







虚拟试衣
| 论文 | 来源 | 亮点 |
|---|---|---|
| IDM-VTON: Improving Diffusion Models for Authentic Virtual Try-on in the Wild | ECCV2024 | 利用sdxl unet encode和IP-adapter分别提取服饰的低层和高层特征注入网络,并使用详细的服饰描述词 |
| V-VTON: Multi-View Virtual Try-On with Diffusion Models | AAAI 2025 | 支持多角度试衣,通过同时输入正面和背面服饰,并设计正背面特征选择模块实现 |
| IMAGDressing: Interactive Modular Apparel Generation for Virtual Dressing | AAAI 2025 | 基于sd1.5,开源30w图像对数据 |
| CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models | 中山大学 | 基于Flux效果尚可,以较小的训练代价实现试衣 |
| MMTryon: Multi-Modal Multi-Reference Control for High-Quality Fashion Generation | 中山大学 | parser-free方案,不依赖分割,并可实现套装试衣,控制服饰开合及叠穿顺序等 |
| FitDiT: Advancing the Authentic Garment Details for High-fidelity Virtual Try-on | 腾讯 | 效果测试最好,专门设计服饰特征提取网络保持服饰细节,并通过随机扩大服饰mask区域增强模型对服饰长短的适配能力 |
| Learning Flow Fields in Attention for Controllable Person Image Generation | meta | 提出leffa loss,不增加模型参数,可大幅提升细节保持能力,同时支持姿势迁移 |
| StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On | CVPR2024 | 试衣 |
| CAT-DM: Controllable Accelerated Virtual Try-on with Diffusion Model | CVPR2024 | 试衣 |
| Texture-Preserving Diffusion Models for High-Fidelity Virtual Try-On | CVPR2024 | 试衣 |
| PICTURE: PhotorealistIC virtual Try-on from UnconstRained dEsigns | CVPR2024 | 试衣 |
| M&M VTO: Multi-Garment Virtual Try-On and Editing | CVPR2024 | 试衣 |
| SD-VITON-Virtual-Try-On | AAAI2024 | 试衣 |
| Magic Clothing: Controllable Garment-Driven Image Synthesis | ACM Multimedia 2024 | 试衣 |
| Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on | xiao-i | 高赞,应用classifer-free策略,较好保持服饰细节特征 |
| Magic Clothing: Controllable Garment-Driven Image Synthesis | ACM Multimedia 2024 | 试衣 |
| Controllable Human Image Generation with Personalized Multi-Garments | KAIST | 套装试衣,模特随机生成 |
| PromptDresser: Improving the Quality and Controllability of Virtual Try-On via Generative Textual Prompt and Prompt-aware Mask | KAIST | 使用详细的prompt提升效果,并提出服饰mask调整策略,实现coarse-fine二阶段生成 |
| AnyDressing : Customizable Multi-Garment Virtual Dressing via Latent Diffusion Models | ByteDance | mask free实现试衣 |
| BooW-VTON: Boosting In-the-Wild Virtual Try-On via Mask-Free Pseudo Data Training | 阿里 | mask free实现试衣 |
其他参考论文:
In-Context LoRA for Diffusion Transformers
Group Diffusion Transformers are Unsupervised Multitask Learners
PromptDresser
解决问题:
如何更好的利用text信息,提升试衣效果
解决思路:
-
利用GPT4o对模特/服饰的特定类别进行标注,采用few-shot模式,然后将结果组合成详细prompt输入网络,具体的类别选择:

-
提出服饰mask区域生成策略,解决服饰松紧长短等试衣形态,在尽可能保留模特/背景等与服饰无关的区域同时,避免受原服饰形态影响
整体结构:
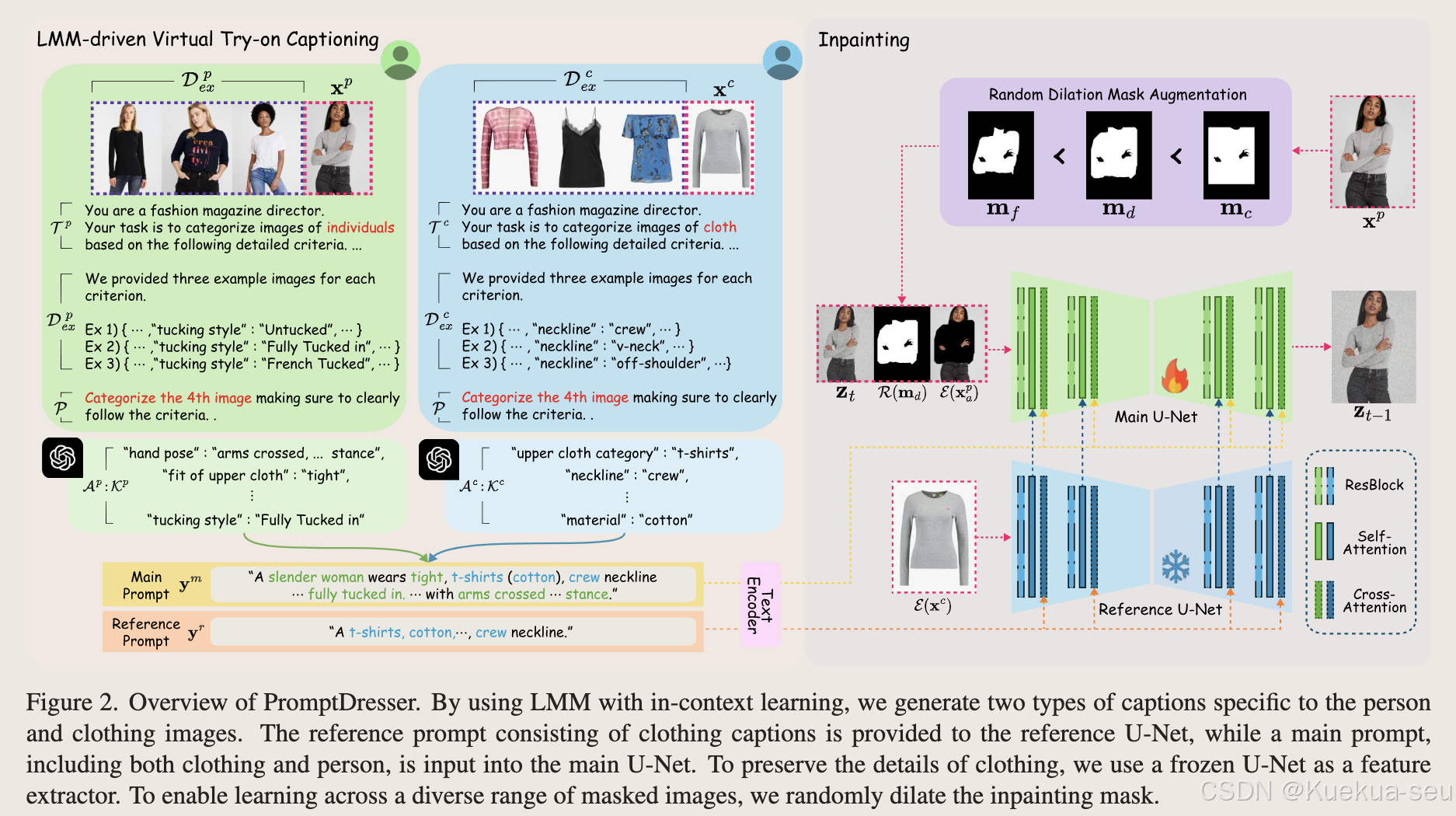
Tips
1.整体结构采用sd xl inpainting模型,reference U-Net提取的服饰feature与对应的生成unet的k,v进行concat,然后再做self-attention -
训练时的mask是用服饰区域mask做膨胀后与coarse mask做交集得到:

-
测试时,先用coarse mask输入生成网络推理a次,得到初步试衣结果后提取服饰区域,然后和原图的服饰mask区域做并集,最后将结果输入网络进行30-a次的生成,假设30是总生成次数:
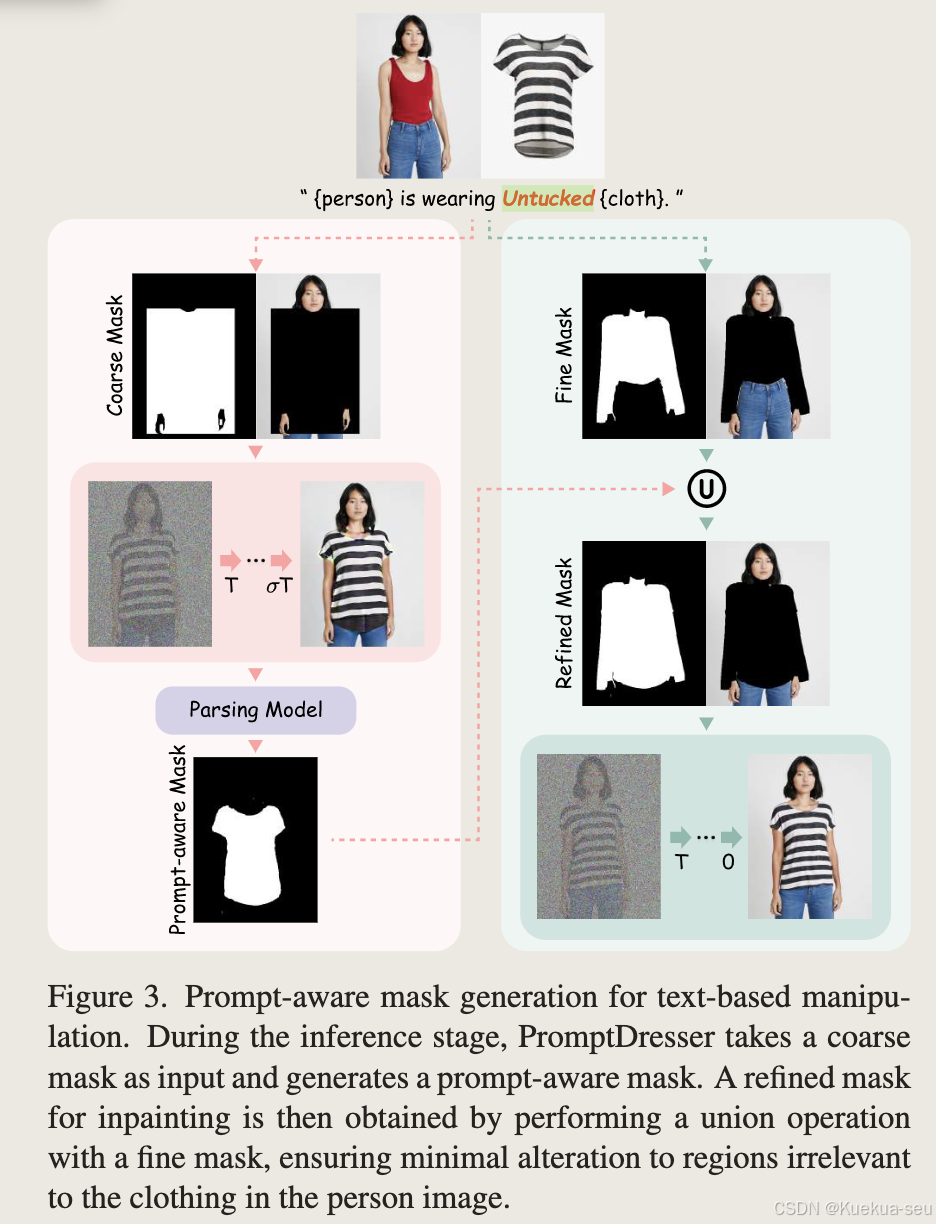
-
加入densepose信息会导致原服饰形状泄漏,效果变差
OOTDiffusion
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on
解决问题:
如何提升虚拟试衣效果
解决思路:
- 使用reference结构,并采用outfitting fusion将服饰信息注入生成unet
- 训练是使用outfitting dropout策略,即以10%的概率不注入服饰信息,即应用classifer-free策略,消融实验证明,选取合适的cfg值能较好提升模型服饰细节保持能力
整体结构:
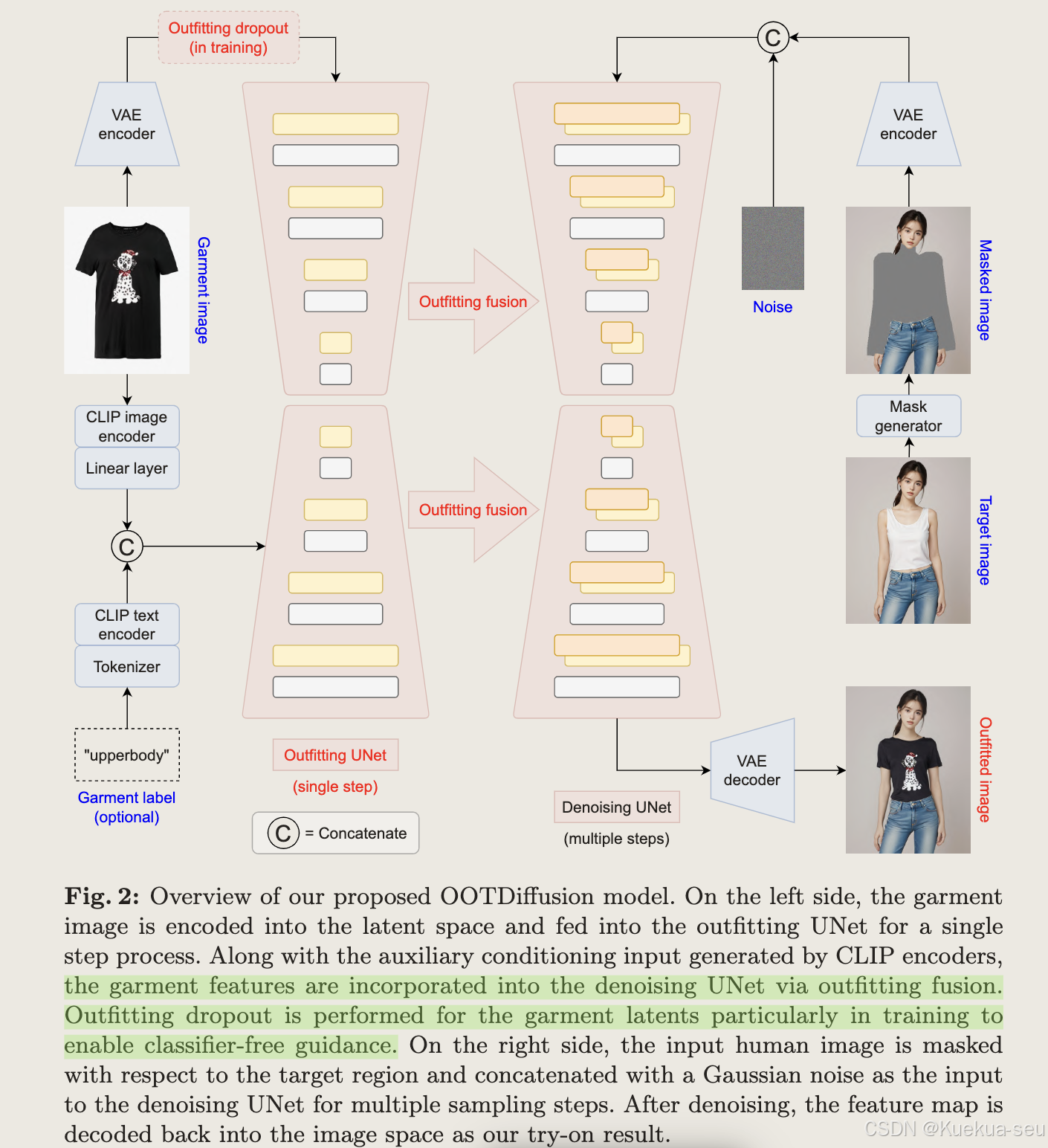
Tips
- 整体结构采用sd 1.5,unet输入channel为8,nosie+masked image,Outfitting UNet和Denoising UNet同时进行训练
- 将服饰图像信息和文本信息用clip进行编码并concat一起通过cross attention注入Outfitting UNet和Denoising UNet
- 服饰特征是通过outfitting fusion注入Denoising UNet,将Outfitting UNet的feature map和Denoising UNet的feature map在width维度concat一起,然后进行self-attention,并取Denoising UNet的那一半作为结果:

- 训练时采用classifer-free策略,以10%的概率随机取消Outfitting UNet的服饰特征
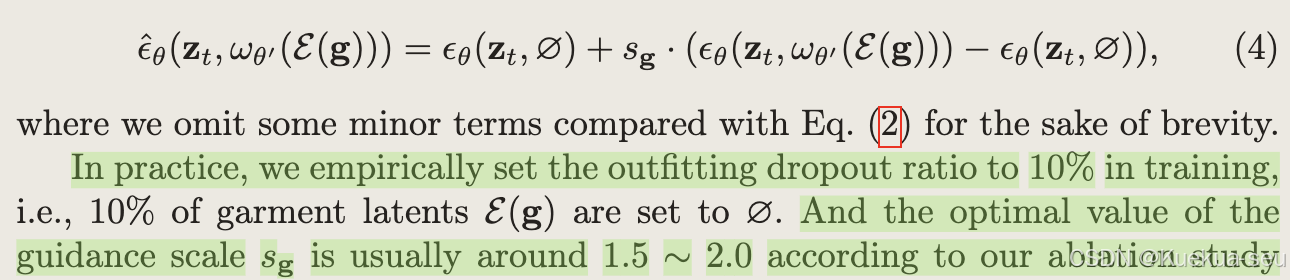
Leffa
Learning Flow Fields in Attention for Controllable Person Image Generation
解决问题:
如何以最小代价增强模型细节保持能力
解决思路:
提出Leffa loss:通过融合reference unet和主unet的特征参数,计算得到flow field,显式的实现warp,得到服饰的warp图,并与真实结果计算l2 loss:


整体结构:
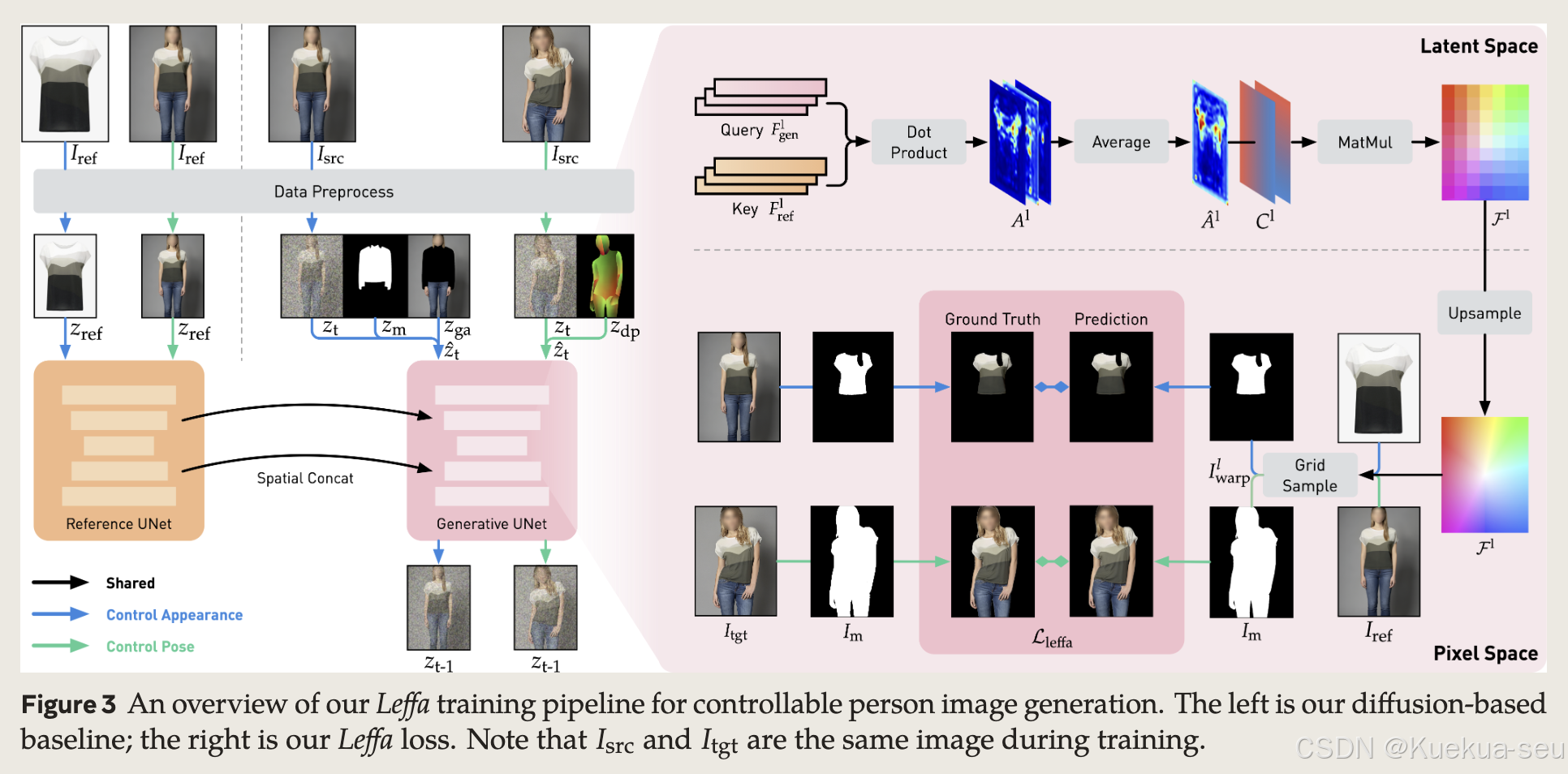
Tips
- 采用reference unet结构,reference unet的输出是通过空间concat注入到主unet,即在宽(高)维度concat,然后进行self-attention
- 去除text encoder模块及text注入的cross attention模块
- Leffa loss仅用在finetune阶段,一开始就用会影响正常的生成效果,并且仅在较高分辨率的attention map上计算,低分辨率warp效果不理想;同时也仅在较低的timesteps使用,较高的timesteps噪声过多
MMTryon
MMTryon: Multi-Modal Multi-Reference Control for High-Quality Fashion Generation
解决问题:
如何减小推理代价,避免因分割导致试衣badcase;如何进行person to person并实现套装试衣;如何控制试衣效果,比如拉拉链/不拉拉链,上下装叠穿顺序
解决思路:
优化思路:
- 引入多模态和多参考图注意力机制,将参考图片和服饰描述融合在一起,实现控制试衣效果和套装试衣,控制试衣效果主要依赖prompt以及试衣模块的生成能力
- 引入parse-free的garment encoder,利用文本引导在模特身上提取相应的服饰特征,实现推理时无需分割
整体结构:
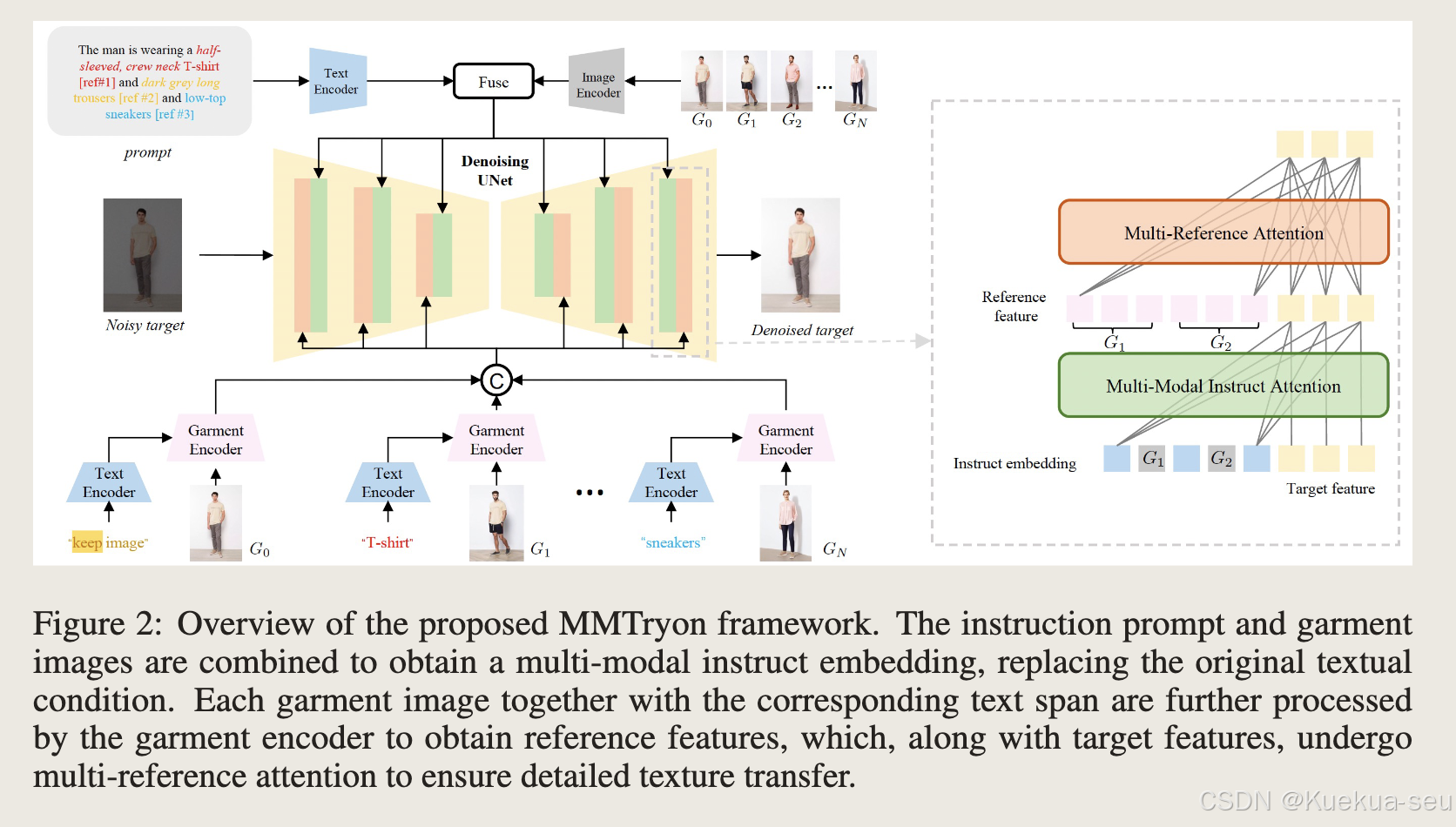
Tips:
作者认为文本和图片特征进行cross-attention,结果更偏向于文本图片对齐,结果更偏向于全局的语义特征;文本和图片特征进行self-attention,结果更偏向于细节特征。因此,在Multi-reference attention使用self-attention,multi-model instruct attention使用cross-attention
训练Garment encoder
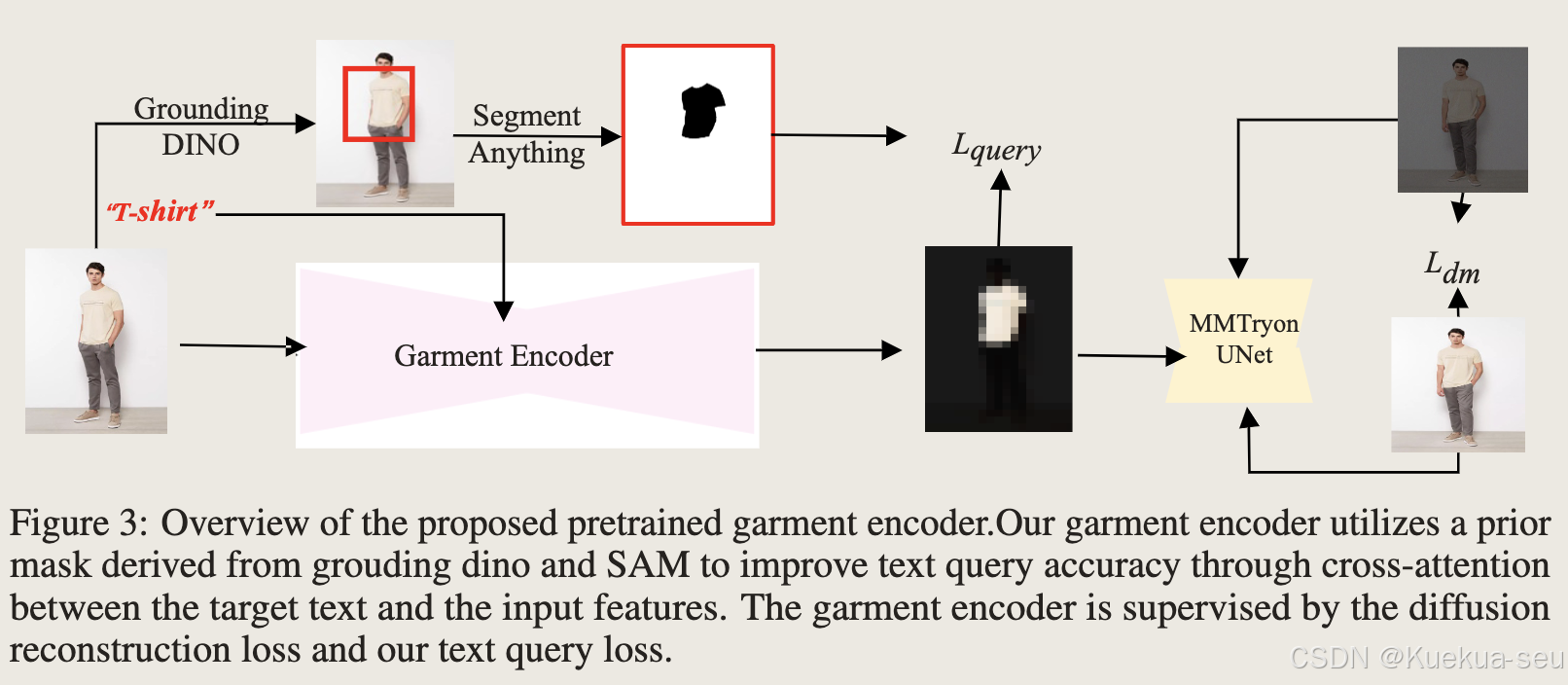
- Garment encoder使用diffusion model中unet的encoder部分,训练时冻结试衣模块MMTryon UNet参数
- 训练时基于DINO+SAM提取服饰mask,然后对encoder提取的特征区域进行监督,及服饰区域外的区域特征参数尽可能为0:

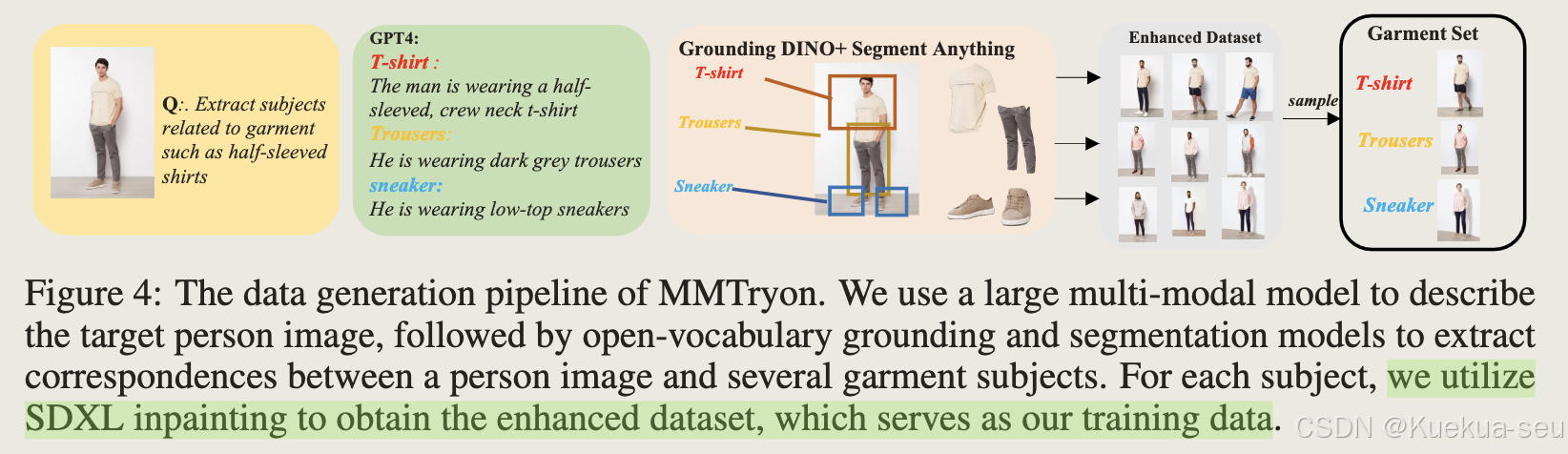
训练数据生成
使用开源的sdxl inpainting模型实现目标服饰不变,生成更多样性的数据,prompt来自原图,是利用GPT4V和CogVLM进行标注的
Multi-Modal Instruction Attention
作者设计了如下的prompt模版,图片间设置了占位符,确保图片特征和文本特征能对应上,最后将text特征和referece image特征融合在一起(如何融合在一起这一细节待确认),取代单一的text特征输入unet网络:
Multi-Reference Texture Attention
作者认为仅使用Multi-Modal Instruction Attention的CLIP ViT image encoder提取服饰特征不够,服饰细节损失严重,因此额外训练Garment encoder,并设计服饰特征注入机制:
CatVTON
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
解决问题:
如何在以最小训练/推理代价,实现试衣
解决思路:
减小训练/推理代价:
- 保持UNet主体不变,只训练self-attention模块
- 去除text encoder及相应的cross attention模块
- 不使用额外的image encoder,仅使用原有的vae encoder提取garment/human图像特征
- 不使用诸如pose,densepose,humanpaser等额外输入信息,减少推理代价
整体结构:
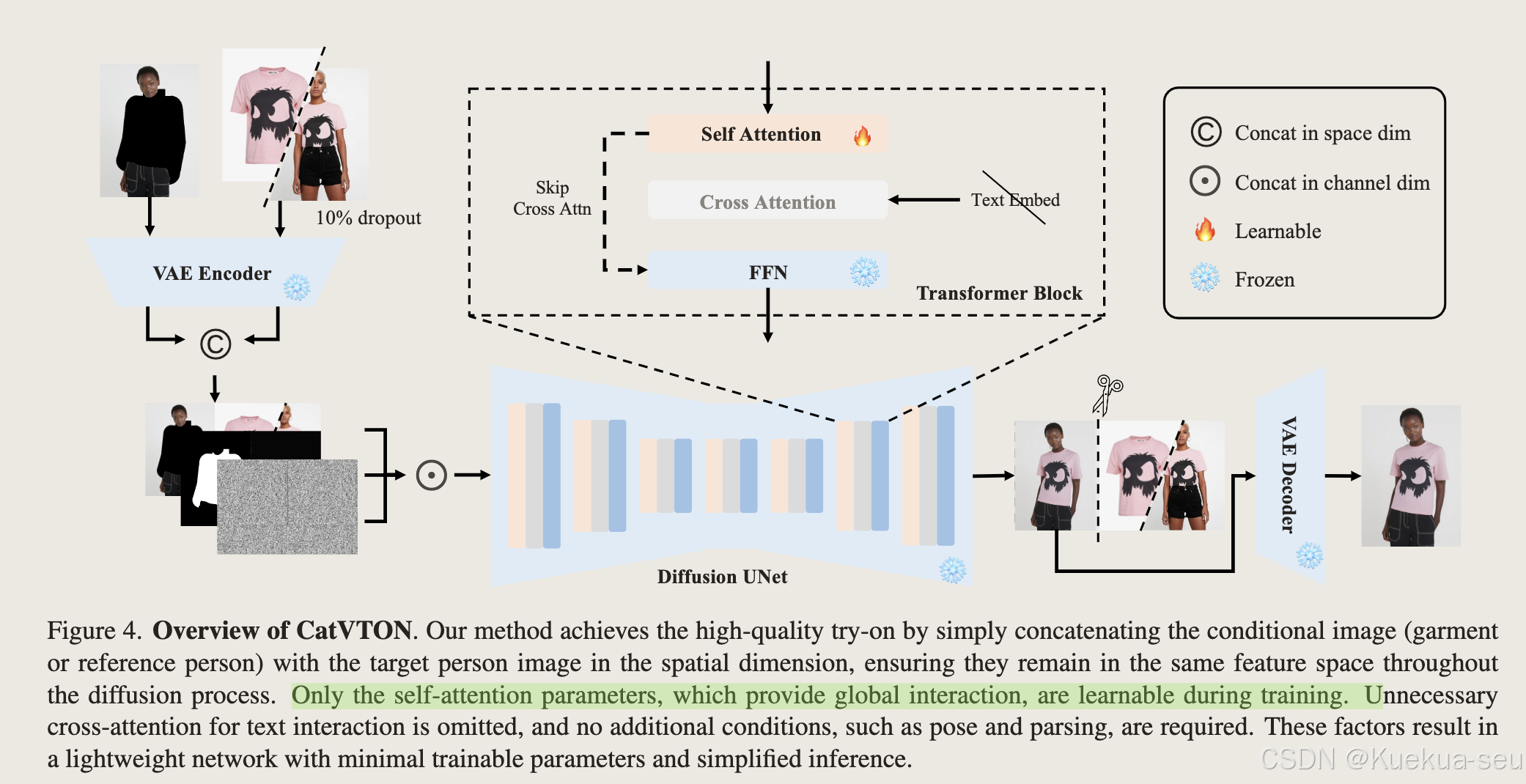
Tips:
- UNet是基于sd 1.5 inpainting模型,可训练参数为49.57M
- 输入网络的condtion均是在channel维度concat,但上图看上去时再width维度concat,存疑
- 训练时采用DREAM算法,提升训练效率,让生成结果细节更丰富,更加真实感,实际设置p=10

4.服饰和模特的特征提取单纯依赖VAE的encoder,有一定的优化空间
IMAGDressing
IMAGDressing-v1: Customizable Virtual Dressing
解决问题:
如何让生成算法不仅能控制服饰,还能控制模特脸/姿势等
解决思路:
训练时保持生成UNet参数不变,推理时就可以复用controlNet/IP-adapter等控制模特脸/姿势等
整体结构:
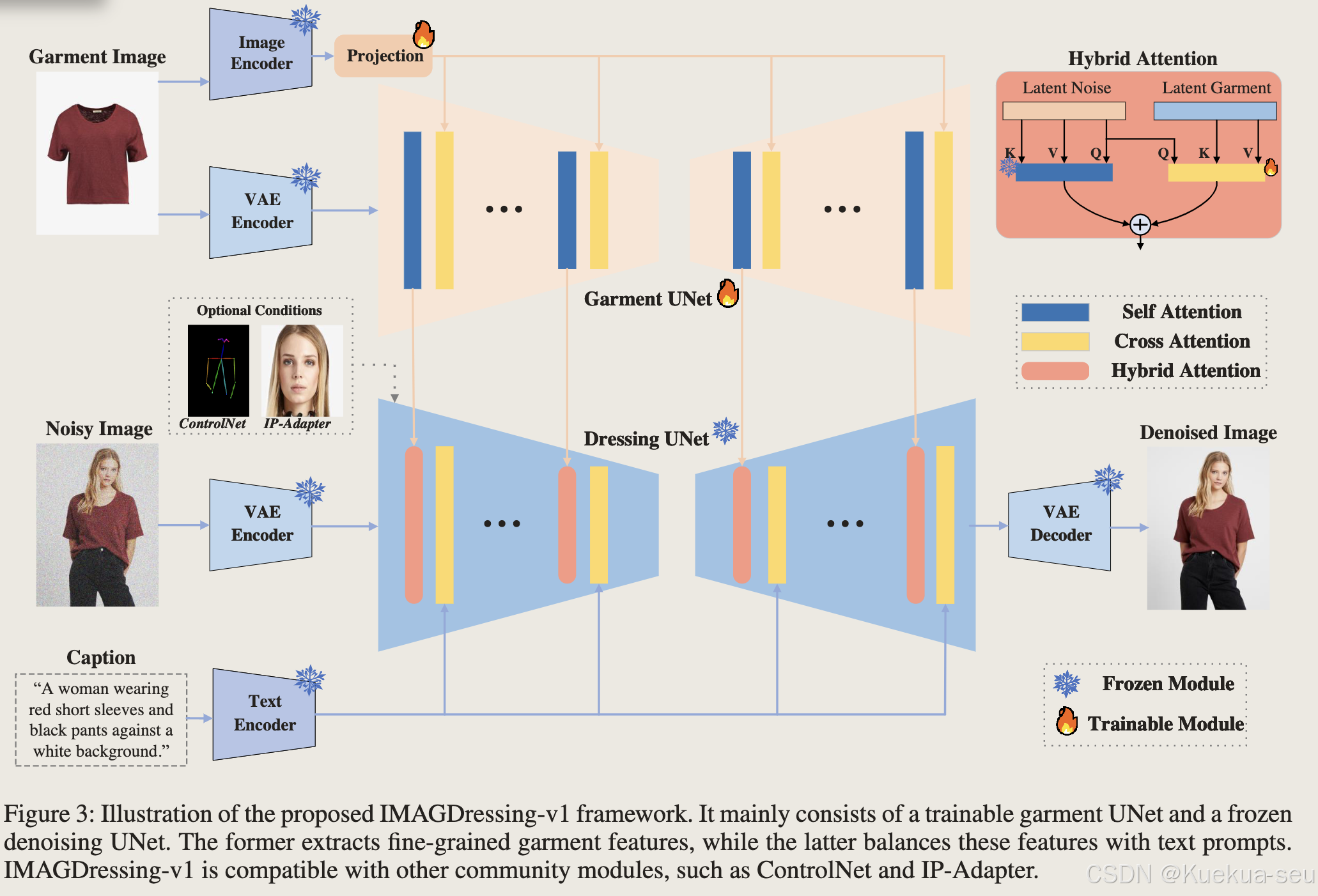
Tips:
- Dressing UNet和Garment UNet均采用sd 1.5的unet架构
- Dressing UNet将所有的self-attention模块换成Hybrid Attention,以更好的融合服饰特征
- 服饰的image encode来自clip,并训练Q-former实现图片特征与文字特征的对齐映射
- Hybrid Attention中仅训练cross attention部分,并将原网络的self-attention进行权重相加,权重越大服饰对结果影响越大:

- 作者提出CAMI算法来评测结果,包含服饰prompt/关键点/纹理及模特prompt/关键点/人脸的匹配度:

MV-VTON
Multi-View Virtual Try-On with Diffusion Models
解决问题:
对于多姿势的模特如何进行试衣
解决思路:
多姿势的模特试衣:
- 输入服饰正面和背面图片
- 设置hard-selection,根据模特关键点选择正面或背面服饰特征作为全局特征
- 设置soft-selection,根据模特关键点和服饰关键点计算权重,然后将正面和反面服饰的特征参数乘上权重concat在一起,作为局部特征
整体结构:
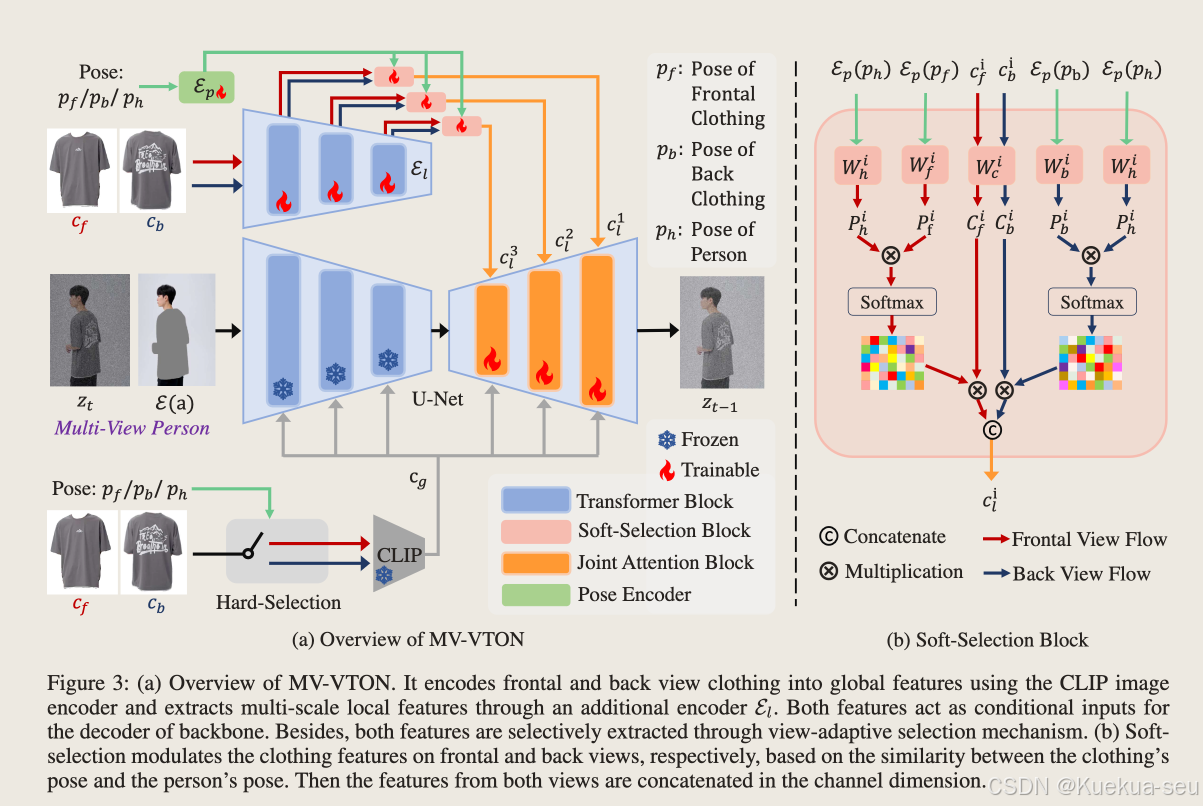
Tips:
1.生成模块采用sd inpainting模型,并用服饰图片(通过hard select选择)替代prompt作为全局特征,并同样使用clip提取特征
2.服饰输入网络前作者使用开源算法PF-AFN/stableVITON先对服饰进行简单warp
3.设计joint attention block融合全局服饰/局部服饰/模特特征:
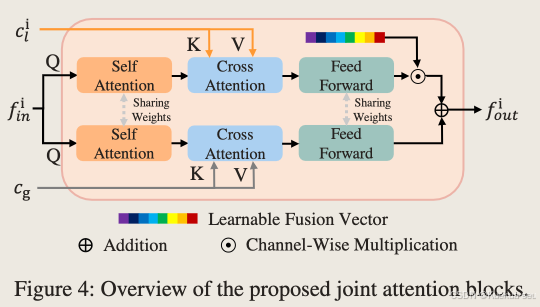

4. 训练loss中添加图片维度的l1 loss和vgg loss
IDM–VTON
Improving Diffusion Models for Authentic Virtual Try-on in the Wild
解决问题:
如何保持服饰纹理细节,提升试衣效果
解决思路:
保持服饰纹理细节:
- 使用GarmentNet(基于sdxl unet encode部分)网络提取服饰底层细节特征,concat融入试衣模块
- 使用IP-Adapter提取并注入服饰的高层语义特征
- 利用服饰属性分类工具对服饰图属性进行标志,构建详细的服饰属性描述prompt
整体结构:
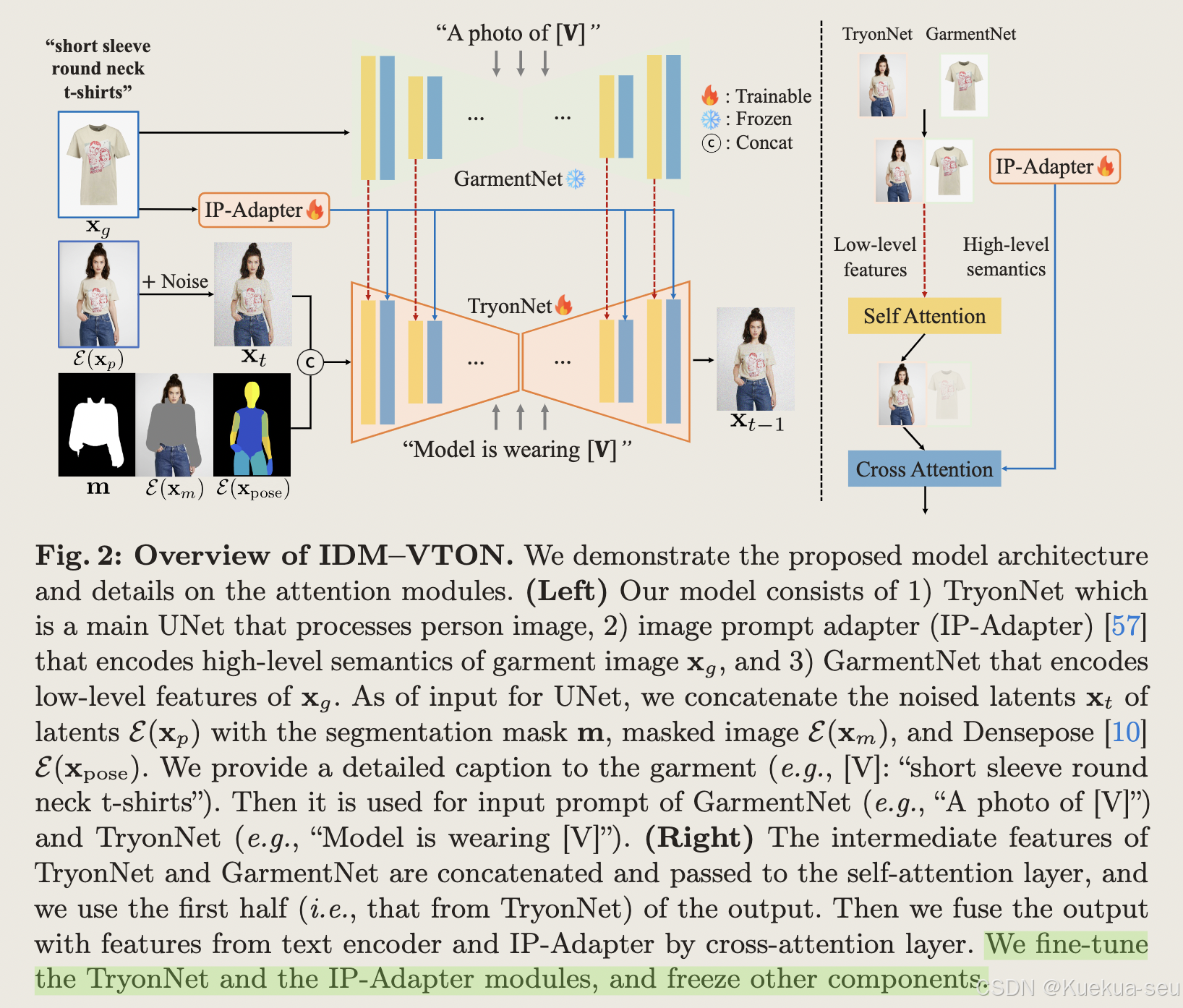
Tips:
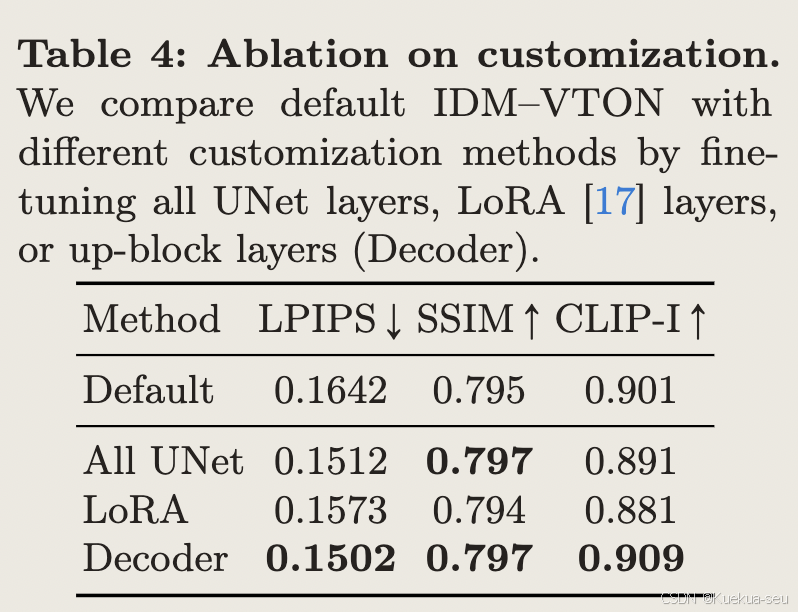
- TryonNet使用sdxl inpainting模型,unet输入channel数为13,分别是人物latent,masked人物latent, densepose latent和mask,实验发现,只finetune unet的decode部分的attention层效果最好,训练lora性价比最高
- GarmentNet基于开源的sdxl unet encode部分,不参与训练
- 详细的服饰属性描述prompt用于TryonNet和GarmentNet模块,以充分发挥基础模型的生成能力
- 实验发现基于GAN的试衣算法对简单姿势的服饰细节保持较好,但是对复杂场景和人物生成效果较差;目前基于diffsuion model的试衣算法对服饰细节保持较差
- 算法采用cfg,以GarmentNet提取的低层语义特征+IP-Adapter提取的高层语义特征+prompt为统一的condition

FitDiT
FitDiT: Advancing the Authentic Garment Details for High-fidelity Virtual Try-on
解决问题:
如何保持服饰纹理细节,自适应服饰衣长等尺寸信息
解决思路:
保持服饰纹理细节:
a. 设计服饰特征提取网络
b. 将服饰图片使用DFT映射到频谱图,训练时计算生成服饰图的频谱loss,减少高频信息(细节)的丢失
自适应服饰衣长:
训练时将模特图的服饰区域适当扩大,减少服饰形状泄漏,并随机扩大服饰区域的长度,增强模型自适应服饰衣长能力
整体结构:
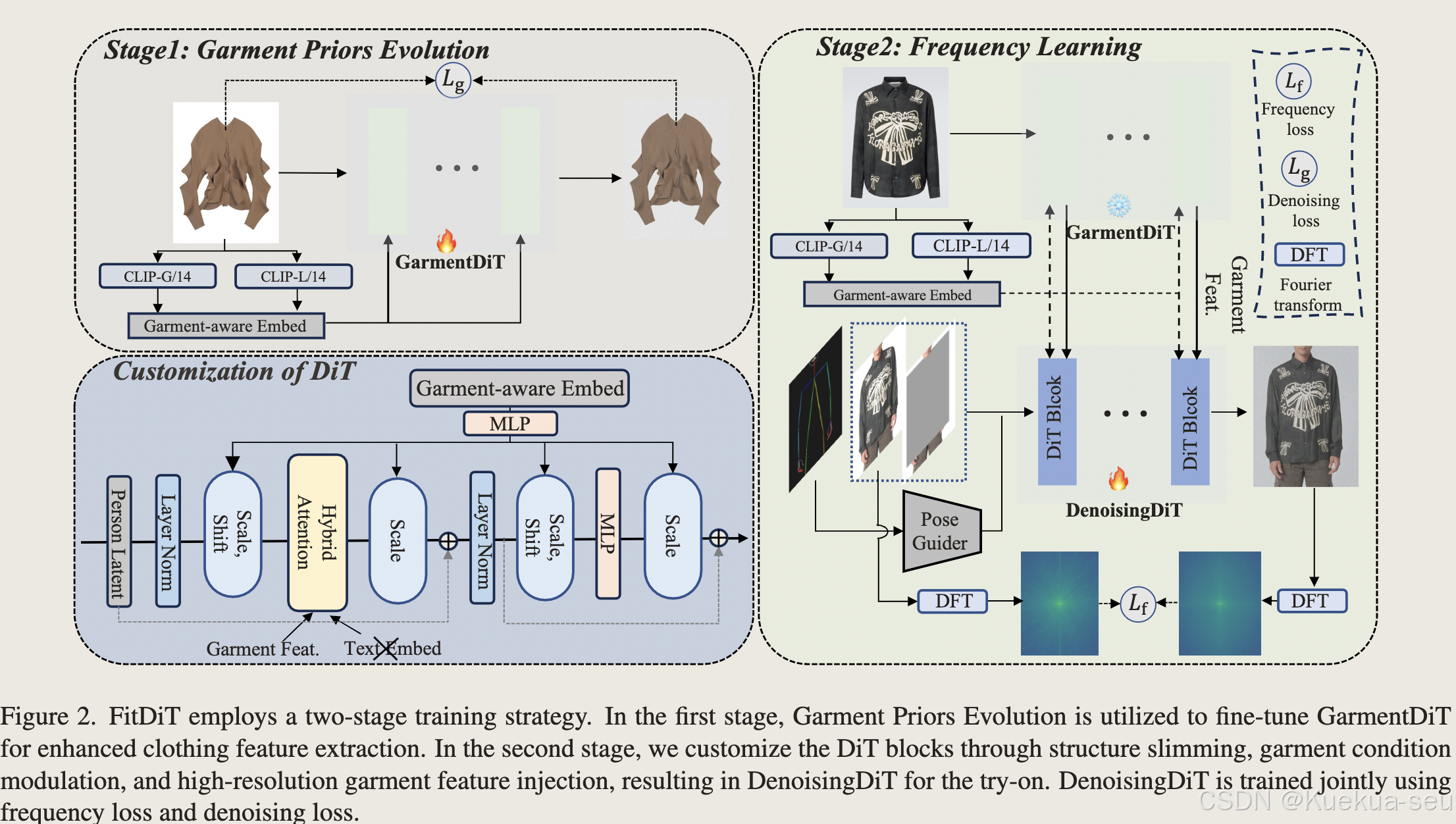
Tips:
- 主体结构采用sd3,去除text encoder部分
- 使用OpenCLIP bigG/14 和 CLIP-ViT/L去提取服饰特征,和timestep embedding合并一起作为全局特征输入网络
- 训练GarmentDiT网络提取服饰特征,网络同样使用sd3,训练时采用图生图的方式训练,推理时仅使用t=0时的网络特征参数 。服饰特征和生成网络的k,v特征concat一起,然后做self-attention

- 膨胀待服饰区域,并随机扩大服饰区域的长度

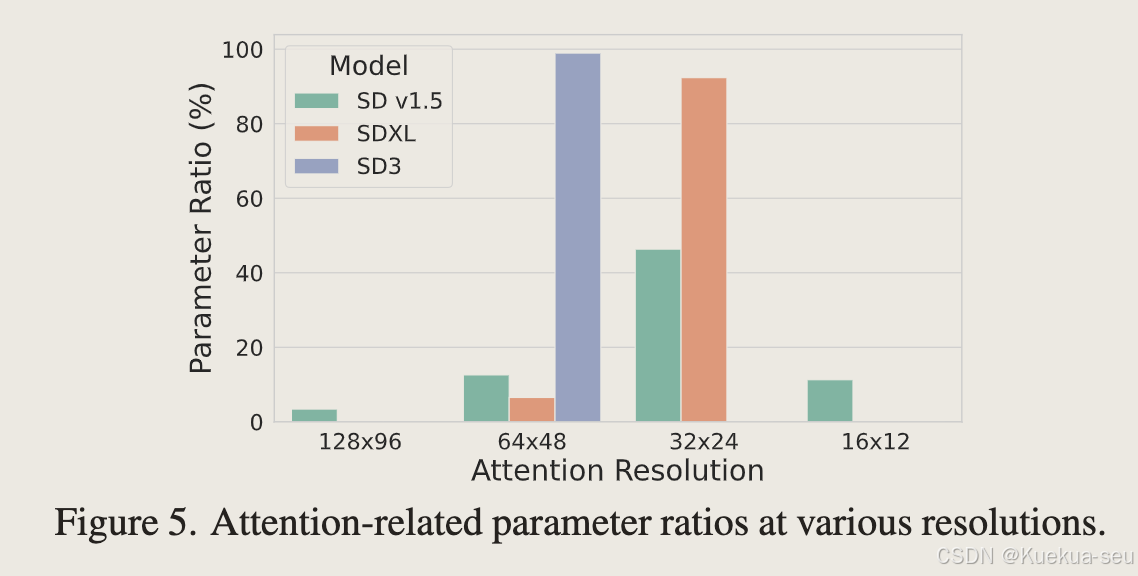
- 之所以选择sd3架构而不是sd xl/sd1.5,是因为sd3生成模块具有更强大的生成能力,并且因为没有过多下采样,99%特征维度在66*48以上,能更好的保持细节
PIDM
Person Image Synthesis via Denoising Diffusion Model
解决问题:
如何提升姿势迁移生成能力,增强细节生成效果,并保持内容的持续性。该方案同样可用于虚拟试衣,换脸等场景
解决思路:
整体网络结构:

创新点:
- 将diffusion model引入姿势迁移
- 引入TDB模块,将原图信息经特征提取后通过cross attention输入到unet的各层中,以保持生成内容的持续性
- 将target pose和nosie合并作为网络输入,引导网络生成指定姿态的模特图
- 优化classfy free算法,对原图和target pose这两个条件进行调节:


衍生应用:
- 试衣:类似与sd inpainting思路,为保持非服饰区域不变,每次去噪后将非服饰区域贴回生成图
- 风格渐变插值:即生成两种风格图片的渐变状态,使用spherical linear插值算法对两种风格的,利用线性插值对风格特征进行插值,然后输入网络进行生成


















 4598
4598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









