






 本文介绍了基于Docker解决AI系统开发痛点,如配置复杂、环境变化等问题。百度PaddlePaddle团队通过创建开发和生产镜像,简化了编译和测试流程。使用开发镜像,开发者只需一键编译,降低了环境配置难度,提高了bug复现效率。文章还展示了如何制作和使用开发、生产镜像,以及在容器中利用Nvidia GPU的实践。
本文介绍了基于Docker解决AI系统开发痛点,如配置复杂、环境变化等问题。百度PaddlePaddle团队通过创建开发和生产镜像,简化了编译和测试流程。使用开发镜像,开发者只需一键编译,降低了环境配置难度,提高了bug复现效率。文章还展示了如何制作和使用开发、生产镜像,以及在容器中利用Nvidia GPU的实践。
作者来自百度PaddlePaddle团队:王鹤麟、于洋、王益
责编:何永灿(heyc@csdn.net),本文来源于《程序员》,未经允许不得转载。
基于深度学习的AI系统是由深度学习框架、AI应用以及服务部署组成的一个闭环。在PaddlePaddle的开发与使用过程中,我们发现框架和AI应用的开发及服务部署,都可以基于Docker完成,让流程简化。
开发痛点
编译工具难配置
编译AI系统需要安装很多工具(PaddlePaddle需要40个工具,TensorFlow需要51个),编译环境很难配置。作为一个开源项目,PaddlePaddle的编译环境必须非常容易配置,这样才会有更多的开发者加入进来。
编译工具不断变化
一个不停迭代的项目往往编译环境也是在不停变化的:比如PaddlePaddle 0.9版本用的是CUDA 7.5,0.10版本是CUDA 8.0,每次都手动更新编译环境非常浪费时间。
问题难以复现
我们在GitHub给开源项目提issue的时候,首先要写运行环境,因为bug和运行环境有关。从用户的角度来讲,回答这些问题很麻烦,有时程序运行在集群上,并不清楚具体环境。从开发者的角度来讲,很难找到相同的环境来复现bug。
解决方案
我们把PaddlePaddle的编译环境打包成一个镜像,称为“开发镜像”,里面涵盖了编译所需的所有工具。把编译出来的PaddlePaddle也打包成一个镜像,称为“生产镜像”,里面涵盖了运行所需的所有环境。PaddlePaddle会发布每个版本的生产及开发镜像。
这样不管开发者用的是macOS,Linux还是Windows,只要安装了Docker都可以编译PaddlePaddle。我们可以把这个开发镜像看作一个程序,以前大家用的是CMake、Make、GCC以及Protobuf编译器这些程序编译。现在用的是这个开发镜像编译。
PaddlePaddle的旧版本基于CMake,新版本基于开发镜像。请对比以下命令:
cd paddle/build; cmake ..; make
cd paddle; docker run -v $(pwd):/paddle paddlepaddle/paddle:latest-dev
第一行是基于CMake的编译方法,用户需要手动配置所有的编译工具。第二行是基于容器的编译方法,用户只用安装Docker就能够一键编译了(“-v”起的作用是将本地的PaddlePaddle repo根目录挂载到容器内,这样容器内就能看到并且编译PaddlePaddle了)。
下面介绍如何使用开发环境镜像。开发者可能会用到自己的笔记本和安装有GPU的工作站。
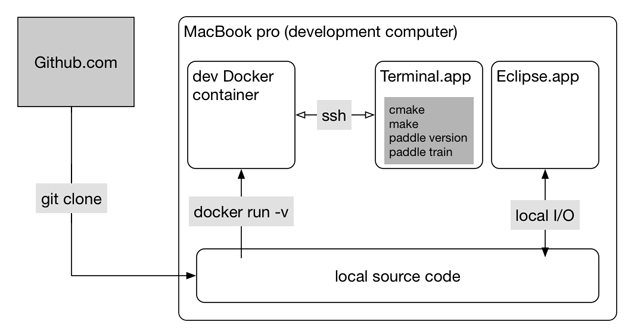
基本思路是: 使用git clone下载PaddlePaddle源码到开发机,然后就可以使用自己最喜欢的编辑器(如IntelliJ/Emacs)开始代码编写工作。编译和测试则可以使用docker run -v挂载源码目录到开发环境镜像,在容器中直接编译和测试刚才修改的代码。我们将在后面的实战部分举例说明。
我们看看痛点能否被解决:
编译工具难配置:编译工具被打包成了一个镜像,配置编译环境的任务被最熟悉编译环境的开发者一次性完成了,其他人不需要重复这个步骤,只用一键运行编译命令就可以。对编译通过可以有充分的信心:容器每次运行的时候环境是完全一致的,每个开发镜像都通过了编译测试。
编译工具不断变化:每次发布新版本我们都会发布对应的开发镜像。切换编译的版本只用切换镜像即可。之前提到的CUDA版本的问题也得到了解决,因为CUDA直接被打包在开发和生产镜像中。在接下来的一节“在容器中使用GPU”中我们会详细介绍CUDA相关的细节。
Bug难以复现:因为PaddlePaddle唯一官方支持的版本是Docker镜像,去掉了编译环境以及运行环境这两大变量,让bug复现变得简单很多。
实战演练
这里我们通过介绍PaddlePaddle的开发和使用来举例说明基于容器的AI系统开发流程。
- 制作开发镜像
生成Docker镜像的方式有两个,一个是直接把容器转换成镜像;另一个是运行docker build指令按照Dockerfile生成镜像。第一个方法的好处是简单快捷,适合自己实验。第二个方法的好处是Dockerfile可以把整个生成流程描述清楚,容易看懂,持续集成系统也可以复现。我们采用第二个方法,Dockerfile位于PaddlePaddle repo的根目录,生成生产镜像只需要运行:
git clone https://github.com/PaddlePaddle/Paddle.git
cd Paddle
docker build -t paddle:dev .
docker build的-t参数指定了生成的镜像的名字。到此,PaddlePaddle开发镜像就构建完毕了。
- 制作生产镜像
生产镜像的生成分为两步,第一步是运行:
docker run -v $(pwd):/paddle -e "WITH_GPU=OFF" -e "WITH_TESTING=ON" paddle:dev以上命令会编译PaddlePaddle,以及生成创建生产镜像的Dockerfile。所有生成的文件都在build目录下。“WITH_GPU”控制生成的生产镜像是否支持GPU,“WITH_TESTING”控制是否生成单元测试程序。
第二步是运行:
docker build -t paddle:prod -f build/Dockerfile ./build以上命令会利用生成的Dockerfile创建名为paddle:prod的生产镜像。
- 运行单元测试
运行以下指令:
docker run -it -v $(pwd):/paddle paddle:dev bash -c "cd /paddle/build && ctest"- 训练模型
运行以下指令:
wget https://raw.githubusercontent.com/PaddlePaddle/book/develop/02.recognize_digits/train.py
docker run -it -v $(pwd)/train.py:/train.py paddlepaddle/paddle python /train.py
以上代码会下载并运行paddlepaddle/paddle镜像。其中train.py是使用mnist数据集训练数字识别的神经元网络代码,我们把它挂载到/train.py,并在容器启动时执行python /train.py进行训练。
以上的命令运行的是CPU版本的PaddlePaddle。如果要运行GPU版本的PaddlePaddle请在装了Nvidia GPU的机器上执行:
nvidia-docker run -it -v $(pwd)/train.py:/train.py paddlepaddle/paddle:latest-gpu python /train.py可以看到两行指令的第一个区别是docker变成了nvidia-docker,这个我们会在下一节详细说明。另一个区别是镜像名字变成了paddlepaddle/paddle:latest-gpu。GPU版本既可以跑GPU又可以跑CPU,但是镜像尺寸会比CPU版大很多,所以PaddlePaddle会同时发布CPU版本和GPU版本的镜像。
- 模型打包
模型训练完毕只是AI系统开发的一个阶段性成果,要完成整个流程还需要把模型打包,部署到线上服务用户。打包是将预测的代码存放到生产镜像中,生成线上使用的镜像。因为这个镜像是基于生产镜像的,所以可以保证线上预测结果与线下训练结果的一致性。同时,打包成镜像也是线上服务被Kubernetes 集群操作系统调度的必要条件。
在容器中使用Nvidia GPU
GPU是许多AI系统的运算核心,这里讨论如何在Docker 中使用Nvidia GPU。因为容器技术是基于Linux Control Groups(CGroups)的,而CGroups对于设备是有原生支持的,所以让容器支持GPU设备应该是一件很容易的事情。而Nvidia 的GPU驱动却让事情变得复杂:一般的设备驱动只有一个kernel object(ko)文件,只要在宿主机上安装驱动,ko文件就会自动被载入内核供容器使用。但是Nvidia的GPU驱动除了ko文件之外还有shared object(so)文件,是用户层的程序,需要在容器内程序运行时被动态加载。并且,ko文件的版本必须与so文件版本一摸一样。
要在容器中找到so文件,我们很自然地想到可以把so文件打包到镜像里,但是在生成镜像的时候我们并不知道宿主机器的GPU驱动是什么版本的,所以无法预先打包对应版本的so文件。另一个方法是运行容器的时候,自动找到宿主系统中的so文件并挂载进来。但是so文件有很多可能的安装路径。这时候nvidia-docker就出现了,为我们把这些细节问题隐藏了起来。使用起来非常的简单,把docker命令换成nvidia-docker即可。
此外还有一个环节需要考虑:CUDA库和cuDNN库。CUDA库用来做CUDA架构下的数值计算,它包含编译时需要的头文件以及运行时需要的so文件。cuDNN是专门为深度学习设计的数值计算库,也是包含头文件与so文件。它们都有很多版本,并且编译时的头文件版本必须与运行时的so文件版本一致。
如果不用容器,这两个库很麻烦,自己编译好的程序可能拿到别人的机器上就因为版本不一致而不能用了。用容器就不会有这个问题,在生成开发镜像的时候我们把CUDA和cuDNN库以及所需的工具都打包了进去,在生产镜像也打包了对应版本的so文件,不会出现版本不一致的问题。运行GPU生产镜像的时候,宿主机器只用安装Nvidia驱动就可,不需要安装CUDA或者cuDNN。
Q&A
基于容器的开发方式怎么使用IDE做文本补全?
难点在于IDE不是运行在容器中的。一般有两种文本补全方式,一种是字符串匹配(譬如Ctags),另一种是词法分析(譬如Rtags)。字符串匹配的补全容易支持,只要将第三方库的头文件放入IDE搜索路径中即可。词法分析的补全方式较复杂,最简单的解决方法是直接在容器内运行Emacs或者Vim编辑代码。
每一次编译必须从头开始吗?
因为编译的时候,所有生成的中间文件都保存在宿主文件系统里的build目录下,下一次编译仍然可以使用这些中间文件,所以每一次编译并非从头开始。
我已经在我的机器上配置好了多个环境:不同GCC版本,ARM架构的cross-compile环境,换到基于容器的编译方式好像很麻烦?
把本地已经设置好的编译环境转换成新的环境肯定比继续使用原有的环境麻烦,但是基于容器的编译方式只要设定好了一次,就非常容易分享给别人,自己重装系统后也可立刻使用。
另外,跨操作系统、架构的cross compile配置起来按编译环境的不同,难易程度也不一样,有些很复杂甚至不支持。因为容器能够运行其他系统及架构的镜像,所以可以直接在编译的目标操作系统与架构的容器里配置编译环境,就不需要花时间配置cross compile了。
作者简介:
- 王鹤麟,百度PaddlePaddle开发组核心成员。从事PaddlePaddle分布式容错计算功能的开发。曾参与百度Deep Speech 2、百度无人车等科研、开发工作。
- 于洋,百度工程师,从事百度深度学习平台PaddlePaddle开发工作。硕士毕业于天津大学,15年毕业后加入百度深度学习实验室。随后一直从事深度学习系统的研发,主要负责深度学习系统的性能优化和功能开发工作。
- 王益,百度PaddlePaddle团队tech lead。2007年从清华大学计算机系博士毕业后加入Google中国任研究员。2010年加入腾讯后任广告技术总监。2014年加入LinkedIn总部任资深主任工程师。是AI创业公司ScaledInference创始科学家。2015年底加入百度。
















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









