffer Unit)和TCU(Translation Control Unit)是两个子模块,分别用于地址翻译和翻译控制。
TBU负责执行虚拟地址到物理地址的转换,并将转换结果存储在缓存中,以便在后续的访问中使用。外设访问主存时,SMMU会首先将虚拟地址发送给TBU进行翻译,然后将物理地址传递给TCU进行权限控制。
TCU负责检查物理地址的权限信息,以确保访问是合法的。如果访问被允许,TCU将传递访问请求给外设或系统内存。否则,TCU将拒绝访问请求并引发异常。
在虚拟化系统中,由于存在多个虚拟机(VM),每个虚拟机都有自己的虚拟地址空间,因此需要使用多个TBU来独立管理每个虚拟机的地址转换。而在同一时间只有一个TCU,是因为TCU主要负责翻译控制,而不是地址转换,因此只需要一个TCU来处理多个虚拟机的权限控制。
在虚拟化系统中,每个虚拟机的TBU都会维护自己的地址转换缓存,并将转换结果发送给共享的TCU进行权限检查。当外设访问请求时,SMMU会根据请求所属的虚拟机选择相应的TBU进行地址转换,并将转换结果与虚拟机的权限信息一起传递给TCU进行权限检查。如果访问被允许,TCU将会转发请求给相应的外设或系统内存,否则会引发异常。
因此,虚拟化系统中的多个TBU和共享的TCU之间的关系是,多个TBU负责管理不同虚拟机的地址转换,而共享的TCU负责检查所有虚拟机的权限信息,并控制转发请求。这种设计可以有效提高虚拟化系统的性能和安全性。
7. 参考资料
虚拟化技术 - I/O虚拟化(一)
IHI0070_System_Memory_Management_Unit_Arm_Architecture_Specification
ARMv8 Virtualization Overview
————————————————
版权声明:本文为CSDN博主「Hober_yao」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。

















 2402
2402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









