







我们可以在IDEA中直接运行spark程序,来连接服务器上的HDFS或者是spark集群来跑spark任务。
- 提前工作
我们需要先解决idea直接运行程序远程访问HDFS的问题。- 首先下载 hadoop-common-2.6.0-bin-master.rar 压缩包(需要和服务器上的Hadoop版本对应),解压到任意目录,然后在环境变量中添加 HADOOP_HOME ,变量值为解压的位置。
- 在 PATH 变量中添加以下值:%HADOOP_HOME%\bin ,之后确认即可,如果后面在idea中运行程序报错:
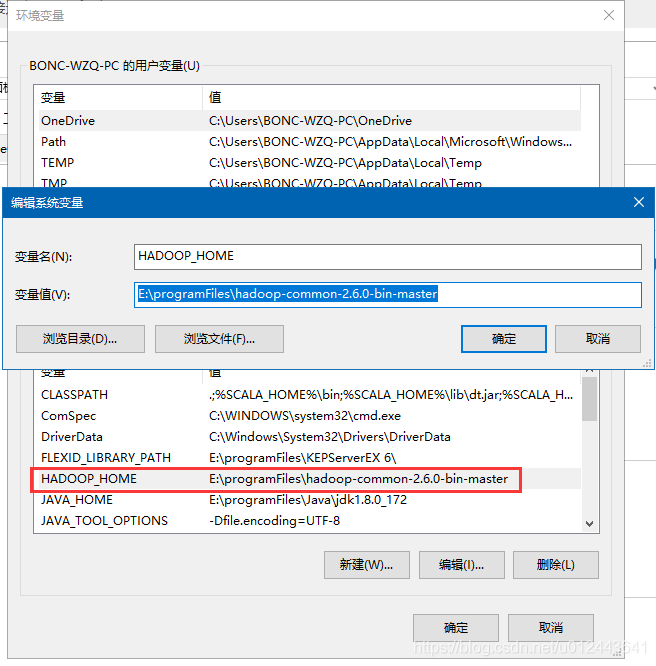
则重启一下电脑,使上面的配置生效。
- 本地运行
本地调试是使用本地idea中编写的代码引入的spark的相关jar包来运行spark程序,将spark程序提交到本地spark(本地并不需要安装Windows版本的spark)运行。下面是获取SparkContext的代码:val config = new SparkConf().setAppName("WordCount").setMaster("local") val sparkContext = new SparkContext(config)一定要调用setMaster()方法,方法参数设置为local。
之后直接运行主方法就可以运行该程序。
- 远程运行
远程运行是指经过代码设置,idea自动将代码打包并发布到指定的远程服务器上的spark上运行,远程服务器上的spark master接受jar包,并发布给worker运行,并可以在页面上看到master和worker中程序的执行情况。下面是获取SparkContext的代码:val config = new SparkConf().setAppName("WordCount").setMaster("spark://zb2:7077") .setJars(List("target/sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar")) .setIfMissing("spark.driver.host", "172.16.72.251") val sparkContext = new SparkContext(config)1. setMaster方法中设置远程spark服务的master地址;
2. setJars方法中传递一个Seq,里面写上jar包的位置(idea中打完jar包的位置);
3. setIfMissing方法中设置spark驱动的机器IP地址,也就是你Windows开发电脑的IP地址。
4. 之后直接运行主方法就可以运行该程序,idea自动打包并发布到远程spark服务器。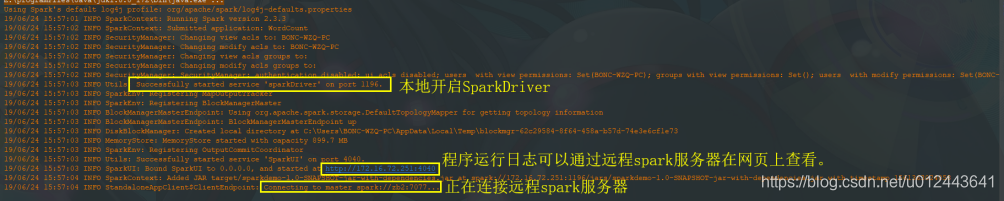
注意:你的Windows和虚拟机里面的spark所在的linux系统(或者是linux服务器)必须能够互相ping通才行,而且都得关闭防火墙,因为他们相互之间需要通信。
















 5373
5373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











