









RNN(recurrent neural network)(一)——基础知识
RNN系列博客:
- RNN(recurrent neural network)(一)——基础知识
- RNN(recurrent neural network)(二)——动手实现一个RNN
这篇博客主要介绍一下RNN的基础知识,如果你对RNN已经很了解了,想动手自己撸个RNN加深下理解,那么直接转到 RNN(recurrent neural network)(二)——动手实现一个RNN。RNN主要用于处理序列数据,因此在NLP领域发挥了巨大的影响,被广泛用于语言模型、语音识别、机器翻译等领域。RNN的基础主要包括以下几个部分:
- RNN基本结构
- RNN公式原理
- 常见的几种RNN结构
一、RNN基本结构
RNN的基本架构如下图所示:
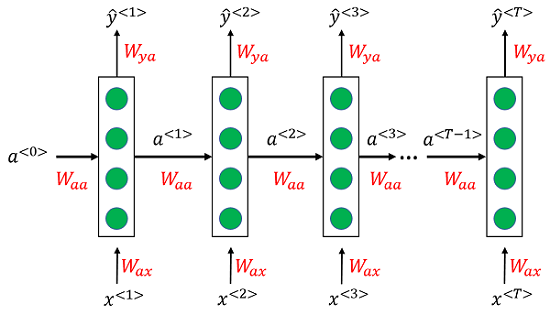

从图一能够看出RNN是个序列模型,
a
<
0
>
a^{<0>}
a<0>一般初始化为全0的向量。其实RNN模型对于初学者来说可能会比较疑惑,因此这里我想尽量的描述细致一点,让路过的同学看的轻松些。首先,第一个要注意的点:上面的图也显示了RNN在每一个时间戳
t
t
t 它的参数是相同的,也就是大家通常所说的参数共享,因此RNN实际上只有三个参数,即
W
a
x
、
W
a
a
、
W
y
a
W_{ax}、W_{aa}、W_{ya}
Wax、Waa、Wya,因此RNN的结构又可以华成图二的形式。这一点和我们熟知的MLP、CNN每一层的参数都不一样是不同的。每一个时间戳
t
t
t的输入、输出构成一个cell,图一忽略省略的部分,共有4个cell,一般cell的个数输入的序列长度相同。
下面来看看单独一个cell的内部构成,这个图就直接盗用ng deep learning课的图了(图片出处:Andrew ng 《sequence model》):

两个输入分别是:当前时刻的输入样本 x < t > x^{<t>} x<t>和上一个cell激活函数的输出 a < t − 1 > a^{<t-1>} a<t−1>,两个输出是 y ^ < t > \widehat{y}^{<t>} y <t>(也就是当前时刻的输出)和 a < t > a^{<t>} a<t>(同样也是下一个cell(下一时刻)的输入)。因此RNN实际上在 t t t时刻得到的结果是基于前 t t t个输入的,最原始的RNN也就是这种单向的只能够利用前面的信息,但是有时候单向的RNN很难解决问题,比如下面这个例子(例子来自ng 《sequence model》):
He said, “Teddy Roosevelt was a great president”.
He said, " Teddy bears are on sale".
如果需要判断 Teddy 是人还是动物,这个例子如果仅仅用单向的RNN(只利用前面的信息)是很难判断出来的,但如果用到后面的信息,比如 president 则很容易判断出第一句话里的Teddy是人。扯远了,关于双向RNN暂时不在这篇文章的讨论范围之内。
RNN结构更加细致的描述
看了上面的介绍,应该对RNN的结构有个基本的了解了,但是对于初学者,仅仅看上面的结构还是会很懵逼,会产生很多疑问,比如:1、如果你在用TensorFlow/Keras等框架时发现RNN cell要设置隐藏单元的数量,是不是会很懵逼?2、如果要处理一句话,RNN的输入
x
<
1
>
、
x
<
2
>
、
.
.
.
、
x
<
T
>
x^{<1>}、x^{<2>}、...、x^{<T>}
x<1>、x<2>、...、x<T>到底是什么?
先回答第二个问题,假如我们的输入一个句子,这个每个输入实际上是个单词,但是要先把单词转化为词向量(比如one-hot或者embedding),因此RNN的输入
x
<
t
>
x^{<t>}
x<t>是个向量,而输入
X
X
X则是个三维矩阵
[
n
x
,
m
,
T
x
]
[n_x, m, T_x]
[nx,m,Tx],其中
n
x
n_x
nx是词向量的维度,
m
m
m是样本数量,
T
x
T_x
Tx是句子长度(句子单词的个数)。再回到第一个问题,我们都知道MLP和CNN每一层都有一定数量的隐藏单元,那么RNN的隐藏单元是什么鬼?直接看下面这个图吧:

因此一点RNN cell中的隐藏单元数量确定后,每个cell里的隐藏单元数目都是相等的,因为它们共享权重矩阵 W a x 、 W a a 、 W y a W_{ax}、W_{aa}、W_{ya} Wax、Waa、Wya。因此,你完全可以把RNN的每个cell理解为一个复制过程。知乎上Scofield(用户id)对RNN结构讲的也很好,大家可以参考一下:Scofield对RNN结构的讲解
二、RNN公式原理
讲到RNN的公式原理,这里只讲前向传播和损失函数,后向传播留在《RNN(recurrent neural network)(二)——动手实现一个RNN》里讲解。
还是在看下这个图吧:
RNN的前向传播公式为:
a
<
t
>
=
t
a
n
h
(
W
a
x
x
<
t
>
+
W
a
a
a
<
t
−
1
>
+
b
a
)
a^{<t>} = tanh(W_{ax}x^{<t>} + W_{aa}a^{<t-1>} + b_a)
a<t>=tanh(Waxx<t>+Waaa<t−1>+ba)
y
^
<
t
>
=
s
o
f
t
m
a
x
(
W
y
a
a
<
t
>
+
b
y
)
\widehat{y}^{<t>} = softmax(W_{ya}a^{<t>} + b_y)
y
<t>=softmax(Wyaa<t>+by)
上面全都是矩阵乘法(不是点乘),下面来看看每个矩阵的维度,假设cell里hidden unit的个数为 n a n_a na,词向量的维度为 n x n_x nx,softmax输出个数为 n y n_y ny,则各个矩阵的维度如下:

以上就是对RNN基础知识的介绍,
RNN有一个非常大的缺点:就是会存在梯度消失和梯度爆炸的问题,因此LSTM就是为了解决RNN的梯度消失而提出的,RNN之所以存在梯度消失问题是因为bp时链式法则导致的,如果偏导小于1,如果网络很深连乘后会使得梯度无限趋向于0,因而导致梯度消失。而梯度爆炸问题则可以用梯度裁剪来实现(clipping gradient),关于梯度裁剪会在下一篇博客中《RNN(recurrent neural network)(二)——动手实现一个RNN》详细的介绍以及实现。
三、常见的RNN结构
常见的RNN结构有:多对多结构(常用于机器翻译)、多对一结构(常用与情感分析)、一对一结构、一对多结构(音乐生成)。下面是这几种结构的示意图:




关于RNN的综述可参考论文《Recent Advances in Recurrent Neural Networks》,机器之心对这篇论文做了翻译,参见:从90年代的SRNN开始,纵览循环神经网络27年的研究进展。















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









