







官网链接
http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html#about-this-document
要求
有NVDIA的显卡硬件(官网上有需要满足的条件)
下载
之前看网上的cuda安装好像都是需要安装驱动、SDK、Toolkit的,但是我自己安装cuda7.5的时候只需要下载以下2个东西
安装驱动
按照要求安装即可让
安装toolkit
双击exe,直接安装即可,我是全部按照默认设置进行安装的,怕之后cuda自动创建环境变量的时候会出现问题
之前看其他的安装教程上面都是创建了2个环境变量,这个的安装只是创建了一个CUDA_PATH:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5
还有一个CUDA_PATH_V7_5没有怎么用。。
安装完成后
可以打开文件夹C:\ProgramData\NVIDIA Corporation\CUDA Samples\v7.5,里面有安装自带的例程,可以作为参考
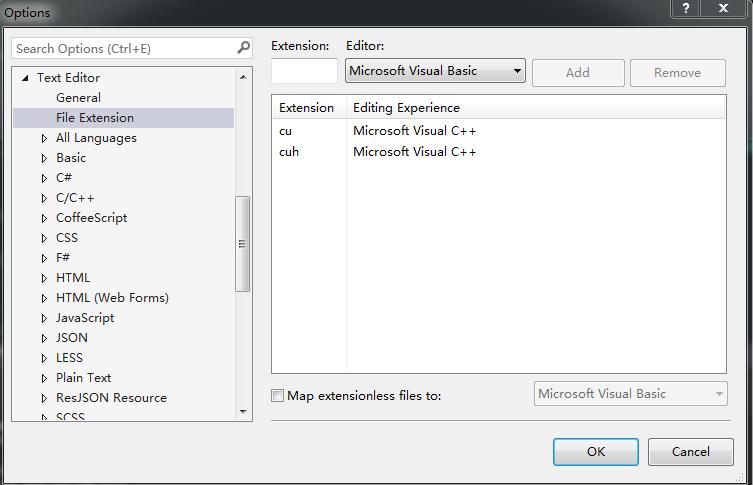
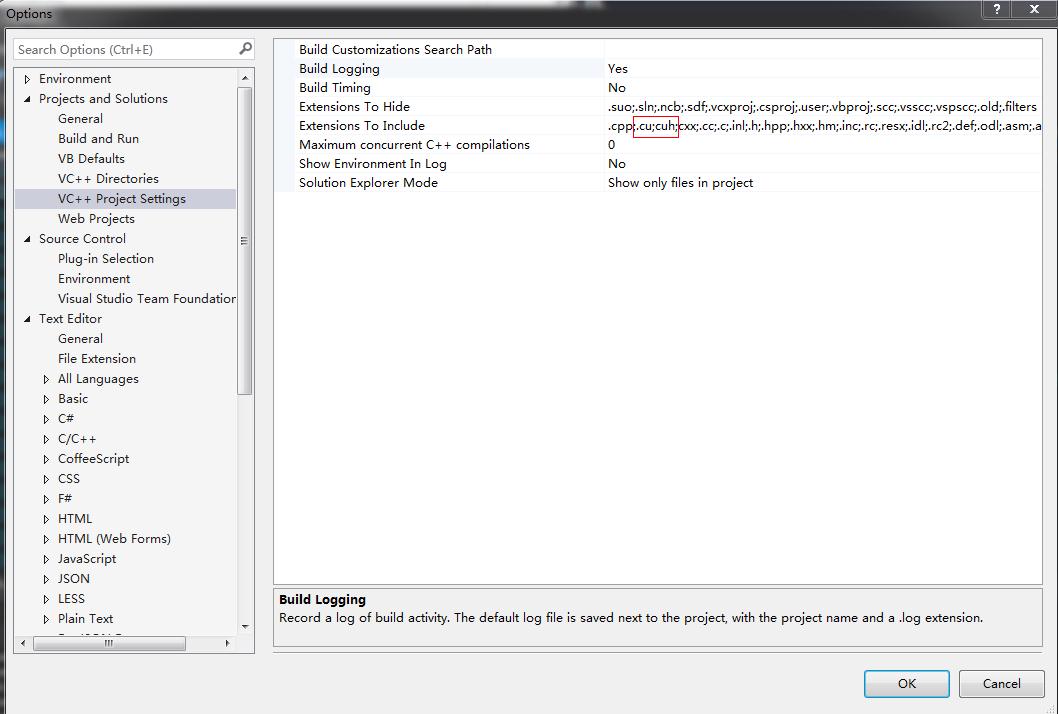
打开后,关于cuda的许多定义会有下划线,也不能转到定义,需要将VS进行如下设置
- 配置文件的扩展名等
在选项里配置
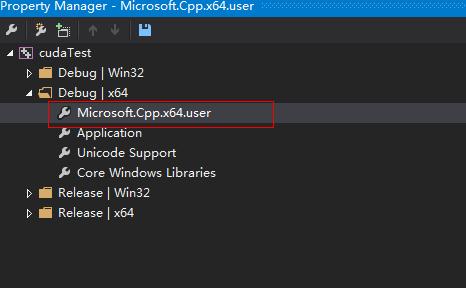
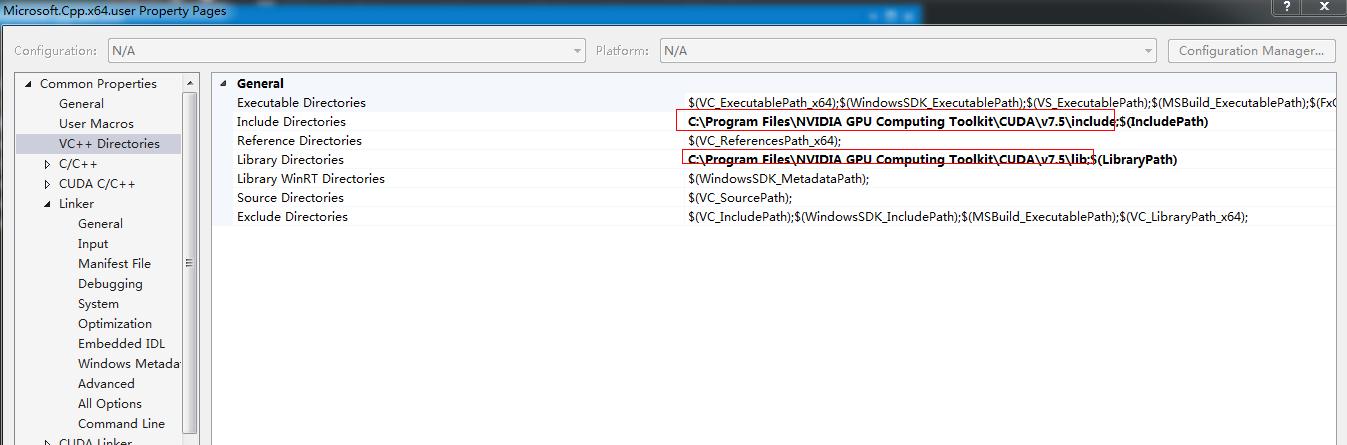
- 配置头文件目录和库目录
打开属性管理器,在VC++目录中添加如下
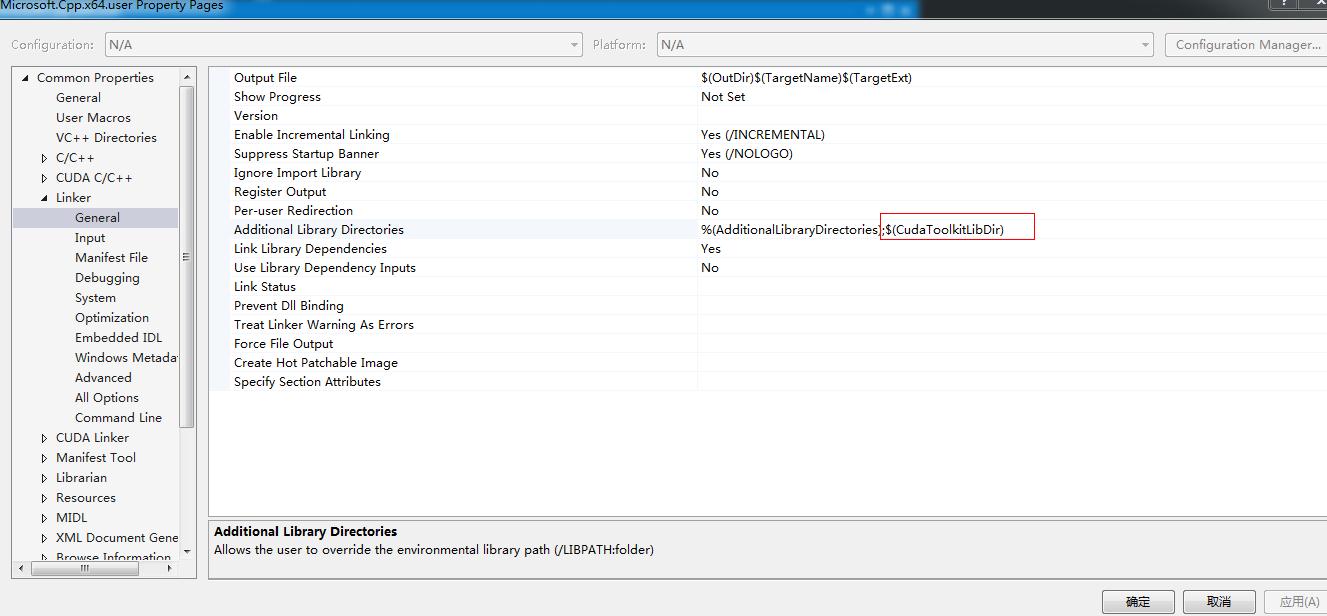
- 选择项目,右键选额
选择依赖项,设置如下
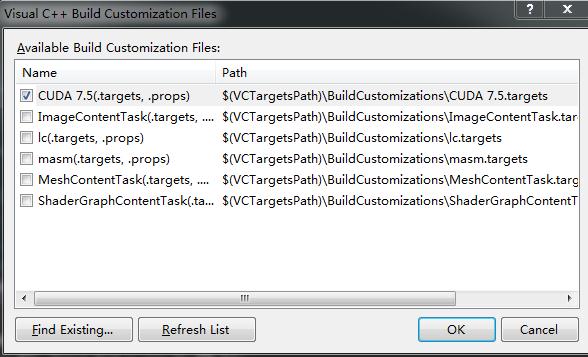
- 在链接器的输入中添加
cudaart.lib 输入如下,运行程序即可
#include"cuda.h" #include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> __global__ void SaxPY(float a, float* X_d, float* Y_d, int n) { if (threadIdx.x < n) { Y_d[threadIdx.x] = a*X_d[threadIdx.x] + Y_d[threadIdx.x]; } } int main() { int n = 64; float a = 2; float *X_h, *X_d, *Y_h, *Y_d; X_h = (float*)malloc( n * sizeof(float) ); Y_h = (float*)malloc(n * sizeof(float)); for (int i = 0; i < n; i++) { X_h[i] = (float)i; Y_h[i] = 1.0; } cudaMalloc( &X_d, n*sizeof(float) ); cudaMalloc(&Y_d, n*sizeof(float)); cudaMemcpy( X_d, X_h, n*sizeof(float), cudaMemcpyHostToDevice ); cudaMemcpy(Y_d, Y_h, n*sizeof(float), cudaMemcpyHostToDevice); SaxPY <<< 1, 64 >>>(a, X_d, Y_d, n); cudaMemcpy( Y_h, Y_d, n*sizeof(float), cudaMemcpyDeviceToHost ); for (int i = 0; i < n; i++) { printf("%2.1f X[%d] + Y[%d] = %f\n", a, i, i, Y_h[i]); } cudaFree( X_d ); cudaFree(Y_d); free(X_h); free(Y_h); system("Pause"); return 0; }
尖括号<<<>>>中第一个参数代表启动的线程块的数量,第二个参数代表每个线程块中线程的数量
参考链接
http://www.cnblogs.com/liangliangdetianxia/p/3978955.html
本次实验的代码网址
http://download.csdn.net/detail/u012526003/9504930
关于VS中配置的一些说明
- 属性管理器
在属性管理器中配置的时候,如果是项目的属性,则改变的是针对该项目的属性,包括头文件目录,附加库目录等,如下图

而如果是对debug模式弹出的属性设置,则是改变整个VS在此模式下的设置,如下图:
一般有debug win32、release win32、debug win64、release win64四种模式,对相同版本的debug和release模式,只需设置其中一种,另一中也自动设置,如设置了debug win32中的头文件后,则release win32中也会出现对应的设置。一般如果不想在每次新建工程时都需要重新设置,就可以直接修改整个VS的设置
cudad性能测试
- 基于上面的demo,在C++中写了2个数组相加的函数,并进行叠加,改变相加数组的大小,得到以下的运算结果
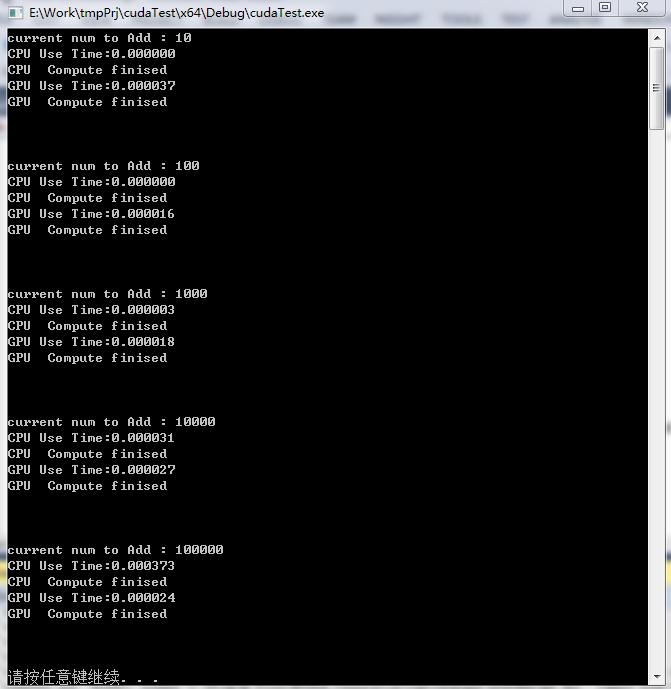
由图可知,当数组规模比较小的时候,运算时间方面,CPU相对占优势,但是当数组规模变大时,CPU时间上升的很快,而GPU时间几乎不变,在处理大规模数据运算的时候更具有优势
本次实验如下:
#include"cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include<Windows.h>
#include<time.h>
__global__ void SaxPY(float a, float* X_d, float* Y_d, int n)
{
if (threadIdx.x < n)
{
Y_d[threadIdx.x] = a*X_d[threadIdx.x] + Y_d[threadIdx.x];
}
}
void Add(float a, float *X_d, float *Y_d, int n)
{
for (int i = 0; i < n; i++)
{
Y_d[i] = a*X_d[i] + Y_d[i];
}
}
int main()
{
LARGE_INTEGER t1, t2, tc;
QueryPerformanceFrequency(&tc);
int n = 64000;
int nums[5] = { 10, 100, 1000, 10000, 100000 };
float a = 2;
float *X_h, *X_d, *Y_h, *Y_d;
for (int i = 0; i < 5; i++)
{
printf("current num to Add : %d\n", nums[i]);
X_h = (float*)malloc(nums[i] * sizeof(float));
Y_h = (float*)malloc(nums[i] * sizeof(float));
for (int i = 0; i < nums[i]; i++)
{
X_h[i] = (float)i;
Y_h[i] = 1.0;
}
QueryPerformanceCounter(&t1);
Add(a, X_h, Y_h, nums[i]);
QueryPerformanceCounter(&t2);
printf("CPU Use Time:%f\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart);
printf("CPU Compute finised\n");
free(X_h);
free(Y_h);
X_h = (float*)malloc(nums[i] * sizeof(float));
Y_h = (float*)malloc(nums[i] * sizeof(float));
for (int i = 0; i < nums[i]; i++)
{
X_h[i] = (float)i;
Y_h[i] = 1.0;
}
cudaMalloc(&X_d, nums[i] * sizeof(float));
cudaMalloc(&Y_d, nums[i] * sizeof(float));
cudaMemcpy(X_d, X_h, nums[i] * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(Y_d, Y_h, nums[i] * sizeof(float), cudaMemcpyHostToDevice);
QueryPerformanceCounter(&t1);
SaxPY << < 1, 64 >> >(a, X_d, Y_d, nums[i]);
QueryPerformanceCounter(&t2);
printf("GPU Use Time:%f\n", (t2.QuadPart - t1.QuadPart)*1.0 / tc.QuadPart);
cudaMemcpy(Y_h, Y_d, n*sizeof(float), cudaMemcpyDeviceToHost);
/*for (int i = 0; i < n; i++)
{
printf("%2.1f X[%d] + Y[%d] = %f\n", a, i, i, Y_h[i]);
}*/
printf("GPU Compute finised\n");
cudaFree(X_d);
cudaFree(Y_d);
free(X_h);
free(Y_h);
printf("\n\n\n");
}
system("Pause");
return 0;
}
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











