









Problem
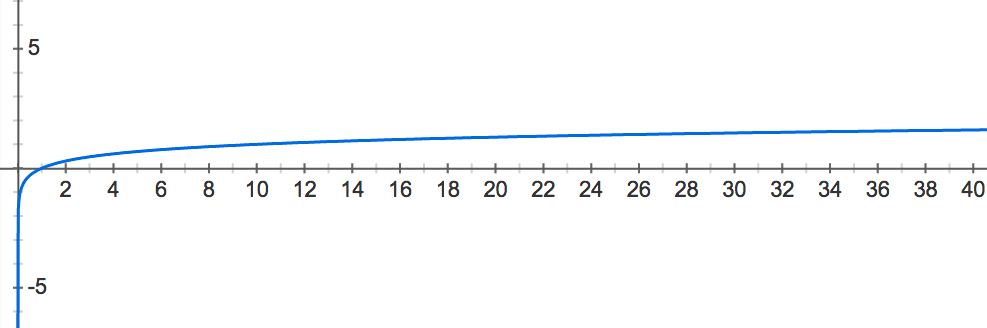
Figure 1. The graph of the common logarithm function of x. For a given x-value, the corresponding y-value is the exponent to which we must raise 10 to obtain x. Note that x-values between 0 and 1 get mapped to y-values between -infinity and 0.
An array is a structure containing an ordered collection of objects (numbers, strings, other arrays, etc.). We let denote the -th value in array . You may like to think of an array as simply a matrix having only one row.
A random string is constructed so that the probability of choosing each subsequent symbol is based on a fixed underlying symbol frequency.
GC-content offers us natural symbol frequencies for constructing random DNA strings. If the GC-content is , then we set the symbol frequencies of C and G equal to and the symbol frequencies of A and T equal to . For example, if the GC-content is 40%, then as we construct the string, the next symbol is 'G'/'C' with probability 0.2, and the next symbol is 'A'/'T' with probability 0.3.
In practice, many probabilities wind up being very small. In order to work with small probabilities, we may plug them into a function that "blows them up" for the sake of comparison. Specifically, the common logarithm of (defined for and denoted ) is the exponent to which we must raise 10 to obtain .
See Figure 1 for a graph of the common logarithm function . In this graph, we can see that the logarithm of -values between 0 and 1 always winds up mapping to -values between and 0: -values near 0 have logarithms close to , and -values close to 1 have logarithms close to . Thus, we will select the common logarithm as our function to "blow up" small probability values for comparison.
Given: A DNA string of length at most 100 bp and an array containing at most 20 numbers between 0 and 1.
Return: An array having the same length as in which represents the common logarithm of the probability that a random string constructed with the GC-content found in will match exactly.
一个阵列是包含对象(数字,字符串,其它阵列等)的有序集合的结构。我们用array表示第-th个值。您可能想将数组视为仅包含一行的矩阵。
甲随机串被使得选择每个后续符号的概率是基于一个固定的底层的符号频率构成。
GC含量为构建随机DNA串提供了自然的符号频率。如果GC含量为,则将C和G 的符号频率设置为,将A和T的符号频率设置为。例如,如果GC含量为40%,则在构造字符串时,下一个符号为'G'/'C'的概率为0.2,下一个符号为'A'/'T'的概率为0.3。
在实践中,很多可能性很小。为了处理较小的概率,为了进行比较,我们可以将它们插入“炸毁”函数中。具体而言,常用对数的(用于定义和表示的)是,这是我们必须提高10以获得指数。
常见对数函数的图表参见图1。在此图中,我们可以看到0到1之间的-value的对数总是映射到-0到-之间的值: -0附近的-值具有接近的对数,-1附近的-值具有接近的对数。因此,我们将选择对数作为函数,以“吹灭”较小的概率值进行比较。
给定:一个长度不超过100 bp的DNA字符串 ,一个数组,最多包含20个介于0和1之间的数字。
返回值:与长度相同的数组 表示在其中找到含有GC内容的随机字符串完全匹配的概率的对数。
Sample Dataset
ACGATACAA
0.129 0.287 0.423 0.476 0.641 0.742 0.783
Sample Output
-5.737 -5.217 -5.263 -5.360 -5.958 -6.628 -7.009














 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









