







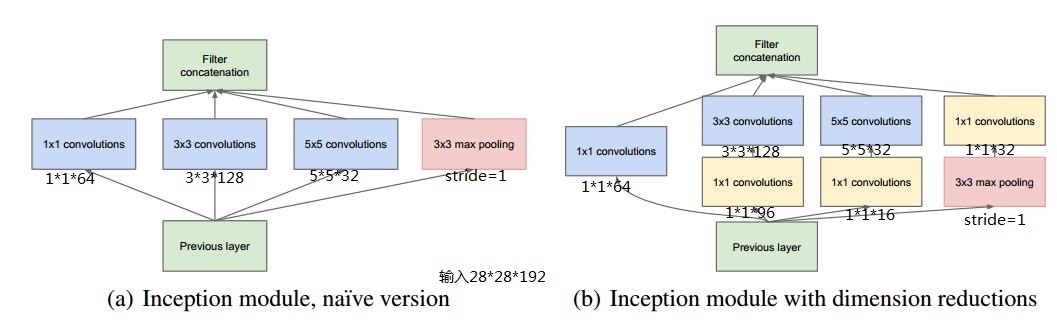
假设previous layer的大小为28*28*192,则,
a的weights大小,1*1*192*64+3*3*192*128+5*5*192*32=387072
a的输出featuremap大小,28*28*64+28*28*128+28*28*32+28*28*192=28*28*416
b的weights大小,1*1*192*64+(1*1*192*96+3*3*96*128)+(1*1*192*16+5*5*16*32)+1*1*192*32=163328
b的输出feature map大小,28*28*64+28*28*128+28*28*32+28*28*32=28*28*256
写到这里,不禁感慨天才般的1*1 conv,从上面的数据可以看出一方面减少了weights,另一方面降低了dimension。
Inception v1的亮点总结如下:
(1)卷积层共有的一个功能,可以实现通道方向的降维和增维,至于是降还是增,取决于卷积层的通道数(滤波器个数),在Inception v1中1*1卷积用于降维,减少weights大小和feature map维度。
(2)1*1卷积特有的功能,由于1*1卷积只有一个参数,相当于对原始feature map做了一个scale,并且这个scale还是训练学出来的,无疑会对识别精度有提升。
(3)增加了网络的深度
(4)增加了网络的宽度
(5)同时使用了1*1,3*3,5*5的卷积,增加了网络对尺度的适应性
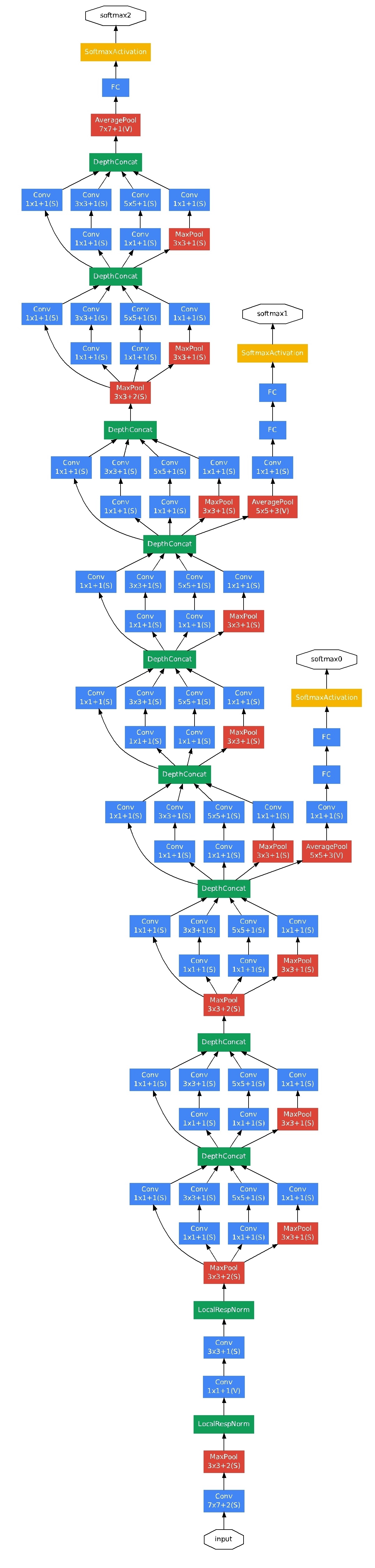
下图为googlenet网络结构:
这里有2个地方需要注意:
(1)整个网络为了保证收敛,有3个loss
(2)最后一个全连接层之前使用的是global average pooling,全局pooling使用的好了,还是有好多地方可以发挥的。
v2:Batch Normalization: Accelerating Deep Network Training by ReducingInternal Covariate Shift
Inception v2的网络,代表作为加入了BN(Batch Normalization)层,并且使用2个3*3替代1个5*5卷积的改进版GoogleNet。
Inception v2的亮点总结如下:
(1)加入了BN层,减少了InternalCovariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,从而增加了模型的鲁棒性,可以以更大的学习速率训练,收敛更快,初始化操作更加随意,同时作为一种正则化技术,可以减少dropout层的使用。
(2)用2个连续的3*3 conv替代inception模块中的5*5,从而实现网络深度的增加,网络整体深度增加了9层,缺点就是增加了25%的weights和30%的计算消耗。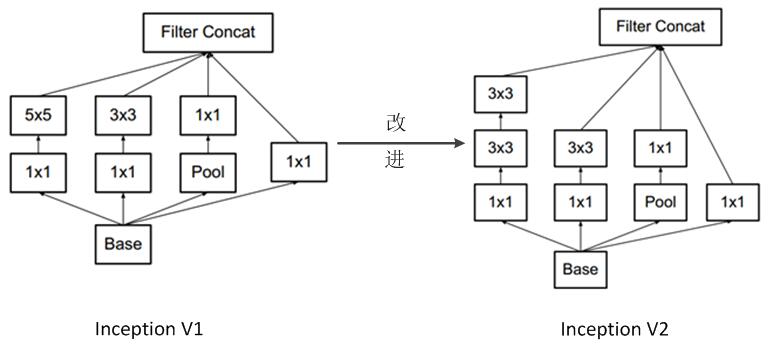
v3:Rethinking the InceptionArchitecture for Computer Vision
Inception v3网络,主要在v2的基础上,提出了卷积分解(Factorization),代表作是Inceptionv3版本的GoogleNet。
Inception v3的亮点总结如下:
(1) 将7*7分解成两个一维的卷积(1*7,7*1),3*3也是一样(1*3,3*1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,更加精细设计了35*35/17*17/8*8的模块。
(2)增加网络宽度,网络输入从224*224变为了299*299。
v4:Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning
Inception v4主要利用残差连接(Residual Connection)来改进v3结构,代表作为,Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4
resnet中的残差结构如下,这个结构设计的就很巧妙,简直神来之笔,使用原始层和经过2个卷基层的feature map做Eltwise。Inception-ResNet的改进就是使用上文的Inception module来替换resnet shortcut中的conv+1*1 conv。
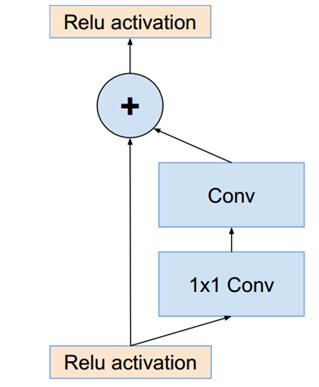
Inception v4的亮点总结如下:
(1)将Inception模块和ResidualConnection结合,提出了Inception-ResNet-v1,Inception-ResNet-v2,使得训练加速收敛更快,精度更高。
ILSVRC-2012测试结果如下(single crop),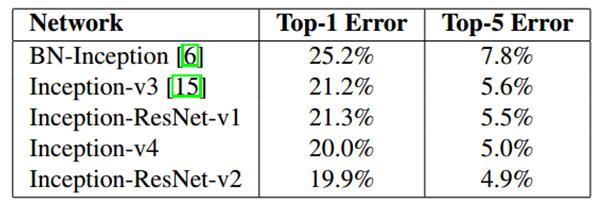
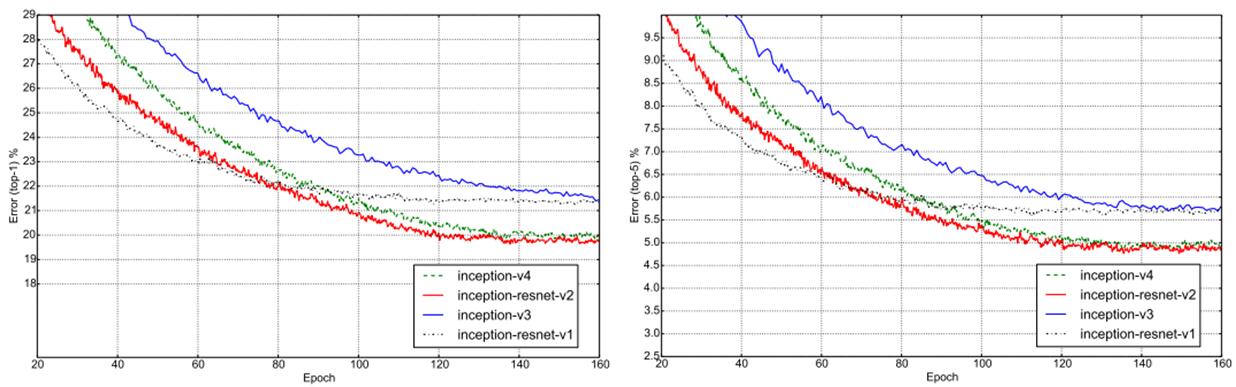
(2)设计了更深的Inception-v4版本,效果和Inception-ResNet-v2相当。
(3)网络输入大小和V3一样,还是299*299
Aggregated ResidualTransformations for Deep Neural Networks
这篇提出了resnet的升级版。ResNeXt,the next dimension的意思,因为文中提出了另外一种维度cardinality,和channel和space的维度不同,cardinality维度主要表示ResNeXt中module的个数,最终结论
(1)增大Cardinality比增大模型的width或者depth效果更好
(2)与 ResNet 相比,ResNeXt 参数更少,效果更好,结构更加简单,更方便设计
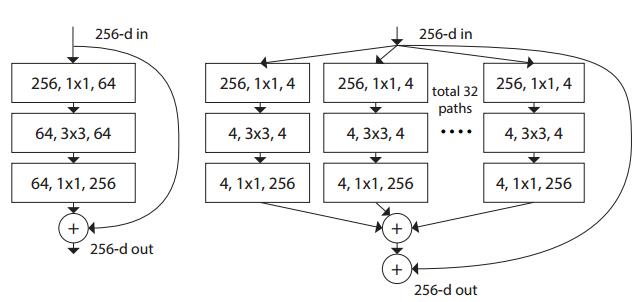
其中,左图为ResNet的一个module,右图为ResNeXt的一个module,是一种split-transform-merge的思想
Xception: DeepLearning with Depthwise Separable Convolutions
这篇文章主要在Inception V3的基础上提出了Xception(Extreme Inception),基本思想就是通道分离式卷积(depthwise separable convolution operation)。最终实现了
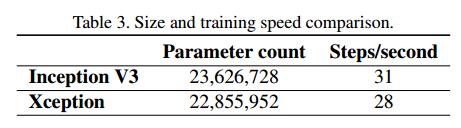
(1)模型参数有微量的减少,减少量很少,具体如下,
(2)精度较Inception V3有提高,ImageNET上的精度如下,
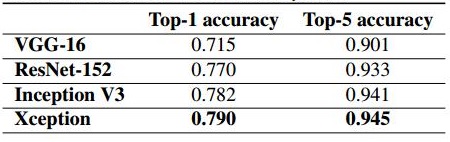
先说,卷积的操作,主要进行2种变换,
(1)spatial dimensions,空间变换
(2)channel dimension,通道变换
而Xception就是在这2个变换上做文章。Xception与Inception V3的区别如下:
(1)卷积操作顺序的区别
Inception V3是先做1*1的卷积,再做3*3的卷积,这样就先将通道进行了合并,即通道卷积,然后再进行空间卷积,而Xception则正好相反,先进行空间的3*3卷积,再进行通道的1*1卷积。
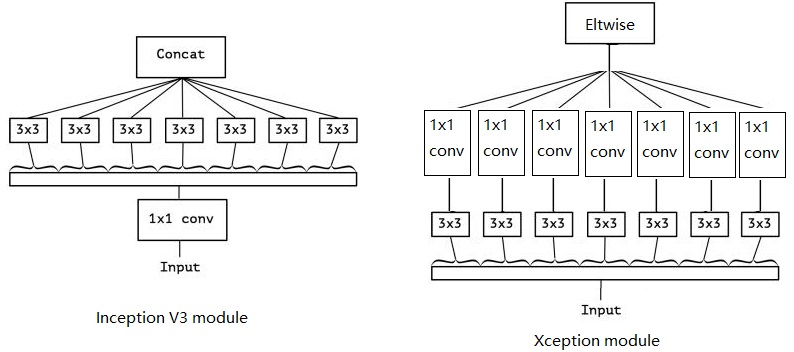
(2)RELU的有无
这个区别是最不一样的,Inception V3在每个module中都有RELU操作,而Xception在每个module中是没有RELU操作的。
MobileNets: EfficientConvolutional Neural Networks for Mobile Vision Applications
MobileNets其实就是Exception思想的应用。区别就是Exception文章重点在提高精度,而MobileNets重点在压缩模型,同时保证精度。
depthwiseseparable convolutions的思想就是,分解一个标准的卷积为一个depthwise convolutions和一个pointwise convolution。简单理解就是矩阵的因式分解。

传统卷积和深度分离卷积的区别如下,

假设,输入的feature map大小为DF * DF,维度为M,滤波器的大小为DK * DK,维度为N,并且假设padding为1,stride为1。则,
原始的卷积操作,需要进行的矩阵运算次数为DK · DK · M · N · DF · DF,卷积核参数为DK · DK · N · M
depthwise separable convolutions需要进行的矩阵运算次数为DK · DK ·M · DF · DF + M · N · DF · DF,卷积核参数为DK · DK · M+N · M
由于卷积的过程,主要是一个spatial dimensions减少,channel dimension增加的过程,即N>M,所以,DK · DK · N · M> DK · DK · M+N · M。
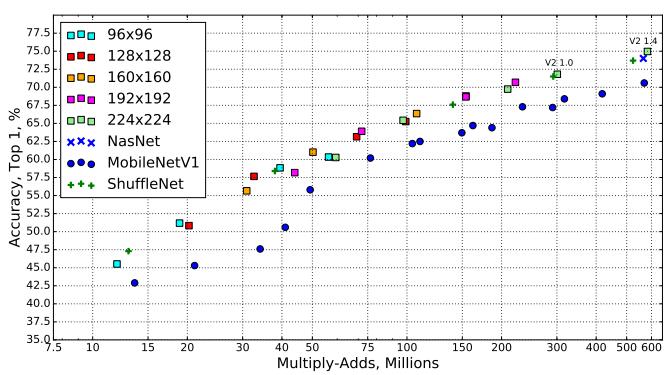
因此,depthwiseseparable convolutions在模型大小上和模型计算量上都进行了大量的压缩,使得模型速度快,计算开销少,准确性好。如下图所示,其中,横轴MACS表示加法和乘法的计算量(Multiply-Accumulates),纵轴为准确性。
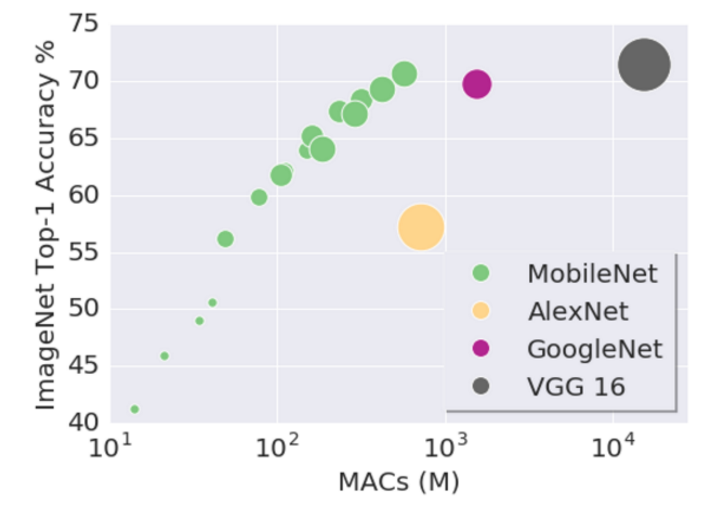
depthwise separable convolutions在caffe中,主要通过卷积层中group操作实现,base_line模型大小大概为16M。
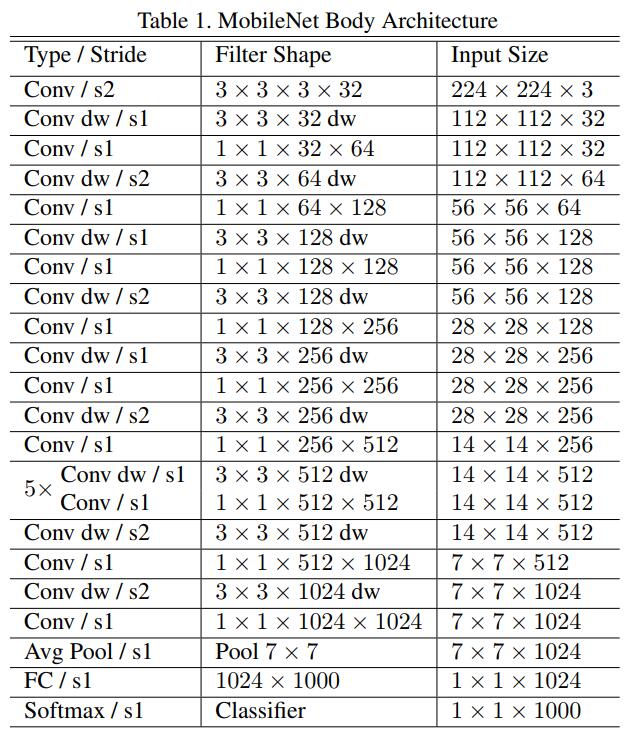
mobileNet网络结构如下:
ShuffleNet: AnExtremely Efficient Convolutional Neural Network for Mobile Devices
这篇文章在mobileNet的基础上主要做了1点改进:
mobileNet只做了3*3卷积的deepwiseconvolution,而1*1的卷积还是传统的卷积方式,还存在大量冗余,ShuffleNet则在此基础上,将1*1卷积做了shuffle和group操作,实现了channel shuffle 和pointwise group convolution操作,最终使得速度和精度都比mobileNet有提升。
如下图所示,
(a)是原始的mobileNet的框架,各个group之间相互没有信息的交流。
(b)将feature map做了shuffle操作
(c)是经过channel shuffle之后的结果。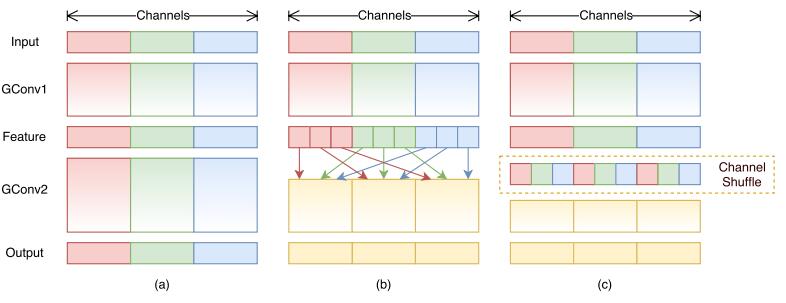
Shuffle的基本思路如下,假设输入2个group,输出5个group
| group 1 | group 2 |
| 1,2,3,4,5 |6,7,8,9,10 |
转化为矩阵为2*5的矩阵
1 2 3 4 5
6 7 8 9 10
转置矩阵,5*2矩阵
1 6
2 7
3 8
4 9
5 10
摊平矩阵
| group 1 | group 2 | group 3 | group 4 | group 5 |
| 1,6 |2,7 |3,8 |4,9 |5,10 |
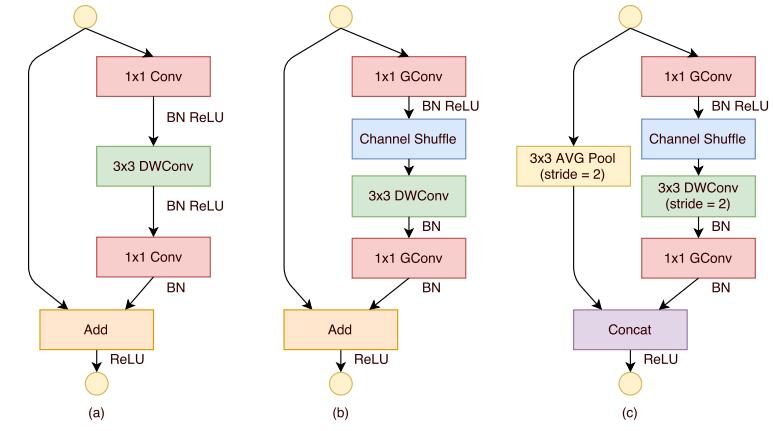
ShuffleNet Units 的结构如下,
(a)是一个带depthwiseconvolution (DWConv)的bottleneck unit
(b)在(a)的基础上,进行了pointwisegroup convolution (GConv) and channel shuffle
(c)进行了AVG pooling和concat操作的最终ShuffleNetunit
MobileNetV2: Inverted Residuals and Linear Bottlenecks
主要贡献有2点:
1,提出了逆向的残差结构(Inverted residuals)
由于MobileNetV2版本使用了残差结构,和resnet的残差结构有异曲同工之妙,源于resnet,却和而不同。
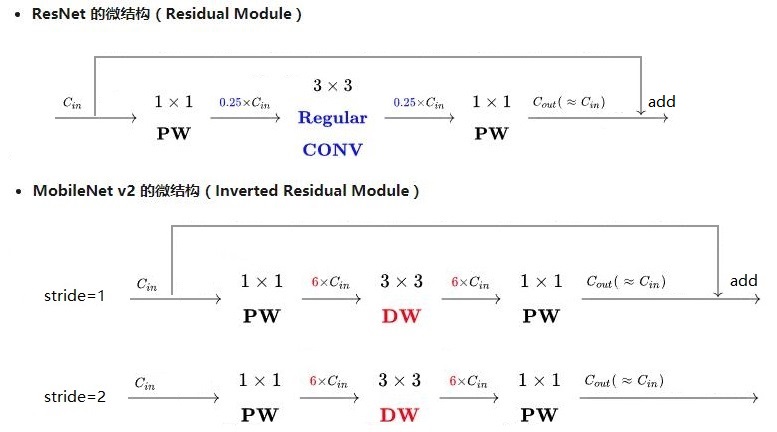
由于Resnet没有使用depthwise conv,所以,在进入pointwise conv之前的特征通道数是比较多的,所以,残差模块中使用了0.25倍的降维。而MobileNet v2由于有depthwise conv,通道数相对较少,所以残差中使用 了6倍的升维。
总结起来,2点区别
(1)ResNet的残差结构是0.25倍降维,MobileNet V2残差结构是6倍升维
(2)ResNet的残差结构中3*3卷积为普通卷积,MobileNet V2中3*3卷积为depthwise conv
MobileNet v1,MobileNet v2 有2点区别:
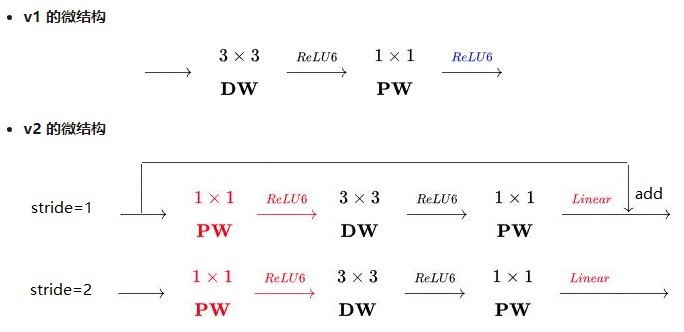
(1)v2版本在进入3*3卷积之前,先进行了1*1pointwise conv升维,并且经过RELU。
(2)1*1卷积出去后,没有进行RELU操作
2,提出了线性瓶颈单元(linear bottlenecks)
Why no RELU?
首选看看RELU的功能。RELU可以将负值全部映射为0,具有高度非线性。下图为论文的测试。在维度比较低2,3的时候,使用RELU对信息的损失是比较严重的。而单维度比较高15,30时,信息的损失是比较少的。

MobileNet v2中为了保证信息不被大量损失,应此在残差模块中去掉最后一个的RELU。因此,也称为线性模块单元。
MobileNet v2网络结构:

其中,t表示通道的扩大系数expansion factor,c表示输出通道数,
n表示该单元重复次数,s表示滑动步长stride
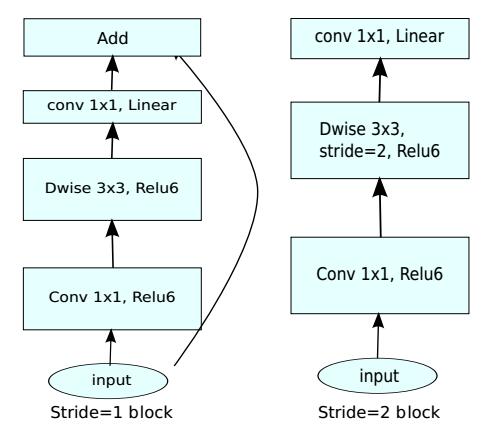
其中bottleneck模块中,stride=1和stride=2的模块分别如上图所示,只有stride=1的模块才有残差结构。
结果:
MobileNet v2速度和准确性都优于MobileNet v1
references:
http://iamaaditya.github.io/2016/03/one-by-one-convolution/
https://github.com/soeaver/caffe-model
https://github.com/facebookresearch/ResNeXt
https://github.com/kwotsin/TensorFlow-Xception
https://github.com/shicai/MobileNet-Caffe https://github.com/shicai/MobileNet-Caffe
https://github.com/tensorflow/models/blob/master/slim/nets/mobilenet_v1.md
https://github.com/camel007/Caffe-ShuffleNet














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









