









回头重新看正则化相关的知识,又了一些新的感悟。
1. 为什么要有正则化?
1.1 学习问题本质
当我们训练一个模型的时候,需要知道预测结果的好坏。用#损失函数#度量模型一次预测好坏,用#风险函数#度量模型平均预测好坏。风险函数也称#期望风险#,是损失函数的期望,即是模型关于联合分布P(X,Y)的平均意义下的损失。联合分布是未知的、想通过学习得到的,所以学习问题就变成了一个病态问题。
1.2 解决方法
对于上述病态问题,当样本量足够大时,我们可以根据大数定理,用#经验风险#近似替代#期望风险#。当样本量有限时,可以通过先对经验风险进行一些矫正然后再替代期望风险。矫正的方法有两种,一是经验风险最小化,二是结构风险最小化。而结构风险最小化等价于正则化。
2.正则化项L1范数与L2范数
大牛的博客已经从很多方面介绍了
范数规则化相关知识。但是他在谈到L1和L2区别时,通过函数曲线说“Lasso的图看起来像ridge,而ridge的图看起来像lasso”,我觉得有失大牛一贯严谨的作风。因为ridge的由来是在讲解回归问题时介绍的。这里我再补充一下。
2.1 岭回归
从题目名字就可以看出,岭回归挂边回归问题。最先它是用来处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。为什么会提到特征数和样本数呢?因为我们在解决机器学习的一个大类问题:回归。说到回归,一般都指线性回归,即可以将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归一般采用平方误差作为损失函数(原因见相关专题博客),如下:
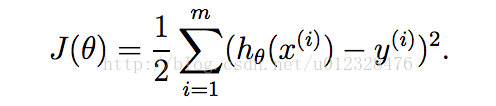
通过矩阵求解可以得到的最佳估计参数形式如下:
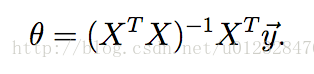
这种求解方法比较快,但是条件也更苛刻:逆矩阵必须存在,即要求矩阵X必须是满置矩阵(样本数多于特征数)。所以,当X不是满置矩阵时,我们可以通过加入一个乘以常量lambda的单位矩阵,使得矩阵非奇异,进而得到最佳估计值:
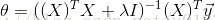
单位矩阵中,只有对角线值为1,其余的是0,像是在0构成的平面中有一条1组成的岭,这就是岭回归的由来。
在增加约束的条件下,普通的OLS法回归会得到与岭回归一样的公式:
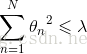
上式限定了所有回归系数的平方和不能大于lambda,避免出现很大正数或者很大负数的情况。这种通过引入lambda来限制系数可以减少不重要的参数,达到缩减(shrinkage)的效果。此时优化目标为:
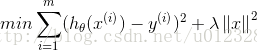
2.2 Lasso
除了ridge,lasso也是一种缩减方法,它对回归系数的限制为是指绝对值的和小于lambda
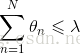
在lambda足够小的时候,一些系数会等于0.在该约束条件下求解回归系数时,需要使用二次规划算法,计算很复杂。此时优化目标为:
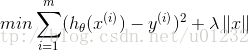
前向逐步回归算法可以得到与lasso差不多的效果,但是更为简单,在此不做更多介绍。















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









