








数学公式
很多标准的机器学系算法都可以表示为一个凸优化问题,即找到使得凸函数f最小的参数向量。
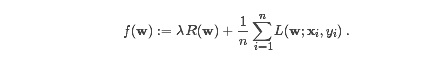
正则部分控制模型复杂度,loss函数L表示模型在训练集上的误差,通常是w的凸函数。参数labmda用来权衡两者。
loss functions
spark支持的loss函数
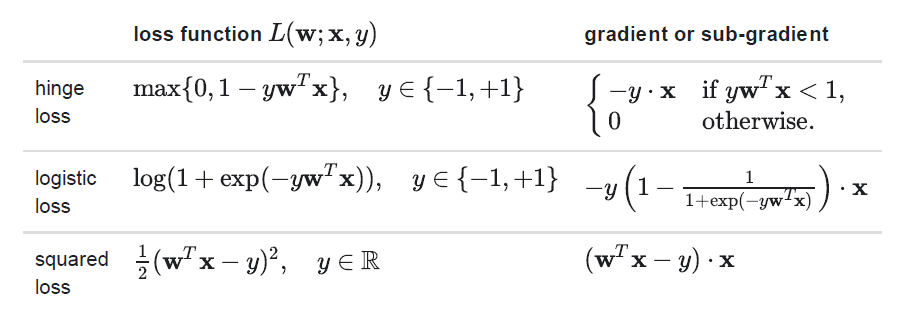
正则化
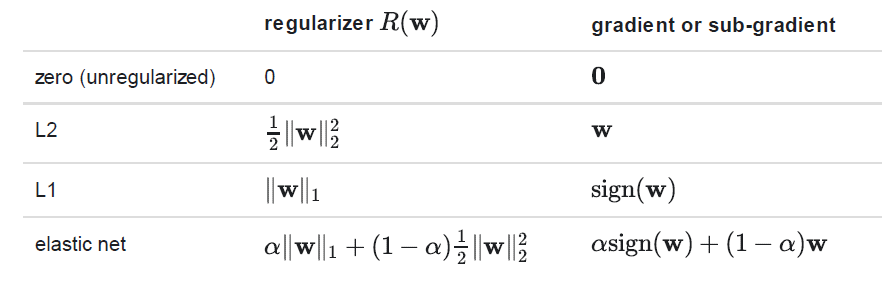
由于平滑性,L2正则比L1正则要简单,但是L1正则有助于改善权重稀疏而得到更小且更易解释的模型,L1有助于特征选择。不建议不使用任何正则化,尤其是训练集很小的时候
optimization
线性方法使用凸优化方法来最优化目标函数。
spark使用两种方法:SGD和L-BFGS。
分类
Spark支持两种分类算法:SVM,Logistic回归
SVM
SVM用于大规模分类任务。默认使用L2正则化训练,然而我们也可以选择L1正则,那样的话问题变成线性规划。
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import org.apache.spark.mllib.util.MLUtils
// Load training data in LIBSVM format.
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// Split data into training (60%) and test (40%).
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// Run training algorithm to build the model
val numIterations = 100
val model = SVMWithSGD.train(training, numIterations)
// Clear the default threshold.
model.clearThreshold()
// Compute raw scores on the test set.
val scoreAndLabels = test.map { point =>
val score = model.predict(point.features)
(score, point.label)
}
// Get evaluation metrics.
val metrics = new BinaryClassificationMetrics(scoreAndLabels)
val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
// Save and load model
model.save(sc, "myModelPath")
val sameModel = SVMModel.load(sc, "myModelPath")
SVMWithSGD.train()默认使用L2正则,且参数为1.0,我们也可以自己配置
import org.apache.spark.mllib.optimization.L1Updater
val svmAlg = new SVMWithSGD()
svmAlg.optimizer.
setNumIterations(200).
setRegParam(0.1).
setUpdater(new L1Updater)
val modelL1 = svmAlg.run(training)Logistic 回归
import org.apache.spark.SparkContext
import org.apache.spark.mllib.classification.{LogisticRegressionWithLBFGS, LogisticRegressionModel}
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.util.MLUtils
// 加载数据
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// 划分测试集
val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0).cache()
val test = splits(1)
// 训练模型
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.run(training)
//计算测试集得分
val predictionAndLabels = test.map { case LabeledPoint(label, features) =>
val prediction = model.predict(features)
(prediction, label)
}
// 获得评估矩阵
val metrics = new MulticlassMetrics(predictionAndLabels)
val precision = metrics.precision
println("Precision = " + precision)
// Save and load model
model.save(sc, "myModelPath")
val sameModel = LogisticRegressionModel.load(sc, "myModelPath")回归
Linear least squares, Lasso, and ridge regression
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.regression.LinearRegressionModel
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
import org.apache.spark.mllib.linalg.Vectors
// Load and parse the data
val data = sc.textFile("data/mllib/ridge-data/lpsa.data")
val parsedData = data.map { line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}.cache()
// Building the model
val numIterations = 100
val model = LinearRegressionWithSGD.train(parsedData, numIterations)
// Evaluate model on training examples and compute training error
val valuesAndPreds = parsedData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val MSE = valuesAndPreds.map{case(v, p) => math.pow((v - p), 2)}.mean()
println("training Mean Squared Error = " + MSE)
// Save and load model
model.save(sc, "myModelPath")
val sameModel = LinearRegressionModel.load(sc, "myModelPath")Streaming linear regression
目前只支持最小二乘
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.regression.StreamingLinearRegressionWithSGD
Then we make input streams for training and testing data. We assume a StreamingContext ssc has already been created, see Spark Streaming Programming Guide for more info. For this example, we use labeled points in training and testing streams, but in practice you will likely want to use unlabeled vectors for test data.
val trainingData = ssc.textFileStream("/training/data/dir").map(LabeledPoint.parse).cache()
val testData = ssc.textFileStream("/testing/data/dir").map(LabeledPoint.parse)We create our model by initializing the weights to 0
val numFeatures = 3
val model = new StreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.zeros(numFeatures))Now we register the streams for training and testing and start the job. Printing predictions alongside true labels lets us easily see the result.
model.trainOn(trainingData)
model.predictOnValues(testData.map(lp => (lp.label, lp.features))).print()
ssc.start()
ssc.awaitTermination()














 2864
2864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









