






搜索过程:
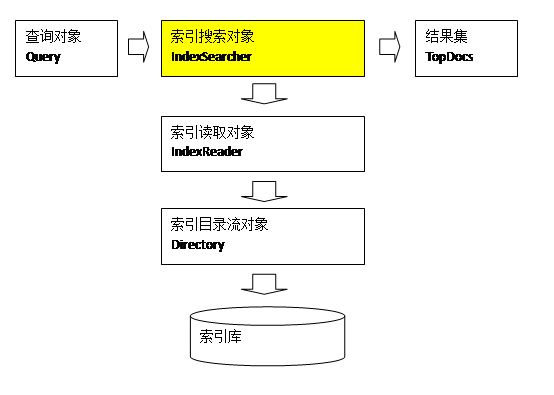
1、用户定义查询语句,用户确定查询什么内容(输入什么关键字)
指定查询语法,相当于sql语句。
2、IndexSearcher索引搜索对象,定义了很多搜索方法,程序员调用此方法搜索。
3、IndexReader索引读取对象,它对应的索引维护对象IndexWriter,IndexSearcher通过IndexReader读取索引目录中的索引文件
4、Directory索引流对象,IndexReader需要Directory读取索引库,使用FSDirectory文件系统流对象
5、IndexSearcher搜索完成,返回一个TopDocs(匹配度高的前边的一些记录)
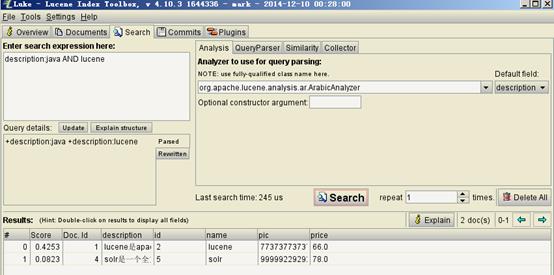
3.5.1 输入查询语句
同数据库的sql一样,lucene全文检索也有固定的语法:
最基本的有比如:AND, OR, NOT 等
举个例子,用户想找一个description中包括java关键字和lucene关键字的文档。
它对应的查询语句:description:java AND lucene
如下是使用luke搜索的例子:
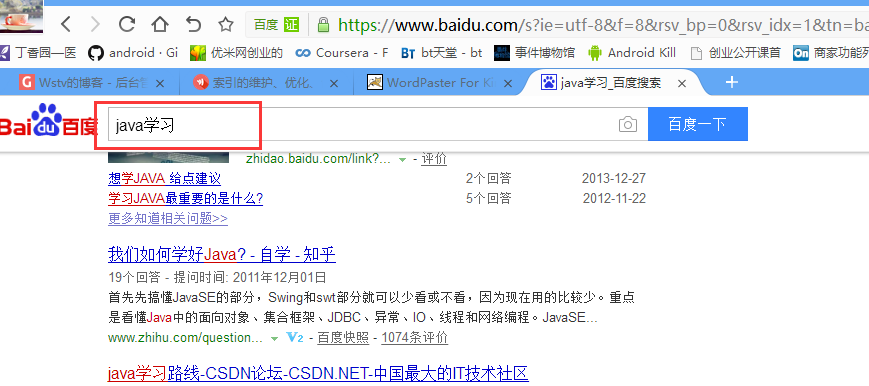
3.5.2 搜索分词
和索引过程的分词一样,这里要对用户输入的关键字进行分词,一般情况索引和搜索使用的分词器一致。
比如:输入搜索关键字“java学习”,分词后为java和学习两个词,与java和学习有关的内容都搜索出来了,如下:
3.5.3 搜索索引
根据关键字从索引中找到对应的索引信息,即词term。term与document相关联,找到了term就找到了关联的document,从document取出Field中的信息即是要搜索的信息。
代码实现:
// 查询索引
@Test
publicvoid searcherIndex() throws Exception {
// 1、创建查询(Query对象)
// 创建分析器
Analyzer analyzer = new StandardAnalyzer();
QueryParser queryParser = new QueryParser("description", analyzer);
Query query = queryParser.parse("description:java AND lucene");
// 2、执行搜索
// a) 指定索引库目录
Directory directory = FSDirectory.open(new File("E:\\\\11-index\\\\0720"));
// b) 创建IndexReader对象
IndexReader reader = DirectoryReader.open(directory);
// c) 创建IndexSearcher对象
IndexSearcher searcher = new IndexSearcher(reader);
// d) 通过IndexSearcher对象执行查询索引库,返回TopDocs对象
// 第一个参数:查询对象
// 第二个参数:最大的n条记录
TopDocs topDocs = searcher.search(query, 10);
// e) 提取TopDocs对象中前n条记录
ScoreDoc\[\] scoreDocs = topDocs.scoreDocs;
System.out.println("查询出文档个数为:" + topDocs.totalHits);
for (ScoreDoc scoreDoc : scoreDocs) {
// 文档对象ID
int docId = scoreDoc.doc;
Document doc = searcher.doc(docId);
// f) 输出文档内容
System.out.println("===============================");
System.out.println("文档id:" + docId);
System.out.println("图书id:" + doc.get("id"));
System.out.println("图书name:" + doc.get("name"));
System.out.println("图书price:" + doc.get("price"));
System.out.println("图书pic:" + doc.get("pic"));
System.out.println("图书description:" + doc.get("description"));
}
// g) 关闭IndexReader
reader.close();
}6 搜索
6.1 创建查询的两种方法
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法。类似关系数据库Sql语法一样,Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
Query是一个抽象类,lucene提供了很多查询对象,比如TermQuery项精确查询,NumericRangeQuery数字范围查询等。
如下代码:
Query query = **new** TermQuery(**new** Term("name", "lucene"));2)使用QueryParse解析查询表达式
QueryParser会将用户输入的查询表达式解析成Query对象实例。
如下代码:
QueryParser queryParser = **new** QueryParser("name", **new** IKAnalyzer());
Query query = queryParser.parse("name:lucene");6.2 通过Query子类搜索
6.2.1 TermQuery
TermQuery项查询,TermQuery不使用分析器,搜索关键词作为整体来匹配Field域中的词进行查询,比如订单号、分类ID号等。
privatevoid doSearch(Query query) {
IndexReader reader = null;
try {
// a) 指定索引库目录
Directory indexdirectory = FSDirectory.open(new File(
"E:\\\\11-index\\\\0720"));
// b) 创建IndexReader对象
reader = DirectoryReader.open(indexdirectory);
// c) 创建IndexSearcher对象
IndexSearcher searcher = new IndexSearcher(reader);
// d) 通过IndexSearcher对象执行查询索引库,返回TopDocs对象
// 第一个参数:查询对象
// 第二个参数:最大的n条记录
TopDocs topDocs = searcher.search(query, 10);
// e) 提取TopDocs对象中的文档ID,如何找出对应的文档
ScoreDoc\[\] scoreDocs = topDocs.scoreDocs;
System.out.println("总共查询出的结果总数为:" + topDocs.totalHits);
Document doc;
for (ScoreDoc scoreDoc : scoreDocs) {
// 文档对象ID
int docId = scoreDoc.doc;
doc = searcher.doc(docId);
// f) 输出文档内容
System.out.println(doc.get("filename"));
System.out.println(doc.get("path"));
System.out.println(doc.get("size"));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}@Test
publicvoid testTermQuery() throws Exception {
// 1、创建查询(Query对象)
Query query = new TermQuery(new Term("filename", "apache"));
// 2、执行搜索
doSearch(query);
}6.2.2 NumbericRangeQuery
NumericRangeQuery,指定数字范围查询.
@Test
publicvoid testNumbericRangeQuery() throws Exception {
// 创建查询
// 第一个参数:域名
// 第二个参数:最小值
// 第三个参数:最大值
// 第四个参数:是否包含最小值
// 第五个参数:是否包含最大值
Query query = NumericRangeQuery.newLongRange("size", 1l, 100l, true,true);
// 2、执行搜索
doSearch(query);
}6.2.3 BooleanQuery
BooleanQuery,布尔查询,实现组合条件查询。
//MUST:查询条件必须满足,相当于AND
//SHOULD:查询条件可选,相当于OR
//MUST_NOT:查询条件不能满足,相当于NOT非
@Test
publicvoid booleanQuery() throws Exception {
BooleanQuery query = new BooleanQuery();
Query query1 = new TermQuery(new Term("id", "3"));
Query query2 = NumericRangeQuery.newFloatRange("price", 10f, 200f,
true, true);
//MUST:查询条件必须满足,相当于AND
//SHOULD:查询条件可选,相当于OR
//MUST\_NOT:查询条件不能满足,相当于NOT非
query.add(query1, Occur.MUST);
query.add(query2, Occur.SHOULD);
System.out.println(query);
search(query);
}组合关系代表的意思如下:
1、MUST和MUST表示“与”的关系,即“并集”。
2、MUST和MUST_NOT前者包含后者不包含。
3、MUST_NOT和MUST_NOT没意义
4、SHOULD与MUST表示MUST,SHOULD失去意义;
5、SHOUlD与MUST_NOT相当于MUST与MUST_NOT。
6、SHOULD与SHOULD表示“或”的概念。
6.3 通过QueryParser搜索
通过QueryParser也可以创建Query,QueryParser提供一个Parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);查询。
6.3.1 QueryParser
6.3.1.1 代码实现
@Test
publicvoidtestQueryParser() throws Exception {
// 创建QueryParser
// 第一个参数:默认域名
// 第二个参数:分词器
QueryParser queryParser = new QueryParser("name", new IKAnalyzer());
// 指定查询语法,如果不指定域,就搜索默认的域
Query query = queryParser.parse("lucene");
System.out.println(query);
// 2、执行搜索
doSearch(query);
}6.3.1.2 查询语法
1、基础的查询语法,关键词查询:
域名+“:”+搜索的关键字
例如:content:java
- 范围查询
域名+“:”+[最小值 TO 最大值]
例如:size:[1 TO 1000]
注意:QueryParser不支持对数字范围的搜索,它支持字符串范围。数字范围搜索建议使用NumericRangeQuery。
- 组合条件查询
Occur.MUST 查询条件必须满足,相当于and | +(加号) |
Occur.SHOULD 查询条件可选,相当于or | 空(不用符号) |
Occur.MUST_NOT 查询条件不能满足,相当于not非 | -(减号) |
1)+条件1 +条件2:两个条件之间是并且的关系and
例如:+filename:apache +content:apache
- +条件1 条件2:必须满足第一个条件,忽略第二个条件
例如:+filename:apache content:apache
- 条件1 条件2:两个条件满足其一即可。
例如:filename:apache content:apache
4)-条件1 条件2:必须不满足条件1,要满足条件2
例如:-filename:apache content:apache
第二种写法:
条件1 AND 条件2
条件1 OR 条件2
条件1 NOT 条件2
6.3.2 MultiFieldQueryParser
通过MuliFieldQueryParse对多个域查询。
@Test
publicvoidtestMultiFieldQueryParser() throws Exception {
// 可以指定默认搜索的域是多个
String\[\] fields = { "name", "description" };
// 创建一个MulitFiledQueryParser对象
QueryParser parser = new MultiFieldQueryParser(fields, new IKAnalyzer());
// 指定查询语法,如果不指定域,就搜索默认的域
Query query = parser.parse("lucene");
// 2、执行搜索
doSearch(query);
}6.4 TopDocs
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下:
方法或属性 | 说明 |
totalHits | 匹配搜索条件的总记录数 |
scoreDocs | 顶部匹配记录 |
注意:
Search方法需要指定匹配记录数量n:indexSearcher.search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n
7 相关度排序
7.1 什么是相关度排序
相关度排序是查询结果按照与查询关键字的相关性进行排序,越相关的越靠前。比如搜索“Lucene”关键字,与该关键字最相关的文章应该排在前边。
7.2 相关度打分
Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边。如何打分呢?Lucene是在用户进行检索时实时根据搜索的关键字计算出来的,分两步:
1)计算出词(Term)的权重
2)根据词的权重值,计算文档相关度得分。
什么是词的权重?
通过索引部分的学习,明确索引的最小单位是一个Term(索引词典中的一个词****),搜索也是要从Term中搜索,再根据Term找到文档,Term****对文档的重要性称为权重,影响Term权重有两个因素:
- Term Frequency (tf)****:
指此Term在此文档中出现了多少次。****tf 越大说明越重要。
词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“Lucene”这个词,在文档中出现的次数很多,说明该文档主要就是讲Lucene技术的。
- Document Frequency (df)****:
指有多少文档包含次Term。****df 越大说明越不重要。
比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,有越多的文档包含此词(Term), 说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
7.3 设置boost值影响相关度排序
boost是一个加权值(默认加权值为1.0f****),它可以影响权重的计算。
- 在索引时对某个文档中的field设置加权值高,在搜索时匹配到这个文档就可能排在前边。
- 在搜索时对某个域进行加权,在进行组合域查询时,匹配到加权值高的域最后计算的相关度得分就高。
设置boost是给域(field)或者Document设置的。
7.3.1 在创建索引时设置
如果希望某些文档更重要,当此文档中包含所要查询的词则应该得分较高,这样相关度排序可以排在前边,可以在创建索引时设定文档中某些域(Field)的boost值来实现,如果不进行设定,则Field Boost默认为1.0f。一旦设定,除非删除此文档,否则无法改变。
7.3.1.1 代码实现
@Test
publicvoid setBoost4createIndex() throws Exception {
// 创建分词器
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig cfg = new IndexWriterConfig(Version.LUCENE\_4\_10\_3,
analyzer);
Directory directory = FSDirectory.open(new File("E:\\\\11-index\\\\0728"));
// 创建IndexWriter对象,通过它把分好的词写到索引库中
IndexWriter writer = new IndexWriter(directory, cfg);
Document doc = new Document();
Field id = new StringField("id", "11", Store.YES);
Field description = new TextField("description", "测试设置BOOST值 lucene",
Store.YES);
// 设置boost
description.setBoost(10.0f);
// 把域添加到文档中
doc.add(id);
doc.add(description);
writer.addDocument(doc);
// 关闭IndexWriter
writer.close();
}7.3.1.2 输出
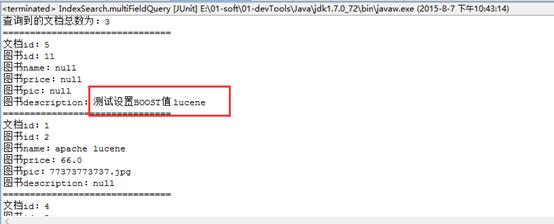
7.3.2 在查询索引时设置
7.3.2.1 代码实现
7.3.2.2 输出
未设置加权值:















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









