







1. 基本概念
1.1 Mali GPU家族
Mali GPU家族都包含以下通用的硬件:
• 基于分块的延迟渲染:
Mali GPU把framebuffer分成许多块(16 x 16像素),然后一块一块地进行渲染。基于分块的渲染是有效的,因为像素值使用片上内存进行计算。它需要更少的内存带宽和功耗。
• L2 Cache控制器:
一个Mali GPU有一个或多个L2 Cache控制器,它可减少内存带宽(可减少访问主内存)和功耗。Mail GPU使用L2 Cache代替本地内存(Local Memory)。
1.1.1 Utgard架构家族
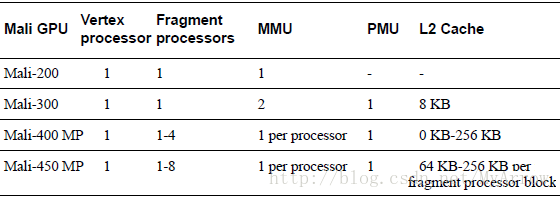
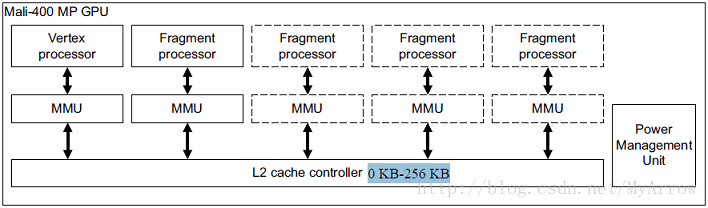
• 顶点处理器(Vertex Processor: VP)
VP处理图形管道的顶点处理(vertex processing)阶段的工作,它产生原语(点、线、三角形)列表,并加速创建供像素处理器(Fragment Processors: FP)使用的数据结构(如:多边形列表和打包的顶点数据)。
• 像素处理器(Fragment Processor:FP)
FP处理图形管道的光栅化和像素处理阶段的工作。它使用VP输出的数据结构和原语列表来产生framebuffer中的像素数据,以方便显示在屏幕上。
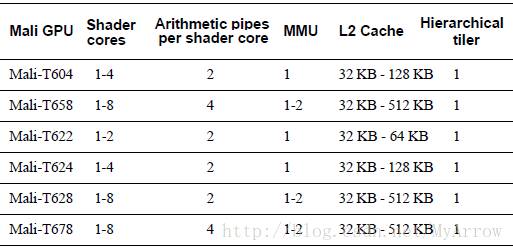
1.1.2 Midgard架构家族
Midgard架构的GPU拥有用于执行顶点、片断和计算处理的统一的Shader cores,它支持OpenGL ES 1.1、2.0、3.0,以及OpenCL 1.1。
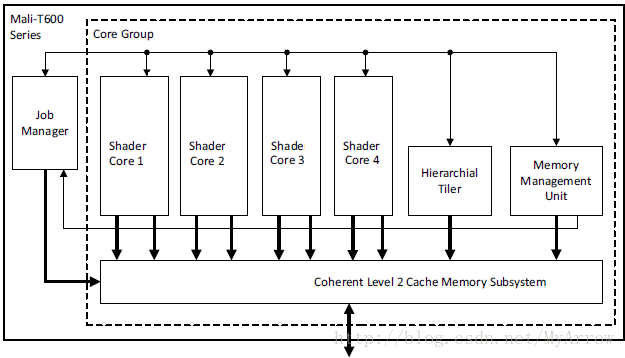
1) Mali-T600系列GPU组件
2) Mali-T600系列GPU架构
1.2 图形管道(OpenGL ES Graphics Pipeline)
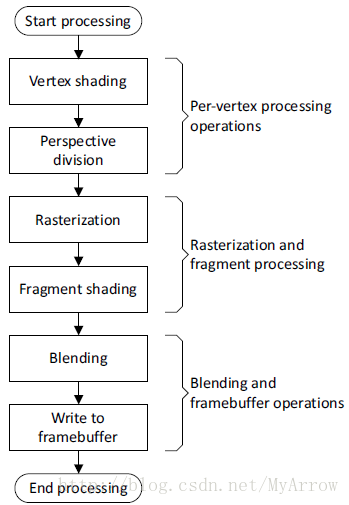
Mali GPU使用数据结构和硬件功能模块(VP、FP、MMU、PMU、L2 Cache控制器)来实现OpenGL ES图形管道。
1.2.1 初始化处理 (Start processing)
OpenGL ES API级的驱动在内存中为GPU创建数据结构、且为每个场景配置硬件。软件主要功能如下:
1) 为RSWs(Render State Words)和纹理描述产生数据结构
2) 为顶点处理创建命令列表
3) 在需要时编译Shaders
1.2.2 顶点处理操作(Per-vertex processing operations)
顶点处理器为每个顶点运行一次顶点着色器程序(Vertex Shader Program),顶点着色器程序执行如下操作:
1) 光照(Lighting)
2) 变换(Transforms:平移、旋转、拉伸)
3) 视口变换(Viewport transformation)
4) 透视变换(Perspective transformation)
5) 组装图形顶点原语(Assembles vertices of graphics primitives)
6) 创建多边形列表(Builds polygon lists)
1.2.3 光栅化和片断着色(Rasterization and fragment shading)
片断/像素处理器(FP)执行以下操作:
1) 读取数据(数据-->系数):
读取状态信息、多边形列表和变换之后的顶点数据。这些数据由【三角形设置单元】进行处理并生成系数。
2) 多边形光栅化(系数-->片断):
光栅器从【三角形设置单元】中获取系数,然后执行方程式以创建片断。
3) 执行片断着色器(片断-->颜色):
片断/像素处理器为每一个片断执行一次【片断着色器程序】以计算出每个片断的颜色。
1.2.4 混合和帧缓冲操作(Blending and framebuffer operations)
fragments--> tile buffers --> framebuffer
在处理完tile buffer之后,FP为framebuffer产生最后的显示数据。为了提高处理速度,每一个FP处理不同的tile。
混合单元把fragments与在对应位置的tile buffer中已经存在的颜色数据进行混合。
FP主要功能如下:
1) 测试fragments且更新tile buffer
2) 计算fragments是否可见,且把可见的fragments保存到tile buffers中
3) 在当前tile被完全渲染之后,把tile buffer中的内容写入framebuffer中
2. 优化清单
2.1 检查显示设置
1) 应用程序使用正确的drawing surface,使用支持的surface中的一个。2) Framebuffer分辨率和颜色格式与显示控制器兼容
3) Framebuffer不要超过屏幕的分辨率
4) Framebuffer不要超过屏幕的的颜色的深度
5) Framebuffer格式应当与drawing surface格式相同
2.2 使用正确的工具和工具设置
1) 使用工具的最新版本2) 当工具更新之后,重新编译所有代码
3) 创建与硬件结构相对应的版本
4) 充分使用硬件特性:如果硬件支持硬浮点(Vector Floating Point<VFP>)或NEON,使用此特性编译所有相关的代码
5) 最后以Release版本发布
2.3 删除调试信息
1) 尽量少使用printf,但logcat对性能影响不大2) 尽量不要调用glGetError(),如果需要,每帧不要超过一次,因为它需要占用较多的时间
2.4 避免无限命令列表
1) 如果帧间不清楚buffers,命令列表可能一直增长,它将导致GPU做无用功。2) 如果App渲染到surface(如:pixmapsurface、pbuffersurface),在一帧结束时不清除命令列表
3) 如果使用FBO(Framebuffer Objects),则不存在此问题
4) 如果渲染到eglWindowSurface,每当调用eglSwapBuffers()时,命令列表自动结束
5) 为了防止命令列表无限增长,必须同时清楚这些颜色、深度和模板buffer。调用函数:
glClear( GL_COLOR_BUFFER_BIT | GL_DEPTHBUFFER_BIT | GL_STENCILBUFFER_BIT );
2.5 避免调用阻塞图形管道的函数
1) glReadPixels()2) glCopyTexImage()
3) glTexSubImage()
2.6 不要每一帧都编译Shaders
尽量在应用程序启动时编译Shaders,或者使用预编译的shaders。预编译的Shaders只能在编译时指定的GPU上运行。2.7 使用VSYNC
VSYNC(Vertical Synchronization)可使应用的帧率与屏幕的显示速率同步,其功能如下:1) 它通过消除撕裂改善图像的质量
2) 防止应用产生的帧率大于屏幕可显示的帧率,以降低功耗
2.8 禁止使用24位纹理
可使用16位或32位纹理,而不要使用24位纹理。24位纹理不完全适合高速缓存。采用24位纹理可能会导致数据使用超过一个高速缓存行,这对性能和内存带宽将产生负面影响。2.9 使用纹理映射(mipmapping)--good
纹理映射:采取高分辨率纹理,并将其伸缩到多个较小的尺寸称为mipmap级别的纹理。这需要比非mipmapped纹理多约33%的内存。在执行时调用glGenerateMipmap()根据未压缩的纹理产生mipmaps,或使用《Mali GPU Texture Compression Tool》预产生mipmaps。
其好处如下:
1) 改善图像质量
2) 提高性能
3) 减少内存带宽
2.10 使用ETC压缩纹理
压缩纹理可减少纹理的大小,其好处如下:1) 提高性能
2) 提高纹理的可缓存性
3) 减少内存带宽
可用的ETC(Ericsson Texture Compression)压缩纹理类型如下:

可使用《Mali GPU Texture Compression Tool》创建ETC1、ETC2和ASTC压缩纹理。
2.11 减少内存带宽
内存带宽不仅是性能bottleneck,而且内存带宽越大,功耗越高。1) 内存带宽是共享资源,如过度使用将导致整个系统性能问题;如图像内存由APP共享,当GPU过度使用带宽时,CPU性能也将下降
2) 访问高速缓存中的将降低功能和提高性能;若APP必须从主内存中读取大量数据,可使用mipmapping或texture compression等技术以确保数据可被高速缓存所缓存
3) 可减少内存带宽的方法:
• Activate back face culling.
• Utilize view frustum culling.
• Ensure textures are not too large.
• Use a texture resolution that fits the object on screen.
• Use low bit depth textures where possible.
• Use lower resolution textures if the texture does not contain sharp detail.
• Only use trilinear filtering on specific objects.
• Utilize Level of Detail (LOD).
2.12 使用顶点Buffer对象(VBO)
VBO(Vertex Buffer Object)是让APP存储和操作GPU内存中数据的一种机制。当GPU处理数据时,不需要从CPU内存中读取,可以节约内存带宽。
2.13 发布时检查列表

3. 优化流程
一般优化流程如下图所示:
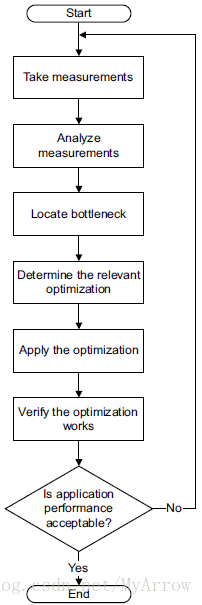
3.1 如何评估优化效果?
评估优化效果时使用Frame Time,而不是FPS。
FPS(Frames per Second) 一个基本的性能指标,而Frame Time是最好的性能优化效果指标。Frame Time是一个线性值,而FPS是一个非线性值,线性值计算更加容易。
FPS与Frame Time的差异如下图所示:

3.2 如何计算Fragment Shader的最大cycles?
A = GPU时钟速度 x FP个数 x 0.8; // 每秒可达到的最大cycles
B = FB_H x FB_W x 期望的FPS x 2.5; //每秒要求的fragments数
C = A/B; // Fragment Shader的平均cycles
通过shader compiler工具可以得知Shader需要的cycles.
注:不要误以为Fragment Processing 周期数(cycles)等于Fragment Processing指令数,Mali GPU中的处理器在每周期可执行许多指令。
3.3 Bottleneck在处理器间移动
• 在优化过程中,性能瓶颈可在图形管理的不同阶段(即不同的处理)间移动。在DS-5 Streamline中可从图形显示中读取瓶颈位置,瓶颈是其负荷最大的地方。
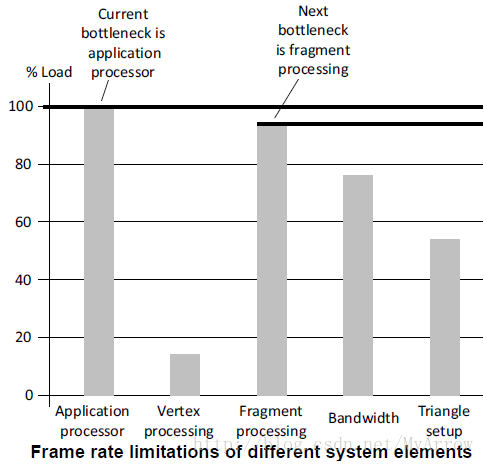
在上图中,为了改善性能,可把应用处理器和Fragment处理器上的部分工作移到Vertex处理器上来做。
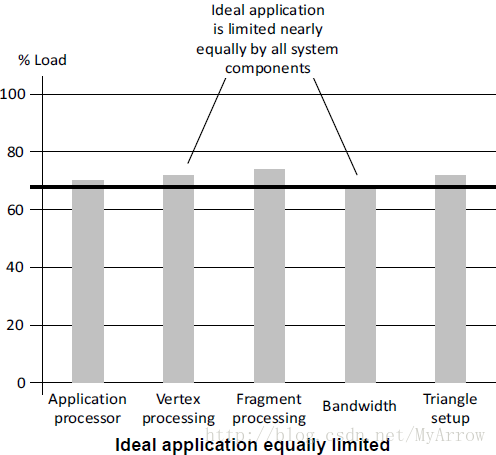
• 理想的负荷状态
理想的负荷状态是:图形管道各个阶段的负荷相当,如下图所示:

















 2148
2148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









