










前言
做为一个tensorflow的忠实用户,一直对keras有一种‘嫌弃’之情,网上大部分人对keras的评价也是low+灵活性差+慢,直到tf2.0决定添加keras的api后,我改变了自己的看法,keras简洁、结构清晰、代码易读,和sklearn保持一致的api,自定义层也能解决其灵活性的问题,keras一开始是基于theno开发的,tf的确慢一些,不过现在的版本已经改进了许多,速度方面也不用再担心。其次相比自己写的tf代码,keras的代码日志输出更加合理,总感觉自己对tf的封装还是做的不尽如人意,这也是我为什么打算出一个keras源码分析专题的原因。后续的文章,会对所有keras的代码进行分析讲解,并结合一些简单的demo。那么,废话不多说let’s go。
keras的总体结构
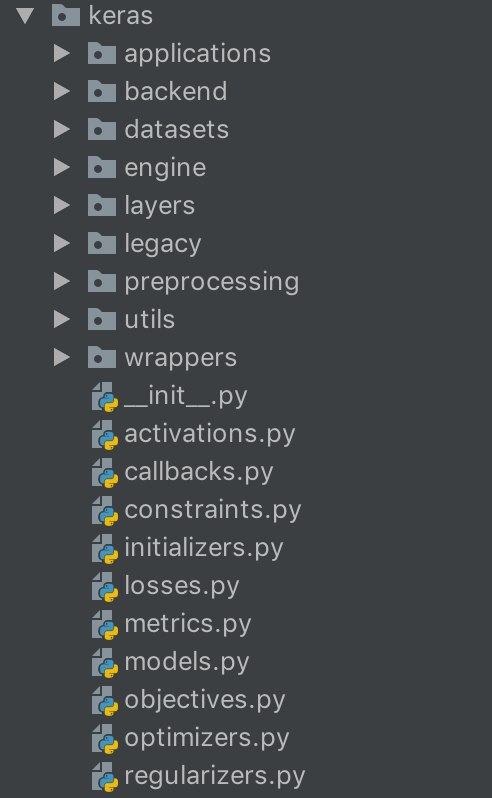
先看下keras源码的总体结构,其代码量并不多,毕竟只是其他底层库的封装,我们一个一个模块的来看。
-
applications,一些常用的预训练好的模型,可以直接拿过来做预测、特征提取、或者微调,模型包括了

可惜没有nlp方面的模型,不知道以后会不会把bert、xlnet这些模型添加进去。 -
backend,keras是一个对底层api进行了进一步封装的高级库,backend表示的即是keras调用的底层库,其目前包括了三个底层库,分别是
tensorflow,theano,CNTK,官方也表示未来还会添加更多。如果已经运行过keras,那么会在$HOME/.keras/keras.json找到一个配置文件,默认配置如下:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
其中backend就是在此处配置。
- datasets,keras自带的数据集,包括cifar10,imdb等等数据获取的脚本
- engine,Layer类的实现,也是keras最核心的内容
- layers,一些常用的layer,对engine的进一步封装
- legacy
- preprocessing,一些预处理代码
- utils,工具类
- wrappers,对fit、predict等函数的包装
以上模块我会选择比较重要的去进行详细的源码讲解,持续更新中。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









