







本文笔记整理来源于教学视频,对其进行了简单化整理,去掉了冗余的内容。
基础知识
优缺点
优点
- 简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。它使你能够专注于解决问题而不是去搞明白语言本身。
- 易学:就如同你即将看到的一样,Python极其容易上手。前面已经提到了,Python有极其简单的语法。
- 免费、开源:Python是FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。这是为什么Python如此优秀的原因之一——它是由一群希望看到一个更加优秀的Python的人创造并经常改进着的。
- **高层语言:**当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
- 可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就可以在下述任何平台上面运行。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE甚至还有PocketPC、Symbian以及Google基于linux开发的Android平台!
- 解释型语言:一个用编译型语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。
- 面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常强大又简单的方式实现面向对象编程。
- 可扩展性:如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 丰富的库:Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。记住,只要安装了Python,所有这些功能都是可用的。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
- 规范的代码:Python采用强制缩进的方式使得代码具有极佳的可读性。
缺点
Python语言非常完善,没有明显的短板和缺点,唯一的缺点就是执行效率慢,这个是解释型语言所通有的,同时这个缺点也将被计算机越来越强大的性能所弥补。
注释
具体看代码注释
# 这是一个注释,这是不会执行,是对代码的解释说明
# 注释分为单行注释和多行注释, 单行注释以#号开头
# print()是python中的一个函数,作用是在控制台输出括号中的内容
print('hello world!')
# 多行注释,三个引号中的内容就是多行注释
'''
这是三个单引号,这是一个多行注释
多行注释可以换行
不会执行
'''
"""
三个双引号,也是多行注释
也不会执行
也可以换行
"""
print('hello itcast')
def print_hi(name):
""" 这里是文档注释
:param name: s
:return: 返回值为空
"""
# 在下面的代码行中使用断点来调试脚本。
print(f'Hi, {name}') # 按 Ctrl+Shift+B 切换断点。
if __name__ == '__main__':
print_hi("hi")
注意:在文档注释(函数注释)中, 有关参数和返回值的注释,前面的冒号,后面的冒号,都不能添加多余的空格,否则文档注释显示会很乱,下图是展示的效果。
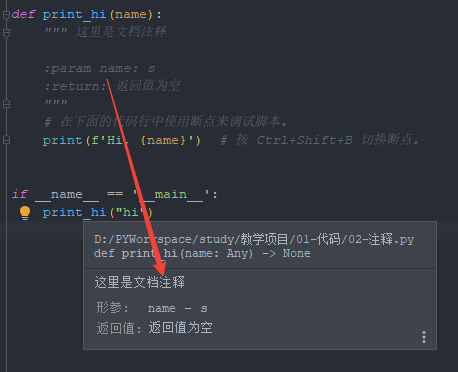
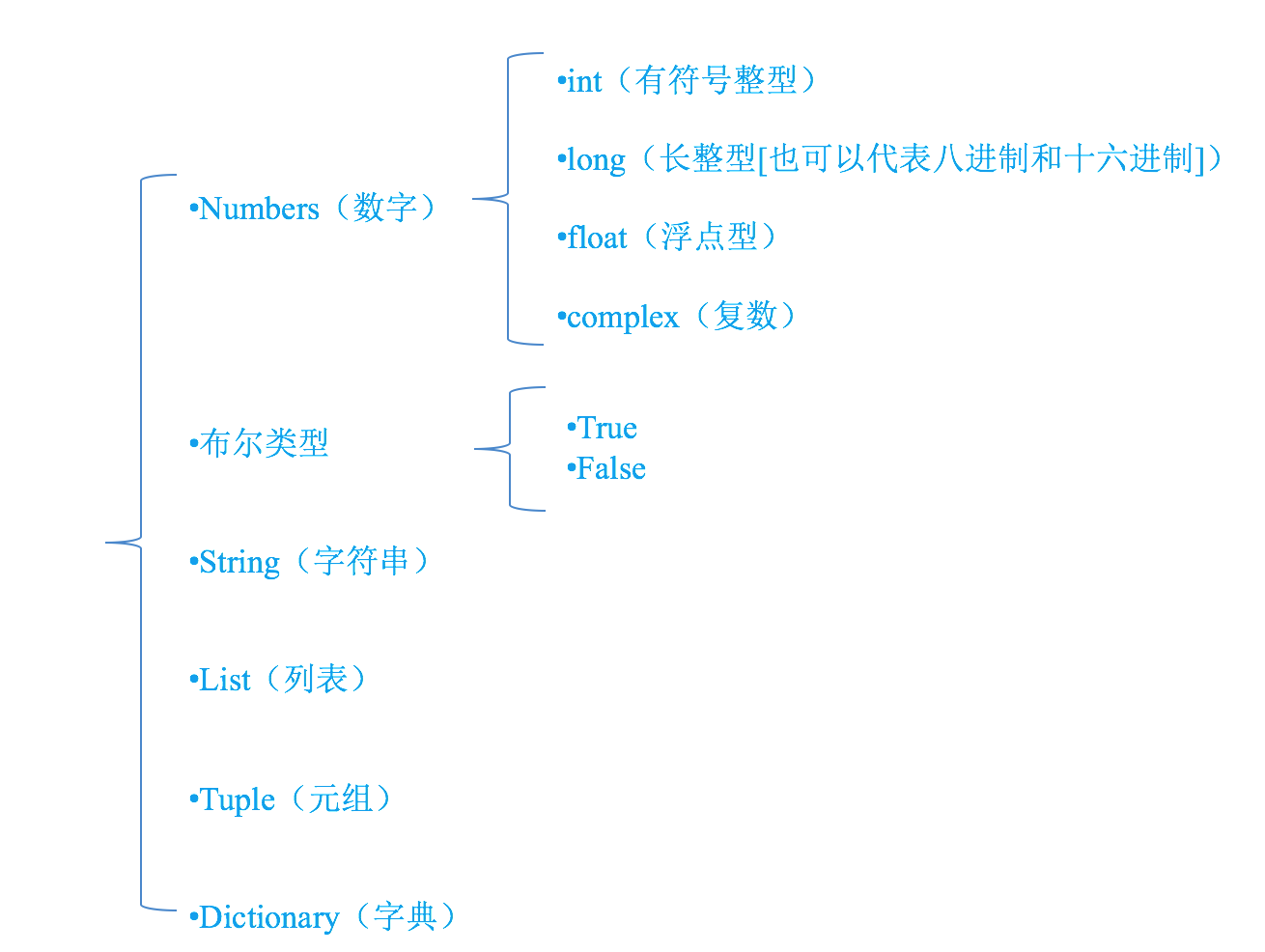
变量的类型
为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型的,如下所示:
通过以下方式可以知道变量的类型
- 在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要咱们开发者主动的去指定它的类型,系统会自动辨别
- 可以使用type(变量的名字),来查看变量的类型
# 变量的数据类型,由变量中存储的数据决定的
# 可以使用 type() 函数得到变量的数据类型, 想要进行输出,需要使用print函数
# int 整数
result = 10
# 1. 先使用 type() 函数获得变量result的数据类型 , 2, 使用print函数输出这个数据类型
print(type(result)) # <class 'int'>
# float 小数
result = 3.14 # 修改变量中存储的数据
print(type(result)) # <class 'float'>
# str 引号引起来的内容就是字符串, 包含单引号和双引号
name = 'isaac'
print(type(name)) # <class 'str'>
name = "hello"
print(type(name))
# bool 布尔类型, 只有两个值 True, False
result = True
print(type(result)) # <class 'bool'>
标识符和关键字
标识符是开发人员在程序中自定义的一些符号和名称,是自己定义的,如变量名 、函数名等。
标识符的规则
标识符由字母、下划线和数字组成,且数字不能开头
python中的标识符是区分大小写的,Andy和andy是不同的。
命名规则
-
见名知意
起一个有意义的名字,尽量做到看一眼就知道是什么意思(提高代码可读性) 比如: 名字就定义为 name , 定义学生用 student
-
驼峰命名法
如:userName、userLoginFlag
- 小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
- 大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:FirstName、LastName
- 还有一种命名法是用下划线“_”来连接所有的单词,比如send_buf
关键字
-
什么是关键字
python一些具有特殊功能的标识符,这就是所谓的关键字
关键字,是python已经使用的了,所以不允许开发者自己定义和关键字相同的名字的标识符
· 所有关键字
and as assert break class continue def del
elif else except exec finally for from global
if in import is lambda not or pass
print raise return try while with yield
输出
普通输出
python中变量的输出
# 打印提示
print('hello world')
print('萨瓦迪卡---泰语,你好的意思')
格式化输出
# 在python中的输出使用print函数
# 基本输出
print('hello') # 会输出 hello
print(123) # 会输出 123
# 一次输出多个内容
print('isaac', 18) # 会输出 isaac 和18 ,两者之间使用 空格隔开
# 可以书写表达式
print(1 + 2) # 会输出 1 +2 的结果 3
# 格式化输出, 格式化占位符(坑位), %s 字符串 %d int 整数int %f 小数浮点数float
name = 'isaac'
# 需求: 输出 我的名字是xxx,我很开心
print("我的名字是%s,我很开心." % name) # 我的名字是isaac,我很开心.
age = 18
# 需求: 输出 我的年龄是18岁
print('我的年龄是%d岁' % age) # 我的年龄是18岁
height = 170.5
# %f 输出小数,默认保留6位小数
print('我的身高是%f cm' % height) # 我的身高是170.500000 cm
# %.nf 保留n 位小数
print('我的身高是%.1f cm' % height) # 我的身高是170.5 cm
print('我的身高是%.2f cm' % height) # 我的身高是170.50 cm
# 需求: 我的名字是xx,年龄是xx岁, 身高是xxcm
print('我的名字是%s,年龄是%d岁, 身高是%fcm' % (name, age, height)) # 我的名字是isaac,年龄是18岁, 身高是170.500000cm
# 输出50%, 使用格式化输出的时候,想要输出一个%, 需要使用两个%
print('及格人数占比为%d%%' % 50) # 及格人数占比为50%
# python3.6版本开始支持 f-string ,占位统一使用 {} 占位,填充的数据直接写在 {} 里边
print(f"我的名字是{name},年龄是{age}岁, 身高是{height}cm") # 我的名字是isaac,年龄是18岁, 身高是170.5cm
# 转义字符 \n 将\和n组合在一块,作为一个字符使用, \n 代表换行
# print()函数输出之后,默认会添加一个换行, 如果不想要这个换行可以去掉
# print('hello', end=' ')
print('hello', end='_*_')
print('hello', end='')
print('world') # 上面三行代码合起来会输出:hello_*_helloworld
print('good good study\nday day up')
在程序中,看到了%这样的操作符,这就是Python中格式化输出。
常用的格式符号
下面是所有可用的格式符号
| 格式符号 | 转换 |
|---|---|
| %c | 字符 |
| %s | 字符串 |
| %d | 有符号十进制整数 |
| %u | 无符号十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数(小写字母0x) |
| %X | 十六进制整数(大写字母0X) |
| %f | 浮点数 |
| %e | 科学计数法(小写’e’) |
| %E | 科学计数法(大写“E”) |
| %g | %f和%e 的简写 |
| %G | %f和%E的简写 |
输入
# 输入: 从键盘获取输入的内容,存入计算机程序中
# 在python中使用的是 input()函数
# input('给用户的提示信息'), 得到用户输入的内容, 遇到回车代表输入结束, 得到的数据都是字符串类型
# password = input() # input() 括号中不写内容,语法不会出错,但是非常不友好,不知道要做什么事
password = input('请输入密码:')
print('你输入的密码是 %s' % password)
运算符
算术运算符
下面以a=10 ,b=20为例进行计算
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
注意:混合运算时,优先级顺序为:
**高于*/%//高于+-,为了避免歧义,建议使用()来处理运算符优先级。
并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。
赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 |
# 单个变量赋值
>>> num = 10
# 多个变量赋值
>>> num1, num2, f1, str1 = 100, 200, 3.14, "hello"
复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
数据类型转换
常用的数据类型转换
| 函数 | 说明 |
|---|---|
| int(x [,base ]) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| complex(real [,imag ]) | 创建一个复数,real为实部,imag为虚部 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| chr(x) | 将一个整数转换为一个Unicode字符 |
| ord(x) | 将一个字符转换为它的ASCII整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
| bin(x) | 将一个整数转换为一个二进制字符串 |
# # 1. 使用input函数获取苹果的价格
# price = input('请输入苹果价格:') # str
# # 2. 使用input函数获取购买的重量
# weight = input('请输入重量:') # str
# # 3. 输出想要的结果
# result = float(price) * float(weight) # 类型转换
# print(f'苹果单价为{price}元/斤,购买了{weight}斤, 需要支付{result}元')
# 类型转换,将原始数据转换为我们需要的数据类型,在这个过程中,不会改变原始的数据,会生成一个新的数据
# 1. 转换为int类型 int(原始数据)
# 1.1 float类型的数据 转换为int
pi = 3.14
num = int(3.14)
# print(type(pi)) # float
# print(type(num)) # int
# 1.2 整数类型的字符串, "10"
my_str = '10'
num1 = int(my_str)
# print(type(my_str)) # str
# print(type(num1)) # int
# 2. 转换为 float类型 float()
# 2.1 int ---> float
num2 = 10
num3 = float(num2)
# print(type(num2)) # int
# print(type(num3)) # float
# 2.2 将数字类型字符串转换为 float "10" "3.14"
num4 = float("3.14")
num5 = float("10")
# print(type(num4)) # float
# print(type(num5)) # float
# eval() 还原原来的数据类型, 去掉字符串的引号
num6 = eval('100') # 100 int
num7 = eval('3.14') # 3.14 float
print(type(num6)) # <class 'int'>
print(type(num7)) # <class 'float'>
num8 = eval('num7') # num7 是已经定义好的变量,可以使用,不会报错
print(num8, type(num8)) # 3.14 <class 'float'>
# num8 = eval('hello') # 代码报错,hello 变量没有定义,不能使用
判断和循环
if语句的基本格式
if语句是用来进行判断的,其使用格式如下:
if 要判断的条件:
条件成立时,要做的事情
demo:
# 1. 通过用户键盘输入,获取年龄 input()
age = input('请输入你的年龄:') # str
# 需要将字符串类型的的age, 转换为 int类型的age
age = int(age) # int
# 2. 判断年龄是否满足18岁,满足输出`哥18岁了,可以进入网吧为所欲为了`
if age >= 18:
# 条件满足才会执行
print('哥18岁了,可以进入网吧为所欲为了')
# 3. 程序最后输出,`if 判断结束`(不管是否满足,都会输出)
print('if 判断结束')
注意:代码的缩进为一个tab键,或者4个空格
比较运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果是则条件变为真。 | 如a=3,b=3,则(a == b) 为 True |
| != | 检查两个操作数的值是否相等,如果值不相等,则条件变为真。 | 如a=1,b=3,则(a != b) 为 True |
| > | 检查左操作数的值是否大于右操作数的值,如果是,则条件成立。 | 如a=7,b=3,则(a > b) 为 True |
| < | 检查左操作数的值是否小于右操作数的值,如果是,则条件成立。 | 如a=7,b=3,则(a < b) 为 False |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3,则(a >= b) 为 True |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是,则条件成立。 | 如a=3,b=3,则(a <= b) 为 True |
逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与":如果 x 为 False,x and y 返回 False,否则它返回 y 的值。 | True and False, 返回 False。 |
| or | x or y | 布尔"或":如果 x 是 True,它返回 True,否则它返回 y 的值。 | False or True, 返回 True。 |
| not | not x | 布尔"非":如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not True 返回 False, not False 返回 True |
>>> # and : 左右表达式都为True,整个表达式结果才为 True
... if (1 == 1) and (10 > 3):
... print("条件成立!")
...
条件成立!
>>> # or : 左右表达式有一个为True,整个表达式结果就为 True
... if (1 == 2) or (10 > 3):
... print("条件成立!")
...
条件成立!
>>> # not:将右边表达式的逻辑结果取反,Ture变为False,False变为True
... if not (1 == 2):
... print("条件成立!")
...
条件成立!
if…else
格式:
if 条件:
满足条件时要做的事情1
满足条件时要做的事情2
满足条件时要做的事情3
...(省略)...
else:
不满足条件时要做的事情1
不满足条件时要做的事情2
不满足条件时要做的事情3
...(省略)...
案例:
# 1. 通过用户键盘输入,获取年龄 input()
age = input('请输入你的年龄:') # str
# 需要将字符串类型的的age, 转换为 int类型的age
age = int(age) # 将 str 转化为 int 类型
# 2. 判断年龄是否满足18岁,满足输出`哥18岁了,可以进入网吧为所欲为了`
if age >= 18:
# 条件满足才会执行
print('哥18岁了,可以进入网吧为所欲为了')
else:
# 判断条件不满足,会执行的代码
print('不满18岁,回去好好学习吧,少年!!!')
# 3. 程序最后输出,`if 判断结束`(不管是否满足,都会输出)
print('if 判断结束')
if…elif…else
elif的使用格式如下:
if xxx1:
事情1
elif xxx2:
事情2
elif xxx3:
事情3
else:
事情4
elif必须和if一起使用,否则会出错,else一般用在最后,即所有条件都不满足时使用。
案例:
score = eval(input('请输入你的成绩:'))
# 1. 成绩大于等于90 ,输出优秀
if score >= 90:
print('优秀')
# 2. 成绩大于等于80,小于90,输出良好
elif (score >= 80) and score < 90:
print('良好')
# 3. 成绩大于等于60,小于80,输出及格
elif score >= 60: # 想要执行这个判断的前提是,前边两个条件都不满足, 代表score一定小于80
print('及格')
# 4. 小于60,输出不及格
else:
print('不及格')
print("程序结束")
if 实现三目运算操作
a if a > b else b
如果 a > b 的条件成立,三目运算的结果是a,否则就是b。
案例:
a = 1
b = 2
c = a if a < b else b
print(c) # 输出:1
if嵌套
格式:
if 条件1:
满足条件1 做的事情
if 条件2:
满足条件2 做的事情
- 说明
- 外层的if判断,也可以是if-else
- 内层的if判断,也可以是if-else
- 根据实际开发的情况,进行选择
案例:
# 假设 money 大于等于2 可以上车
money = int(input('请输入你拥有的零钱:'))
# 1. 有钱可以上车
if money >= 2:
print('我上车了')
# 假设 seat 大于等于1,就可以坐
seat = int(input('车上的空位个数:'))
# 3. 有空座位,可以坐
if seat >= 1:
print('有座位坐')
else:
# 4. 没有空座位,就站着
print('没有座位,只能站着')
else:
# 2. 没钱不能上车,走路
print('没钱,我只能走路'),
随机数的处理
>>> import random
>>> random.randint(1,3)
3
>>> random.randint(1,3)
3
>>> random.randint(1,3)
2
>>> random.randint(1,3)
3
>>> random.randint(1,3)
2
>>> random.randint(1,3)
1
while循环
while循环的格式:
while 条件:
条件满足时,做的事情
案例:
i = 0
while i < 5:
print("当前是第%d次执行循环" % (i + 1))
print("i=%d" % i)
i+=1
结果:
当前是第1次执行循环
i=0
当前是第2次执行循环
i=1
当前是第3次执行循环
i=2
当前是第4次执行循环
i=3
当前是第5次执行循环
i=4
while循环嵌套
格式:
while 条件1:
条件1满足时,做的事情
...(省略)...
while 条件2:
条件2满足时,做的事情
...(省略)...
案例:
# 操场跑圈 一共需要跑5圈
# 每跑一圈,需要做3个俯卧撑,
# 1. 定义变量记录跑的圈数
i = 0
while i < 5:
# 2. 定义变量, 记录每一圈做了多少个俯卧撑
j = 0
# 3. 操场跑圈
print('操场跑圈中.....')
# 4. 做俯卧撑
while j < 3:
print('做了一个俯卧撑')
j += 1
# 一圈完整了,圈数加1
i += 1
for循环
在Python中 for循环可以遍历任何序列的项目,如一个列表或者一个字符串等。
格式:
for 临时变量 in 列表或者字符串等可迭代对象:
循环满足条件时执行的代码
案例:
for i in 'hello':
# i 是字符串中的每一个字符
print(i, end=' ')
# range(n) 会生成 [0, n) 的数据序列, 不包含n
for i in range(5): # 0 1 2 3 4
# print(i)
print('操场跑圈...')
# range(a, b) 会生成 [a, b) 的整数序列, 不包含b
for i in range(3, 7): # 3 4 5 6
print(i)
# range(a, b, step) 会生成[a, b) 的整数序列,但是每个数字之间的间隔(步长)是step
for i in range(1, 10, 3): # 1 4 7
print(i)
for循环嵌套
案例:
for j in range(n):
# 1. 打印一行
for i in range(n):
print('*', end=' ')
print() # 换行
break和continue
break
立刻结束break所在的循环
for循环示例:
for i in range(1, 6):
if i == 4:
print('吃饱了, 不吃了')
break # 终止循环的执行
print(f'正在吃标号为 {i} 的苹果')
while循环示例:
i = 0
while i<5:
i = i+1
if i==3:
break
print(i)
else:
print("==while循环过程中,如果没有执行break退出,则执行本语句==")
continue
用来结束本次循环,紧接着执行下一次的循环
for循环示例:
for i in range(1, 6):
if i == 4:
print('发现半条虫子,这个苹果不吃了, 没吃饱,继续吃剩下的')
continue # 会结束本次循环,继续下一次循环
print(f'吃了编号为{i}的苹果')
while循环示例:
i = 0
while i<5:
i = i+1
if i==3:
continue
print(i)
break/continue只能用在循环中,除此以外不能单独使用break/continue在嵌套循环中,只对最近的一层循环起作用
循环和else
案例:
for i in 'hello python!':
if i == 'a':
break
else:
print('不包含a这个字符')
a = 10
while a > 0:
if a == 11:
break
a -= 1
else:
print("不包含11这个数字")
如果循环中的 break 没有被触发,则最后会执行 else 中的语句。
容器:字符串、列表、元组、字典
字符串
格式:
b = "hello itcast.cn"
或者
b = 'hello itcast.cn'
双引号或者单引号中的数据,就是字符串
格式化输出
案例1:
name = '峰哥'
position = '讲师'
address = '北京市'
print('--------------------------------------------------')
print("姓名:%s" % name)
print("职位:%s" % position)
print("公司地址:%s" % address)
print('--------------------------------------------------')
结果:
--------------------------------------------------
姓名: 峰哥
职位: 讲师
公司地址: 北京市
--------------------------------------------------
案例2,使用 f-strings 进行格式化输出。
f-strings 提供了一种简洁易读的方式, 可以在字符串中包含 Python 表达式。 f-strings 以字母 f 或 F 为前缀, 后面直接紧跟着使用一对单引号、双引号、三单引号、三双引号将要格式化的字符串包括起来,案例如下:
name = '峰哥'
age = 33
format_string1 = f'我的名字是 {name}, 我的年龄是 {age}' # 我的名字是 峰哥, 我的年龄是 33
format_string2 = f"我的名字是 {name}, 我的年龄是 {age}" # 我的名字是 峰哥, 我的年龄是 33
format_string3 = F'''我的名字是 {name}, 我的年龄是 {age}''' # 我的名字是 峰哥, 我的年龄是 33
format_string4 = F"""我的名字是 {name}, 我的年龄是 {age}""" # 我的名字是 峰哥, 我的年龄是 33
format_string5 = f'3 + 5 = {3 + 5}' # 3 + 5 = 8
a = 10
b = 20
format_string6 = f'3 + 5 = {a + b}' # 3 + 5 = 30
# 两个花括号会被替换为一个花括号, 注意 {{}} 不是表达式
format_string7 = F'我的名字是 {{name}}, 我的年龄是 {{age}}' # 我的名字是 {name}, 我的年龄是 {age}
输入
input获取的数据,都以字符串的方式进行保存,即使输入的是数字,也是以字符串的方式保存
案例:
username = input('请输入用户名:')
print("用户名为:%s" % username)
password = input('请输入密码:')
print("密码为:%s" % password)
列表与元组支持下标索引,字符串实际上是字符的数组,所以也支持下标索引。
如果想取出部分字符,可以通过使用下标的方法,(注意python中下标从 0 开始)
name = 'abcdef'
print(name[0]) # a
print(name[1]) # b
print(name[3]) # d
切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长]
**注意:选取的区间从“起始”位开始,到“结束”位的前一位结束(不包含结束位本身),步长表示选取间隔。**如果“结束”位为负数,则表示倒数,并且结果包含“结束”位。
我们以字符串为例讲解。
如果取出一部分,则可以在中括号[]中,使用冒号来分隔需要的参数
案例1:
name = 'abcdef'
print(name[0:3]) # 取下标 0~2 的字符,结果为:abc
案例2:
name = 'abcdef'
print(name[2:]) # 取下标从2开始到最后的字符,结果为:cdef
案例3:
name = 'abcdef'
print(name[1:-1]) # 取下标从1开始到倒数第2个之间的字符,结果为:bcde
案例4:
s = 'Hello World!'
print(s[:]) # 取出所有元素(没有起始位和结束位之分),默认步长为1,结果为:Hello World!
print(s[1:]) # 从下标为1开始,取出 后面所有的元素(没有结束位),结果为:ello World!
print(s[:5]) # 从起始位置开始,取到 下标为5的前一个元素(不包括结束位本身),结果为:Hello
print(s[:-1]) # 从起始位置开始,取到 倒数第一个元素(不包括结束位本身),结果为:Hello World
print(s[-4:-1]) # 从倒数第4个元素开始,取到 倒数第1个元素(不包括结束位本身),结果为:rld
print(s[5:1]) # 从下标为5开始,取到下标为1的元素,但是步长为1,表示正向取,所以取不到,结果为:空字符串
print(s[5:1:-1]) # 从下标为5开始,取到下标为1的元素,步长为-1,表示逆向取,所以可以取到,结果为: oll
print(s[1:5:2]) # 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身),结果为:el
# python 字符串快速逆置
print(s[::-1]) # 从后向前,按步长为1进行取值,结果为:!dlroW olleH
常见操作
find
检测 str 是否包含在 mystr 中,如果是,则返回其所在位置的索引值,否则返回-1
mystr.find(str, start=0, end=len(mystr))
mystr = 'hello world itcast and itcastcpp'
print(mystr.find('itcast')) # 12
print(mystr.find('itcast', 0, 10)) # -1
index
作用跟find()方法一样,但是如果str不在mystr中则会报一个异常。
mystr.index(str, start=0, end=len(mystr))
mystr = 'hello world itcast and itcastcpp'
print(mystr.find('itcast', 0, 10)) # -1
print(mystr.index('itcast', 0, 10))
第三行报错,错误如下
Traceback (most recent call last):
File "D:/PYWorkspace/study/教学项目/03-代码/temp.py", line 3, in <module>
print(mystr.index('itcast', 0, 10))
ValueError: substring not found
count
返回str在start和end之间,在mystr里面出现的次数
mystr.count(str, start=0, end=len(mystr))
mystr = 'hello world itcast and itcastcpp'
print(mystr.count('itcast')) # 2
replace
把 mystr 中的 str1 替换成 str2,如果指定了 count ,则替换不超过 count 次,默认 count 为子字符串出现的次数。
mystr.replace(str1, str2, count=mystr.count(str1))
name = 'hello world ha ha'
print(name.replace('ha', 'HA')) # hello world HA HA
print(name.replace('ha', 'HA', 1)) # hello world HA ha
split
以 str 为分隔符切片 mystr,如果指定了 maxsplit 的值,则仅分隔 maxsplit 次,最后会产生 maxsplit 个子字符串
mystr.split(str=" ", 2)
name = 'hello world ha ha'
# 如果不指定分割的字符串,则表示任何空白字符,比如空格、换行、制表符等,其分割结果会忽略空字符串。
print(name.split()) # ['hello', 'world', 'ha', 'ha']
print(name.split(' ')) # ['hello', 'world', 'ha', 'ha']
print(name.split(' ', 2)) # ['hello', 'world', 'ha ha']
join
将 str 插入到列表或数组中每个元素之间,构造出一个新的字符串
list.join(str)
str = ' '
li = ['my', 'name', 'is', 'tony']
str = '_'
print(str.join(li)) # my_name_is_tony
capitalize
把字符串的第一个字符大写
mystr.capitalize()
mystr = 'hello world it cast and itcastcpp'
print(mystr.capitalize()) # Hello world it cast and itcastcpp
title
把字符串的每个单词首字母都大写
>>> a = "hello itcast"
>>> a.title()
'Hello Itcast'
startswith
检查字符串是否是以 str 开头, 是则返回 True,否则返回 False
mystr.startswith(str)
mystr = 'hello world it cast and itcastcpp'
print(mystr.startswith('hello')) # True
print(mystr.startswith('Hello')) # False
endswith
检查字符串是否以 str 结束,如果是返回True,否则返回 False.
mystr.endswith(str)
mystr = 'hello world it cast and itcastcpp'
print(mystr.endswith('cpp')) # True
print(mystr.endswith('app')) # False
lower
将 mystr 中所有字符转为小写
mystr.lower()
mystr = 'hello world it cast and itcastcpp'
print(mystr.lower()) # hello world it cast and itcastcpp
uppser
将 mystr 中所有字符转为大写
mystr = 'hello world it cast and itcastcpp'
print(mystr.upper()) # HELLO WORLD IT CAST AND ITCASTCPP
ljust
返回一个将原字符串左对齐,并使用空格填充至长度 width 的新字符串
mystr.ljust(width)
mystr = 'hello'
print(mystr.ljust(10)) # 'hello '
rjust
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
mystr.rjust(width)
mystr = 'hello'
print(mystr.rjust(10)) # ' hello'
center
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
mystr.center(width)
mystr = 'hello world it cast and itcastcpp'
print(mystr.center(50)) # ' hello world it cast and itcastcpp '
lstrip
删除 mystr 左边的空白字符
mystr.lstrip()
mystr = ' hello'
print(mystr.lstrip()) # 'hello'
rstrip
删除 mystr 字符串末尾的空白字符
mystr.rstrip()
mystr = ' hello '
print(mystr.rstrip()) # ' hello'
rfind
类似于 find()函数,不过是从右边开始查找.
mystr.rfind(str, start=0,end=len(mystr) )
mystr = 'hello world itcast and itcastcpp'
print(mystr.rfind('itcast')) # 23
rindex
类似于 index(),不过是从右边开始.
mystr.rindex( str, start=0,end=len(mystr))
mystr = 'hello world itcast and itcastcpp'
print(mystr.rindex("it")) # 23
partition
把mystr以str分割成三部分,str前,str和str后,返回值是元组
mystr.partition(str)
mystr = 'hello world itcast and itcastcpp'
print(mystr.partition('itcast')) # ('hello world ', 'itcast', ' and itcastcpp')
rpartition
类似于 partition()函数,不过是从右边开始.
mystr.rpartition(str)
mystr = 'hello world itcast and itcastcpp'
print(mystr.partition('itcast')) # ('hello world ', 'itcast', ' and itcastcpp')
print(mystr.rpartition('itcast')) # ('hello world itcast and ', 'itcast', 'cpp')
splitlines
按照行分隔,返回一个包含各行作为元素的列表
mystr.splitlines()
mystr = 'hello\nworld'
print(mystr.splitlines()) # ['hello', 'world']
isalpha
如果 mystr 所有字符都是字母 则返回 True,否则返回 False
mystr.isalpha()
mystr = 'abc'
print(mystr.isalpha()) # True
mystr = 'abc12'
print(mystr.isalpha()) # False
mystr = 'ab啊'
print(mystr.isalpha()) # True
sdigit
如果 mystr 只包含数字则返回 True 否则返回 False.
mystr.isdigit()
mystr = '123'
print(mystr.isdigit()) # True
mystr = 'abc12'
print(mystr.isdigit()) # False
mystr = '123啊'
print(mystr.isdigit()) # False
isalnum
如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False
mystr.isalnum()
mystr = '123'
print(mystr.isalnum()) # True
mystr = 'abc12'
print(mystr.isalnum()) # True
mystr = '123 啊'
print(mystr.isalnum()) # False
isspace
如果 mystr 中只包含空格,则返回 True,否则返回 False,制表符、换行符,也算是空格
mystr.isspace()
mystr = '123'
print(mystr.isspace()) # False
mystr = ' '
print(mystr.isspace()) # True
mystr = ' '
print(mystr.isspace()) # True
mystr = ' \t '
print(mystr.isspace()) # True
mystr = ' \n '
print(mystr.isspace()) # True
列表
列表中的元素可以是不同类型的
案例;
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
testList = [1, 'a']
访问列表中元素:
namesList = ['xiaoWang','xiaoZhang','xiaoHua']
print(namesList[0]) # xiaoWang
print(namesList[1]) # xiaoZhang
print(namesList[2]) # xiaoHua
列表的循环
使用for循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
案例:
names_list = ['xiaoWang','xiaoZhang','xiaoHua']
for name in names_list:
print(name)
结果:
xiaoWang
xiaoZhang
xiaoHua
使用while循环
为了更有效率的输出列表的每个数据,可以使用循环来完成
demo:
names_list = ['xiaoWang','xiaoZhang','xiaoHua']
length = len(names_list)
i = 0
while i < length:
print(names_list[i])
i+=1
结果:
xiaoWang
xiaoZhang
xiaoHua
列表的相关操作
列表中存放的数据是可以进行修改的,比如"增"、“删”、“改”、“查”
添加元素
append
通过append可以向列表添加元素
案例:
#定义变量A,默认有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
print("-----添加之前,列表A的数据-----")
for temp_name in A:
print(temp_name)
#添加元素
temp = 'xiaoMing'
A.append(temp)
print("-----添加之后,列表A的数据-----")
for temp_name in A:
print(temp_name)
结果:
-----添加之前,列表A的数据-----
xiaoWang
xiaoZhang
xiaoHua
-----添加之后,列表A的数据-----
xiaoWang
xiaoZhang
xiaoHua
xiaoMing
extend
通过extend可以将另一个列表中的元素整体添加到当前列表中
a = [1, 2]
b = [3, 4]
a.append(b)
print(a) # [1, 2, [3, 4]]
a.append(b)
print(a) # [1, 2, [3, 4], [3, 4]]
insert
insert(index, object) 在指定位置index前插入元素
a = [0, 1, 2]
a.insert(1, 3)
print(a) # [0, 3, 1, 2]
修改元素
修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
案例:
#定义变量A,默认有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
print("-----修改之前,列表A的数据-----")
for temp_name in A:
print(temp_name)
#修改元素
A[1] = 'xiaoLu'
print("-----修改之后,列表A的数据-----")
for temp_name in A:
print(temp_name)
结果:
-----修改之前,列表A的数据-----
xiaoWang
xiaoZhang
xiaoHua
-----修改之后,列表A的数据-----
xiaoWang
xiaoLu
xiaoHua
查找元素
所谓的查找,就是看看指定的元素是否存在
in, not in
python中查找的常用方法为:
- in(存在),如果存在那么结果为true,否则为false
- not in(不存在),如果不存在那么结果为true,否则false
案例:
# 待查找的列表
name_list = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
# 查找是否存在
if 'xiaoWang' in name_list:
print('在字典中找到了相同的名字')
else:
print('没有找到')
结果:
在字典中找到了相同的名字
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在
index, count
index和count与字符串中的用法相同
a = ['a', 'b', 'c', 'a', 'b']
# a.index('a', 1, 3) # 注意是左闭右开区间,这样代码报错,因为在指定区间内找不到指定元素
print(a.index('a', 1, 4)) # 3
print(a.count('b')) # 2
print(a.count('d')) # 0
删除元素
列表元素的常用删除方法有:
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素的值进行删除
del案例:
movie_name = ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情']
print('------删除之前------')
print(movie_name) # ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情']
del movie_name[2]
# 下面这种写法和上面的一样
# movie_name.__delitem__(2)
print('------删除之后------')
print(movie_name) # ['加勒比海盗', '骇客帝国', '指环王', '霍比特人', '速度与激情']
pop案例:
movie_name = ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情']
print('------删除之前------')
print(movie_name) # ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情']
movie_name.pop()
print('------删除之后------')
print(movie_name) # ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人']
remove案例:
movie_name = ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情']
print('------删除之前------')
print(movie_name) # ['加勒比海盗', '骇客帝国', '第一滴血', '指环王', '霍比特人', '速度与激情']
movie_name.remove('骇客帝国')
print('------删除之后------')
print(movie_name) # ['加勒比海盗', '第一滴血', '指环王', '霍比特人', '速度与激情']
排序
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list反转。
a = [1, 4, 2, 3]
a.reverse() # [3, 2, 4, 1]
print(a)
a.sort() # [1, 2, 3, 4]
print(a)
a.sort(reverse=True)
print(a) # [4, 3, 2, 1]
列表的嵌套
一个列表中的元素又是一个列表,这就是列表的嵌套.
格式:
school_names = [['北京大学','清华大学'],
['南开大学','天津大学','天津师范大学'],
['山东大学','中国海洋大学']]
元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
>>> my_tuple = ('et',77,99.9)
>>> my_tuple
('et',77,99.9)
访问元组
tuple = ('hello', 100, 3.14)
print(tuple[0]) # hello
print(tuple[1]) # 100
print(tuple[2]) # 3.14
修改元组
tuple = ('hello', 100, 3.14)
tuple[2] = 188
运行时报错如下:
Traceback (most recent call last):
File "D:/PYWorkspace/study/教学项目/03-代码/temp.py", line 2, in <module>
tuple[2] = 188
TypeError: 'tuple' object does not support item assignment
说明: python中不允许修改元组的数据,包括不能删除其中的元素。
count, index
index和count与字符串和列表中的用法相同
a = ('a', 'b', 'c', 'a', 'b')
# a.index('a', 1, 3) # 注意是左闭右开区间,这样代码爆粗,因为在指定区间内找不到对应的元素
print(a.index('a', 1, 4)) # 3
print(a.count('b')) # 2
print(a.count('d')) # 0
字典
格式:
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
说明:
- 字典和列表一样,也能够存储多个数据
- 列表中找某个元素时,是根据下标进行的
- 字典中找某个元素时,是根据’名字’(就是冒号:前面的那个值,例如上面代码中的’name’、‘id’、‘sex’)
- 字典的每个元素由2部分组成,键:值。例如 ‘name’:‘班长’ ,'name’为键,'班长’为值
# 字典 dict 定义使用{} 定义, 是由键值对组成(key-value)
# 变量 = {key1: value1, key2:value2, ...} 一个key:value 键值对是一个元素
# 字典的key 可以是 字符串类型和数字类型(int float), 不能是 列表
# value值可以是任何类型
# 1. 定义空字典
my_dict = {}
my_dict1 = dict()
print(my_dict, type(my_dict)) # {} <class 'dict'>
print(my_dict1, type(my_dict1)) # {} <class 'dict'>
# 2. 定义带数据的字典
my_dict2 = {'name': 'isaac', 'age': 18, 'like': ['学习', '购物', '游戏'], 1: [2, 5, 8]}
print(my_dict2) # {'name': 'isaac', 'age': 18, 'like': ['学习', '购物', '游戏'], 1: [2, 5, 8]}
# 3. 访问value 值, 在字典中没有下标的概念, 使用 key 值访问对应的value 值
print(my_dict2['age']) # 18
print(my_dict2['like'][1]) # 购物
# 如果key值不存在
# print(my_dict2['gender']) # 代码报错,key值不存在
# 字典.get(key) 如果key值不存在,不会报错,返回的是None
print(my_dict2.get('gender')) # None
# my_dict2.get(key, 数据值) 如果key存在,返回key对应的value值,如果key不存在,返回给定的默认值
print(my_dict2.get('gender', '男')) # 男
print(my_dict2.get('age', 1)) # 18
print(len(my_dict2)) # 4
常见操作
查看元素
除了使用key查找数据,还可以使用get来获取数据
info = {'name':'吴彦祖','age':18}
print(info['age']) # 18
# print(info['sex']) # 获取不存在的key,会发生异常
print(info.get('sex')) # 获取不存在的key,获取到空的内容,不会出现异常,返回值:None
添加和修改元素
字典[key] = 数据值,如果key值存在,就是修改,如果key值不存在,就是添加
my_dict = {'name': 'isaac'}
print(my_dict) # {'name': 'isaac'}
# 字典中添加和修改数据,使用key值进行添加和修改
# 字典[key] = 数据值; 如果key值存在,就是修改,如果key值不存在,就是添加
my_dict['age'] = 18 # key值不存在,添加
print(my_dict) # {'name': 'isaac', 'age': 18}
my_dict['age'] = 19 # key值已经存在,就是修改数据
print(my_dict) # {'name': 'isaac', 'age': 19}
# 注意: key 值 int 的 1 和float的 1.0 代表一个key值
my_dict[1] = 'int'
print(my_dict) # {'name': 'isaac', 'age': 19, 1: 'int'}
my_dict[1.0] = 'float'
print(my_dict) # {'name': 'isaac', 'age': 19, 1: 'float'}
删除元素
对字典进行删除操作,有以下两种:
- del:删除指定元素,或者是删除整个字典
- clear():清空整个字典
my_dict = {'name': 'isaac', 'age': 19, 1: 'float', 2: 'aa'}
# 根据key值删除数据: del 字典名[key]
del my_dict[1] #
# 下面这种写法和上面的效果一样
# my_dict.__delitem__(1)
print(my_dict) # {'name': 'isaac', 'age': 19, 2: 'aa'}
# 字典.pop(key): 根据key值删除, 返回值是删除的key对应的value值
result = my_dict.pop('age')
print(my_dict) # {'name': 'isaac', 2: 'aa'}
print(result) # 19
# 字典.clear(): 清空字典, 删除所有的键值对
my_dict.clear()
print(my_dict) # {}
# del 字典名 直接将这个字典删除了,不能使用这个字典了
del my_dict # 后边的代码不能再直接使用这个变量了,除非再次定义
# print(my_dict) 代码报错, 变量2未定义
len
返回字典中键值对的个数
dict = {'name':'zhangsan', 'sex':'m'}
print(dict.__len__()) # 2
print(len(dict)) # 2
keys
返回字典所有KEY组成的列表
dict = {'name':'zhangsan', 'sex':'m'}
print(dict.keys()) # dict_keys(['name', 'sex'])
values
返回字典所有VALUE组成的列表
dict = {'name':'zhangsan', 'sex':'m'}
print(dict.values()) # dict_values(['zhangsan', 'm'])
items
返回一个包含所有(键,值)元组的列表
dict = {'name':'zhangsan', 'sex':'m'}
print(dict.items()) # dict_items([('name', 'zhangsan'), ('sex', 'm')])
遍历
可以遍历字典的 所有key、所有value、所有键值对(作为k-v两个变量)、所有项(作为元组)。
my_dict = {'name': 'isaac', 'age': 18, 'gender': '男'}
# for循环体直接遍历字典, 遍历的字典的key值
for key in my_dict:
print(key, my_dict[key], end=';') # name isaac;age 18;gender 男;
print('\n')
# 字典.keys() 获取字典中所有的key值, 得到的类型是 dict_keys, 该类型具有的特点是
# 1. 可以使用list() 进行类型转换,即将其转换为列表类型
# 2. 可以使用for循环进行遍历
result = my_dict.keys()
print(result) # dict_keys(['name', 'age', 'gender'])
print(type(result)) # <class 'dict_keys'>
for key in result:
print(key, end=';') # name;age;gender;
print('\n')
# 字典.values() 获取所有的value值, 类型是 dict_values
# 1. 可以使用list() 进行类型转换,即将其转换为列表类型
# 2. 可以使用for循环进行遍历
result = my_dict.values()
print(result) # dict_values(['isaac', 18, '男'])
print(type(result)) # <class 'dict_values'>
for value in my_dict.values():
print(value, end=';') # isaac;18;男;
print('\n')
# 字典.items() 获取所有的键值对, 类型是 dict_items, key,value 组成元组类型
# 1. 可以使用list() 进行类型转换,即将其转换为列表类型
# 2. 可以使用for循环进行遍历
result = my_dict.items()
print(result) # dict_items([('name', 'isaac'), ('age', 18), ('gender', '男')])
print(type(result)) # <class 'dict_items'>
for item in my_dict.items():
print(item[0], item[1], end=';') # name isaac;age 18;gender 男;
print('\n')
for (k, v) in my_dict.items(): # k 是元组中的第一个数据, v 是元组中的第二个数据,k 和 v 使用小括号括起来,或者是不适用小括号,效果一样
print(k, v, end=';') # name isaac;age 18;gender 男;
enumerate
enumerate() 函数可以将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据下标和数据,一般用在 for 循环中。
my_list = ['a', 'b', 'c', 'd', 'e']
for i in my_list:
print(i, end=';') #a;b;c;d;e;
print()
for i in my_list:
print(my_list.index(i), i, end=';') # 0 a;1 b;2 c;3 d;4 e;
print()
# enumerate 将可迭代序列中元素所在的下标和具体元素数据组合在一块,变成元组
for t in enumerate(my_list):
print(t, end=';') # (0, 'a');(1, 'b');(2, 'c');(3, 'd');(4, 'e');
print()
for (index, value) in enumerate(my_list):
print(index, value, end=';') # 0 a;1 b;2 c;3 d;4 e;
公共方法
运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 复制 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
+
>>> "hello " + "itcast"
'hello itcast'
>>> [1, 2] + [3, 4]
[1, 2, 3, 4]
>>> ('a', 'b') + ('c', 'd')
('a', 'b', 'c', 'd')
*
>>> 'ab' * 4
'ababab'
>>> [1, 2] * 4
[1, 2, 1, 2, 1, 2, 1, 2]
>>> ('a', 'b') * 4
('a', 'b', 'a', 'b', 'a', 'b', 'a', 'b')
in
>>> 'itc' in 'hello itcast'
True
>>> 3 in [1, 2]
False
>>> 4 in (1, 2, 3, 4)
True
>>> "name" in {"name":"Delron", "age":24}
True
注意,in在对字典操作时,判断的是字典的键
python内置函数
Python包含了以下内置函数
| 方法 | 描述 |
|---|---|
| len(item) | 计算容器中元素个数 |
| max(item) | 返回容器中元素最大值 |
| min(item) | 返回容器中元素最小值 |
| del(item) | 删除变量 |
len
>>> len("hello itcast")
12
>>> len([1, 2, 3, 4])
4
>>> len((3,4))
2
>>> len({"a":1, "b":2})
2
注意:len在操作字典数据时,返回的是键值对个数。
max
>>> max("hello itcast")
't'
>>> max([1,4,522,3,4])
522
>>> max({"a":1, "b":2})
'b'
>>> max({"a":10, "b":2})
'b'
>>> max({"c":10, "b":2})
'c'
del
del有两种用法,一种是del加空格,另一种是del()
>>> a = 1
>>> a
1
>>> del a
>>> a
变量 a 已经被删除了,所以下面访问变量 a 会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
>>> a = ['a', 'b']
>>> del a[0]
>>> a
['b']
>>> del(a)
>>> a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
多维列表/元祖访问的示例
>>> tuple1 = [(2,3),(4,5)]
>>> tuple1[0]
(2, 3)
>>> tuple1[0][0]
2
>>> tuple1[0][2]
元祖的索引只有 0 和 1,2超过了最大索引,所以会报错
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: tuple index out of range
>>> tuple1[0][1]
3
>>> tuple1[2][2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>> tuple2 = tuple1+[(3)]
>>> tuple2
[(2, 3), (4, 5), 3]
>>> tuple2[2]
3
>>> tuple2[2][0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not subscriptable
可变、不可变类型
所谓可变类型与不可变类型是指:直接对数据进行修改,如果能直接修改就是可变,否则就是不可变。
可变类型有: 列表、字典、集合
不可变类型有: 数字、字符串、元组,给不可变类型的变量重新复制,其实是重新创建了一个新的值赋给原来的变量
函数
定义和调用
格式:
def 函数名():
代码
案例:
# 定义一个函数,能够完成打印信息的功能
def print_info():
print('------------------------------------')
print(' 人生苦短,我用Python')
print('------------------------------------')
定义了函数之后,就相当于有了一个可以完成某些功能的代码,想要让这些代码能够执行,通过 函数名() 即可完成调用。、
注意:
-
每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了
-
当然了如果函数中执行到了return也会结束函数
-
函数名不可重复,和
java等其他语言不一样,后面的同名函数会覆盖掉前面的同名函数,如下代码所示def test(a): print(a) def test(a, b): print(a, b)定义的这两个函数,只有第二个函数是可用的。
函数文档
def add(a, b):
"""
计算两个参数经过 + 操作之后的结果
:param a: 第一个参数
:param b: 第二个参数
:return: 无返回值
"""
print(a + b)
add(1, 2)
将鼠标放到函数上,就会显示如下信息,十分美观:

函数参数
带有参数的函数
# 定义一个函数,实现两个数的和
def add(a, b): # a 和 b 称为是形式参数, 简称形参
c = a + b
print(a, b)
# 函数调用, 如果函数在定义的时候有形参,那么在函数调用的时候,必须传递参数值
# 这个参数称为 实际参数,简称实参
# 在函数调用的时候,会将实参的值传递给形参
add(1, 2)
# 可以通过指定参数的名称赋值,来改变传递参数的顺序,不过没有默认值的形参,调用函数时,必须传递对应参数的值
add(b=2, a=1)
缺省参数
缺省参数,形参,在函数定义的时候,给形参一个默认值,这个形参就是缺省参数,
注意: 缺省参数要写在普通参数的最后边
特点: 在函数调用的时候,如果给缺省参数传递了实参值,使用的是传递的实参值,如果没有传递,使用默认值
# print()
def func(a, b, c=10): # 形参c 称为缺省形参
print(f"a: {a}")
print(f"b: {b}")
print(f"c: {c}")
func(1, 2) # 没有给c 传递实参,使用默认值10
func(1, 2, 3) # 给c传递实参值,使用传递的数据3
缺省参数在*args后面
def sum_nums_3(a, *args, b=22, c=33, **kwargs):
print(a)
print(b)
print(c)
print(args)
print(kwargs)
sum_nums_3(100, 200, 300, 400, 500, 600, 700, b=1, c=2, mm=800, nn=900)
如果很多个值都是不定长参数,这种情况下,可以将缺省参数放到 *args 的后面, 但如果有**kwargs的话,**kwargs必须放在最后。
不定长参数
格式:
def functionname([formal_args,] *args, **kwargs):
"""函数_文档字符串"""
function_suite
return [expression]
在形参前边加上一个*, 该形参变为不定长元组形参,可以接收所有位置的实参, 类型是元组
在形参前边加上两个**, 该形参变为不定长字典形参, 可以接收所有的关键字实参,类型是字典
案例:
>>> # 第一个和第二个是普通参数,必须传递,第三个以元组形式保存所有非字典形参,第三个以字典形式保存所有 k-v 对
>>> def fun(a, b, *args, **kwargs):
... """可变参数演示示例"""
... print("a =%d" % a)
... print("b =%d" % b)
... print("args:")
... print(args)
... print("kwargs: ")
... for key, value in kwargs.items():
... print("key=%s" % value)
...
>>> fun(1, 2, 3, 4, 5, m=6, n=7, p=8) # 注意传递的参数对应
a = 1
b = 2
args:
(3, 4, 5)
kwargs:
p = 8
m = 6
n = 7
>>>
>>>
>>> c = (3, 4, 5)
>>> d = {"m":6, "n":7, "p":8}
>>> fun(1, 2, *c, **d) # 注意元组与字典的传参方式
a = 1
b = 2
args:
(3, 4, 5)
kwargs:
p = 8
m = 6
n = 7
>>>
>>>
>>> fun(1, 2, c, d) # 注意不加星号与上面的区别:不添加星号,则所有形参都会被第三个形参以元组的形式接收
a = 1
b = 2
args:
((3, 4, 5), {'p': 8, 'm': 6, 'n': 7})
kwargs:
>>>
函数参数的完整形式
# 普通形参 缺省形参 不定长元组形参 不定长字典形参
def func(a, b=1): # 先普通再 缺省
pass
def func1(a, b=1, *args): # 语法上不会报错,但是缺省参数不能使用默认值
print('a', a)
print('b', b)
print(args)
def func2(a, *args, b=1): # 普通形参 不定长元组形参 缺省形参
print('a', a)
print('b', b)
print(args)
def func3(a, *args, b=1, **kwargs): # 普通形参 不定长元组形参 缺省形参 不定长字典形参
pass
函数返回值
格式:
def add2num(a, b):
c = a+b
return c
# 或者
def add2num(a, b):
return a+b
函数通过 return 语句来返回数据,函数有 return 语句,说明函数有返回值,反之则表示没有返回值。
案例:
# 函数想要返回一个数据值,给调用的地方,需要使用关键字 return
# return 关键字的作用: ①, 将return 后边的数据值进行返回 ②,程序代码遇到return, 会终止(结束)执行
# 注意: return 关键字必须写在函数中
def add(a, b):
c = a + b
# 想要将求和的结果 c, 返回,即函数外部使用求和的结果, 不在函数内部打印结果
return c
print(f'求和的结果是{c}') # 函数遇到return就结束了,不会执行return之后的代码
result = add(100, 200)
print(f'函数外部获得了求和的结果{result}') # 函数外部获得了求和的结果300
print(add(10, 30)) # 40
返回多个值
def func(a, b):
c = a + b
d = a - b
# 需求: 想要将 c 和 d 都进行返回
# 实现: 将 c 和 d 放到容器中进行返回
# return [c, d],以列表形式返回
# return (c, d),以元组形式返回
# return {'c': c, 'd': d},以字典形式返回
# return {0: c, 1: d},以字典形式返回
return c, d # 如果 retruan 语句后面是多个返回值,则默认组成元组进行返回
result = func(10, 20)
print(f"a+b的结果是{result[0]}, a-b的结果是{result[1]}")
多个return语句
根据不同的条件,函数返回不同的结果
def create_nums(num):
if num == 100:
return num + 1
else:
return num + 2
result1 = create_nums(100)
print(result1) # 打印101
result2 = create_nums(200)
print(result2) # 打印202
函数的嵌套调用
一个函数里面又调用了另外一个函数,这就是函数嵌套调用
def testB():
print('---- testB start----')
print('这里是testB函数执行的代码...(省略)...')
print('---- testB end----')
def testA():
print('---- testA start----')
testB()
print('---- testA end----')
testA()
结果:
---- testA start----
---- testB start----
这里是testB函数执行的代码...(省略)...
---- testB end----
---- testA end----
局部变量和全局变量
局部变量
# 局部变量, 就是在函数内部定义的变量
# 局部变量,只能在函数内部使用,不能在函数外部和其他函数中使用
# 因为其作用范围只是在自己的函数内部,所以不同的函数可以定义相同名字的局部变量
# 当函数调用时,局部变量被创建,当函数调用完成后这个变量就不能够使用了
def func1():
# 定义局部变量 num
num = 100
print(num)
def func2():
num = 200 # 这个num 和 func 中的num 是没有关系的
print(num)
全局变量
# 全局变量: 就是在函数外部定义的变量,它既能在一个函数中使用,也能在其他的函数中使用
# 定义全局变量
g_num = 100
# 1. 可以直接在函数中访问全局变量的值
def func1():
print(g_num)
# 2. 不能直接在函数内修改全局变量的值
def func2():
# g_num = 200 # 这里并不是修改全局变量的值,而是定义一个局部变量,并且和全局变量的名字一样而已,后面的代码访问的时候,访问的也是该局部变量
# 想要在函数内部修改全局变量的值,需要使用 global 关键字表明这个变量为全局变量
global g_num
g_num = 300
func1() # 100
func2()
func1() # 300
如果在一个函数中需要对多个全局变量进行修改,那么可以使用
global a, b
当然写多条 global 语句也是可以的
拆包
对返回值的多个值拆包
def get_my_info():
high = 178
weight = 100
age = 18
return high, weight, age
result = get_my_info()
print(result) # (178, 100, 18)
my_high, my_weight, my_age = get_my_info()
print(my_high) # 178
print(my_weight) # 100
print(my_age) # 18
拆包时要注意,需要拆的数据的个数要与变量的个数相同,否则程序会异常
对元组、列表、字典等拆包
a, b = (11, 22)
print(a) # 11
print(b) # 22
a, b = [33, 44]
print(a) # 33
print(b) # 44
# 取出来的是key,而不是键值对
a, b = {"m":11, "n":22}
print(a) # m
print(b) # n
交换两个变量的值
a, b = 4, 5
a, b = b, a
引用
可以使用 id() 函数查看变量的引用, 可以将 id 值认为是内存地址的别名
python中数据值的传递的是引用
赋值运算符可以改变变量的引用
数字:
# 将数据10 存储到变量a 中, 本质是将数据10 所在内存的引用地址保存到变量a 中
a = 10
# 将变量a中保存的引用地址给给到b
b = a
print(a, b) # 使用print函数打印变量a 和b 引用中存储的值,结果为:10 10
print(id(a), id(b)) # 140708913223728 140708913223728,地址一样,说明变量 a 和 b 指向同一块地址
a = 20
print(a, b) # 20 10
print(id(a), id(b)) # 140708913224048 140708913223728,变量 a 的地址发生了变化,说明重新给 a 赋值的操作,是将新变量的内存地址重新赋值给了 a
a = 100
a += 1 # += 是直接对a指向的空间进行修改,而不是让a指向一个新的
a = a + 1 # xx = xx+yyy 先把=号右边的结果计算出来,然后让a指向这个新的地方,不管原来a指向谁,现在a一定指向这个新的地方
列表:
my_list = [1, 2, 3] # 将列表的引用地址保存到变量 my_list 中
my_list1 = my_list # 将 my_list 变量中存储的引用地址赋值给 my_list1
print(my_list, id(my_list)) # [1, 2, 3] 2062004223040
print(my_list1, id(my_list1)) # [1, 2, 3] 2062004223040
my_list.append(4) # 向列表中添加数据4
print(my_list, id(my_list)) # [1, 2, 3, 4] 2062004223040
print(my_list1, id(my_list1)) # [1, 2, 3, 4] 2062004223040
my_list[2] = 5 # 改变下标为 2 的位置的值
print(my_list, id(my_list)) # [1, 2, 5, 4] 2062004223040
print(my_list1, id(my_list1)) # [1, 2, 5, 4] 2062004223040
从结果中可以看到,两个变量指向的都是同一块地址,因此修改任何一个变量存储的内容,都会直接作用到实际内存中。
引用当做函数参数传递
# 函数传参传递的也是引用
my_list = [1, 2, 3] # 全局变量
def func1(a):
a.append(4)
def func2():
# 为啥不加global, 因为没有修改 my_list 中存的引用值
my_list.append(5)
def func3():
global my_list
my_list = [6, 7, 8] # 修改全局变量的值
def func4(a):
# += 对于列表来说,类似列表的extend方法,不会改变变量的引用地址
a += a # a = a + a, 修改了a变量a的引用
func1(my_list)
print(my_list) # [1, 2, 3, 4]
func2()
print(my_list) # [1, 2, 3, 4, 5]
func3()
print(my_list) # [6, 7, 8]
func4(my_list)
print(my_list) # [6, 7, 8, 6, 7, 8]
总结:
- Python中函数参数是引用传递(注意不是值传递)
- 对于不可变类型,因变量不能修改,所以运算不会影响到变量自身
- 而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量
递归函数
def calNum(num):
"""
求 num 的阶乘
:param num: 求几的阶乘
:return: 阶乘结果
"""
if num > 1:
result = num * calNum(num - 1)
else:
result = 1
return result
print(calNum(5)) # 120
匿名函数
格式:
lambda [形参1], [形参2], ... : [单行表达式] 或 [函数调用]
案例,普通函数和匿名函数的对比:
# 1. 无参无返回值
def func1():
print('hello')
f1 = lambda: print('hello lambda')
# 2. 无参有返回值
def func2():
return 1 + 2
f2 = lambda: 1 + 2
print(f2())
# 3. 有参无返回值
def func3(name):
print(name)
f3 = lambda name: print(name)
f3('hwllo')
# 4. 有参有返回值
def func4(*args):
return args
f4 = lambda *args: args
匿名函数和普通函数的区别:
- 匿名函数中不能使用 if 语句、while 循环、for 循环, 只能编写单行表达式,或普通函数调用.
- 匿名函数中返回结果不需要使用 return, 表达式的运行结果就是返回结果, 普通函数返回结果必须写
return. - 匿名函数中也可以不返回结果. 例如:
lambda : print('hello world')
匿名函数作为函数参数
def my_calc(a, b, func):
"""
进行四则运算
:param a: 第一个数据
:param b: 第二个数据
:param func: 函数,要进行的运算
:return: 运算的结果
"""
num = func(a, b)
print(num)
def add(a, b):
return a + b
# 调用
my_calc(10, 20, add) # 30
my_calc(10, 20, lambda a, b: a - b) # -10
my_calc(10, 20, lambda a, b: a * b) # 200
my_calc(10, 20, lambda a, b: a / b) # 0.5
函数可以作为参数传递给另外一个函数, 可以使得函数的实现更加通用,对于只需要用到一次函数, 可以通过匿名函数减少代码量.
列表排序应用匿名函数
# 列表排序, 列表中的数据的类型要保持一致
my_list = [1, 3, 5, 4, 2, 1]
my_list.sort()
print(my_list) # [1, 1, 2, 3, 4, 5]
list1 = [{'name': 'd', 'age': 19},
{'name': 'b', 'age': 16},
{'name': 'a', 'age': 16},
{'name': 'c', 'age': 20}]
# list1.sort() # 程序报错,字典类型数据不能直接排序
# 匿名函数的形参是列表中的每一个数据
list1.sort(key=lambda x: x['name'])
print(list1) # [{'name': 'a', 'age': 16}, {'name': 'b', 'age': 16}, {'name': 'c', 'age': 20}, {'name': 'd', 'age': 19}]
list1.sort(key=lambda x: x['age'])
print(list1) # [{'name': 'a', 'age': 16}, {'name': 'b', 'age': 16}, {'name': 'd', 'age': 19}, {'name': 'c', 'age': 20}]
list2 = ['aghdd', 'bc', 'ghlj', 'def', 'ab']
list2.sort()
print(list2) # ['ab', 'aghdd', 'bc', 'def', 'ghlj']
# 需求: 根据列表中字符串的长度,列表进行排序
# 下面这两种实现效果一样
list2.sort(key=len)
list2.sort(key=lambda x: len(x))
print(list2) # ['ab', 'bc', 'def', 'ghlj', 'aghdd']
# sort(key= lambda 形参: (排序规则1, 排序规则2, ...))
# 当第一个规则比较结果相同时,会按照第二个规则排序
list1.sort(key=lambda x: (x['age'], x['name']))
print(list1) # [{'name': 'a', 'age': 16}, {'name': 'b', 'age': 16}, {'name': 'd', 'age': 19}, {'name': 'c', 'age': 20}]
list1.sort(key=lambda x: (x['age'], x['name']), reverse=True)
print(list1) # [{'name': 'c', 'age': 20}, {'name': 'd', 'age': 19}, {'name': 'b', 'age': 16}, {'name': 'a', 'age': 16}]
列表推导式
列表推导式, 为了快速的生成一个列表。
# 1. 变量 = [生成数据的规则 for 临时变量 in xxx]
# 每循环一次,就会创建一个数据
my_list = [i for i in range(5)]
print(my_list) # [0, 1, 2, 3, 4]
my_list1 = ['hello' for i in range(5)]
print(my_list1) # ['hello', 'hello', 'hello', 'hello', 'hello']
my_list2 = [f'num:{i}' for i in my_list]
print(my_list2) # ['num:0', 'num:1', 'num:2', 'num:3', 'num:4']
my_list3 = [i + i for i in range(5)]
print(my_list3) # [0, 2, 4, 6, 8]
# 2. 变量 = [生成数据的规则 for 临时变量 in xxx if xxx]
# 每循环一次,并且if条件为True,生成一个数据
my_list = [i for i in range(5) if i % 2 == 0]
print(my_list) # [0, 2, 4]
# 3. 变量 = [生成数据的规则 for 临时变量 in xxx for j in xxx]
# 第二个for 循环,循环一次,生成一个数据
my_list4 = [(i, j) for i in range(3) for j in range(3)]
print(my_list4) # [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
字典推导式
# 变量 = {生成字典的规则 for 临时变量 in xx}
# my_dict = {key: value for i in range(3)}
my_dict = {f"name{i}": i for i in range(3)}
print(my_dict) # {'name0': 0, 'name1': 1, 'name2': 2}
my_dict = {f"name{i}": j for i in range(3) for j in range(3)}
print(my_dict) # {'name0': 2, 'name1': 2, 'name2': 2}
my_dict = {f"name{i}{j}": j for i in range(3) for j in range(3)}
print(my_dict) # {'name00': 0, 'name01': 1, 'name02': 2, 'name10': 0, 'name11': 1, 'name12': 2, 'name20': 0, 'name21': 1, 'name22': 2}
set集合
集合 set 定义使用 {} ,格式为:{数据, 数据}
# 1. 集合中的元素必须是不可变类型
my_set = {1, 3.14, False, 'hello', (1, 2)}
print(my_set, type(my_set)) # {False, 1, (1, 2), 3.14, 'hello'} <class 'set'>
# my_set = {[1, 2]} # 代码报错
# 2. 集合是可变类型
my_set.remove(3.14) # {False, 1, (1, 2), 'hello'}
print(my_set)
my_set.pop() # {1, (1, 2), 'hello'}
print(my_set)
print('----')
my_set.add(100)
print(my_set) # {1, (1, 2), 100, 'hello'}
# 修改数据 100 ---> 200
my_set.remove(100)
my_set.add(200)
print(my_set) # {1, (1, 2), 'hello', 200}
my_set.clear()
print(my_set) # set()
# 3. 集合是无序的,不支持下标操作
# 4. 集合中的没有重复数据(去重)
my_list = [1, 2, 3, 4, 2, 5, 1, 0]
print(set(my_list)) # [0, 1, 2, 3, 4, 5]
# 集合, 列表, 元组 三者之间可以互相转换
print(list(my_list), type(list(my_list))) # [1, 2, 3, 4, 2, 5, 1, 0] <class 'list'>
print(set(my_list), type(set(my_list))) # {0, 1, 2, 3, 4, 5} <class 'set'>
print(tuple(my_list), type(tuple(my_list))) # (1, 2, 3, 4, 2, 5, 1, 0) <class 'tuple'>
文件
读取
函数:
open(file, mode='r', encoding)
file 要操作的文件名字, 类型是 string
mode, 文件打开的方式, r(read) 只读打开, w(write) 只写打开, a(append) 追加打开
encoding 文件的编码格式, 常见的编码格式有两种, 一种是gbk, 一种是utf-8
返回值, 文件对象, 后续所有的文件操作,都需要通过这个文件对象进行
read
# 以只读的方式打开当前目录中 1.txt 文件, 文件不存在会报错。如果是使用 r 模式,则参数 r 可以省略不写
f = open('1.txt', 'r')
# 2. 读文件 文件对象.read()
buf = f.read()
print(buf)
# read 函数的参数表示一次读取多少内容,如果读取方式为 r ,则表示读取多少字符,如果读取方式为 rb ,则表示读取多少字节,可用于二进制文件操作
buf = f.read(3)
print(buf)
# 3. 关闭文件 文件.close()
f.close()
readlines
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行数据为列表的一个元素。
f = open('test.txt', 'r')
content = f.readlines()
readline
f = open('test.txt', 'r')
# 每次调用只会读取一行,所以要多去多行数据,需要放到循环中不断调用
content = f.readline()
content = f.readline()
追加
以 a 方式打开文件, 追加内容,在文件的末尾写入内容
文件不存在,会创建文件
注意: 不管是 a 方式打开文件,还是 w 方式打开文件,写内容,都是使用 write()函数
f = open('b.txt', 'a', encoding='utf-8')
f.write('111\n')
f.close()
模拟读取大文件
f = open('a.txt', 'r', encoding='utf-8')
while True:
buf = f.readline()
if buf: # if len(buf) > 0 容器可以直接作为判断条件,容器中有内容,为True,没有数据是False
print(buf, end='')
else:
# 文件读完了
break
f.close()
f = open('b.txt', 'r', encoding='utf-8')
while True:
buf = f.read(5) # f.read(4096)
if buf:
# print(buf, end='')
print(buf)
else:
break
f.close()
写入
# 1. 打开文件 w 方式打开文件,文件不存在,会创建文件, 文件存在,会覆盖清空原文件
f = open('a.txt', 'w', encoding='utf-8')
# 2. 写文件 文件对象.write(写入文件的内容)
f.write('hello world!\n')
f.write('hello python!\n')
f.write('你好,中国!')
# 3. 关闭文件
f.close()
二进制操作
f = open('c.txt', 'wb')
f.write('hello, 你好'.encode()) # encode() 将str 转换为二进制格式的字符串
f.close()
f1 = open('c.txt', 'rb')
buf = f1.read()
print(buf) # b'hello, \xe4\xbd\xa0\xe5\xa5\xbd'
print(buf.decode()) # hello, 你好
f1.close()
文件 c.txt 内容为
hello, 你好
文件备份
# 提示输入文件
old_file_name = input("请输入要拷贝的文件名字:")
# 以读的方式打开文件
old_file = open(old_file_name,'rb')
# 提取文件的后缀
file_flag_num = old_file_name.rfind('.')
if file_flag_num > 0:
file_flag = old_file_name[file_flag_num:]
# 组织新的文件名字
new_file_name = old_file_name[:file_flag_num] + '[复件]' + file_flag
# 创建新文件
new_file = open(new_file_name, 'wb')
# 把旧文件中的数据,一行一行的进行复制到新文件中
for live_content in old_file.readlines():
new_file.write(live_content)
# 关闭文件
old_file.close()
new_file.close()
文件和目录操作
# 对文件和目录的操作,需要导入 os 模块
import os
# 1. 文件重命名 os.rename(原文件路径名, 新文件路径名)
os.rename('a.txt', 'aa.txt')
# 2. 删除文件 os.remove(文件的路径名)
os.remove('aa.txt')
# 3. 创建目录 os.mkdir(目录路径名) make directory
os.mkdir('test')
os.mkdir('test/aa')
# 4. 删除空目录 os.rmdir(目录名) remove directory
os.rmdir('test/aa')
# 5. 获取当前所在的目录 os.getcwd() get current working directory
buf = os.getcwd()
print(buf) # D:\PYWorkspace\study\教学项目\07-代码
# 6. 修改当前的目录 os.chdir(目录名) change dir
os.chdir('test')
buf = os.getcwd()
print(buf) # D:\PYWorkspace\study\教学项目\07-代码\test
# 7. 获取指定目录中的内容, os.listdir(目录), 默认不写参数,是获取当前目录中的内容
# 返回值是列表, 列表中的每一项是文件名
buf = os.listdir() # 当前所在目录是:test
print(buf) # ['03-模拟读取大文件.py', '04-模拟读取大文件2.py', '05-二进制方式操作文件.py']
面向对象
类
类(Class) 由3个部分构成
- 名称:类名
- 属性:一组数据
- 方法:允许对进行操作的方法 (行为)
格式:
class 类名(object):
类中的代码
案例:
# class Hero: # 经典类(旧式类)定义形式
# class Hero(): # 经典类(旧式类)定义形式
class Hero(object): # 新式类定义形式
def info(self):
print("英雄各有见,何必问出处。")
说明:
- 定义类时有2种形式:新式类和经典类,上面代码中的Hero为新式类,前两行注释部分则为经典类;
object是 Python 里所有类的最顶级父类;- 类名的命名规则按照"大驼峰命名法";
info是一个实例方法,第一个参数一般是self,表示实例对象本身,也可以将self换为其它的名字,其作用是一个变量,这个变量指向了实例对象
对象
创建对象
格式:
对象名1 = 类名()
对象名2 = 类名()
对象名3 = 类名()
每条语句都会创建一个新的对象。
案例:
class Hero(object): # 新式类定义形式
"""info 是一个实例方法,类对象可以调用实例方法,实例方法的第一个参数一定是self"""
def info(self):
"""当对象调用实例方法时,Python会自动将对象本身的引用做为参数,传递到实例方法的第一个参数self里"""
print(self)
# 实例化对象
a = Hero()
b = Hero()
# 对象调用实例方法info(),执行info()里的代码
# . 表示选择属性或者方法
a.info() # <__main__.Hero object at 0x000002C480FA8940>
print(a) # 打印对象,则默认打印对象在内存的地址,结果等同于info里的print(self),结果为:<__main__.Hero object at 0x000002C480FA8940>
print(id(a)) # id(taidamier) 则是内存地址的十进制形式表示,结果为:3043000748352
print(id(b)) # 3043001131216
类外部添加和获取对象数据
class Hero(object):
"""定义了一个英雄类,可以移动和攻击"""
def move(self):
"""实例方法"""
print("正在前往事发地点...")
def attack(self):
"""实例方法"""
print("发出了一招强力的普通攻击...")
# 实例化了一个英雄对象 泰达米尔
taidamier = Hero()
# 给对象添加属性,以及对应的属性值
taidamier.name = "泰达米尔" # 姓名
taidamier.hp = 2600 # 生命值
taidamier.atk = 450 # 攻击力
taidamier.armor = 200 # 护甲值
# 通过.成员选择运算符,获取对象的属性值
print("英雄 %s 的生命值 :%d" % (taidamier.name, taidamier.hp)) # 英雄 泰达米尔 的生命值 :2600
print("英雄 %s 的攻击力 :%d" % (taidamier.name, taidamier.atk)) # 英雄 泰达米尔 的攻击力 :450
print("英雄 %s 的护甲值 :%d" % (taidamier.name, taidamier.armor)) # 英雄 泰达米尔 的护甲值 :200
# 通过.成员选择运算符,获取对象的实例方法
taidamier.move() # 正在前往事发地点...
taidamier.attack() # 发出了一招强力的普通攻击...
类内部获取外部对象数据
class Hero(object):
"""定义了一个英雄类,可以移动和攻击"""
def move(self):
"""实例方法"""
print("正在前往事发地点...")
def attack(self):
"""实例方法"""
print("发出了一招强力的普通攻击...")
def info(self):
"""在类的实例方法中,通过self获取该对象的属性"""
print("英雄 %s 的生命值 :%d" % (self.name, self.hp))
print("英雄 %s 的攻击力 :%d" % (self.name, self.atk))
print("英雄 %s 的护甲值 :%d" % (self.name, self.armor))
# 实例化了一个英雄对象 泰达米尔
taidamier = Hero()
# 给对象添加属性,以及对应的属性值
taidamier.name = "泰达米尔" # 姓名
taidamier.hp = 2600 # 生命值
taidamier.atk = 450 # 攻击力
taidamier.armor = 200 # 护甲值
# 通过.成员选择运算符,获取对象的实例方法
taidamier.info() # 只需要调用实例方法info(),即可获取英雄的属性,此时打印的就是该对象的属性值
taidamier.move() # 正在前往事发地点...
taidamier.attack() # 发出了一招强力的普通攻击...
taidamier2 = Hero()
# 如果对象没有设置调用的方法中需要的那些属性,则会报错:AttributeError: 'Hero' object has no attribute 'name'
taidamier2.info()
魔法方法
Python 的类里提供的,两个下划线开始,两个下划线结束的方法,就是魔法方法。
__init__()方法
init()是一个魔法方法,通常用来做属性初始化 或 赋值 操作。
如果类面没有写__init__()方法,Python会自动创建,但是不执行任何操作。
如果为了能够在完成自己想要的功能,可以自己定义__init__()方法。
所以一个类里无论自己是否编写了__init__()方法 一定有__init__()方法。
案例:
class Hero(object):
"""定义了一个英雄类,可以移动和攻击"""
def __init__(self):
""" 该用来做变量初始化 或 赋值 操作,在类实例化对象的时候,会被自动调用"""
self.name = "泰达米尔" # 姓名
self.hp = 2600 # 生命值
self.atk = 450 # 攻击力
self.armor = 200 # 护甲值
def info(self):
"""在类的实例方法中,通过self获取该对象的属性"""
print("英雄 %s 的生命值 :%d" % (self.name, self.hp))
print("英雄 %s 的攻击力 :%d" % (self.name, self.atk))
print("英雄 %s 的护甲值 :%d" % (self.name, self.armor))
def move(self):
"""实例方法"""
print("正在前往事发地点...")
def attack(self):
"""实例方法"""
print("发出了一招强力的普通攻击...")
# 实例化了一个英雄对象,并自动调用__init__()方法
taidamier = Hero()
# 通过.成员选择运算符,获取对象的实例方法
taidamier.info() # 只需要调用实例方法info(),即可获取英雄的属性
print('-' * 30)
taidamier.move()
taidamier.attack()
结果:
英雄 泰达米尔 的生命值 :2600
英雄 泰达米尔 的攻击力 :450
英雄 泰达米尔 的护甲值 :200
------------------------------
正在前往事发地点...
发出了一招强力的普通攻击...
有参数的__init__()方法
class Hero(object):
"""定义了一个英雄类,可以移动和攻击"""
def __init__(self, name, skill, hp, atk, armor):
""" __init__() 方法,用来做变量初始化 或 赋值 操作"""
# 英雄名
self.name = name
# 技能
self.skill = skill
# 生命值:
self.hp = hp
# 攻击力
self.atk = atk
# 护甲值
self.armor = armor
def move(self):
"""实例方法"""
print("%s 正在前往事发地点..." % self.name)
def attack(self):
"""实例方法"""
print("发出了一招强力的%s..." % self.skill)
def info(self):
print("英雄 %s 的生命值 :%d" % (self.name, self.hp))
print("英雄 %s 的攻击力 :%d" % (self.name, self.atk))
print("英雄 %s 的护甲值 :%d" % (self.name, self.armor))
# 实例化英雄对象时,参数会传递到对象的__init__()方法里
taidamier = Hero("泰达米尔", "旋风斩", 2600, 450, 200)
gailun = Hero("盖伦", "大宝剑", 4200, 260, 400)
# 创建的两个对象的内存地址不同,说明这是两个不同的对象
print(gailun) # <__main__.Hero object at 0x0000017F1D9A60D0>
print(taidamier) # <__main__.Hero object at 0x0000017F1D948940>
# 不同对象的属性值的单独保存
print(id(taidamier.name)) # 1645469893328
print(id(gailun.name)) # 1645469017264
# 同一个类的不同对象,实例方法共享
print(id(taidamier.move())) # 140715264809088
print(id(gailun.move())) # 140715264809088
说明:
- 通过一个类,可以创建多个对象
__init__(self)中,默认有1个参数,名为self,如果在创建对象时传递了2个实参,那么__init__(self)中除了self作为第一个形参外,还需要2个形参,例如__init__(self,x,y)
注意:
- 在类内部获取 属性 和 实例方法,通过
self获取。 - 在类外部获取 属性 和 实例方法,通过
对象名获取。 - 如果一个类有多个对象,则每个对象的属性是各自保存的,都有各自独立的地址。
- 类的实例方法是所有对象共享的,只占用一份内存空间,类会通过self来判断是哪个对象调用了实例方法。
__str__()方法
class Hero(object):
"""定义了一个英雄类,可以移动和攻击"""
def __init__(self, name, skill, hp, atk, armor):
""" __init__() 方法,用来做变量初始化 或 赋值 操作"""
# 英雄名
self.name = name # 实例变量
# 技能
self.skill = skill
# 生命值:
self.hp = hp # 实例变量
# 攻击力
self.atk = atk
# 护甲值
self.armor = armor
def move(self):
"""实例方法"""
print("%s 正在前往事发地点..." % self.name)
def attack(self):
"""实例方法"""
print("发出了一招强力的%s..." % self.skill)
def info(self):
print("英雄 %s 的生命值 :%d" % (self.name, self.hp))
print("英雄 %s 的攻击力 :%d" % (self.name, self.atk))
print("英雄 %s 的护甲值 :%d" % (self.name, self.armor))
def __str__(self):
"""
这个方法是一个魔法方法 (Magic Method) ,用来显示信息
该方法需要 return 一个数据,并且只有self一个参数,当在类的外部 print(对象) 时,则打印该方法的返回值,类似于 java 中重写的的 toString 方法
"""
return "英雄 <%s> 数据: 生命值 %d, 攻击力 %d, 护甲值 %d" % (self.name, self.hp, self.atk, self.armor)
taidamier = Hero("泰达米尔", "旋风斩", 2600, 450, 200)
gailun = Hero("盖伦", "大宝剑", 4200, 260, 400)
# 如果没有__str__ 则默认打印 对象在内存的地址。
# 当类的实例化对象 拥有 __str__ 方法后,那么打印对象则打印 __str__ 的返回值。
print(taidamier) # 英雄 <泰达米尔> 数据: 生命值 2600, 攻击力 450, 护甲值 200
print(gailun) # 英雄 <盖伦> 数据: 生命值 4200, 攻击力 260, 护甲值 400
# 查看类的文档说明,也就是类的注释
print(Hero.__doc__) # 定义了一个英雄类,可以移动和攻击
说明:
- 在python中,方法名如果是
__xxxx__()形式,就说明该方法有特殊的功能,因此叫做“魔法”方法。 - 当使用print输出对象的时候,默认打印对象的内存地址。如果类定义了
__str__(self)方法,那么就会打印从在这个方法中return的数据 __str__()方法通常返回一个字符串,作为这个对象的描述信息。
__repr__()方法
__repr__()方法和__str__()方法十分类似,都是返回一些对象的信息。
__str__()方法默认会被 print 方法调用,返回的多是一些可用人阅读的形式。__repr__()方法返回的信息,主要是给编辑器使用。- 默认情况下,他们返回的都是对象的内存地址。
class Dog(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f'{self.name}, {self.age}'
def __repr__(self):
"""repr 方法和 str 方法非常类似,也是必须返回一个字符串"""
return f"{self.name}"
# 将三个Dog类的对象添加到列表中
my_list1 = [Dog('大黄', 2), Dog('小白', 4), Dog('小花', 6)]
print(my_list1) # [大黄, 小白, 小花]
dog = Dog('大黄', 2)
print(dog) # 大黄, 2
__del__()方法
class Dog(object):
def __init__(self, name, age):
# 添加属性
self.name = name
self.age = age
def __str__(self):
# 必须返回一个字符串
return f"小狗的名字是{self.name}, 年龄是{self.age}"
def __del__(self):
print(f'我是__del__ 方法,我被调用了, {self.name}被销毁了.......')
dog = Dog('小花', 3) # 小花 引用计数为1
dog2 = dog # 小花 引用计数2
print('第一次删除之前')
del dog # dog 变量不能使用, 小花对象引用计数 1
print('第一次删除之后')
print('第二次删除之前')
del dog2 # dog2变量不能使用, 小花对象的引用计数为 0, 会立即__del__ 方法
print('第二次删除之后')
结果:
第一次删除之前
第一次删除之后
第二次删除之前
我是__del__ 方法,我被调用了, 小花被销毁了.......
第二次删除之后
总结
- 当有变量保存了一个对象的引用时,此对象的引用计数就会加1;
- 当使用
del()删除变量指向的对象时,则会减少对象的引用计数。如果对象的引用计数不为1,就会让这个对象的引用计数减1,当对象的引用计数为0的时候,对象会被真正删除(内存被回收)。
查看对象引用计数
import sys
class Dog(object):
pass
dog = Dog() # 1
print(sys.getrefcount(dog)) # 结果为2,显示的时候,会比实际的多一个,
dog1 = dog # 2
print(sys.getrefcount(dog)) # 结果为3,显示的时候,会比实际的多一个,
del dog # 1
print(sys.getrefcount(dog1)) # 结果为2,显示的时候,会比实际的多一个,
继承
- 在程序中,继承描述的是多个类之间的所属关系。
- 如果一个类A里面的属性和方法可以复用,则可以通过继承的方式,传递到类B里。
- 那么类A就是基类,也叫做父类;类B就是派生类,也叫做子类。
单继承
如果一个类只有一个父类,把这种继承关系称为单继承
# 1. 定义 动物类 animal
class Animal(object):
def play(self):
print('快乐的玩耍....')
# 2. 定义Dog类继承animal类
class Dog(Animal):
pass
# 3. 创建dog类对象.调用父类的方法
dog = Dog()
dog.play() # 快乐的玩耍....
多层继承
C–> B --> A
# 定义动物类 animal
class Animal(object): # 对于Animal类和object类来说,单继承
def play(self):
print('快乐的玩耍....')
# 定义Dog类继承animal类
class Dog(Animal): # Dog --> Animal 也是单继承, Dog --> Animal --> object 这种继承关系称为多层继承
def bark(self):
print('汪汪汪叫.......')
# 定义类 XTQ类, 继承 Dog类
# 多层继承中,子类可以使用所有继承链中的类中的方法和属性
class XTQ(Dog): # XTQ --> Dog 单继承, XTQ --> Dog --> Animal 类, 多层继承
pass
xtq = XTQ()
xtq.bark() # 调用父类Dog中的方法
xtq.play() # 调用爷爷类 animal类中的方法
多继承
继承多个父类
# 定义Dog类, 定义bark方法和 eat方法
class Dog(object):
def bark(self):
print('汪汪汪叫.....')
def eat(self):
print('啃骨头.....')
# 定义God类, 定义 play方法和eat方法
class God(object):
def play(self):
print('在云中飘一会....')
def eat(self):
print('吃蟠桃仙丹....')
# 定义XTQ类, 继承Dog类和God类
# XTQ 类有两个父类,这个继承关系称为多继承,XTQ类对象,可以调用两个父类中的属性和方法
class XTQ(God, Dog):
pass
# 创建XTQ类对象
xtq = XTQ()
xtq.bark() # 调用 Dog父类中的方法
xtq.play() # 调用 God父类中的方法
xtq.eat() # 两个父类都存在eat方法,子类对象调用的是 第一个父类中的方法
说明:
- 多继承可以继承多个父类,同时继承所有父类的属性和方法。
- 如果多个父类中有同名的属性和方法,则默认使用第一个父类的属性和方法。
- 多个父类中,不重名的属性和方法,不会有任何影响。
重写父类同名方法和属性
如果子类和父类的方法名和属性名相同,则默认使用子类的
# 定义Dog类, 书写bark方法, 输出 汪汪汪叫
class Dog(object):
def __init__(self):
self.name = 'dog'
def bark(self):
print('汪汪汪叫.........')
# 定义XTQ类,继承Dog类. 重写父类中的bark方法, 输出 嗷嗷嗷叫
class XTQ(Dog):
def __init__(self):
self.name = 'xtq'
def bark(self):
print('嗷嗷嗷叫--------')
# 创建Dog类对象
dog = Dog()
dog.bark() # 父类自己的,结果为:汪汪汪叫.........
print(dog.name) # dog
# 创建XTQ类对象
xtq = XTQ()
xtq.bark() # 子类自己的,结果为:嗷嗷嗷叫--------
print(xtq.name) # 子类自己的,结果为:xtq
supper()方法
# 定义Dog类, 定义bark方法,和 eat方法
class Dog(object):
def bark(self):
print('汪汪汪叫.....')
def eat(self):
print('啃骨头.....')
# 定义God类, 定义 play方法和eat方法
class God(object):
def play(self):
print('在云中飘一会....')
def eat(self):
print('吃蟠桃仙丹....')
# 定义XTQ类, 继承Dog类和God类
# XTQ 类有两个父类,这个继承关系称为多继承,XTQ类对象,可以调用两个父类中的属性和方法
class XTQ(God, Dog):
def eat(self):
print('子类重写eat方法,调用子类自己的方法')
# 调用指定父类中的方法
# 方法一 类名.方法名(self, 参数)
Dog.eat(self) # 啃骨头.....
God.eat(self) # 吃蟠桃仙丹....
# 方法二 super(类A, self).方法名(参数) 类A的父类(继承顺序链的下一个类)中的方法
super(XTQ, self).eat() # God 类中的方法,结果为:吃蟠桃仙丹....
super(God, self).eat() # 调用的Dog类中的方法,结果为:啃骨头.....
# super(Dog, self).eat() # 调用的object类中的方法,注意: object类中没有eat方法,代码报错,因为继承树中 Dog 类为最后一个类,再往后,就是 object 类了。
xtq = XTQ()
xtq.bark() # 调用 Dog父类中的方法,结果为:汪汪汪叫.....
xtq.play() # 调用 God父类中的方法,结果为:在云中飘一会....
xtq.eat() # 两个父类都存在eat方法,子类对象调用的是 第一个父类中的方法
# 类名.__mro__ 可以查看当前类的继承顺序链,也叫做方法的调用顺序
print(XTQ.__mro__) # (<class '__main__.XTQ'>, <class '__main__.God'>, <class '__main__.Dog'>, <class 'object'>)
重写后调用父类同名方法和属性
# 定义Dog类, 书写bark方法, 输出 汪汪汪叫
class Dog(object):
def bark(self):
print('汪汪汪叫.........')
# 定义XTQ类,继承Dog类. 重写父类中的bark方法, 输出 嗷嗷嗷叫
class XTQ(Dog):
def bark(self):
print('嗷嗷嗷叫--------')
def see_host(self):
# 调用本类中的其他方法,不管是普通方法,还是和父类同名的方法,都需要用 self.方法名() 的形式
self.bark()
"""看见主人之后,要汪汪汪叫,不能嗷嗷嗷叫"""
print('看见主人了:')
# 想要在子类中调用父类的同名方法
# 方法一: 父类名.方法名(self, 其他参数), 通过 实例对象.方法名() 调用方法,不需要给self传递实参值,python解释器会自动将对象作为实参值传递给self形参
# 如果是通过类名.方法() 调用,python解释器就不会自动传递实参值,需要手动给self形参传递实参值
Dog.bark(self)
# 方法二 super(当前类, self).方法名(参数) , 会调用当前类的父类中的方法
super(XTQ, self).bark() # 调用XTQ类父类中的bark方法
# 方法三 是方法二的简写, super().方法名(参数) ==> super(当前类, self).方法名()
super().bark()
# 创建XTQ类对象
xtq = XTQ()
xtq.see_host()
结果:
嗷嗷嗷叫--------
看见主人了:
汪汪汪叫.........
汪汪汪叫.........
汪汪汪叫.........
继承中的init方法
# 定义Dog类
class Dog(object):
def __init__(self, name):
# 添加属性
self.age = 0
self.name = name
def __str__(self):
return f'名字为:{self.name}, 年龄为{self.age}'
# 定义XTQ类继承Dog类
class XTQ(Dog):
# 子类重写了父类的__init__ 方法,默认不再调用父类的init方法, 需要手动的调用父类的init方法
# 如果不手动调用父类的 __init__ 方法,则父类中的属性就不会被初始化,子类中访问父类的属性时,就会报错:AttributeError: 'XTQ' object has no attribute 'name'
def __init__(self, name, color):
super().__init__(name)
self.color = color
def __str__(self):
return f'名字为:{self.name}, 年龄为{self.age}, 毛色为:{self.color}'
xtq = XTQ('小黑', '红色')
print(xtq) # 名字为:小黑, 年龄为0, 毛色为:红色
私有属性和方法
私有权限
面向对象三大特性:封装、继承、多态
封装的意义:
- 将属性和方法放到一起做为一个整体,然后通过实例化对象来处理;
- 隐藏内部实现细节,只需要和对象及其属性和方法交互就可以了;
- 对类的属性和方法增加访问权限控制。
私有权限:在属性名和方法名前面加上两个下划线 __
- 类的私有属性 和 私有方法,都不能通过对象直接访问,但是可以在本类内部访问;
- 类的私有属性 和 私有方法,都不会被子类继承,子类也无法访问;
- 私有属性 和 私有方法 往往用来处理类的内部事情,不通过对象处理,起到安全作用。
私有属性的值不能通过实例对象直接修改,只能通过定义普通方法来修改其私有属性的值。
私有属性
class People(object):
def __init__(self):
# 在属性名的前边加上 __ 前缀,将其变为私有属性
self.__ICBC_money = 0
def get_money(self):
return self.__ICBC_money
# 定义公有的方法,提供接口,修改余额,通过这个方式来修改私有属性的值
def set_money(self, money):
self.__ICBC_money += money
# 创建People类对象
xw = People()
# 实例对象.__dict__ 方法可以查看对象具有的属性信息,类型是字典,字典的key是属性名, 字典的value是属性值
print('赋值之前:', xw.__dict__) # 赋值之前: {'_People__ICBC_money': 0}
# print(xw.__ICBC_money) # 报错:AttributeError: 'People' object has no attribute '__ICBC_money'
xw.__ICBC_money = 1000 # 不是修改私有属性,是重新添加一个公有属性
print('赋值之后:', xw.__dict__) # 赋值之后: {'_People__ICBC_money': 0, '__ICBC_money': 1000}
print(xw.__ICBC_money) # 1000
print(xw.get_money()) # 0
xw.set_money(1000)
print(xw.get_money()) # 1000
xw.set_money(-500)
print(xw.get_money()) # 500
私有方法
class Dog(object):
def born(self):
"""生小狗的方法, 生一个小狗,休息30天"""
print('生了一只小狗...')
self.__sleep()
def __sleep(self):
print('休息30天')
dog = Dog()
# dog.__sleep() # 报错:AttributeError: 'Dog' object has no attribute '__sleep'
dog.born()
多态
在需要使用父类对象的地方,也可以使用子类对象, 这种情况就叫多态.
比如, 在函数中,我需要调用 某一个父类对象的方法, 那么我们也可以在这个地方调用子类对象的方法.
可以按照以下几个步骤在程序中使用多态:
- 子类继承父类
- 子类重写父类中的方法
- 通过对象调用这个方法
案例:
# 1. 定义DOg类
class Dog(object):
def __init__(self, name):
self.name = name
def play(self):
print(f'小狗{self.name} 在玩耍.......')
# 2. 定义哮天犬类,继承Dog类
class XTQ(Dog):
# 3. 重写 play方法
def play(self):
print(f'{self.name} 在天上追云彩.....')
# 该类并不是 Dog 的子类,但是因为他也有 play() 方法,因此它的对象也可以作为 play_with_dog() 方法的参数,然后被其调用 play() 方法。
class Cat(object):
def __init__(self, name):
self.name = name
def play(self):
print(f'小猫{self.name} 被撸中...')
# 4. 定义一个共同的方法,
def play_with_dog(obj_dog):
obj_dog.play()
# 创建Dog类对象@
dog = Dog('大黄')
play_with_dog(dog) # 小狗大黄 在玩耍.......
# 创建一个XTQ类的对象
xtq = XTQ('小黑')
play_with_dog(xtq) # 小黑 在天上追云彩.....
cat = Cat('小花')
play_with_dog(cat) # 小猫小花 被撸中...
多态的好处:
给play_with_dog(obj_dog)函数传递哪个对象,在它里面就会调用哪个对象的play()方法,也就是说在它里面既可以调用父类对象的play()方法,也能调用子类对象的play()方法,当然了也可以在它里面调用其他子类对象的play()方法,这样可以让play_with_dog(obj_dog)函数变得更加灵活,额外增加了它的功能,提高了它的扩展性.
另外,普通类,只要其有对应的方法,其实例对象也是可以作为play_with_dog(obj_dog)方法的参数的。
类属性和实例属性
在前面的例子中我们接触到的就是实例属性(对象属性),顾名思义,类属性就是类(类对象)所拥有的属性,它被所有类对象的对象(实例对象)所共有,在内存中只存在一个副本,这个和C++中类的静态成员变量有点类似。对于公有的类属性,在类外可以通过类对象和实例对象访问。
类属性
class People(object):
name = 'Tom' # 公有的类属性
__age = 12 # 私有的类属性
p = People()
print(p.name) # 正确
print(People.name) # 正确
print(p.__age) # 错误,不能在类外通过实例对象访问私有的类属性
print(People.__age) # 错误,不能在类外通过类对象访问私有的类属性
实例属性(对象属性)
class People(object):
address = '山东' # 类属性
def __init__(self):
self.name = 'xiaowang' # 实例属性
self.age = 20 # 实例属性
p = People()
p.age = 12 # 实例属性
print(p.address) # 正确
print(p.name) # 正确
print(p.age) # 正确
print(People.address) # 正确
print(People.name) # 错误,AttributeError: type object 'People' has no attribute 'name'
print(People.age) # 错误,AttributeError: type object 'People' has no attribute 'age'
通过实例(对象)去修改类属性
class People(object):
country = 'china' # 类属性
print(People.country) # china
p = People()
print(p.country) # china
p.country = 'japan'
print(p.country) # 实例属性会屏蔽掉同名的类属性,结果为:japan
print(People.country) # china
del p.country # 删除实例属性
print(p.country) # china
总结
如果需要在类外修改类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
静态方法和类方法
类方法
类对象所拥有的方法,需要用修饰器@classmethod来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls作为第一个参数(当然可以用其他名称的变量作为其第一个参数,但是大部分人都习惯以’cls’作为第一个参数的名字,就最好用’cls’了),能够通过实例对象和类对象去访问。
class People(object):
country = 'china'
# 类方法,用classmethod来进行修饰
@classmethod
def get_country(cls):
return cls.country
p = People()
print(p.get_country()) # 可以用过实例对象引用
print(People.get_country()) # 可以通过类对象引用
类方法还有一个用途就是可以对类属性进行修改:
class People(object):
country = 'china'
# 类方法,用classmethod来进行修饰
@classmethod
def get_country(cls):
return cls.country
@classmethod
def set_country(cls, country):
# 对类属性进行修改,类属性只在内存存在一份。
cls.country = country
p = People()
print(p.get_country()) # 可以用过实例对象访问,结果为:china
print(People.get_country()) # 可以通过类访问, 结果为:china
p.set_country('japan')
print(p.get_country()) # japan
print(People.get_country()) # japan
结果显示在用类方法对类属性修改之后,通过类对象和实例对象访问都发生了改变
静态方法
需要通过修饰器@staticmethod来进行修饰,静态方法可以有参数,也可以没有参数,可以通过对象和类来访问。
class People(object):
country = 'china'
# 静态方法
@staticmethod
def get_country():
return People.country
p = People()
# 通过对象访问静态方法
print(p.get_country()) # china
# 通过类访问静态方法
print(People.get_country()) # china
总结
- 从类方法和实例方法以及静态方法的定义形式就可以看出来,类方法的第一个参数是类对象cls,通过cls引用的必定是类的属性和方法;
- 实例方法的第一个参数是实例对象self,通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高。
- 静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类来引用.
异常
介绍
看如下示例:
open('123.txt','r')
运行结果:
FileNotFoundError: [Errno 2] No such file or directory: '123.txt'
说明:打开一个不存在的文件123.txt时,就会抛出一个IOError类型的错误,No such file or directory:123.txt (没有123.txt这样的文件或目录)
异常: 当Python检测到一个错误时,解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常"
异常捕获
在程序代码运行过程中,遇到错误, 不让程序代码终止,让其继续运行, 同时可以给使用者一个提示信息,并记录这个错误, 便于后期改进
try…except…
格式:
try:
可能发生异常的代码
except 异常的类型:
发生异常执行的代码
案例:
try:
print('-----test--1---')
open('123.txt', 'r')
print('-----test--2---')
except IOError:
pass
结果:
-----test--1---
说明:
- 使用
except捕获IOError异常,并添加了处理的方法,所以此程序看不到任何错误。 pass表示实现了相应的实现,但什么也不做;如果把pass改为print语句,就会输出其他信息
小总结:
- 把可能出现问题的代码,放在
try中 - 把处理异常的代码,放在
except中
except捕获多个异常
格式1:
try:
可能发生异常的代码
except (异常的类型1, 异常类型2, ...):
发生异常执行的代码
格式2:
try:
可能发生异常的代码
except 异常类型1:
发生异常1,执行的代码
except 异常类型2:
发生异常2,执行的代码
except ...:
pass
案例1:
# coding=utf-8
try:
print('-----test--1---')
open('123.txt', 'r') # 如果123.txt文件不存在,那么会产生 IOError 异常
print('-----test--2---')
print(num) # 如果num变量没有定义,那么会产生 NameError 异常
except (IOError, NameError):
# 如果想通过一个 except 捕获到多个异常,可以使用元组的方式
pass
注意:
- 当捕获多个异常时,可以把要捕获的异常的名字,放到
except后,并使用元组的方式进行存储
案例2:
num = input('请输入一个数字:')
try:
a = int(num)
num = 10 / a
print('计算得到的结果是:', num)
except ZeroDivisionError:
print('你输入有误,请再次输入')
except ValueError:
print('输入有误,请输入数字')
捕获所有类型异常
num = input('请输入一个数字:')
try:
a = int(num)
num = 10 / a
print('计算得到的结果是:', num)
f = open('1.txt', 'r')
except Exception:
# Exception 类是比较顶层的父类,所以可以捕获到所有类型的异常,最顶层的父类是:BaseException
print('你输入有误,请再次输入')
print('其他的代码......')
处理异常
格式:
try:
可能发生异常的代码
except (异常的类型1, 异常类型2, ...) as 变量名:
发生异常执行的代码
案例:
num = input('请输入一个数字:')
try:
a = int(num)
num = 10 / a
print('计算得到的结果是:', num)
except (ZeroDivisionError, ValueError) as e:
print('你输入有误,请再次输入', e)
异常完整结构
num = input('请输入一个数字:')
try:
a = int(num)
num = 10 / a
print('计算得到的结果是:', num)
except Exception as e:
print('你输入有误,请再次输入', e)
else:
print('没有发生异常,我才会执行')
finally:
print('不管有没有发生异常,我都会执行')
else
在try...except...中,如果没有捕获到异常,就会执行else中的事情。
finally
在程序中,如果一个段代码必须要执行,即无论是否发生了异常都要执行,此时就需要使用finally。 比如文件关闭,释放锁,把数据库连接返还给连接池等。
异常传递
在try嵌套中
num = input('请输入数字:')
try:
try:
a = int(num) # ValueError
except ZeroDivisionError as e:
print(f'内层捕获到异常:{e}')
finally:
print('内层 finally 代码块执行')
num = 10 / a
print(f'计算的结果<<{num}>>')
except Exception as e:
print(f'外层捕获到异常:{e}')
结果1:
请输入数字:0
内层 finally 代码块执行
外层捕获到异常:division by zero
结果2:
请输入数字:a
内层 finally 代码块执行
外层捕获到异常:invalid literal for int() with base 10: 'a'
解释:
- 输入0:由于内层
except捕获的是将输入转化为int的异常,所以输入数字 0 的时候,将0转化为int值并不会发生错误,但是外层的10/0会抛出异常,然后被外层捕获处理。 - 输入a:由于内层
except捕获的是将输入转化为int的异常,所以输入字母 a 的时候,将a转化为int值发生了额错误,但是内层捕获不到这个错误,因此这个错误会传递到外层,然后导致外层的num = 10 / a及其之后的代码并不会执行,而且这个错误会被外层的except捕获并处理。
自定义异常
异常/错误对象必须有一个名字,且它们应是Error或Exception类的子类
# 1. 定义异常类, 密码长度不足的异常
class PasswordLengthError(Exception):
# 如果定义了 __str__(self) 方法,则对捕获到的异常输出的信息为该方法返回的信息,否则为抛出异常时输入的信息。
# def __str__(self):
# return 'xxxxxx'
pass
def get_password(): # 等同于系统定义函数
password = input('请输入密码:')
if len(password) >= 8:
print('密码长度合格')
else:
# 抛出异常
raise PasswordLengthError('密码长度不足8位')
try:
get_password() # 调用系统的函数
except PasswordLengthError as e:
print(e)
结果:
请输入密码:1
密码长度不足8位
模块
导入方式
import
导入格式: import 模块名
调用格式:模块名.功能名
导入之后,调用时必须添加模块名前缀,防止和其他模块的功能名冲突。
案例:
import math
# 调用模块中的方法
print(math.fabs(-2)) # 2.0
# 调用模块中的属性
print(math.pi) # 3.141592653589793
from … import
导入格式:from 模块名 import 功能名1, 功能名2, ....
调用格式:功能名
这种导入方式,可以直接使用功能名去调用,因为不会有冲突。
案例:
from math import fabs, pi
# 调用模块中的方法
print(fabs(-2)) # 2.0
# 调用模块中的属性
print(pi) # 3.141592653589793
from ... import *
将模块中所有的功能进行导入。
导入格式:from 模块名 import *
调用格式:功能名
案例:
from math import *
# 调用模块中的方法
print(fabs(-2)) # 2.0
# 调用模块中的属性
print(pi) # 3.141592653589793
as
起别名,可以对模块和功能起别名,但是:如果使用as起了别名,就不能再使用原来的名字了。
导入格式1:import ... as ...
导入格式2:from ... import ... as ...
案例1:
import math as mt
# 调用模块中的方法
print(mt.fabs(-2)) # 2.0
# 调用模块中的属性
print(mt.pi) # 3.141592653589793
案例2:
from math import fabs as my_abs, pi as my_pi
# 调用模块中的方法
print(my_abs(-2)) # 2.0
# 调用模块中的属性
print(my_pi) # 3.141592653589793
定位模块
当导入一个模块后,Python解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python则搜索在shell变量
PYTHONPATH下的每个目录。 - 如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为
/usr/local/lib/python/ - 模块搜索路径存储在system模块的
sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
自定义模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件test.py,在test.py中定义了函数add
def add(a,b):
return a+b
那么在其他文件中就可以先import test,然后通过test.add(a,b)来调用了,当然也可以通过from test import add来引入
import test
result = test.add(11,22)
print(result)
__name__变量
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息,例如:
test.py
def add(a, b):
return a + b
name = 'abc'
# 用来进行测试
ret = add(12, 22)
print('int my_test.py file, 12+22=%d' % ret)
如果此时,在其他py文件中引入了此文件的话,想想看,测试的那段代码是否也会执行呢!
main.py
import test
result = test.add(11, 22)
print(result)
执行 main.py 代码,输出以下结果:
int my_test.py file, 12+22=34
33
test.py中的测试代码,应该是单独执行test.py文件时才应该执行的,在其他的文件中引用它时,是不应该执行的。
为了解决这个问题,python在执行一个文件时有个变量__name__
test.py
def add(a, b):
return a + b
name = 'abc'
print(f'__name__为:{__name__}')
直接执行该文件,结果为:__name__为:__main__
在其他文件中 import 此文件
import test
直接执行之后这一行代码的文件,结果为:__name__为:test
总结:可以根据__name__变量的结果来判断是直接执行的该模块代码,还是被其他模块引入执行的,从而能够有选择性的执行测试代码。
test.py
def add(a, b):
return a + b
name = 'abc'
# 用来进行测试,只有该模块,也就是改文件代码直接执行时,执行下面的代码
if __name__ == '__main__':
ret = add(12, 22)
print('int test.py file, 12+22=%d' % ret)
main.py
import test
result = test.add(11, 22)
print(result)
执行 main.py 文件,结果为:33,并没有执行 test.py 中的代码。
__all__变量
all 变量,可以在每个代码文件中(模块中)定义, 类型可以是元组或列表,起作用是: 影响 form 模块名 import * 导入行为,其他导入行为不受影响
- 如果没有定义
__all__变量, 模块中的所有功能,都可以被导入 - 如果定义了
__all__变量,则form 模块名 import *只能导入变量中定义的内容
python中的包
当多个模块的功能类似时,我们通常会将其放到同一个目录下,该目录就是python中的包。
包导入方式
import
导入格式:import 包名.模块名
使用格式:模块名.功能名
案例:
import my_package.my_module1
import my_package.my_module2 as mm2
my_package.my_module1.func()
mm2.func()
from … import …
导入格式:from 包名.模块名 import 功能名
使用格式:功能名
案例:
from my_package.my_module1 import func
func()
from ... import *
导入格式:from 包名.模块名 import *
使用格式:功能名
案例:
from my_package import *
func()
如果直接执行上述代码,可能会报错,具体细节查看下节。
__init__.py文件
如果模块目录下没有__init__.py文件,或者是该文件中没有任何内容,则通过from 包名.模块名 import *的方式导入时,其实并没有导入任何东西。
如果__init__.py文件中有内容,则通过from 包名.模块名 import *的方式导入时,导入的就是__init__.py文件中的内容,也就是说,该文件中有什么,导入的就是什么,不管是变量还是方法,都会被导入。
如果想要将包下的所有模块进行导入,则需要在__init__.py文件中添加__all__变量,并且将你想要导入的模块名赋给__all__变量,不过要注意,如果添加了__all__变量,则该文件中的其他内容在导入时就会被忽略。
比如现在有目录my_package,并且有两个模块,文件名分别为:my_module1.py、my_module2.py,同时包含__init__.py文件。
my_module1.py
num = 10
def func():
print('my_package my_module1 func .... 111111')
my_module2.py
num = 20
def func():
print('my_package my_module2 func .... 222222')
__init__.py
__all__ = ['my_module1', 'my_module2']
包导入测试:
from my_package import *
my_module1.func()
my_module2.func()
执行上面代码结果:
my_package my_module1 func .... 111111
my_package my_module2 func .... 222222
编程规范
PEP8: Python代码风格指南
PEP8 提供了 Python 代码的编写约定. 本节知识点旨在提高代码的可读性, 并使其在各种 Python 代码中编写风格保持一致.
-
缩进使用4个空格, 空格是首选的缩进方式. Python3 不允许混合使用制表符和空格来缩进.
-
每一行最大长度限制在79个字符以内.
-
顶层函数、类的定义, 前后使用两个空行隔开.
-
import 导入
-
多个导入建议在不同的行, 例如:
import os import sys # 不建议如下导包 import os, sys # 但是可以如下: from subprocess import Popen, PIPE -
导包位于文件顶部, 在模块注释、文档字符串之后, 全局变量、常量之前. 导入按照以下顺序分组:
- 标准库导入
- 相关第三方导入
- 本地应用/库导入
- 在每一组导入之间加入空行
-
-
Python 中定义字符串使用双引号、单引号是相同的, 尽量保持使用同一方式定义字符串. 当一个字符串包含单引号或者双引号时, 在最外层使用不同的符号来避免使用反斜杠转义, 从而提高可读性.
-
表达式和语句中的空格:
- 避免在小括号、方括号、花括号前跟空格.
- 避免在逗号、分好、冒号之前添加空格.
- 冒号在切片中就像二元运算符, 两边要有相同数量的空格. 如果某个切片参数省略, 空格也省略.
- 避免为了和另外一个赋值语句对齐, 在赋值运算符附加多个空格.
- 避免在表达式尾部添加空格, 因为尾部空格通常看不见, 会产生混乱.
- 总是在二元运算符两边加一个空格, 赋值(=),增量赋值(+=,-=),比较(==,<,>,!=,<>,<=,>=,in,not,in,is,is not),布尔(and, or, not)。
-
避免将小的代码块和 if/for/while 放在同一行, 要避免代码行太长,以下是错误示范:
if foo == 'blah': do_blah_thing() for x in lst: total += x while t < 10: t = delay() -
永远不要使用字母 ‘l’(小写的L), ‘O’(大写的O), 或者 ‘I’(大写的I) 作为单字符变量名. 在有些字体里, 这些字符无法和数字0和1区分, 如果想用 ‘l’, 用 ‘L’ 代替.
-
类名一般使用首字母大写的约定.
-
函数名应该小写, 如果想提高可读性可以用下划线分隔.
-
如果函数的参数名和已有的关键词冲突, 在最后加单一个下划线比缩写或随意拼写更好. 因此 class_ 比 clss 更好.(最好用同义词来避免这种冲突).
-
方法名和实例变量使用下划线分割的小写单词, 以提高可读性.


















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











