







Hadoop版本:hadoop-1.2.1
JDK版本:jdk-6u45-linux-x64
Linux版本:CentOS 6.5 64位
登录用户:root
1、虚拟机搭建
我使用了三个节点,依次命名为master、slave1和slave2。在VMware中以NAT模式安装好CentOS 6.5系统的master后,开始利用配置文件创建slave1和slave2。
1.1 复制master的CentOS配置文件
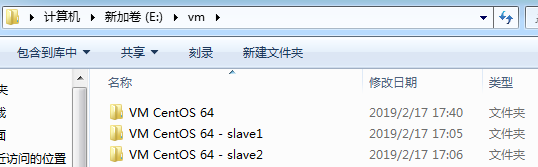
将master的配置文件CentOS 64位.vmx所在的文件夹VM CentOS 64复制两份到根目录下vm,分别命名为slave1和slave2。
配置文件所在的位置可将master挂起后,查看到虚拟机详细信息:
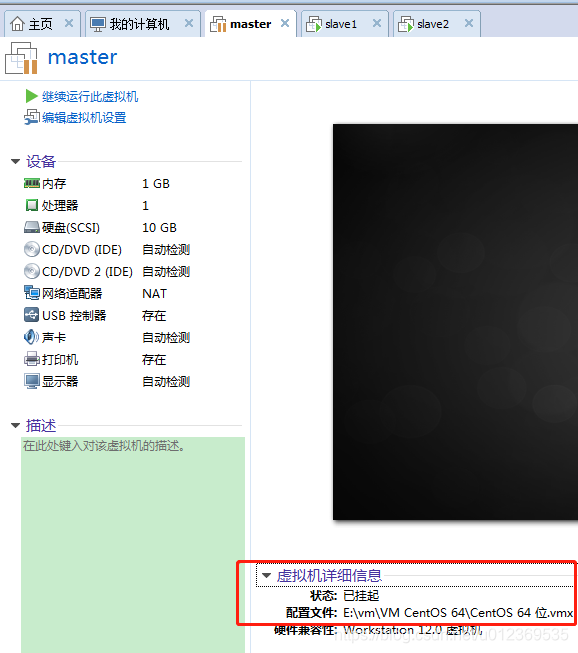
复制后的文件夹:
1.2 利用复制后的配置文件创建slave1和slave2
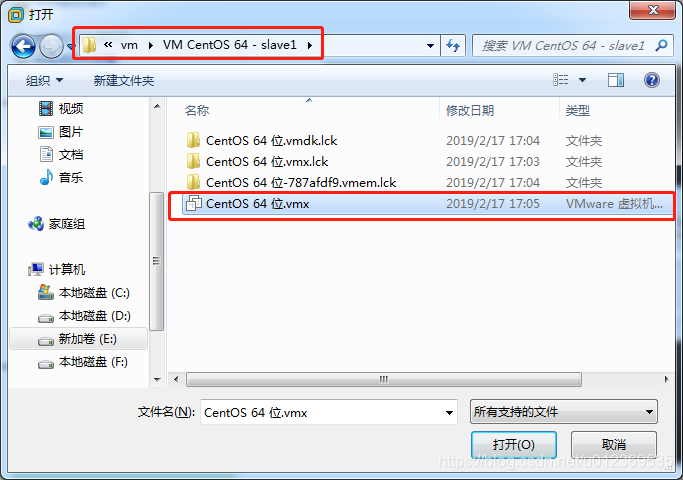
VMware中依次单击“文件”–“打开”,弹出对话框,找到slave1对应的.vmx配置文件,确定,创建复制后的虚拟机,同样的方法创建slave2。
1.3 修改slave1和slave2的网络配置
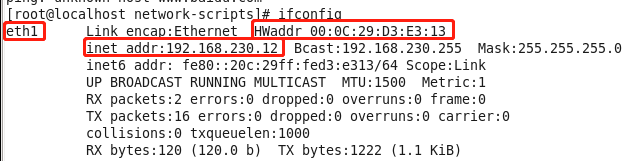
由于slave1和slave2是从master整体复制而来的,其ip地址和网卡均与master相同,必须修改后才能联网。此时在任意虚拟机上执行ifconfig命令可以看到相同的ip地址和网卡信息:
 对于ip地址,直接在/etc/sysconfig/network-scripts/ifcfg-eth0中修改即可,这里slave1为192.168.230.11,slave2位192.168.230.12。
对于ip地址,直接在/etc/sysconfig/network-scripts/ifcfg-eth0中修改即可,这里slave1为192.168.230.11,slave2位192.168.230.12。
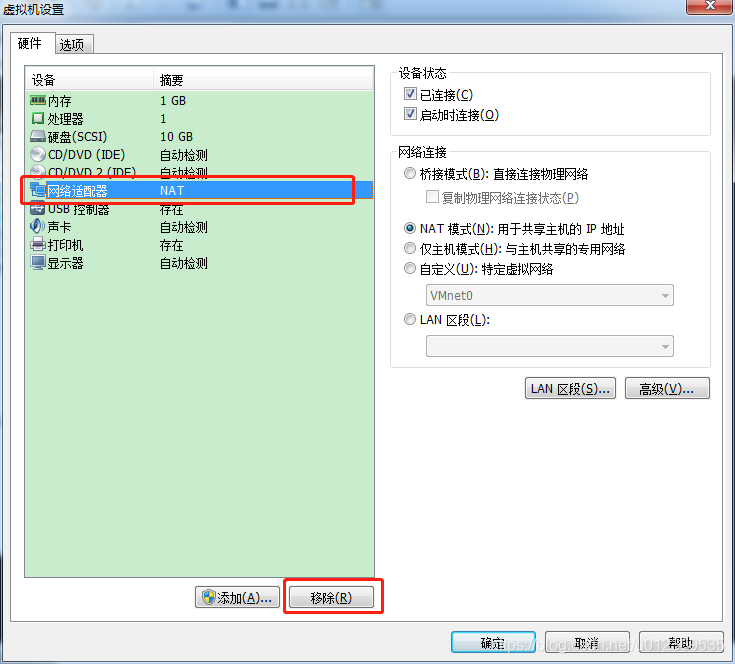
对于网卡,在slave1和slave2的虚拟机设置中,将其网络适配器移除后,再添加即可,此时ip地址和网卡已和master不一样了,可以联网:
2、安装jdk
需要在三台机器master、slave1和slave2上安装jdk,jdk安装包在物理机上,利用VMware共享文件夹的功能,将安装包共享到虚拟机master上,再分发到slave1和slave2上,依次安装。
2.1 设置共享文件夹
对master打开“虚拟机设置”对话框,将物理机上放有jdk安装包和其他程序包的文件夹share folder设置为共享:
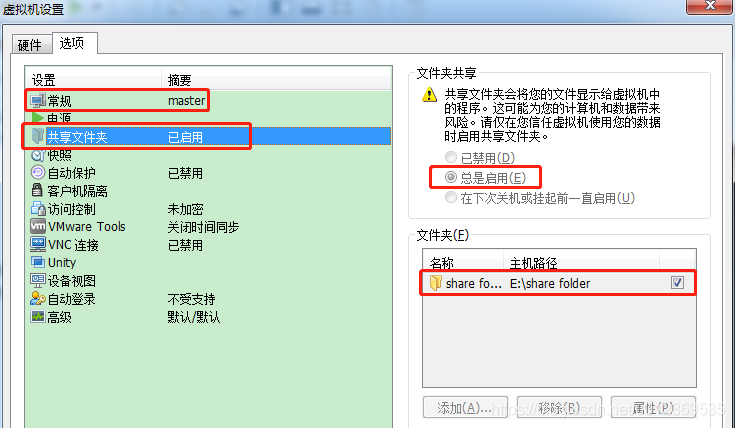
共享后,可在master的/mnt/hgfs下看到共享文件夹share folder,利用cp命令将安装包复制到/usr/local/java文件夹下,执行安装。
cd /mnt/hgfs/share folder
cp jdk-6u45-linux-x64.bin /usr/local/java
./jdk-6u45-linux-x64.bin
关于jdk的安装路径,有必要了解linux的软件安装目录,安装程序并不是非要在指定的目录下安装,但从扩展性和管理性上,遵循规则是为了更方便地管理与使用:
这里参考:http://blog.51cto.com/mystery888/1835223
- /usr:系统级的目录,可以理解为C:/Windows/,/usr/lib理解为C:/Windows/System32。
- /usr/local:用户级的程序目录,可以理解为C:/Progrem Files/。主要存放那些手动安装的软件,即不是通过apt-get安装的软件。用户自己编译的软件默认会安装到这个目录下。
- /opt:用户级的程序目录,可以理解为D:/Software,opt有可选的意思,这里可以用于放置第三方大型软件(或游戏)。安装到/opt目录下的程序,它所有的数据、库文件等等都是放在同个目录下面。当你不需要时,直接rm -rf掉即可。在硬盘容量不够时,也可将/opt单独挂载到其他磁盘上使用。举个例子:测试版firefox,就可以装到/opt/firefox_beta目录下,/opt/firefox_beta目录下面就包含了运 行firefox所需要的所有文件、库、数据等等。要删除firefox的时候,你只需删除/opt/firefox_beta目录即可。
- /usr/src:系统级的源码目录。
- /usr/local/src:用户级的源码目录。
2.2 配置环境变量
在root用户的~/.bashrc文件尾行添加如下环境变量:
- export JAVA_HOME=/usr/local/java/jdk1.6.0_45
- export CLASSPATH=.: $ CLASSPATH:$JAVA_HOME/lib
- export PATH=$ PATH:$JAVA_HOME/bin
然后执行以下语句使配置文件生效,完成jdk安装:
source ~/.bashrc
之所以修改~/.bashrc而不是/etc/profile是因为修改/etc路径下的配置文件将会应用到整个系统,属于系统级的配置,而修改用户目录下的.bashrc只是限制在用户应用上,属于用户级设置。两者在应用范围上有所区别,建议如需修改的话,修改用户目录下的.bashrc,即无需root权限,也不会影响其他用户。
3、安装hadoop
3.1 修改主机名(master、slave1和slave2)
第一步:以maser节点为例,修改/etc/sysconfig/network中的hostname=“你的主机名”:

第二步:在/etc/hosts行尾添加三台节点的ip地址和“各自主机名”:

第三步:执行shutdown -r now重启系统即可。
3.2 解压
通过共享文件夹功能将/mnt/hgfs/folder/hadoop-1.2.1-bin.tar.gz复制到master节点的/usr/local/hadoop1,在该路径下利用如下命令解压得到hadoop-1.2.1文件夹:
tar xvzf hadoop-1.2.1-bin.tar.gz
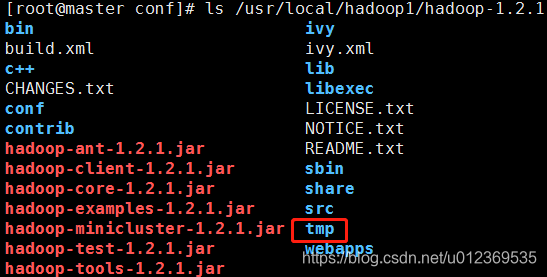
进入hadoop-1.2.1文件夹,建立tmp目录:
3.3 修改配置文件
进入conf目录,依次修改master、slaves、core-site.xml、mapred-site.xml、hdfs-site.xml、hadoop-env.sh配置文件:
- master:

- slaves:

- core-site.xml:

- mapred-site.xml:

- hdfs-site.xml:

- hadoop-env.sh尾行:

注:配置文件中凡是涉及到路径和ip地址的均是填写自己的路径和地址
3.4 从master远程复制到slave1和slave2
在master节点的/usr/local/hadoop1目录下,利用如下语句将hadoop-1.2.1文件夹复制到slave1和slave2对应路径下:
scp -rp hadoop-1.2.1 slave1:/usr/local/hadoop1
scp -rp hadoop-1.2.1 slave2:/usr/local/hadoop1
3.5 关闭防火墙
在每个节点上执行以下语句关闭防火墙:
/etc/init.d/iptables stop
setenforce 0
3.6 建立ssh远程互信
第一步:在master节点上执行下列命令:
ssh-keygen
第二步:在~/.ssh目录下,将id_rsa.pub复制到authorized_keys:
cat id_rsa.pub > authorized_keys
第三步:分别在slave1和slave2节点上执行ssh-keygen命令,将其id_rsa.pub内容复制到master的authorized_keys上:

第四步:将master的authorized_keys远程复制到slave1和slave2上:
scp -rp authorized_keys slave1:~/.ssh/
scp -rp authorized_keys slave2:~/.ssh/
3.7 启动hadoop集群
第一步:在master节点上,进入到/usr/local/hadoop1/hadoop-1.2.1/bin目录下,由于是第一次启动,需要执行以下命令格式化:
[root@master bin]# ./hadoop namenode -format
第二步:启动集群:
[root@master bin]# ./start-all.sh
第三步:在各节点下输入jps命令,master出现JobTracker、NameMode和SecondaryNameNode进程,slave1和slave2出现DataNode和TaskTracker则搭建成功。















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









