







原始文章:
Vision Transformer 超详细解读 (原理分析+代码解读) (一)
1. 一切从Self-attention开始
解决问题: 如何处理序列化Sequence数据,并让网络有全局的视野,一般使用RNN处理,但是RNN不能并行运算,CNN视野又不够,因此self-attention由此诞生!
self-attention原理:
self-attention核心的三个参数q,k,v的含义:
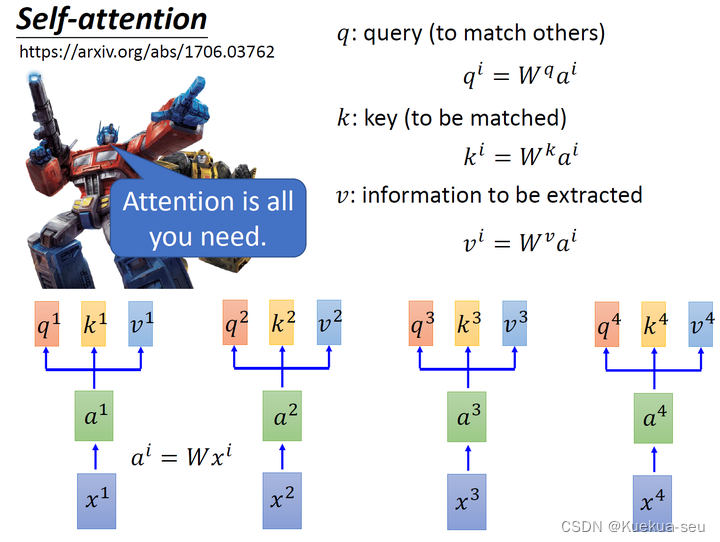
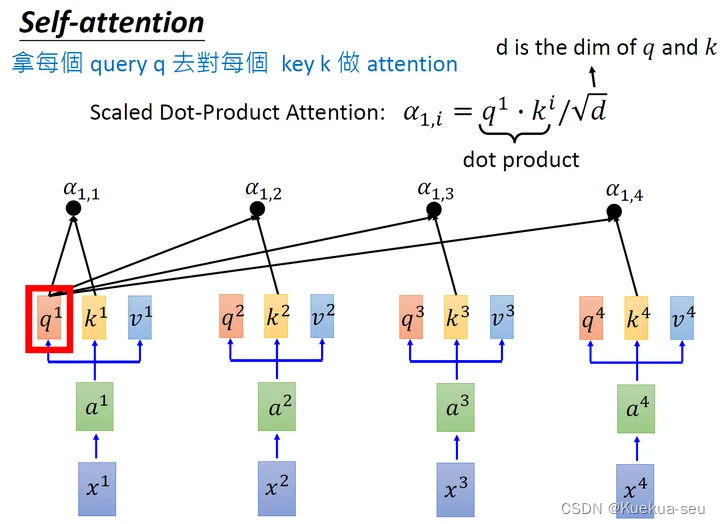
d是 q和k 的维度。因为 q·k的数值会随着dimension的增大而增大,所以要除以 根号d的值,相当于归一化的效果
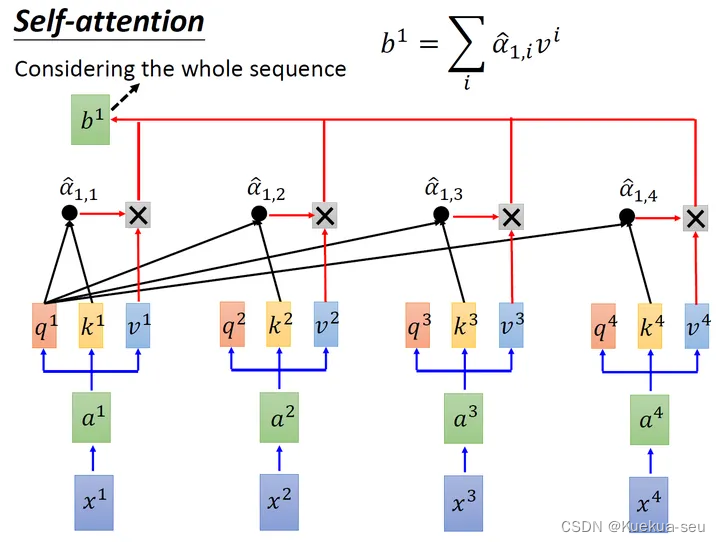
把计算得到的所有a的值取softmax操作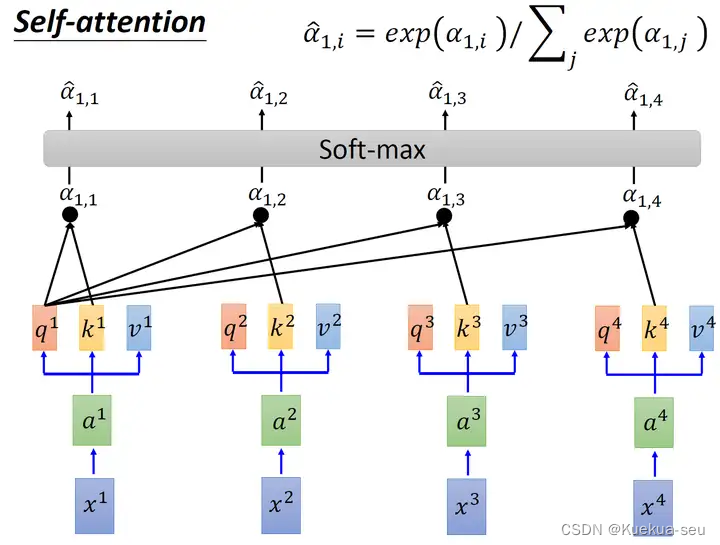
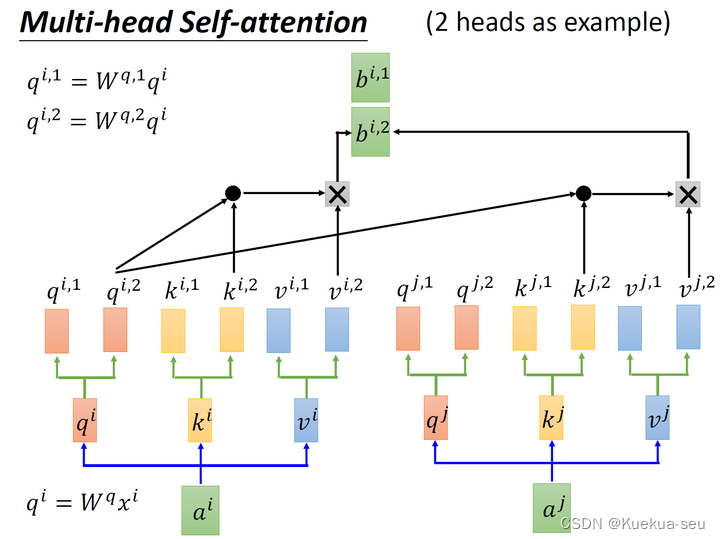
Multi-head Self-attention:
以两头self-attention为例,其实就是多计算一套qkv参数,然后对最终结果concat传入linear层:
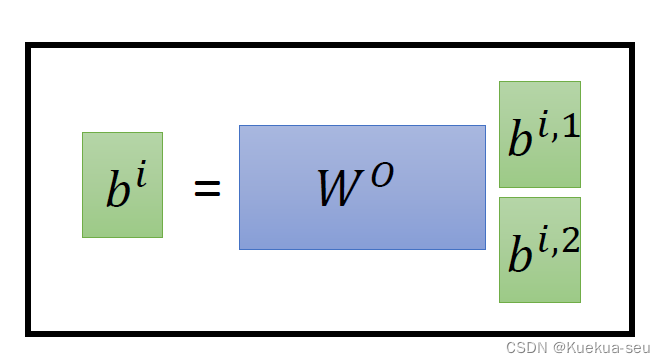
Positional Encoding
以上是self-attention的原理,但是还有一个问题是:现在的self-attention中没有位置的信息,一个单词向量的“近在咫尺”位置的单词向量和“远在天涯”位置的单词向量效果是一样的,没有表示位置的信息(No position information in self attention)。所以你输入"A打了B"或者"B打了A"的效果其实是一样的,因为并没有考虑位置的信息,为了解决这个问题,作者在网络中插入Positional Encoding信息:
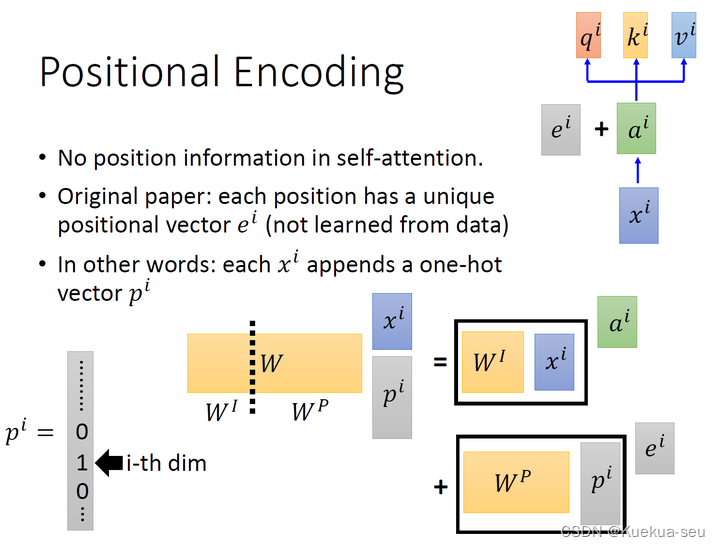
这里作者对位置信息才用add操作而不是concat操作,原因如下:

2 Transformer的实现和代码解读
Transformer原理分析
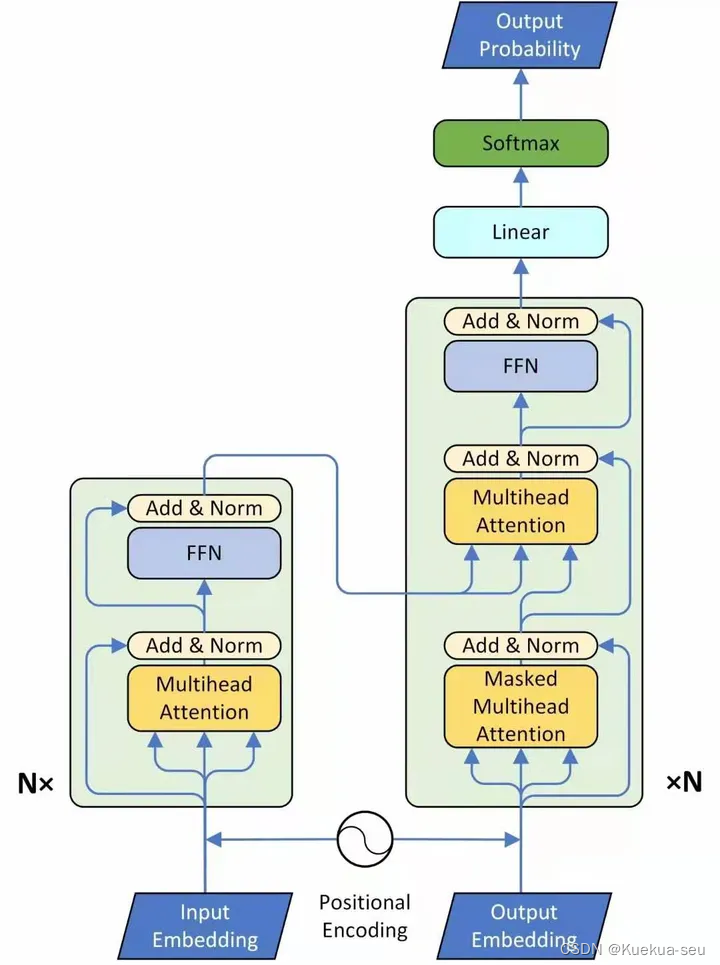
encode部分较简单,decode部分有关masked multihead attention,原因是训练时要把还没预测出的信息给mask掉:
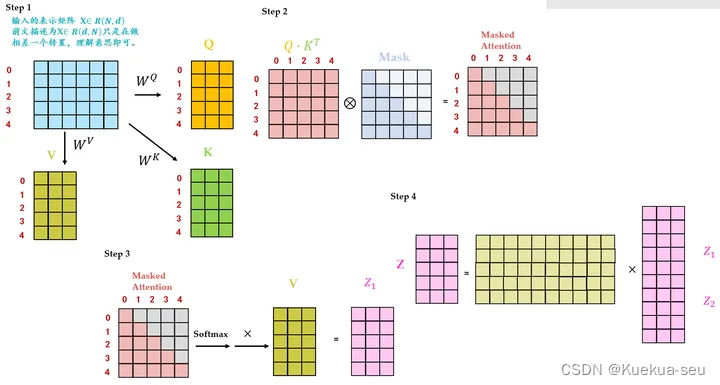
第1个Masked Multi-Head Self-attention的q,k,v均来自Output Embedding。
第2个Multi-Head Self-attention的q来自第1个Self-attention layer的输出, k,v来自Encoder的输出。
为什么这么设计?这里提供一种个人的理解:
k,v来自Transformer Encoder的输出,所以可以看做句子(Sequence)/图片(image)的内容信息(content,比如句意是:“我有一只猫”,图片内容是:“有几辆车,几个人等等”)。
q表达了一种诉求:希望得到什么,可以看做引导信息(guide)。
通过Multi-Head Self-attention结合在一起的过程就相当于是把我们需要的内容信息指导表达出来。
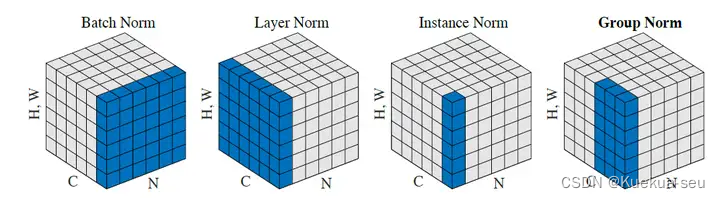
各种Normalization方法比较:
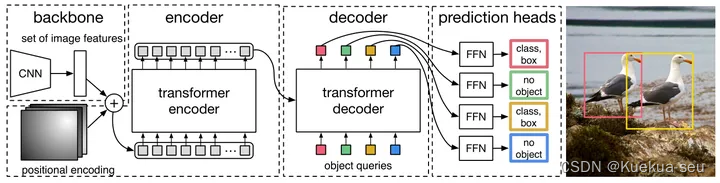
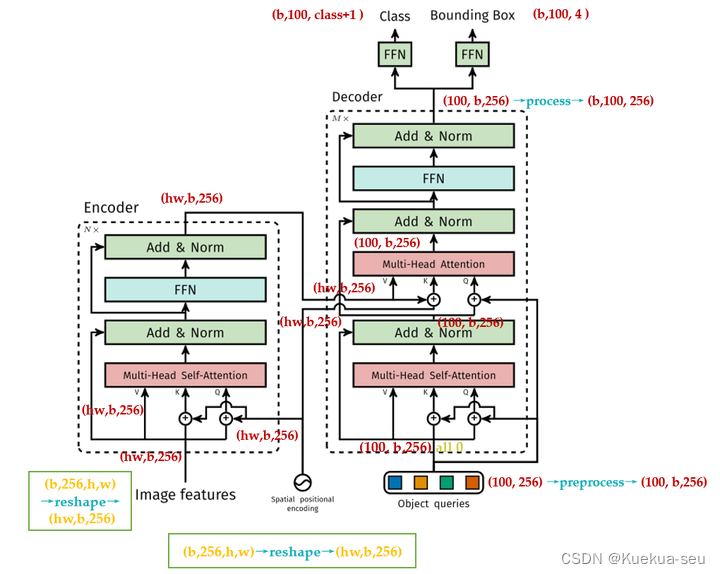
Transformer+Detection:引入视觉领域的首创DETR
文章的主要有两个关键的部分。
第一个是用transformer的encoder-decoder架构一次性生成N个box prediction。其中
N是一个事先设定的、比远远大于image中object个数的一个整数。
第二个是设计了bipartite matching loss,基于预测的boxex和ground truth boxes的二分图匹配计算loss的大小,从而使得预测的box的位置和类别更接近于ground truth。
原版Transformer只考虑 x方向的位置编码,但是DETR考虑了
x,y方向的位置编码,因为图像特征是2-D特征。采用的依然是 sin-cos模式,但是需要考虑 x,y两个方向。不是类似vision transoformer做法简单的将其拉伸为 d*HW ,然后从 [1,HW]进行长度为256的位置编码,而是考虑了 x,y方向同时编码,每个方向各编码128维向量,这种编码方式更符合图像特点。
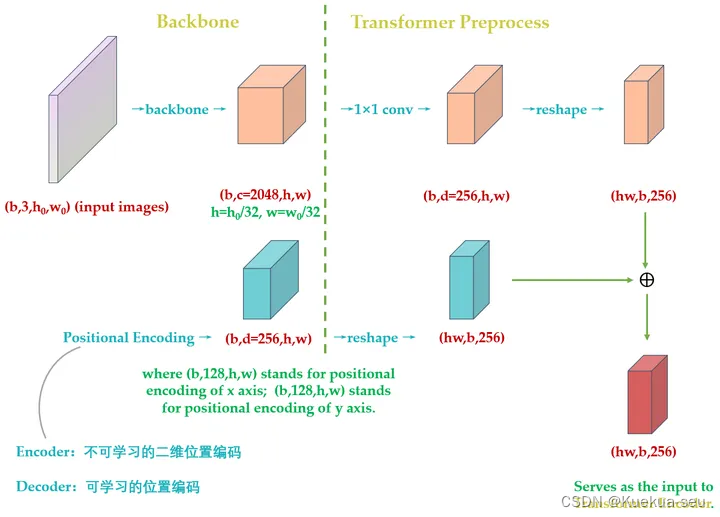
总结下和原始transformer编码器不同的地方:
- 输入编码器的位置编码需要考虑2-D空间位置。
- 位置编码向量需要加入到每个Encoder Layer中。
- 在编码器内部位置编码Positional Encoding仅仅作用于Query和Key,即只与Query和Key相加,Value不做任何处理。















 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









