'''
线性模型
糖尿病数据集包含10个变量,442个病人样本,以及一年后的治疗结果
'''
diabetes = datasets.load_diabetes()
diabetes_X_train = diabetes.data[:-20]
diabetes_X_test = diabetes.data[-20:]
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
from sklearn import linear_model
regr = linear_model.LinearRegression()
regr.fit(diabetes_X_train,diabetes_y_train)
print regr.coef_
#均方误差
np.mean((regr.predict(diabetes_X_test)-diabetes_y_test)**2)
# Explained variance score: 1 is perfect prediction# and 0 means that there is no linear relationship# between X and Y.
regr.score(diabetes_X_test,diabetes_y_test)# 0.58507530226905713
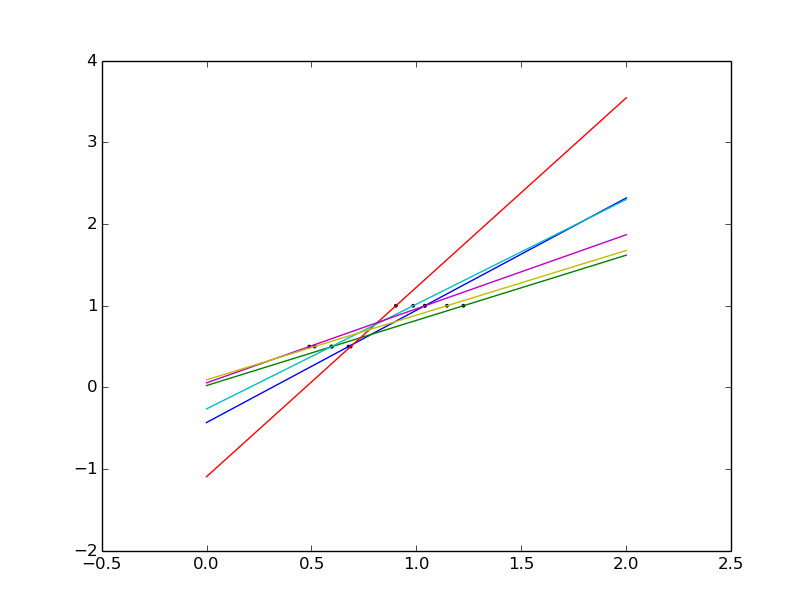
shrnkage
'''
shrinkage
如果每个维度的观测集很少,观测中的噪声将导致高方差
'''
X =np.c_[.5,1].T
y= [.5,1]
test = np.c_[0,2].T
regr = linear_model.LinearRegression()
import pylab as pl
pl.figure()
np.random.seed(0)
for _ in range(6):
this_X = .1*np.random.normal(size=(2,1))+X
regr.fit(this_X,y)
pl.plot(test,regr.predict(test))
pl.scatter(this_X,y,s=3)
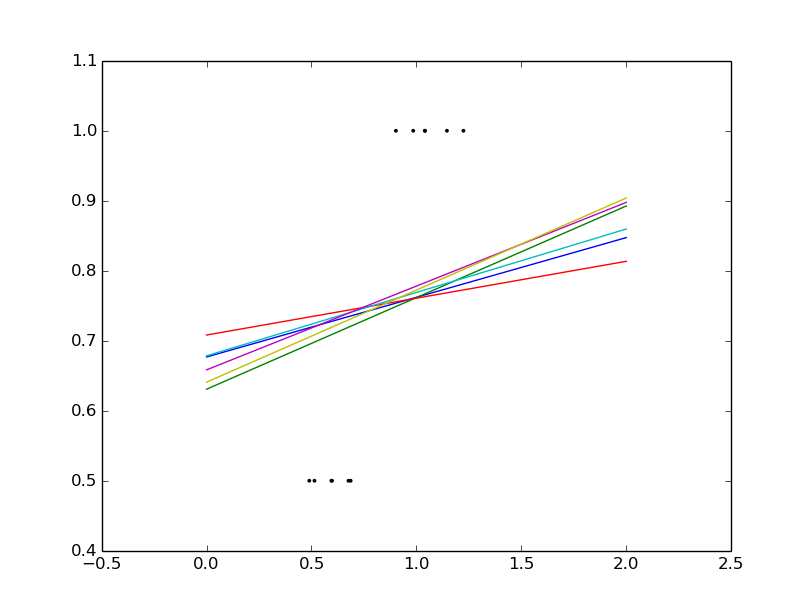
'''
A solution in high-dimensional statistical learning is to shrink the regression
coefficients to zero: any two randomly chosen set
of observations are likely to be uncorrelated. This is called Ridge regression:
'''
regr = linear_model.Ridge(alpha=1)
pl.figure()
np.random.seed(0)
for _ in range(6):
this_X = .1*np.random.normal(size=(2,1))+X
regr.fit(this_X,y)
pl.plot(test,regr.predict(test))
pl.scatter(this_X,y,s=3)

























 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









