







背景
上篇博客尝试了数据增强,取得了不错的效果,但是结果仍旧不是特别好。所以这次又从训练的角度进行了一些优化,包括:
- BatchNorm
- 使用变化的学习率
- 继续增加epoch
最终实验结果还是非常棒的,代码和结果如下。目前已经没有动力继续训练了,因为原则上的方法基本上都已经考虑到了。后续如果要继续改进,无非换更深的网络(利用ResNet18),和增加更多的迭代次数。
https://www.kaggle.com/yannnnnnnnnnnn/kernel5d66c76231?scriptVersionId=28281919
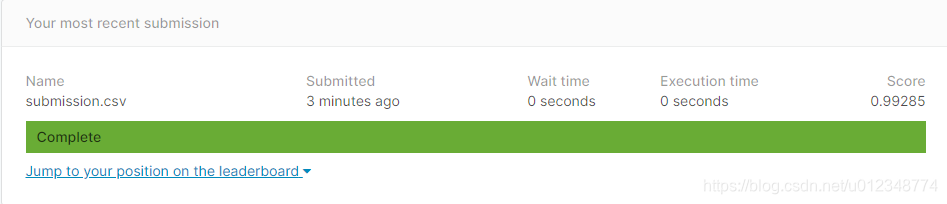
方法
1、增加BatchNorm
关于BatchNorm的原理,此处就不展开介绍了,可以参考《Dive into DL PyTorch》;其作用主要是防止模型的过拟合,提高泛化能力。
代码如下,只需要简单的在代码里添加 nn.BatchNorm2d(num_feature)和nn.BatchNorm1d(num_feature)即可。
class YANNet(nn.Module):
def __init__(self):
super(YANNet,self).__init__()
self.conv = nn.Sequential(
# size: 28*28
nn.Conv2d(1,8,3,1,1), # in_channels out_channels kernel_size stride padding
nn.BatchNorm2d(8),
nn.ReLU(),
nn.Conv2d(8,16,3,1,1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2),
# size: 14*14
nn.Conv2d(16,16,3,1,1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.Conv2d(16,8,3,1,1),
nn.BatchNorm2d(8),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
# size: 7*7
nn.Linear(8*7*7,256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256,256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256,10)
)
def forward(self, img):
x = self.conv(img)
o = self.fc(x.view(x.shape[0],-1))
return o
2、使用变化的学习率
稍微搞过梯度下降的人都知道,固定的学习率并不是什么好主意,因为最好的思路是使用一个可以自动变化的学习率。在PyTorch中,对应的代码也非常简单,如下。只需要在代码里增加lr_scheduler.StepLR即可,其每间隔step_size个epoch,就将当前的学习率乘上gamma。当然PyTorch还提供了很多别的方法,我也不赘述了。
model = YANNet()
error = nn.CrossEntropyLoss()
if torch.cuda.is_available():
model = model.cuda()
error = error.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
num_epoc = 120
from torch.autograd import Variable
for epoch in range(num_epoc):
epoc_train_loss = 0.0
epoc_train_corr = 0.0
epoc_valid_corr = 0.0
print('Epoch:{}/{}'.format(epoch,num_epoc))
model.train()
scheduler.step() #降低学习率
pass
...
3、增加epoch
考虑到学习率的变化,增加epoch是必然的,目前是num_epoc = 120
结论
总体而言,本次实验还是很有收获的,精度从94%->98%->99%。最后也非常感谢,Kaggle提供的免费GPU,非常方便和好用。














 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









