







1.安装onnxruntime-gpu
新版的onnxruntime-gpu 即支持gpu的推理,也支持cpu的推理。
卸载旧的1.7.1 cpu版本,安装新的gpu版本:
pip uninstall onnxruntime
pip install onnxruntime-gpu检查是否安装成功:
>>> import onnxruntime
>>> onnxruntime.__version__
'1.10.0'
>>> onnxruntime.get_device()
'GPU'
>>> onnxruntime.get_available_providers()
['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']
2.修改推理代码
在推理代码上增加 providers参数,选择推理的框架。看自己支持哪个就选择自己支持的就可以了。
session = onnxruntime.InferenceSession('yolov5s.onnx', None)
# 改为:
session = onnxruntime.InferenceSession('yolov5s.onnx',
providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])如果运行推理代码出现 Tensorrt, CUDA都无法推理,如下所示,则是自己的 ONNX Runtime, TensorRT, CUDA 版本没对应正确 。
2022-08-09 15:38:31.386436528 [W:onnxruntime:Default, onnxruntime_pybind_state.cc:509 CreateExecutionProviderInstance] Failed to create TensorrtExecutionProvider. Please reference https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html#requirements to ensure all dependencies are met.
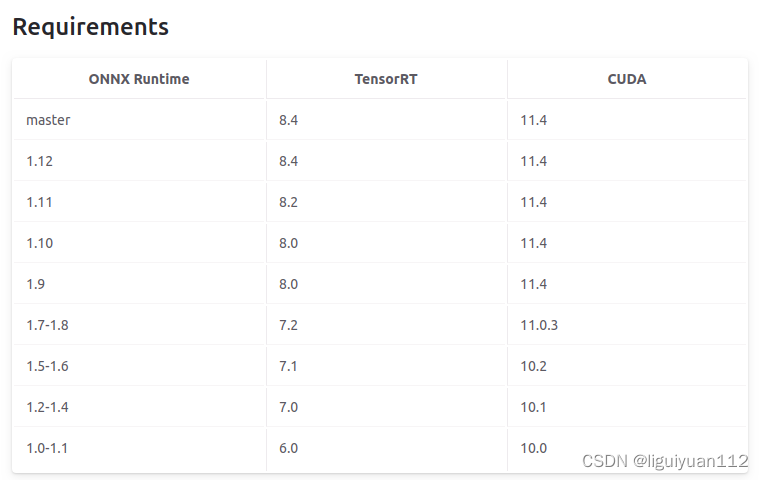
对应版本如下 :


















 7750
7750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











