 Midgard GPU 驱动解析
Midgard GPU 驱动解析




midgard drvier代码比较多,它初始化成功后,会创建一个 /dev/mali0 的混杂设备,libOpenGLES_mali.so 里面应该会通过这个混杂设备的 ioctl() 操控drvier,driver里面的核心代码主要是帮忙管理GPU的VA/PA内存,管理GPU的Jobs, 处理GPU的3个中断。
ARM官网上不同版本的midgard driver版本(最新的版本是 2022年10月的版本):
https://developer.arm.com/downloads/-/mali-drivers/midgard-kernel
Midgard driver是由ARM公司开发的驱动,因为没遵守DRM框架,所以,一直没有能合入到linux mainline,
在下面ARM的官网上面,有midgard driver的不同的版本,用户可以直接下载,最新的版本是 2022年10月的版本
在Midgrad driver之上,是由ARM给手机厂商提供的闭源的LibOpenGLES_mali.so , 它负责从应用层调用midgrad driver创建的设备 /dev/mali0 来操作mali gpu设备。
Device tree信息
Mali GPU 相关的寄存器列表
GPU寄存器主要分为三类:
• 控制整体GPU的: 比如 GPU_ID, GPU_FEATURE, IRQ 等
• 控制JOB相关的: 比如 JOB COMMAND
• 控制MMU相关的:比如MMU配置2级页表

drivers/gpu/arm/midgard/mali_midg_regmap.h
#define GPU_ID 0x000 /* (RO) GPU and revision identifier /
#define L2_FEATURES 0x004 / (RO) Level 2 cache features /
#define SUSPEND_SIZE 0x008 / (RO) Fixed-function suspend buffer size /
#define TILER_FEATURES 0x00C / (RO) Tiler Features /
#define MEM_FEATURES 0x010 / (RO) Memory system features /
#define MMU_FEATURES 0x014 / (RO) MMU features /
#define AS_PRESENT 0x018 / (RO) Address space slots present /
#define JS_PRESENT 0x01C / (RO) Job slots present /
#define GPU_IRQ_RAWSTAT 0x020 / (RW) /
#define GPU_IRQ_CLEAR 0x024 / (WO) /
#define GPU_IRQ_MASK 0x028 / (RW) /
#define GPU_IRQ_STATUS 0x02C / (RO) */
kbase_platform_driver
midgard驱动如果加载OK,那么设备中会创建一个 /dev/mali0 的混杂设备
module_platform_driver(kbase_platform_driver);
static struct platform_driver kbase_platform_driver = {
.probe = kbase_platform_device_probe,
.remove = kbase_platform_device_remove,
.driver = {
.name = kbase_drv_name,
.owner = THIS_MODULE,
.pm = &kbase_pm_ops,
.of_match_table = of_match_ptr(kbase_dt_ids),
},
};
static const struct of_device_id kbase_dt_ids[] = {
{ .compatible = “arm,mali-t624” },
{ .compatible = “arm,malit6xx” },
{ .compatible = “arm,mali-midgard” },
{ /* sentinel */ }
};
kbase_platform_device_probe
kbase_platform_device_probe
-》kbdev = kbase_device_alloc()
-》assign_irqs(pdev) //从DTS中获取3个中断号信息
-》irq_job = platform_get_irq_byname(pdev, “JOB”);
-》irq_mmu = platform_get_irq_byname(pdev, “MMU”);
-》platform_get_irq_byname(pdev, “GPU”);
-》registers_map(kbdev)
-》reg_res = platform_get_resource(pdev, IORESOURCE_MEM, 0)
-》kbdev->reg_start = reg_res->start //获取mali gpu的寄存器基地址空间
-》power_control_init(pdev)
-》clk_get(kbdev->dev, “clk_mali”)
-》clk_prepare_enable(kbdev->clock) //打开GPU的CLK
-》kbase_backend_early_init(kbdev)
kbasep_platform_device_init(kbdev);
kbase_pm_runtime_init(kbdev);
kbase_pm_register_access_enable(kbdev);
kbase_gpuprops_set(kbdev);
kbase_pm_register_access_disable(kbdev);
kbase_install_interrupts(kbdev)
-》request_irq(kbdev->irqs[i].irq, kbase_handler_table[i], //注册3个中断:”job”, “mmu”, “gpu”
kbdev->irqs[i].flags | IRQF_SHARED,
dev_name(kbdev->dev),
kbase_tag(kbdev, i))
-》kbase_device_init(kbdev)
-》kbase_ctx_sched_init(kbdev)
-》kbase_mem_init(kbdev)
-》kbdev->mdev.minor = MISC_DYNAMIC_MINOR;
-》kbdev->mdev.name = kbdev->devname; //设备名:”mali0/1/2”
-》kbdev->mdev.fops = &kbase_fops; //字符设备文件的操作集合
-》kbdev->mdev.parent = get_device(kbdev->dev);
-》kbdev->mdev.mode = 0666;
-》kbdev->inited_subsys |= inited_get_device;
-》misc_register(&kbdev->mdev) //创建一个 /dev/mali0 设备
3个中断处理函数
static irq_handler_t kbase_handler_table[] = {
[JOB_IRQ_TAG] = kbase_job_irq_handler, //“job”中断处理函数,一个job处理完成后,gpu会产生此中断,然后在中断处理函数中,会从软件调度队列中,取出新的job加到硬件队列
[MMU_IRQ_TAG] = kbase_mmu_irq_handler, //“mmu”中断处理函数,当GPU访问了不存在的地址时,会产生此中断,在中断处理函数中,会为GPU分配新的物理内存,并建立MMU映射
[GPU_IRQ_TAG] = kbase_gpu_irq_handler, //“gpu” 中断处理函数,此中断处理比较简单,主要是一些通用的错误报告
};
mmu中断处理
主要处理GPU遇到page fault时,在mmu中断处理函数中,CPU会为GPU分配物理内存,并为GPU的MMU建立VA->PA的映射
kbase_mmu_irq_handler
-》val = kbase_reg_read(kbdev, MMU_REG(MMU_IRQ_STATUS), NULL)
-》kbase_mmu_interrupt(kbdev, val)
-》as->fault_addr = kbase_reg_read(kbdev, //读出发生page fault的地址
MMU_AS_REG(as_no,
AS_FAULTADDRESS_HI),
kctx);
-》as->fault_addr <<= 32;
-》as->fault_addr |= kbase_reg_read(kbdev,
MMU_AS_REG(as_no,
AS_FAULTADDRESS_LO),
kctx);
-》kbase_mmu_interrupt_process(kbdev, kctx, as)
-》queue_work(as->pf_wq, &as->work_pagefault)
-》page_fault_worker
-》kbase_region_tracker_find_region_enclosing_address(kctx, faulting_as->fault_addr) //从kctx维护的一个rb tree中,找到一片包含了fault address的地址
-》kbase_alloc_phy_pages_helper(region->gpu_alloc, new_pages) //分析物理页
-》kbase_mmu_insert_pages_no_flush(kctx, region->start_pfn + pfn_offset, //映射到GPU的MMU页表中PTE项
gpu中断处理
这个中断比较简单,主要是报告一些GPU总体的错误状态
kbase_gpu_irq_handler
-》kbase_reg_read(kbdev, GPU_CONTROL_REG(GPU_IRQ_STATUS), NULL)
-》kbase_gpu_interrupt(kbdev, val)
job中断处理
一个JOB被硬件处理完成后,会产生这个中断,这个中断处理比较复杂,此中断里面,会再次从软件队列中取一些JOB送到硬件队列中去
kbase_job_irq_handler
-》kbase_reg_read(kbdev, JOB_CONTROL_REG(JOB_IRQ_STATUS), NULL)
-》kbase_job_done(kbdev, val)
-》kbase_gpu_complete_hw
-》kbase_backend_slot_update
-》kbase_job_hw_submit //将job提交到硬件队列中去
-》kbase_reg_write(kbdev, JOB_SLOT_REG(js, JS_HEAD_NEXT_LO), //配置GPU硬件中与JOB相关的寄存器
jc_head & 0xFFFFFFFF, kctx);
-》kbase_reg_write(kbdev, JOB_SLOT_REG(js, JS_HEAD_NEXT_HI),
jc_head >> 32, kctx);
-》kbase_reg_write(kbdev, JOB_SLOT_REG(js, JS_AFFINITY_NEXT_LO),
katom->affinity & 0xFFFFFFFF, kctx);
-》kbase_reg_write(kbdev, JOB_SLOT_REG(js, JS_AFFINITY_NEXT_HI),
katom->affinity >> 32, kctx);
kbase_jm_kick
kbase_jm_next_job
kbase_backend_run_atom
kbase_gpu_enqueue_atom
kbase_fops
应用层对 /dev/mali0 这个字符设备进行打开,关闭,控制,映射等操作的集合
static const struct file_operations kbase_fops = {
.owner = THIS_MODULE,
.open = kbase_open,
.release = kbase_release,
.read = kbase_read,
.poll = kbase_poll,
.unlocked_ioctl = kbase_ioctl,
.compat_ioctl = kbase_ioctl,
.mmap = kbase_mmap,
.check_flags = kbase_check_flags,
.get_unmapped_area = kbase_get_unmapped_area,
};
kbase_get_unmapped_area
struct file_operations 中,如果定义了.get_unmapped_area 接口,会调用driver自己的 .get_unmapped_area 接口
如果没定义,会调用系统默认的arch_get_unmapped_area,该函数,主要是在寻找一片空闲的虚拟地址的区间,等后面申请到物理页后,会映射到这里找到的虚拟空间
kbase_get_unmapped_area
-》current->mm->get_unmapped_area(filp, addr, len, pgoff, flags)
-》arch_get_unmapped_area_topdown
-》unmapped_area_topdown
-》rb_entry(mm->mm_rb.rb_node, struct vm_area_struct, vm_rb) //从红黑树中找,(linux 5.10),到 linux6.1.80时,该红黑树已经不存在了,换成了枫叶树
1.3.9 kbase_mmap
kbase_mmap //映射一片地址
-》kbasep_reg_mmap
-》kbase_gpu_mmap(kctx, reg, vma->vm_start + *aligned_offset, reg->nr_pages, 1)
-》kbase_mmu_insert_pages
kbase_ioctl
kbase_ioctl //上层OpenELGS 主要是通过ioctl() 来调用如下这些CMD ,来操控GPU干活
switch (cmd) {
KBASE_HANDLE_IOCTL_IN(KBASE_IOCTL_JOB_SUBMIT,
kbase_api_job_submit, //提交一个Job给GPU
struct kbase_ioctl_job_submit);
KBASE_HANDLE_IOCTL_IN(KBASE_IOCTL_GET_GPUPROPS,
kbase_api_get_gpuprops,
struct kbase_ioctl_get_gpuprops);
KBASE_HANDLE_IOCTL(KBASE_IOCTL_POST_TERM,
kbase_api_post_term);
KBASE_HANDLE_IOCTL_INOUT(KBASE_IOCTL_MEM_ALLOC,
kbase_api_mem_alloc, union kbase_ioctl_mem_alloc); //申请一片内存
KBASE_HANDLE_IOCTL_INOUT(KBASE_IOCTL_MEM_QUERY,
kbase_api_mem_query, //查询一片内存
union kbase_ioctl_mem_query);
KBASE_HANDLE_IOCTL_IN(KBASE_IOCTL_MEM_FREE, //释放一片内存
kbase_api_mem_free,
struct kbase_ioctl_mem_free);
KBASE_HANDLE_IOCTL_IN(KBASE_IOCTL_HWCNT_READER_SETUP,
kbase_api_hwcnt_reader_setup,
struct kbase_ioctl_hwcnt_reader_setup);
为GPU分配内存: kbase_api_mem_alloc
kbase_api_mem_alloc //为GPU申请内存
-》kbase_mem_alloc(kctx, alloc->in.va_pages, alloc->in.commit_pages, alloc->in.extent, &flags, &gpu_va)
-》kbase_alloc_free_region(kctx, 0, va_pages, zone)
-》kbase_update_region_flags(kctx, reg, *flags)
-》kbase_alloc_phy_pages(reg, va_pages, commit_pages)
-》kbase_alloc_phy_pages_helper(reg->cpu_alloc, size)
-》kbase_mem_pool_alloc_pages(&kctx->mem_pool,
nr_left,
tp,
false)
-》kbase_mem_pool_remove_locked(pool)
-》list_first_entry(&pool->page_list, struct page, lru)
-》kbase_mem_alloc_page(pool)
-》alloc_pages(gfp, pool->order) //调用内核函数,分配若干物理page
-》kbase_gpu_mmap(kctx, reg, 0, va_pages, 1)
-》kbase_mmu_insert_pages(kctx,
reg->start_pfn + (i * stride),
alloc->imported.alias.aliased[i].alloc->pages + alloc->imported.alias.aliased[i].offset,
alloc->imported.alias.aliased[i].length,
reg->flags)
-》kbase_mmu_insert_pages_no_flush(kctx, vpfn, phys, nr, flags)
-》kbase_mem_phy_alloc_gpu_mapped(alloc->imported.alias.aliased[i].alloc) //为GPU的MMU映射地址
-》alloc->out.flags = flags;
-》alloc->out.gpu_va = gpu_va; //返回gpu看到的VA
GPU 有3 个 MEM ZONE:
#define KBASE_REG_ZONE_SAME_VA KBASE_REG_ZONE(0)
#define KBASE_REG_ZONE_CUSTOM_VA KBASE_REG_ZONE(1)
#define KBASE_REG_ZONE_EXEC_VA KBASE_REG_ZONE(2)
GPU 的所有VA空间,由CPU来管理,CPU是用一个 struct kbase_va_region 结构体来表示,这点有类似于linux的 VMA结构体:
struct kbase_va_region {
struct rb_node rblink;
struct list_head link;
struct rb_root rbtree; / Backlink to rb tree /
u64 start_pfn; / The PFN in GPU space /
size_t nr_pages;
size_t initial_commit;
unsigned long flags;
size_t extent; / nr of pages alloc’d on PF */
struct kbase_mem_phy_alloc cpu_alloc; / the one alloc object we mmap to the CPU when mapping this region */
struct kbase_mem_phy_alloc gpu_alloc; / the one alloc object we mmap to the GPU when mapping this region /
struct list_head jit_node; / List head used to store the region in the JIT allocation pool /
u16 jit_usage_id; / The last JIT usage ID for this region /
u8 jit_bin_id; / The JIT bin this allocation came from /
int va_refcnt; / number of users of this va */
};
所有GPU VA区域,会在下面的流程中,加入到 rb tree中:
kbase_gpu_mmap
-》kbase_add_va_region
-》kbase_add_va_region_rbtree
-》kbase_insert_va_region_nolock
-》kbase_region_tracker_insert(new_reg) //将一个struct kbase_va_region,加入到 红黑树中去
因为GPU有3个不同的ZONE,所以每个ZONE对应一个rb_root,一共有如下3个rb_root,每个rb_root负责管理属于每个zone的GPU虚拟地址区间:
struct kbase_context {
。。。
struct rb_root reg_rbtree_same;
struct rb_root reg_rbtree_custom;
struct rb_root reg_rbtree_exec;
。。。
}
提交任务到GPU: kbase_api_job_submit
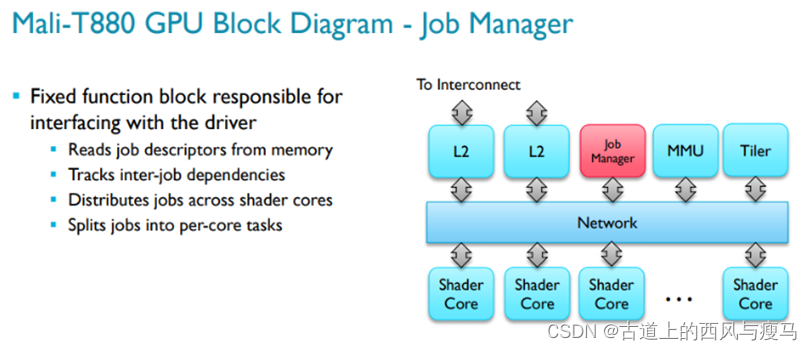
当应用层需要GPU执行任务的时候,用户通常会从gpu driver申请一片地址,在这个地址中,会放一段GPU认识的机器码。然后gpu driver会把这个地址写到GPU的寄存器上,然后gpu driver会告诉GPU,来job了,GPU 就会通过内部的DMA把这段代码读到GPU硬件中的Job Manager模块,Job Manager模块内部应该有一片instruction memory。
GPU硬件只认识三种jobs,分别是 Vertex Job(V), Tiler Job(T) 和 Fragment Job(F)。
应用层是如何提交任务给GPU呢?实质上,就是通过kbase_api_job_submit() 这个接口,在gpu driver向GPU提交任务的时候,可以指定一个Job Slots,可能的值是0,1,2,这三种任务都有自己的priority,当然任务与任务之间有依赖关系,所以,还需要处理好任务的依赖。
注意这几个关键的宏:
#define BASE_JM_MAX_NR_SLOTS 3 //硬件最多有3个 JOB SLOT
#define BASE_MAX_NR_AS 16 //GPU硬件支持的最大address space的个数
#define MIDGARD_MMU_BOTTOMLEVEL MIDGARD_MMU_LEVEL(3) //表明midgard GPU的MMU页表是3级页表
用户态看到的job是这个结构体来描述的:
typedef struct base_jd_atom_v2 {
u64 jc; /< job-chain GPU address */
struct base_jd_udata udata; /< user data */
u64 extres_list; /< list of external resources */
u16 nr_extres; /< nr of external resources or JIT allocations */
u16 compat_core_req; /< core requirements which correspond to the legacy support for UK 10.2 */
struct base_dependency pre_dep[2]; /< pre-dependencies, one need to use SETTER function to assign this field, this is done in order to reduce possibility of improper assigment of a dependency field */
base_atom_id atom_number; /< unique number to identify the atom */
base_jd_prio prio; /< Atom priority. Refer to @ref base_jd_prio for more details */
u8 device_nr; /< coregroup when BASE_JD_REQ_SPECIFIC_COHERENT_GROUP specified */
u8 padding[1];
base_jd_core_req core_req; /< core requirements */
} base_jd_atom_v2;
下面这个atom结构体是driver里面用来描述一个job的,它里面的很多成员来自于用户层的struct base_jd_atom_v2 结构体
struct kbase_jd_atom {
struct work_struct work;
ktime_t start_timestamp;
struct base_jd_udata udata;
struct kbase_context *kctx;
struct list_head dep_head[2];
struct list_head dep_item[2];
const struct kbase_jd_atom_dependency dep[2];
struct list_head jd_item;
bool in_jd_list;
}
kbase_api_job_submit //这个函数非常复杂,主要是用于上层的OpenELGS 库向底层的gpu驱动提交jobs
-》kbase_jd_submit(kctx, u64_to_user_ptr(submit->addr), submit->nr_atoms, submit->stride, false)
-》latest_flush = kbase_backend_get_current_flush_id(kbdev) //从硬件中获取一个flush id
-》copy_from_user(&user_atom, user_addr, sizeof(user_atom))
-》katom = &jctx->atoms[user_atom.atom_number]
-》kbase_js_sched_all(kbdev)
-》 kbase_js_use_ctx(kbdev, kctx, js)
-》kbasep_js_schedule_ctx(kbdev, kctx, js)
-》kbase_ctx_sched_retain_ctx(kctx)
-》kbasep_ctx_sched_find_as_for_ctx(kctx) //寻找一片free address space,为GPU硬件寻找一片它使用的虚拟地址空间,注意不是CPU的VA空间
-》kbase_mmu_update(kbdev, &kctx->mmu,
kctx->as_nr)
-》kbase_backend_use_ctx(kbdev, kctx, as_nr)
-》kbasep_js_add_job(kctx, katom)
-》kbase_js_dep_resolved_submit(kctx, atom)
-》struct jsctx_queue *queue = &kctx->jsctx_queue[prio][js];
-》list_add_tail(&katom->queue, &queue->x_dep_head); //将任务加到链表中, job中断完成后,会从链表中取新的JOBS,加到硬件队列中去
-》kbase_js_ctx_list_add_pullable_nolock(kbdev, kctx, atom->slot_nr)
-》list_add_tail(&kctx->jctx.sched_info.ctx.ctx_list_entry[js], &kbdev->js_data.ctx_list_pullable[js]) //将任务加到链表中
-》jd_submit_atom(kctx, &user_atom, katom)
-》kbase_jd_pre_external_resources(katom, user_atom)
-》kbase_region_tracker_find_region_enclosing_address(katom->kctx, user_res->ext_resource & ~BASE_EXT_RES_ACCESS_EXCLUSIVE)
-》kbase_map_external_resource(katom->kctx, reg, current->mm) //为依赖的外部资源映射空间
-》kbase_jd_user_buf_map(kctx, reg)
-》kbase_mmu_insert_pages(kctx->kbdev, &kctx->mmu, reg->start_pfn, //在GPU的MMU页表中,插入新增的项
pa, kbase_reg_current_backed_size(reg),
reg->flags & gwt_mask, kctx->as_nr)
-》kbasep_js_add_job(kctx, katom)
-》kbase_js_update_ctx_priority(kctx) //更新优先级
-》enqueue_required = kbase_js_dep_resolved_submit(kctx, atom)
-》list_add_tail(&katom->queue, &queue->x_dep_head)
-》jsctx_tree_add(kctx, katom)
// 将此任务写到ring buffer中去,struct kbase_context有队列数组: struct jsctx_queue jsctx_queue
[KBASE_JS_ATOM_SCHED_PRIO_COUNT][BASE_JM_MAX_NR_SLOTS]; 每个优先级一个队列
-》struct jsctx_queue *queue = &kctx->jsctx_queue[prio][js];
-》rb_insert_color(&katom->runnable_tree_node, &queue->runnable_tree) //把任务加到runnable_tree 这棵红黑树中去
-》kbase_jm_try_kick(kbdev, 1 << atom->slot_nr) //如果当前的atom 是该slot上的第一个任务,则直接把任务交到硬件中去
-》kbase_jm_kick(kbdev, js_mask)
-》kbase_backend_slot_free(kbdev, js)
-》kbase_jm_next_job(kbdev, js, nr_jobs_to_submit)
-》kbase_backend_run_atom(kbdev, katom) //准备运行atom这个任务
-》kbase_gpu_enqueue_atom(kbdev, katom); //入软件队列
-》kbase_backend_slot_update(kbdev);
-》kbase_job_hw_submit(kbdev, katom[idx], js) //从软件队列,提交到硬件队列
-》kbase_reg_write(kbdev, JOB_SLOT_REG(js, JS_HEAD_NEXT_LO), jc_head & 0xFFFFFFFF); //配置硬件的JOB寄存器
-》kbase_reg_write(kbdev, JOB_SLOT_REG(js, JS_HEAD_NEXT_HI), jc_head >> 32);
一共只有3个优先级:
enum {
KBASE_JS_ATOM_SCHED_PRIO_HIGH = 0,
KBASE_JS_ATOM_SCHED_PRIO_MED,
KBASE_JS_ATOM_SCHED_PRIO_LOW,
KBASE_JS_ATOM_SCHED_PRIO_COUNT,
};
如何 处理 一个JOB对其他JOB的依赖
jd_submit_atom
-》kbase_jd_pre_external_resources
有三种依赖的类型:
#define BASE_JD_DEP_TYPE_INVALID (0) /< Invalid dependency */
#define BASE_JD_DEP_TYPE_DATA (1U << 0) /< Data dependency */
#define BASE_JD_DEP_TYPE_ORDER (1U << 1) /**< Order dependency */
CPU如何为GPU配置MMU页表
每一个GPU 进程(也就是cpu address space)有一份GPU MMU 4级页表,一般最多16个,在代码中,用 AS 代表一个address space, 每一个address space都可以配置一个pgd一级页表的地址,
注意,这里的gpu address space 要跟cpu里面的address space区分开来,两者是不一样的概念。
如下所示,在提交Command的时候GPU驱动会把进程对应的GPU页表设置到硬件寄存器中:
#define MMU_AS0 0x400 /* Configuration registers for address space 0 /
#define MMU_AS1 0x440 / Configuration registers for address space 1 /
#define MMU_AS2 0x480 / Configuration registers for address space 2 /
#define MMU_AS3 0x4C0 / Configuration registers for address space 3 /
#define MMU_AS4 0x500 / Configuration registers for address space 4 /
#define MMU_AS5 0x540 / Configuration registers for address space 5 /
#define MMU_AS6 0x580 / Configuration registers for address space 6 /
#define MMU_AS7 0x5C0 / Configuration registers for address space 7 /
#define MMU_AS8 0x600 / Configuration registers for address space 8 /
#define MMU_AS9 0x640 / Configuration registers for address space 9 /
#define MMU_AS10 0x680 / Configuration registers for address space 10 /
#define MMU_AS11 0x6C0 / Configuration registers for address space 11 /
#define MMU_AS12 0x700 / Configuration registers for address space 12 /
#define MMU_AS13 0x740 / Configuration registers for address space 13 /
#define MMU_AS14 0x780 / Configuration registers for address space 14 /
#define MMU_AS15 0x7C0 / Configuration registers for address space 15 */
#define MMU_AS_REG(n, r) (MMU_REG(MMU_AS0 + ((n) << 6)) + ®)
#define AS_TRANSTAB_LO 0x00 /* 每一个 address space,都有一个 页表基地址寄存器,这是低32位*/
#define AS_TRANSTAB_HI 0x04 /* 每一个 address space,都有一个 页表基地址寄存器,这是高32位 */
建立一个MMU映射前,首先需要找到一个空闲的 GPU Address Space,找到后,这个as将会有自己的页表基地址寄存器,里面会存放一个一级页表的基地址
如下这个函数,就是用于从GPU硬件中,找到一个空闲的address space,找到后,才可使用这个address space的AS_TRANSTAB_HI 和 AS_TRANSTAB_LO 来配置MMU页表
kbase_ctx_sched_retain_ctx
-》kbasep_ctx_sched_find_as_for_ctx(kctx) // mali_kbase_ctx_sched.c
-》free_as = ffs(kbdev->as_free) – 1 //在kbdev->as_free 有一个bitmap,用来记录16个as的空闲状态
kbase_mmap //映射一片地址
-》kbasep_reg_mmap
-》kbase_gpu_mmap(kctx, reg, vma->vm_start + *aligned_offset, reg->nr_pages, 1)
-》kbase_mmu_insert_pages
-》kbase_mmu_insert_pages_no_flush //VPF是GPU看到的虚拟地址的PFN 号
-》mmu_get_pgd_at_level(kbdev, mmut, insert_vpfn, cur_level, &pgd) ////通过3次循环分配3级页表的物理内存
-》mmu_mode->entry_set_ate(&pgd_page[index + i], phys[i], flags, MIDGARD_MMU_BOTTOMLEVEL)
//将phys代表的多个物理页面,映射到最后一级页表的pte表项中
-》entry_set_ate() //在下面的aarch64_mode 中定义的 .entry_set_ate 接口
-》kbase_mmu_sync_pgd(kctx->kbdev, kbase_dma_addr§ + (index * sizeof(u64)), count * sizeof(u64)) //同步pgd页表到GPU设备端
-》dma_sync_single_for_device(kbdev->dev, handle, size, DMA_TO_DEVICE)
所有底层操作GPU MMU的函数,都是在这个操作集合中实现的:
static struct kbase_mmu_mode const aarch64_mode = {
.update = mmu_update, //更新MMU
.get_as_setup = mmu_get_as_setup, //设置GPU的一个address space,一共有16个address space
.disable_as = mmu_disable_as, //将GPU的一个address space禁止掉
.pte_to_phy_addr = pte_to_phy_addr, //将PTE表项转换物理地址
.ate_is_valid = ate_is_valid, //检查一条ATE是否有效的
.pte_is_valid = pte_is_valid, //检查一条PTE是否有效的
.entry_set_ate = entry_set_ate, //设置最后一级页表项,指向一个实际的物理页面
.entry_set_pte = entry_set_pte, //设置除了第后一级外的页表项,指向下一级页表其地址
.entries_invalidate = entries_invalidate, //将里面的表项无效掉
.flags = KBASE_MMU_MODE_HAS_NON_CACHEABLE
};

















 5695
5695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









